 Oracle数据库:COUNT(1)与COUNT(*)的效率对比分析
Oracle数据库:COUNT(1)与COUNT(*)的效率对比分析




 本文探讨了Oracle数据库中COUNT(1)与COUNT(*)的执行效率,通常认为COUNT(*)会读取所有字段,而COUNT(1)仅统计1的个数,效率更高。但实验结果显示,两者在效率上几乎没有差别,且在有符合条件的索引情况下,都能利用索引。总结得出,COUNT(1)与COUNT(*)在实际应用中效果相当,但在大量数据查询时,推荐使用更简洁的COUNT(*)。
本文探讨了Oracle数据库中COUNT(1)与COUNT(*)的执行效率,通常认为COUNT(*)会读取所有字段,而COUNT(1)仅统计1的个数,效率更高。但实验结果显示,两者在效率上几乎没有差别,且在有符合条件的索引情况下,都能利用索引。总结得出,COUNT(1)与COUNT(*)在实际应用中效果相当,但在大量数据查询时,推荐使用更简洁的COUNT(*)。
目录
前言
Oracle中的统计COUNT(*)和COUNT(1)的效率比较,一直以来都是觉得COUNT(1)会比COUNT(*)快一些。至于为什么,我个人以前总觉得*这个符号会将Oracle中所有的字段记录会返回回来,而COUNT(1)只是统计了1的个数,相对比下就自认为COUNT(1)要快一些。然而有一次去参加客户方的一项数据开发时,他们一篇文档中写着COUNT(*)反而要比COUNT(1)快!这严重地打破了之前的认知。基于这个疑问,就尝试写了一下这篇文章,来探讨一下COUNT(1)和COUNT(*)的效率哪个快?
以下是本篇文章正文内容,下面案例可供参考
一、Oracle的存储机制
众所周知,Oracle是关系型数据库。跟Hbase等非关系型数据库不同的一点在于它的存储形式是采用行式存储的。行式存储也就是将表中的数据一行行的写入数据块。而数据块是Oracle的最小单位。每次我们在查询数据的时候,Oracle时常会从磁盘中读取一些数据块到内存中。也就是说你在查询某些字段时,Oracle是把表中一整行的数据读取到内存当中,然后再从头到尾扫描你需要的字段。并非只读取你查询的那几个字段。
二、COUNT(*)与COUNT(字段)的比较
1.COUNT 表中各个字段的比较
如上面所说,Oracle是一行行读取数据,并且在访问字段的时候是根据表中字段的顺序从左往右访问。所以字段在表中的顺序越靠左访问速度越快。为了验证这个设想,进行了如下实验:
/*
* 步骤1
* 目的:创建一张21个字段的的表
* 大小:1W条记录
*/
CREATE TABLE TMP_TEST_COUNT AS --创建表
SELECT LEVEL AS ID --序号
,CHR(65 + MOD(LEVEL, 26)) AS TEXT1 --字母,用ASCII计算而来
,CHR(65 + MOD(LEVEL, 26)) AS TEXT2
,CHR(65 + MOD(LEVEL, 26)) AS TEXT3
,CHR(65 + MOD(LEVEL, 26)) AS TEXT4
,CHR(65 + MOD(LEVEL, 26)) AS TEXT5
,CHR(65 + MOD(LEVEL, 26)) AS TEXT6
,CHR(65 + MOD(LEVEL, 26)) AS TEXT7
,CHR(65 + MOD(LEVEL, 26)) AS TEXT8
,CHR(65 + MOD(LEVEL, 26)) AS TEXT9
,CHR(65 + MOD(LEVEL, 26)) AS TEXT10
,CHR(65 + MOD(LEVEL, 26)) AS TEXT11
,CHR(65 + MOD(LEVEL, 26)) AS TEXT12
,CHR(65 + MOD(LEVEL, 26)) AS TEXT13
,CHR(65 + MOD(LEVEL, 26)) AS TEXT14
,CHR(65 + MOD(LEVEL, 26)) AS TEXT15
,CHR(65 + MOD(LEVEL, 26)) AS TEXT16
,CHR(65 + MOD(LEVEL, 26)) AS TEXT17
,CHR(65 + MOD(LEVEL, 26)) AS TEXT18
,CHR(65 + MOD(LEVEL, 26)) AS TEXT19
,CHR(65 + MOD(LEVEL, 26)) AS TEXT20
FROM DUAL
CONNECT BY LEVEL <= 10000;
/*
*步骤2
*目的:手动获取表的信息,为了后续SQL执行能有一个正确的执行计划
*/
CALL DBMS_STATS.GATHER_TABLE_STATS(OWNNAME=>RPT, TABNAME=>'TMP_TEST_COUNT');
/*
*步骤3
*目的:统计各个字段统计的时长
*/
DECLARE
L_DUMMY PLS_INTEGER;
L_START PLS_INTEGER;
L_STOP PLS_INTEGER;
L_SQL VARCHAR2(100);
BEGIN
FOR I IN 1 .. 20 LOOP
L_SQL := 'SELECT COUNT(TEXT' || I || ') FROM TMP_TEST_COUNT';
--因为Oracle有缓存机制,第一次执行的数据会被缓存在内存中,当下次被访问时就不会去磁盘中加载。为了精准测试先加载数据
EXECUTE IMMEDIATE L_SQL;
L_START := DBMS_UTILITY.GET_TIME;
--增加CPU的计算,得到更精确的结果
FOR J IN 1 .. 1000 LOOP
EXECUTE IMMEDIATE L_SQL
INTO L_DUMMY;
END LOOP;
L_STOP := DBMS_UTILITY.GET_TIME;
DBMS_OUTPUT.PUT_LINE((L_STOP - L_START) / 100);
END LOOP;
END;
测试结果:
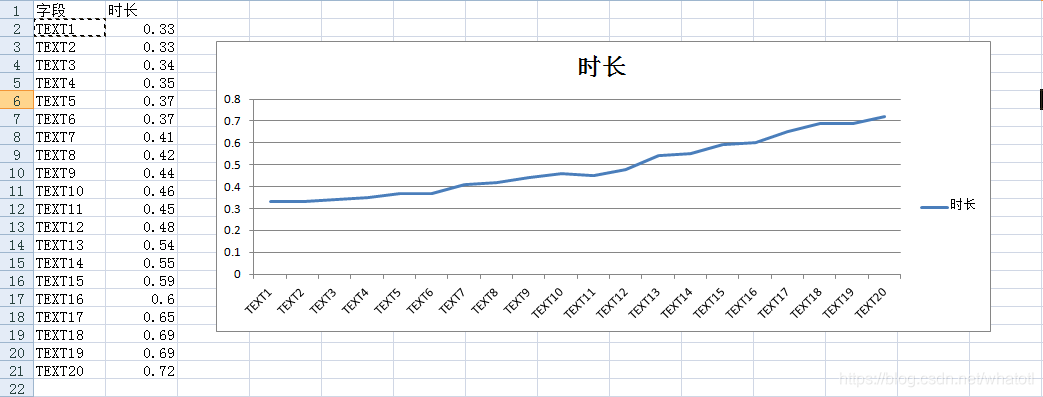
如上图发现,字段的顺序是有影响SQL的执行效率。也就是字段越靠右速度就越慢。
2.COUNT(*)的效率
代码如下(示例):
/*
*目的:统计COUNT(*)统计的时长
*/
DECLARE
L_DUMMY PLS_INTEGER;
L_START PLS_INTEGER;
L_STOP PLS_INTEGER;
L_SQL VARCHAR2(100);
BEGIN
L_SQL := 'SELECT COUNT(*) FROM TMP_TEST_COUNT';
--因为Oracle有缓存机制,第一次执行的数据会被缓存在内存中,当下次被访问时就不会去磁盘中加载。为了精准测试先加载数据
EXECUTE IMMEDIATE L_SQL;
L_START := DBMS_UTILITY.GET_TIME;
--增加CPU的计算,得到更精确的结果
FOR J IN 1 .. 1000 LOOP
EXECUTE IMMEDIATE L_SQL
INTO L_DUMMY;
END LOOP;
L_STOP := DBMS_UTILITY.GET_TIME;
DBMS_OUTPUT.PUT_LINE((L_STOP - L_START) / 100);
END;
结果:0.14s
经过上面的实验发现,COUNT(*)的效率是要比COUNT(字段)要高。也就是说Oracle在统计COUNT(*)时,并不会去读取字段。
三、COUNT(1)的效率,以及与COUNT(*)的比较
1. COUNT(1)与COUNT(*)的效率比较
先测试一下COUNT(1)的效率,代码如下(示例):
/*
*目的:统计COUNT(1)统计的时长
*/
DECLARE
L_DUMMY PLS_INTEGER;
L_START PLS_INTEGER;
L_STOP PLS_INTEGER;
L_SQL VARCHAR2(100);
BEGINL_SQL := 'SELECT COUNT(1) FROM TMP_TEST_COUNT';
--因为Oracle有缓存机制,第一次执行的数据会被缓存在内存中,当下次被访问时就不会去磁盘中加载。为了精准测试先加载数据
EXECUTE IMMEDIATE L_SQL;L_START := DBMS_UTILITY.GET_TIME;
--增加CPU的计算,得到更精确的结果
FOR J IN 1 .. 1000 LOOP
EXECUTE IMMEDIATE L_SQL
INTO L_DUMMY;
END LOOP;L_STOP := DBMS_UTILITY.GET_TIME;
DBMS_OUTPUT.PUT_LINE((L_STOP - L_START) / 100);END;
结果:0.15s,与COUNT(*)相差很少。由于每次执行的结果时间是不一样的,所以会有误差。但其实效率上是一致的。
由于上面的实验并不能很明显的看出COUNT(1)与COUNT(*)的效率,接下去从真实的执行计划去查看。看看哪个比较耗费资源。
2. COUNT(1)与COUNT(*)的执行计划比较
在Oracle中选择执行计划,是根据优化器来决定的。而优化器是基于两种方式进行计算的。一种是规则,另一种是成本。在Oracle 11g当中,Oracle默认采用的优化策略是成本(Cost)。
代码如下(示例):
SET TIMING ON; --设置显示最终执行完所花费的时间
SET AUTOTRACE ON; --设置显示执行过程
SET AUTOTRACE TRACEONLY; --设置只显示执行过程,不显示SQL结果集
分别执行如下代码,获取执行计划:
SELECT COUNT(1) FROM TMP_TEST_COUNT;
SELECT COUNT(*) FROM TMP_TEST_COUNT;
分别的执行计划如下:
SQL> SELECT COUNT(1) FROM TMP_TEST_COUNT;
已用时间: 00: 00: 00.04
执行计划
----------------------------------------------------------
Plan hash value: 728617846
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 22 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| TMP_TEST_COUNT | 9756 | 22 (0)| 00:00:01 |
-----------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
4 recursive calls
0 db block gets
131 consistent gets
0 physical reads
0 redo size
527 bytes sent via SQL*Net to client
520 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processedSQL> SELECT COUNT(*) FROM TMP_TEST_COUNT;
已用时间: 00: 00: 00.00
执行计划
----------------------------------------------------------
Plan hash value: 728617846
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 22 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| TMP_TEST_COUNT | 9756 | 22 (0)| 00:00:01 |
-----------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
4 recursive calls
0 db block gets
131 consistent gets
0 physical reads
0 redo size
527 bytes sent via SQL*Net to client
520 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed从上面的执行计划得出,COUNT(1)和COUNT(*)的花费其实是一致的,成本(Cost)都是22。
3.有索引的情况下,COUNT(1)与COUNT(*)的比较
在有非空索引或者主键的情况下,Oracle执行COUNT运算时会大大地提高性能。这里需要注意的点是索引列不能为空(NULL),因为在Oracle当中,聚合函数是不对NULL值进行运算。也就是说当索引有NULL值,那么它统计出来的就不是表中的记录总条数。所以当索引中有NULL值,那么Oracle就不会走索引扫描。那么问题来了,在执行COUNT(1)或者COUNT(*)时,Oracle会不会走索引?
首先在表中创建主键,代码如下(示例):
ALTER TABLE TMP_TEST_COUNT ADD CONSTRAINT PK_TMP_TEST_COUNT PRIMARY KEY (ID);
根据上面的方式,获取执行计划:
SQL> SELECT COUNT(1) FROM TMP_TEST_COUNT;
已用时间: 00: 00: 00.09
执行计划
----------------------------------------------------------
Plan hash value: 251659311
--------------------------------------------------------------------------------
---
| Id | Operation | Name | Rows | Cost (%CPU)| Time
|
--------------------------------------------------------------------------------
---
| 0 | SELECT STATEMENT | | 1 | 9 (0)| 00:00:0
1 |
| 1 | SORT AGGREGATE | | 1 | |
|
| 2 | INDEX FAST FULL SCAN| PK_TMP_TEST_COUNT | 9756 | 9 (0)| 00:00:0
1 |
--------------------------------------------------------------------------------
---
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
218 recursive calls
6 db block gets
117 consistent gets
20 physical reads
0 redo size
527 bytes sent via SQL*Net to client
520 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
6 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> SELECT COUNT(*) FROM TMP_TEST_COUNT;
已用时间: 00: 00: 00.01
执行计划
----------------------------------------------------------
Plan hash value: 251659311
--------------------------------------------------------------------------------
---
| Id | Operation | Name | Rows | Cost (%CPU)| Time
|
--------------------------------------------------------------------------------
---
| 0 | SELECT STATEMENT | | 1 | 9 (0)| 00:00:0
1 |
| 1 | SORT AGGREGATE | | 1 | |
|
| 2 | INDEX FAST FULL SCAN| PK_TMP_TEST_COUNT | 9756 | 9 (0)| 00:00:0
1 |
--------------------------------------------------------------------------------
---
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
4 recursive calls
0 db block gets
86 consistent gets
0 physical reads
0 redo size
527 bytes sent via SQL*Net to client
520 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed从执行计划来看,COUNT(1)与COUNT(*)的成本是一样的,而且都是走了索引!(统计信息不同,是因为Oracle缓存的原因。执行两遍就能发现其实是一样的)。
总结
经过上面的实验发现,其实COUNT(1)与COUNT(*)是一致的。而且在有符合条件的索引下,它们都会走索引。但是这两个语句在真实的环境中是很少被运用。因为实际业务中,很少会去判断表中有多少条记录。常常是用COUNT来判断表中是否有记录。在这种业务需求下,单单上面的COUNT(1)或者COUNT(*)都不太好,特别是当表中数据量非常大的时候,执行效率非常慢。需要通过以下的代码进行改写:
SELECT COUNT(*) FROM TMP_TEST_COUNT WHERE ROWNUM = 1;

















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









