



 本文介绍了信息检索中的倒排索引,详细讲解了倒排索引的构造过程和查询机制,并探讨了优化查询的WAND算法。此外,文章还深入讨论了BM25算法,一种用于评估搜索词与文档相关性的方法,其中考虑了单词频率和IDF权重。
本文介绍了信息检索中的倒排索引,详细讲解了倒排索引的构造过程和查询机制,并探讨了优化查询的WAND算法。此外,文章还深入讨论了BM25算法,一种用于评估搜索词与文档相关性的方法,其中考虑了单词频率和IDF权重。
引言
Information Retrieval (IR):
从大规模非结构化数据 的集合中找到满足用户信息需求的资料。
包括信息的获取、表示、存储、组织和访问。
一、倒排索引
1、倒排索引介绍
其中倒排索引实现了“单词-文档矩阵”的存储,是实现单词到文档映射关系的最佳实现方式。
所谓正向索引是 通过 文档docID 查找 单词wordID
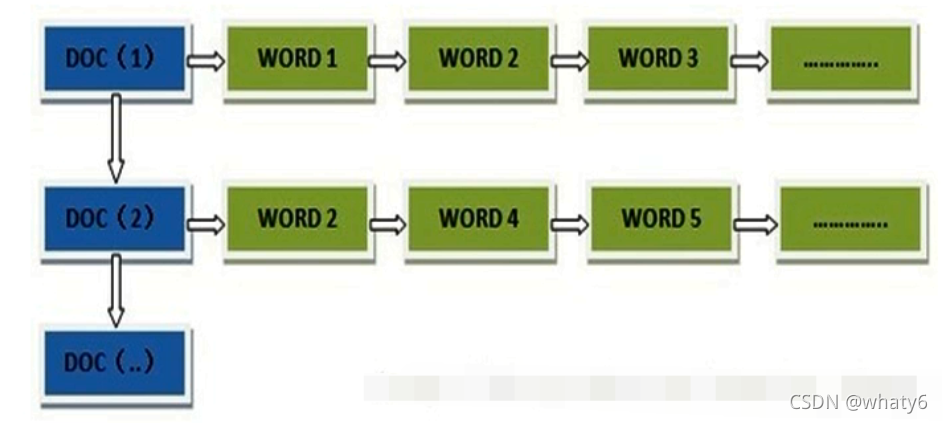
而反向索引(倒排索引)是 通过 wordID 查找 docID,从词的关键字去查找文档。
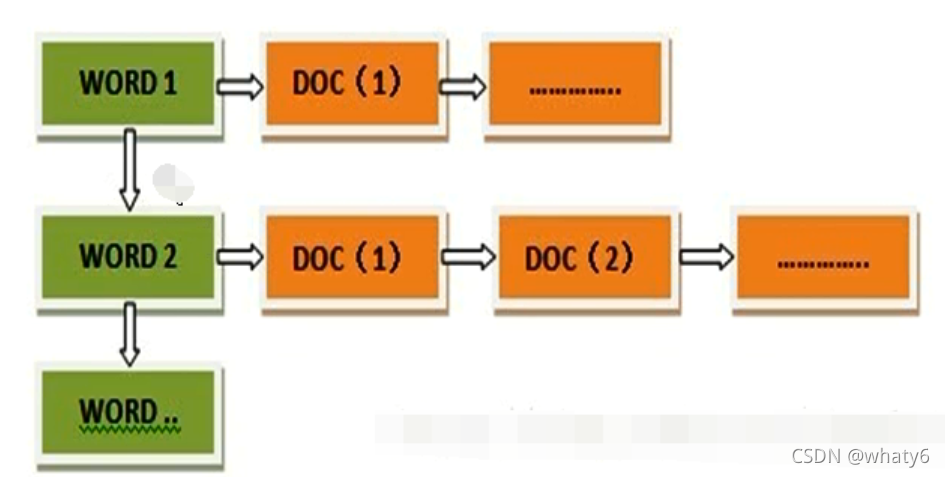
倒排索引主要由两个部分组成:“单词词典”和“倒排文件”
单词词典:文档中所有单词的集合,词典中每条索引项记录单词本身的信息和指向“倒排列表”的指针;
倒排文件:所有单词按照docID排序具有可变长度的记录列表。
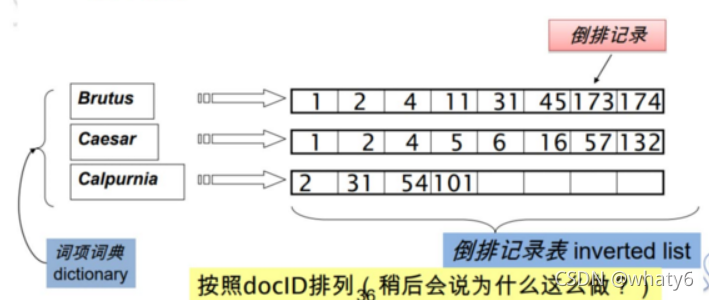
通常,进行 索引建立 会给分词后的单词做些预处理,以防 索引列表过于稀疏。
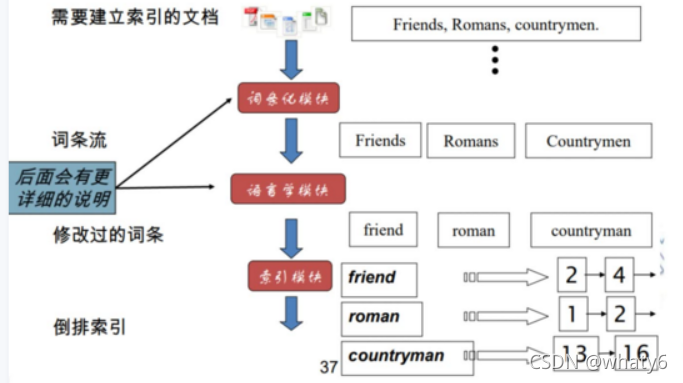
2、建立倒排索引
步骤:
1)建立 词条序列 (wordID -> docID)

2)排序:先按照词条排序,再按照docID排序
3、倒排索引查询
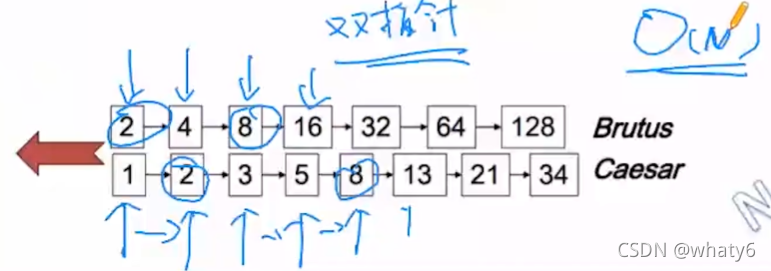
查找Brutus AND Caesar都出现的文档:
- 在字典中分别找到Brutus和Caesar,得到它们的倒排记录表
Brutus: 2,4,8,16,32,64,128
Caesar:1,2,3,5, 8, 13, 21,34 - 通过双指针合并两个倒排记录表
双指针查找步骤:
比较docID大小:2>1 -> 下方指针右移一位 -> 2=2 -> 保留记录2,两边都右移一位 -> 4>3 -> 下方指针右移一位 -> 4< 5 -> 上方指针右移 -> 8>5 -> 下方指针右移一位 -> 8=8 -> 保留记录8,两边都右移一位 -> 16>13 -> 下方指针右移一位 -> 16< 21 -> 上方指针右移一位 -> 32>21 -> 下方指针右移一位 -> 32< 34 -> 上方指针右移一位 -> 64>34 -> 下方已遍历完,结束
二、BM25算法
bm25是一种评价 搜索词和所有文档 之间相关性的算法,用来检索模型。
有一个query和一批文档,求query和每篇文档D之间的相关性(相关性计算中统计的query和文档之间的相关概率可通过query的倒排索引来计算):
1、加权求和
首先对query切分,得到单词qi,计算qi的分数:
- 每个单词的权重Wi
- 相关性分数R:单词和D之间的相关性
- 最后对于每个单词的分数求和,得到**query和文档之间的分数**

2、其中单词权重Wi使用 IDF 表示:
单词qi在文档中出现的次数越少,权重越大。
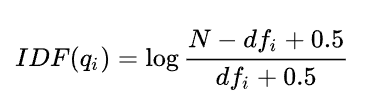
N -> 所有文档数目;dfi -> 包含了单词qi的文档数
3、R相关性分为两部分:
单词与文档的相关性:
BM25的设计依据一个重要的发现:词频和相关性之间的关系是非线性的\color{Blue}{词频和相关性之间的关系是非线性的}词频和相关性之间的关系是非线性的,也就是说,每个词对于文档的 相关性分数不会超过一个特定的阈值\color{Blue}{相关性分数不会超过一个特定的阈值}相关性分数不会超过一个特定的阈值,当词出现的次数达到一个阈值后,其影响就不在线性增加了,而这个阈值会跟文档本身有关。
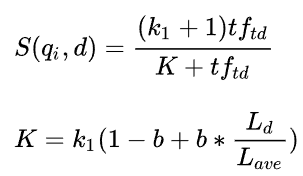
单词与query的相关性:
当query很长时,我们还需要刻画单词与query的之间的权重,对于短的query,这一项不是必须的。
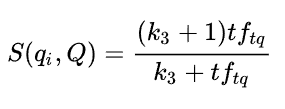
tftd-> 表示qi出现在的d文档数;tftq -> 表示qi在query中出现的次数;Ld -> 表示当前文档的长度;Lave -> 平均doc长度;k1 -> 2;k3 -> 1;b -> 075。
4、BM25最终公式:
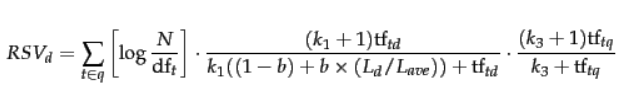
经过试验,上面三个可调参数, [k1] 和 [k3 ] 可取1.2~2,b取0.75
三、倒排索引的优化WAND算法
wand(weak and)算法:计算文本相关性,找出Topk个相关文档。
优势:
采用倒排索引的方式查询,虽然比全量遍历节约大量时间,但有时仍会很慢。wead-and算法通过计算每个词对相关性贡献的上限(TF−IDF)\color{Blue}{计算每个词对相关性贡献的上限(TF-IDF)}计算每个词对相关性贡献的上限(TF−IDF)来估计文档的相关性上限\color{Blue}{估计文档的相关性上限}估计文档的相关性上限,建立一个阈值对倒排中的结果进行减枝\color{Blue}{建立一个阈值对倒排中的结果进行减枝}建立一个阈值对倒排中的结果进行减枝,达到提速\color{Red}{提速}提速的效果。
首先计算每个词的TF-IDF(一般IDF是固定的,只需要估计一个词在各个文档的词频IF,记录这个词的最大TF),再计算一个query和一个文档的相关性上限值,即query中在同一篇文档共同出现的相关性上限之和。通过与预设的阈值比较,若query与文档的相关性大于阈值,则计算query在该偏文档的相关性;若小于,则丢弃,查看下一篇文档。
例子:

1、计算query中每个词在各个文档中的TF-IDF,记录每个词的贡献最大值
| 词 | TF-IDFmax |
| The | 0.9 |
| quick | 1.9 |
| brown | 2.3 |
| fox | 7.1 |
2、倒排索引表上滑动指针,依次计算query在每个文档的相关性
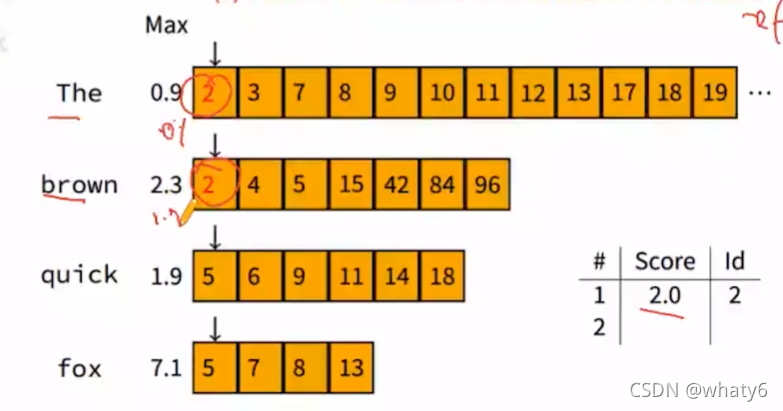
query中词语出现的第一篇文档是docID=2,出现词只有The和brown,假设他们的文档相关性得分分别为0.1、1.9,那么query在docID=2上的得分是2.0;滑动窗口,下一篇文档是docID=3,只有The,假设得分是0.5。(topk=2)
| Score | docID |
| 2.0 | 2 |
| 0.5 | 3 |
依次滑向下一个窗口docID=4,由于brown的贡献上限是2.3,大于0.5(这里的0.5相当于是个估计阈值),很有可能得出query在该文档docID=4上的相关性大于query在docID=3上的相关性,所以计算docID=4的文档相关性,假设是1.4(>0.5),更新表格。
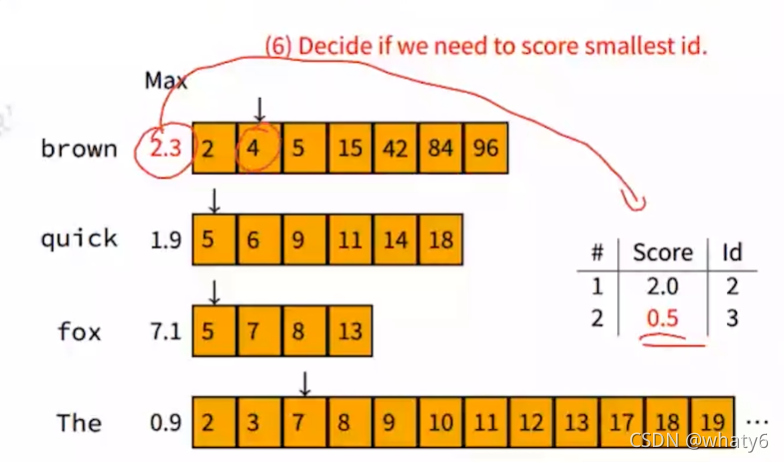
| Score | docID |
| 2.0 | 2 |
| 1.4 | 4 |
依次滑动窗口docID=5:
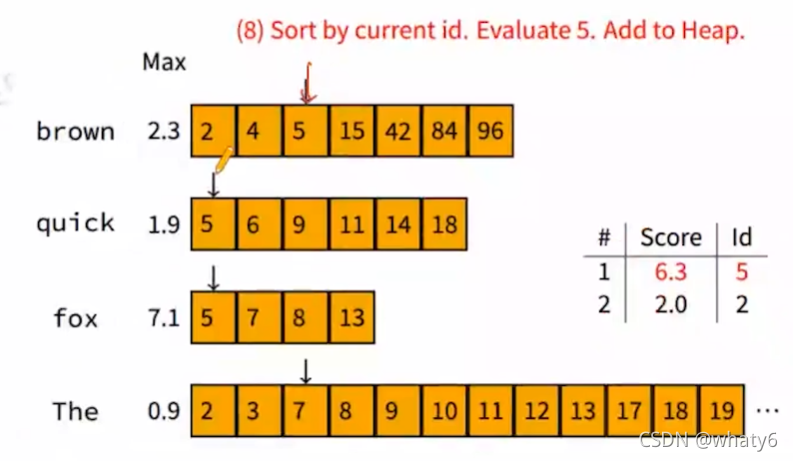
依次滑动窗口docID=6:
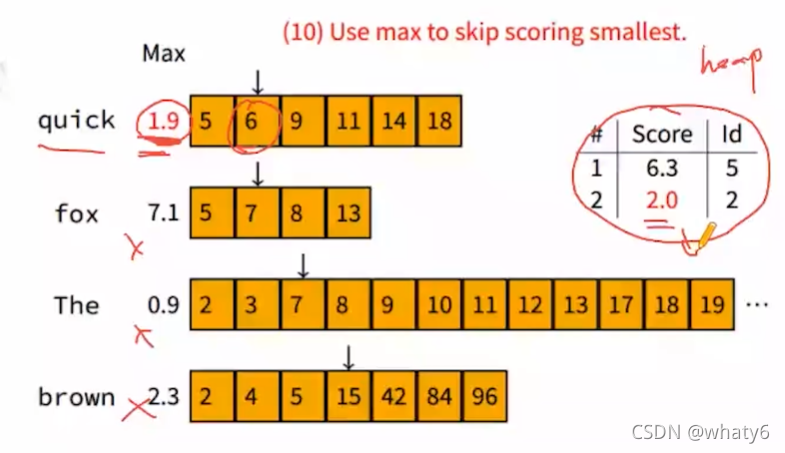
query在docID=6上的最大贡献度1.9,比表格中最小的2.0还小,说明query在docID=6的相关性不可能比超过已计算的top2的相关性,所以
不计算query在docID=6的相关性,再次滑动窗口docID=7…依次类推…
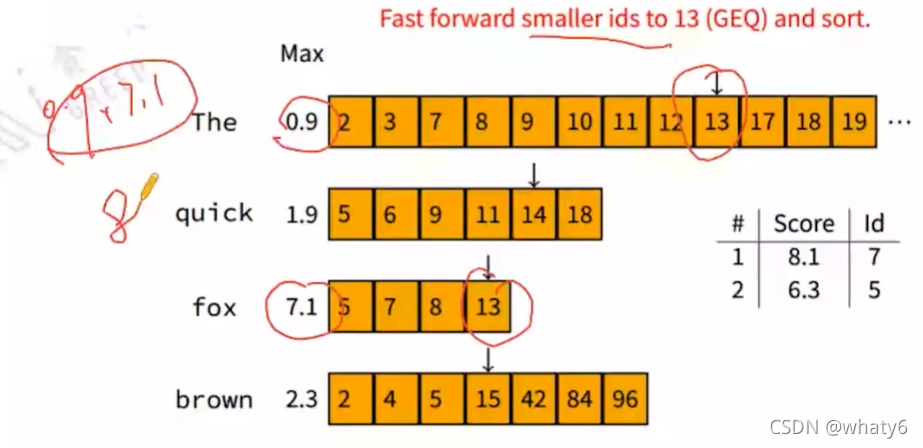
| Score | docID |
| 8.1 | 7 |
| 8 | 13 |
当docID>13,发现query的贡献度都不可能大于表格中top2的score,所以结束。


















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









