






本文档为自留学习型文档,仅供个人使用,主要环境是nodejs
简单介绍
- huggingface是全球开源模型网站,需要魔法访问,模型运行环境是python和nodejs
- 国内平替是【魔塔社区】,但是魔塔社区起步较晚,模型数量相对偏少,模型运行环境是python,nodejs较少
使用说明
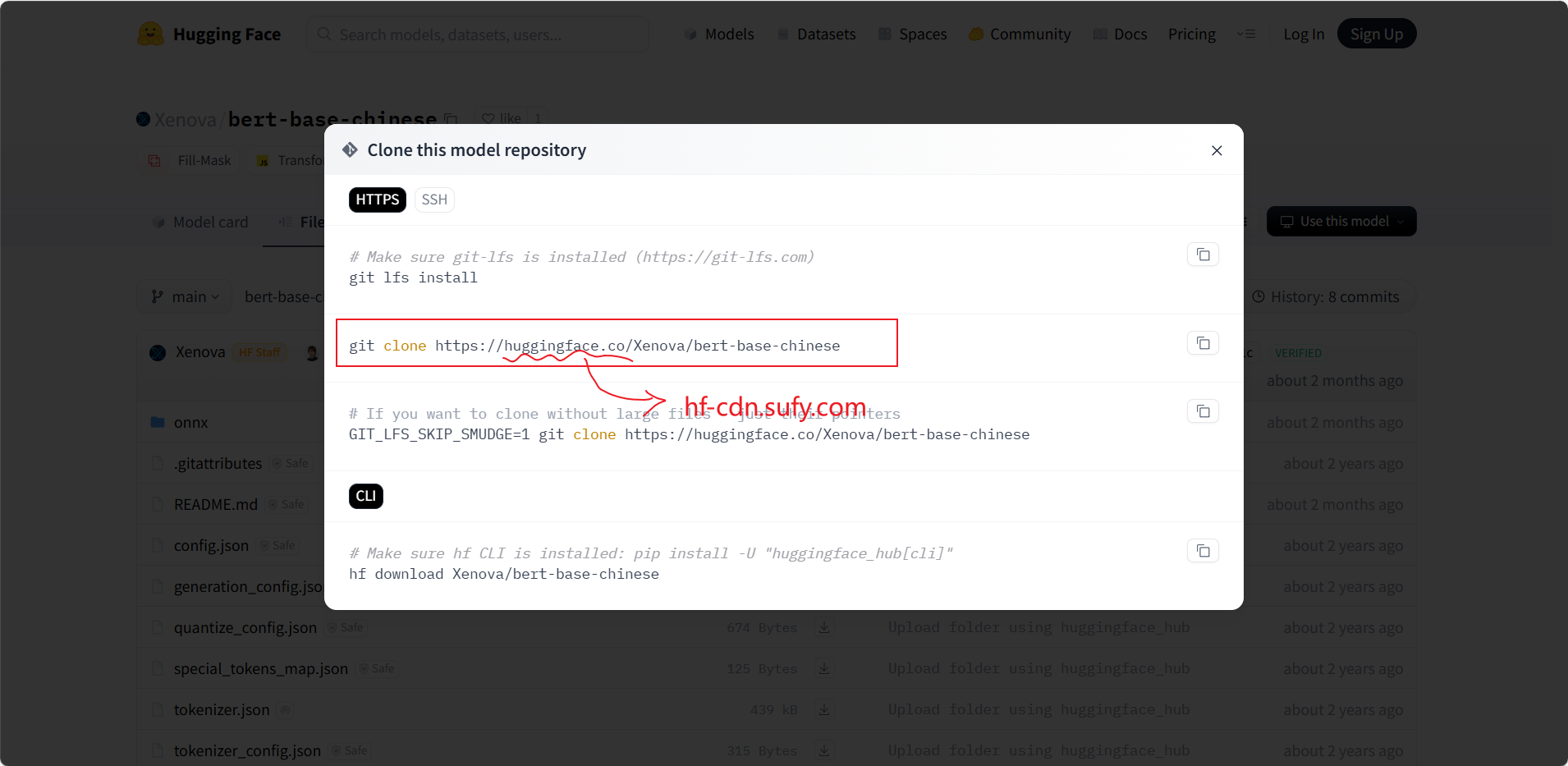
- 国内下载模型缓慢,建议使用国内镜像git clone克隆模型,然后访问本地模型
- 介绍部分看别的文档,我直接说怎么用
-
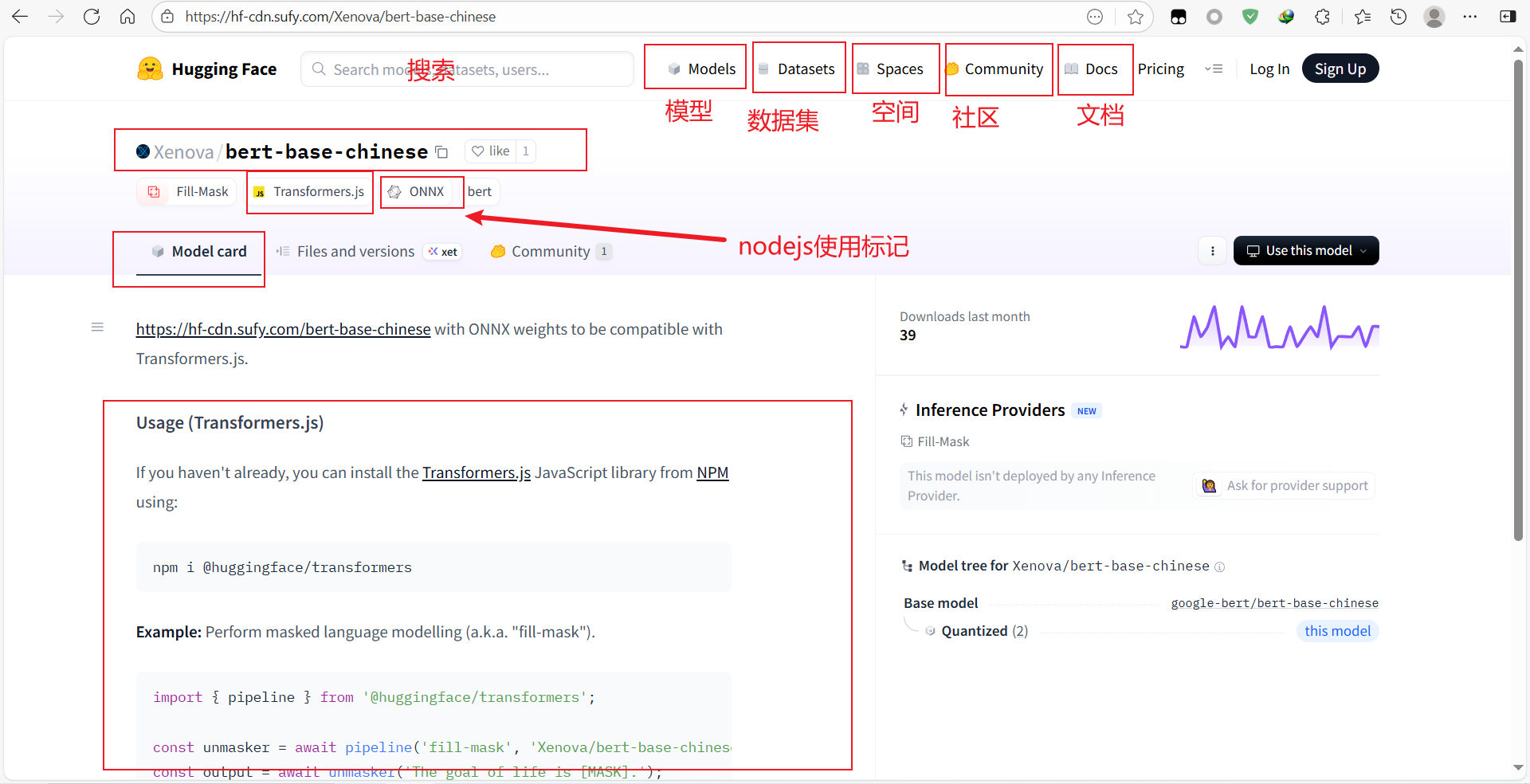
搜索要用的模型,然后模型标签有【Transformers.js】【ONNX】那么大概率就是可以在node环境中使用
-
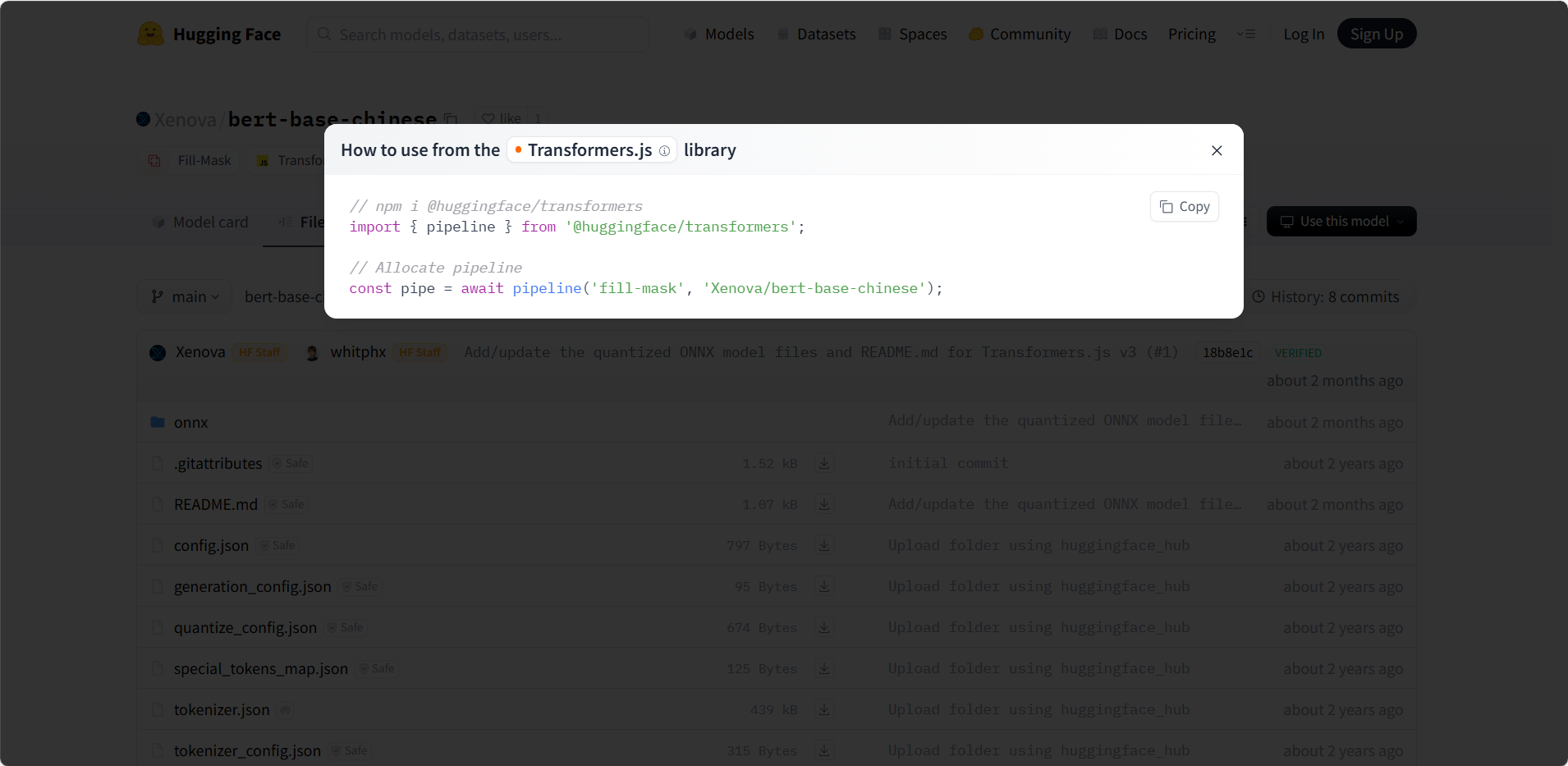
点开,默认显示Model Card(readme),这里有基础介绍和使用指南,如截图1,就写了需要下载 @huggingface/transformers,然后引入直接用
-
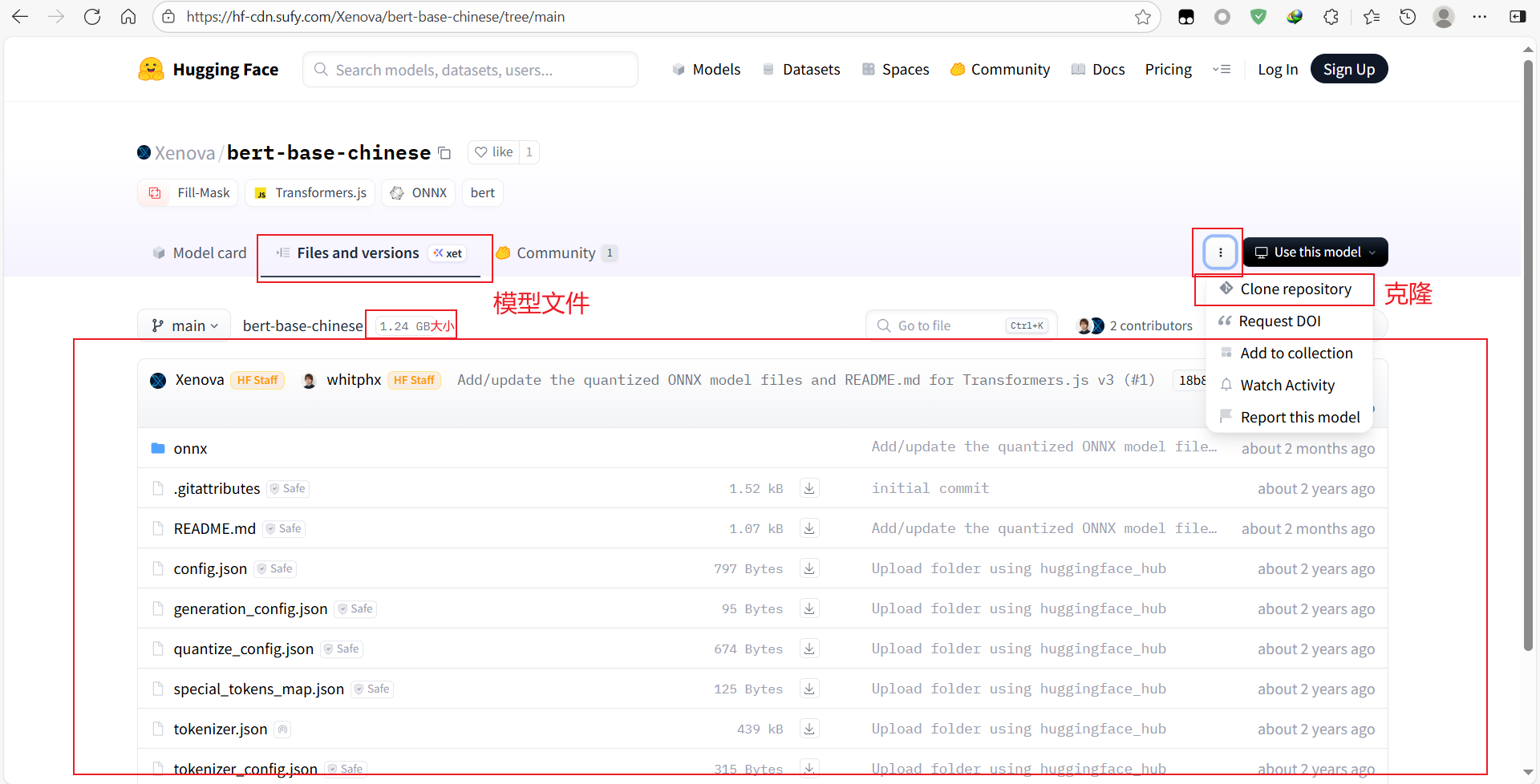
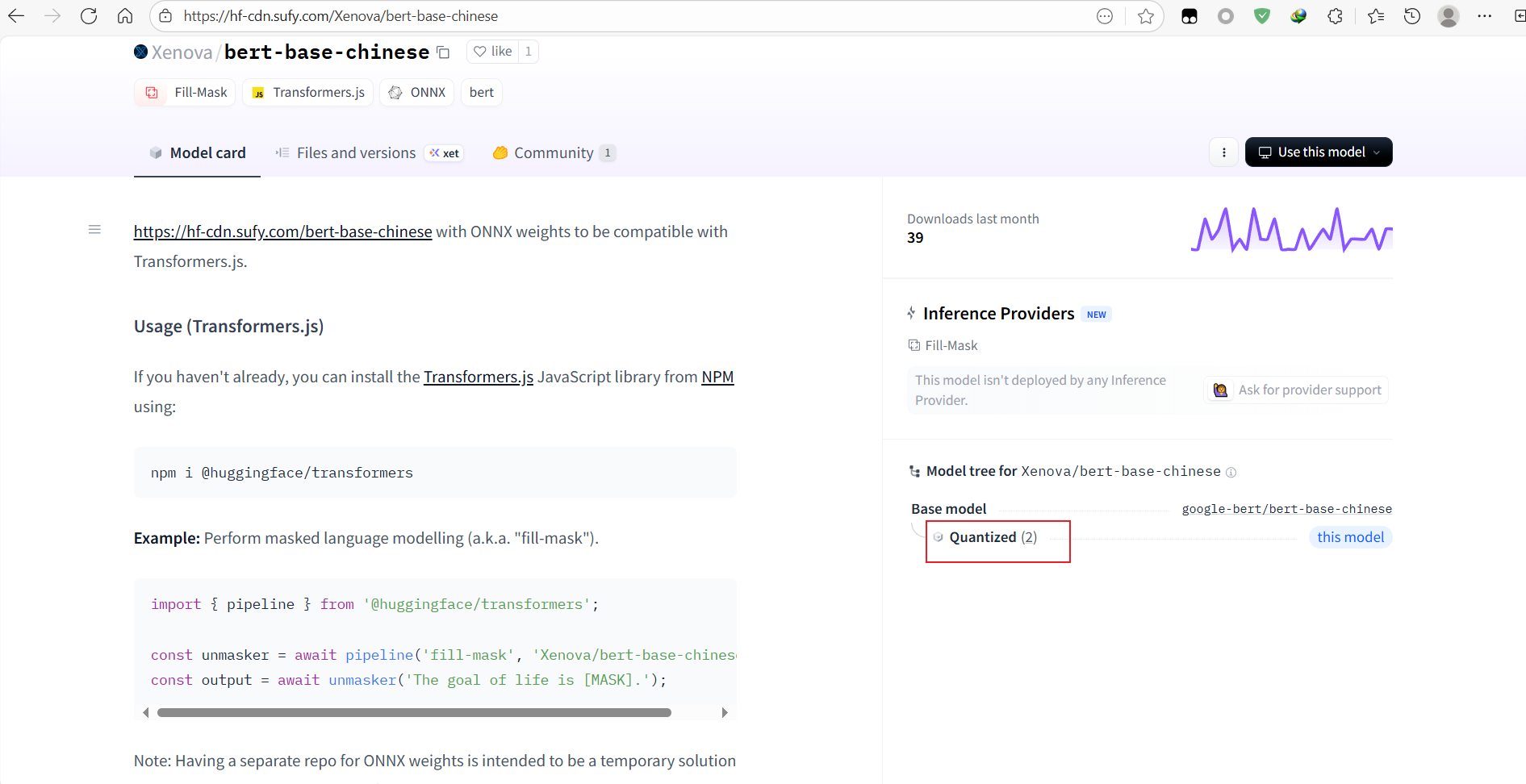
第二个Files and versions,显示模型版本
-
第三个Communit,是社区,也就是这个模型使用反馈的问题,和github的issue一样
-
第四个右边三个点,里面有克隆地址,把域名换成国内镜像站,就可以快速克隆了
-
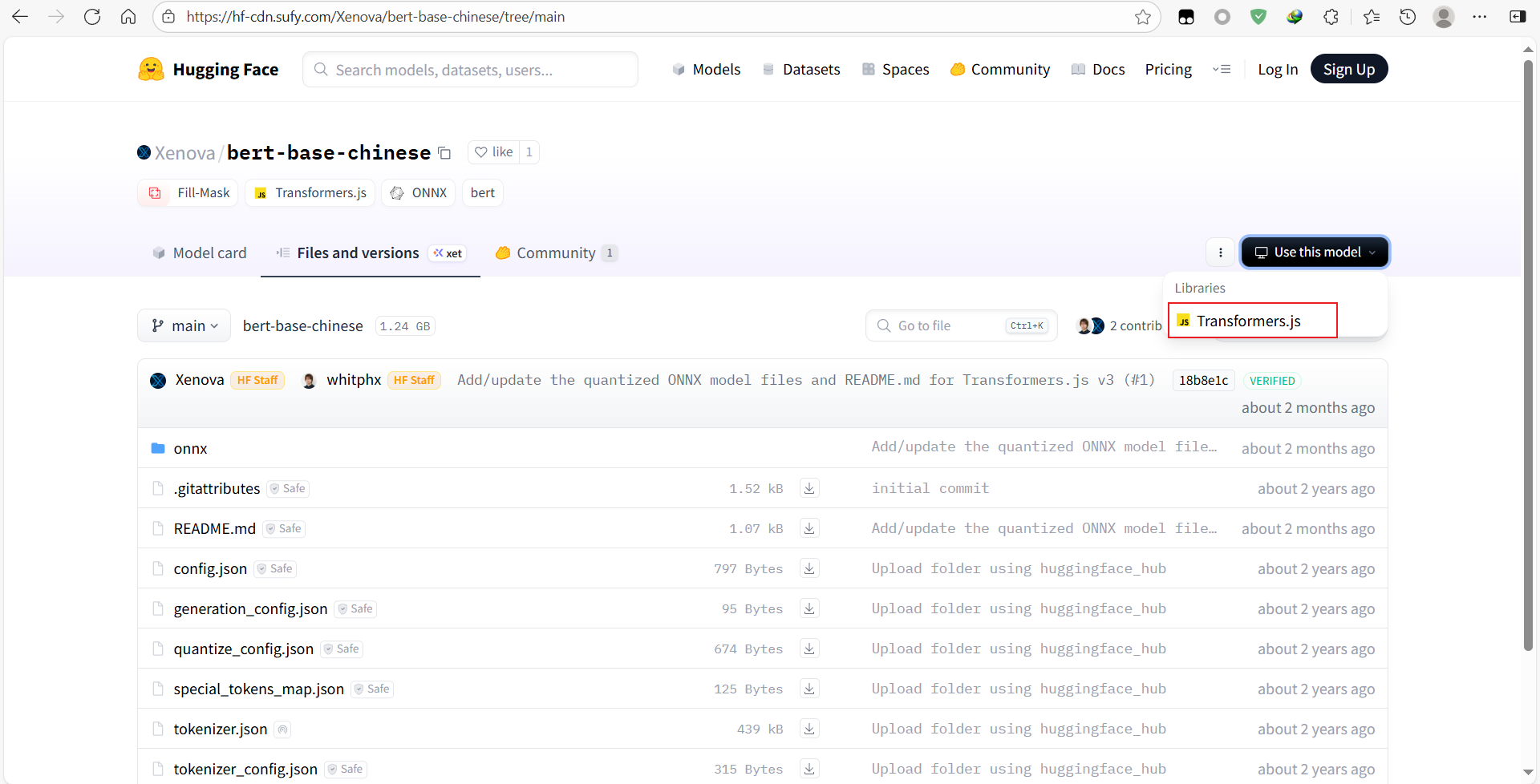
use this model,是使用这个模型,会给出在不同环境下的使用案例,Transformers.js是node环境下的使用案例
-
在Model Card下方,有Model tree,里面的Quantized可以找到当前模型的量化,也许这个模型没有nodejs环境,但是关联的量化里有
-
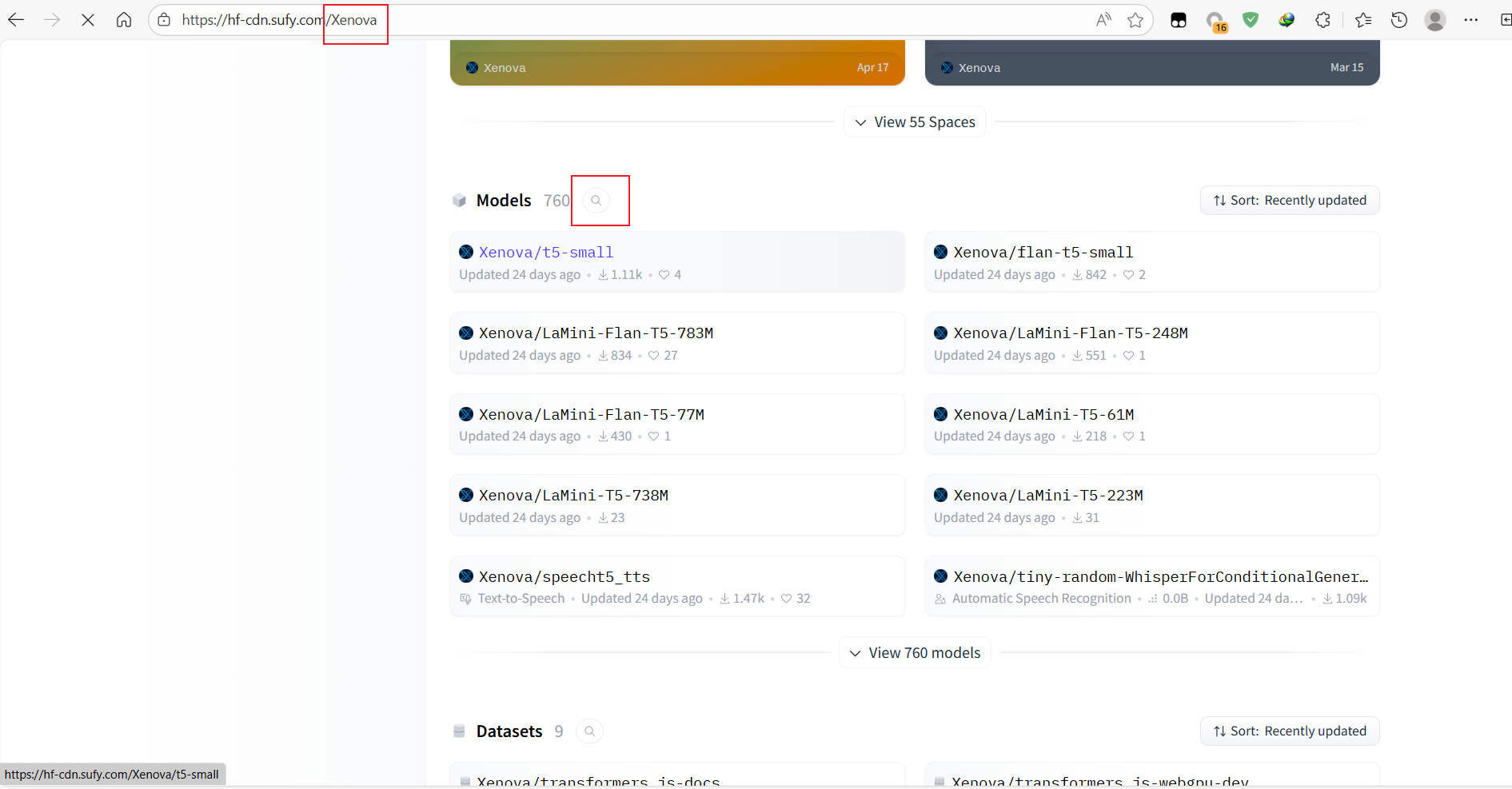
另外,Xenova用户对大量的模型进行了nodejs量化,如果实在找不到,可以去Xenova的首页,在model搜索碰碰运气,或者尝试自己将python处理为nodejs
-
下面给出一个具体的demo
-
/*
* Hugging Face Transformers 基础案例:文本情感分析
* 安装依赖:npm install @huggingface/transformers
*/
const { pipeline } = require('@huggingface/transformers');
const fs = require('fs');
const path = require('path');
// 最小化情感分析实现
async function main() {
try {
console.log('本地模型情感分析测试\n');
// 1. 配置本地模型路径(替换为你的实际路径)
const localModelPath = path.join(__dirname, './local-models/distilbert-base-uncased-finetuned-sst-2-english');
// 检查模型目录是否存在
if (!fs.existsSync(localModelPath)) {
throw new Error(`模型目录不存在: ${localModelPath}`);
}
// 3. 加载本地模型
console.log(`从本地加载模型: ${localModelPath}`);
const analyzer = await pipeline(
'sentiment-analysis',
localModelPath
);
// 4. 测试
// const text = "I love using Hugging Face Transformers! It's amazing.";
// const text = "I hate waiting for models! It's so frustrating.";
const text = "The relationship had been important to me and its loss left me feeling sad and empt.";
const result = await analyzer(text);
console.log(`文本: ${text}`);
console.log(`结果: ${result[0].label} (可信度: ${(result[0].score * 100).toFixed(1)}%)`);
} catch (error) {
console.error('错误:', error.message);
}
}
main();
/*
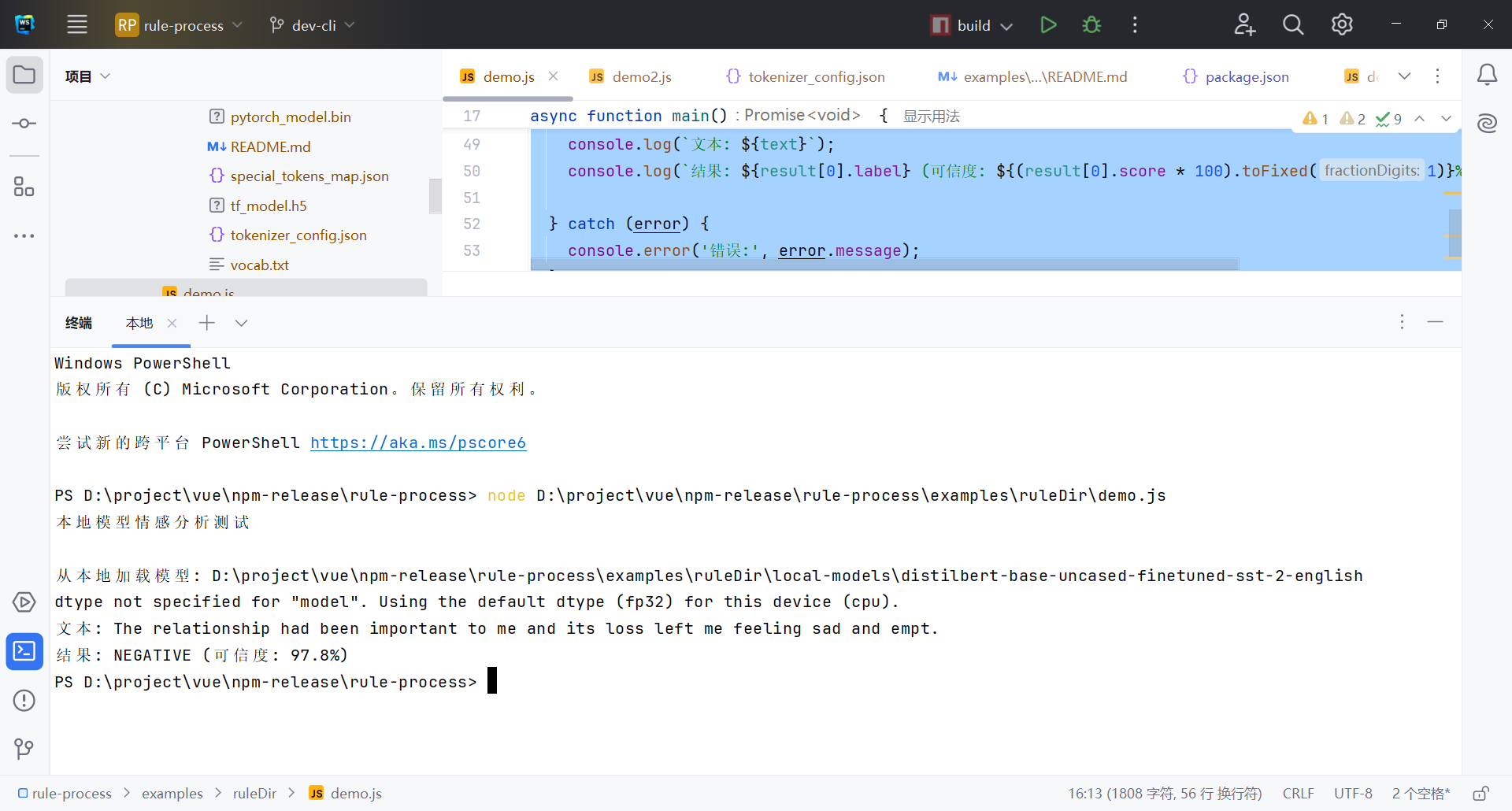
PS D:\project\vue\npm-release\rule-process> node D:\project\vue\npm-release\rule-process\examples\ruleDir\demo.js
本地模型情感分析测试
从本地加载模型: D:\project\vue\npm-release\rule-process\examples\ruleDir\local-models\distilbert-base-uncased-finetuned-sst-2-english
dtype not specified for "model". Using the default dtype (fp32) for this device (cpu).
文本: The relationship had been important to me and its loss left me feeling sad and empt.
结果: NEGATIVE (可信度: 97.8%)
*/
对使用说明的配图


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









