







 本文通过实战案例解析了Scrapy框架中POST请求的注意事项,特别是如何处理Content-Length字段导致的问题,对比requests与Scrapy的不同之处。
本文通过实战案例解析了Scrapy框架中POST请求的注意事项,特别是如何处理Content-Length字段导致的问题,对比requests与Scrapy的不同之处。
Scrapy框架第一发送POST请求遇到的小坑
前言: 爬取一个数据开发平台 悦采 网, 爬取上面的招标_采购信息。
小坑:requests能获取到内容,改成scrapy却
不能获取到内容,而且请求信息之类的条件都一摸一样?
解决方式:
问题就出在headers上面:去掉 headers里面的 Content-Length 这一栏
具体原因如下:
https://stackoverflow.com/questions/42248903/scrapy-post-request-not-working-400-bad-request
首先思路,分析网站,找规律,我感觉这个是重要的一步。
1.先看看网页结构,找规律。
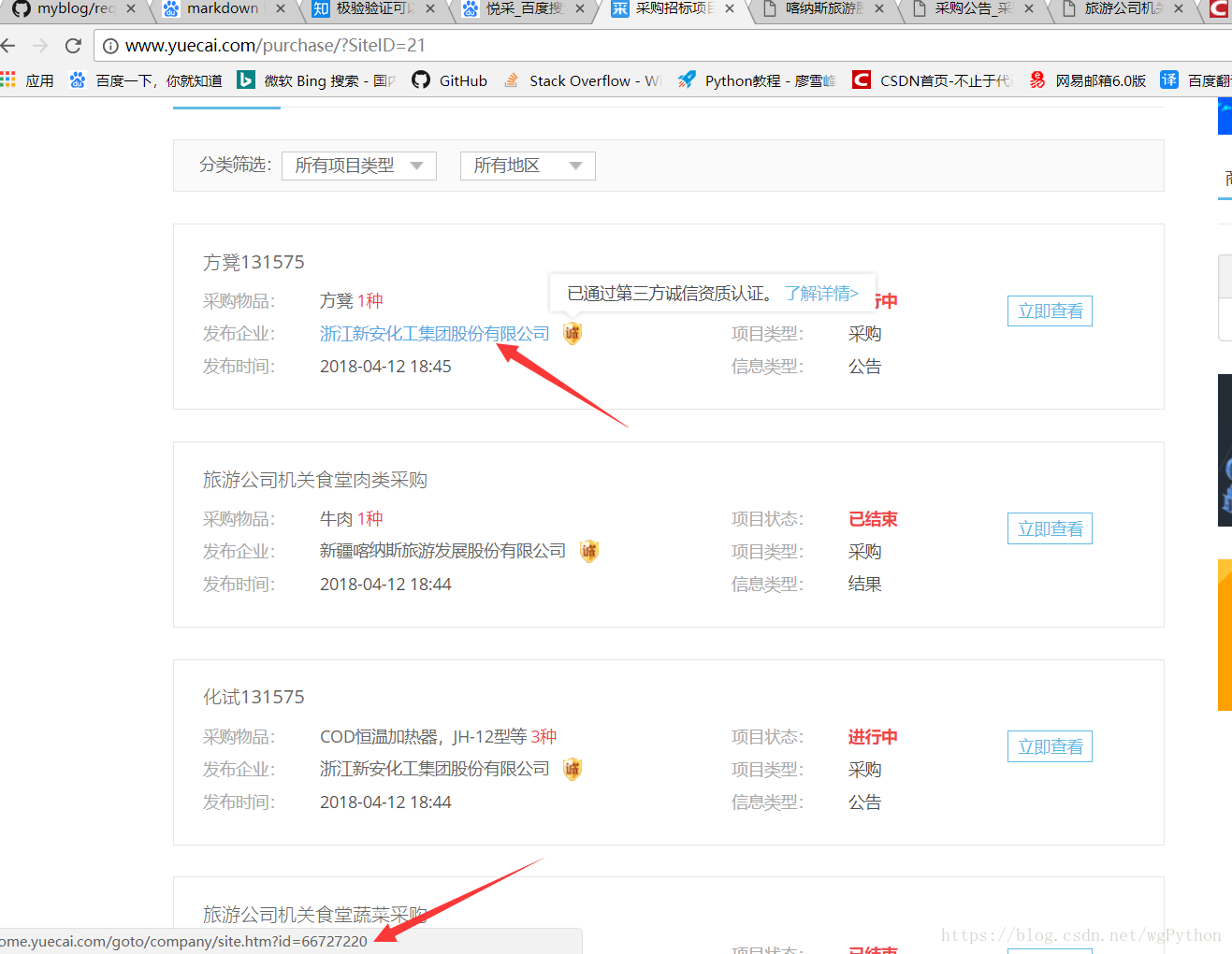
我们发现只要找到这个url然后请求,进入详细页面,就找到想要的数据了。
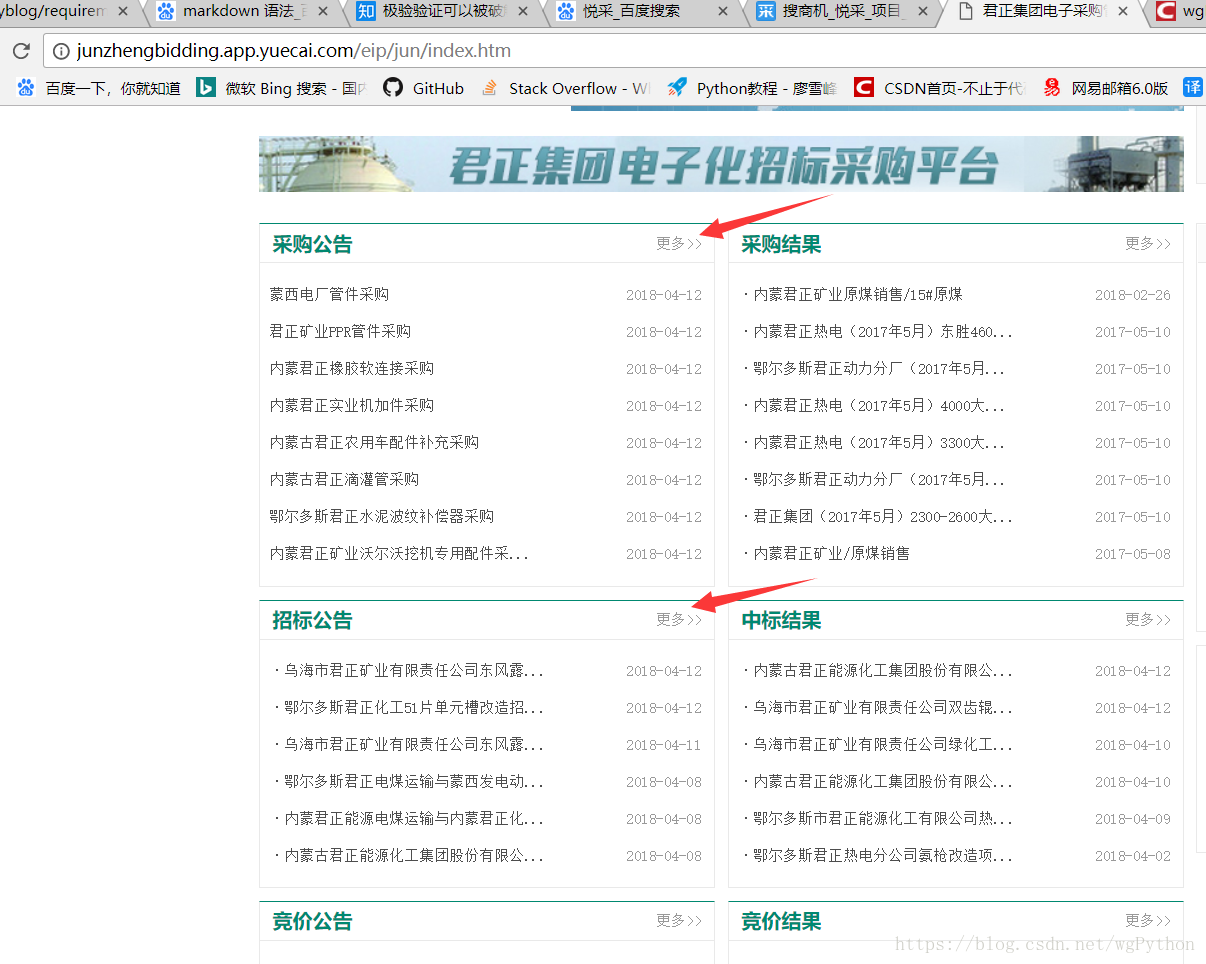
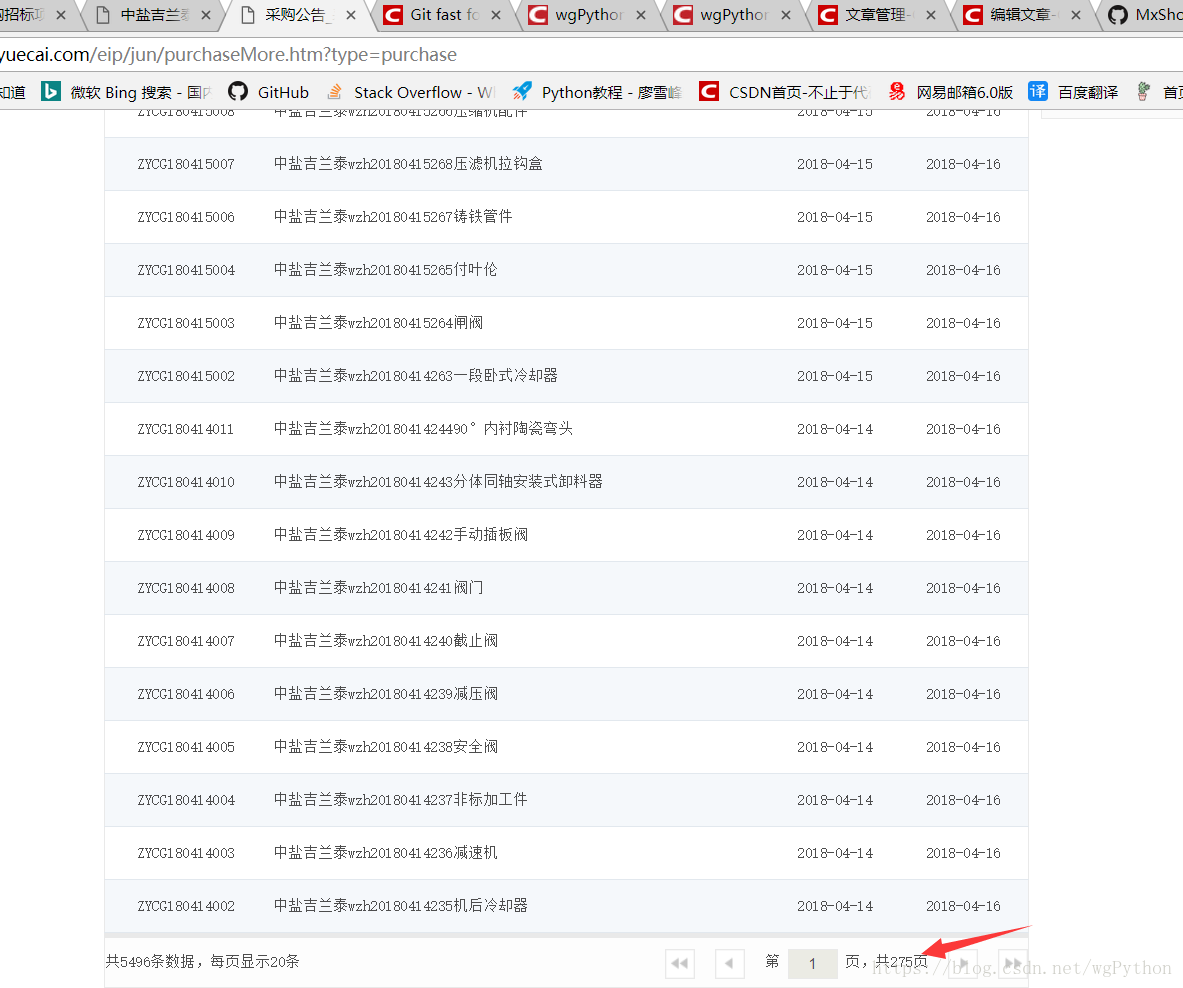
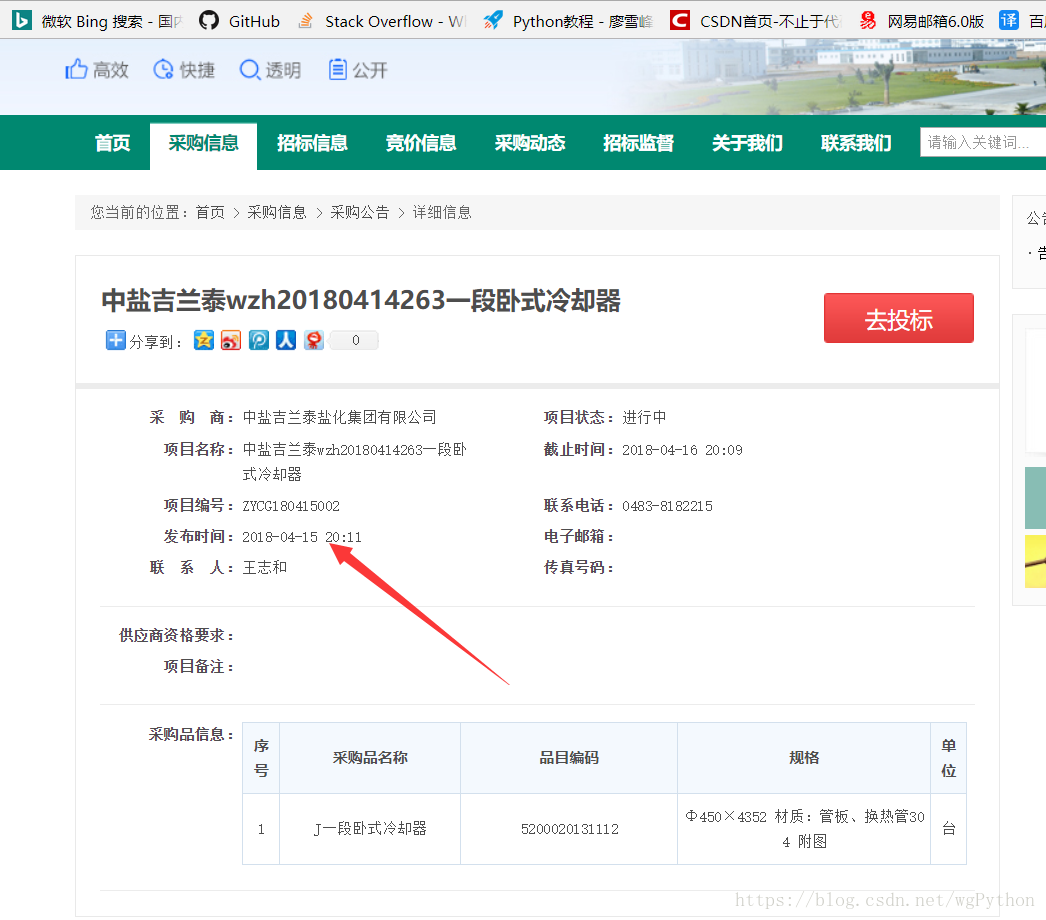
开始找规律爬取数据
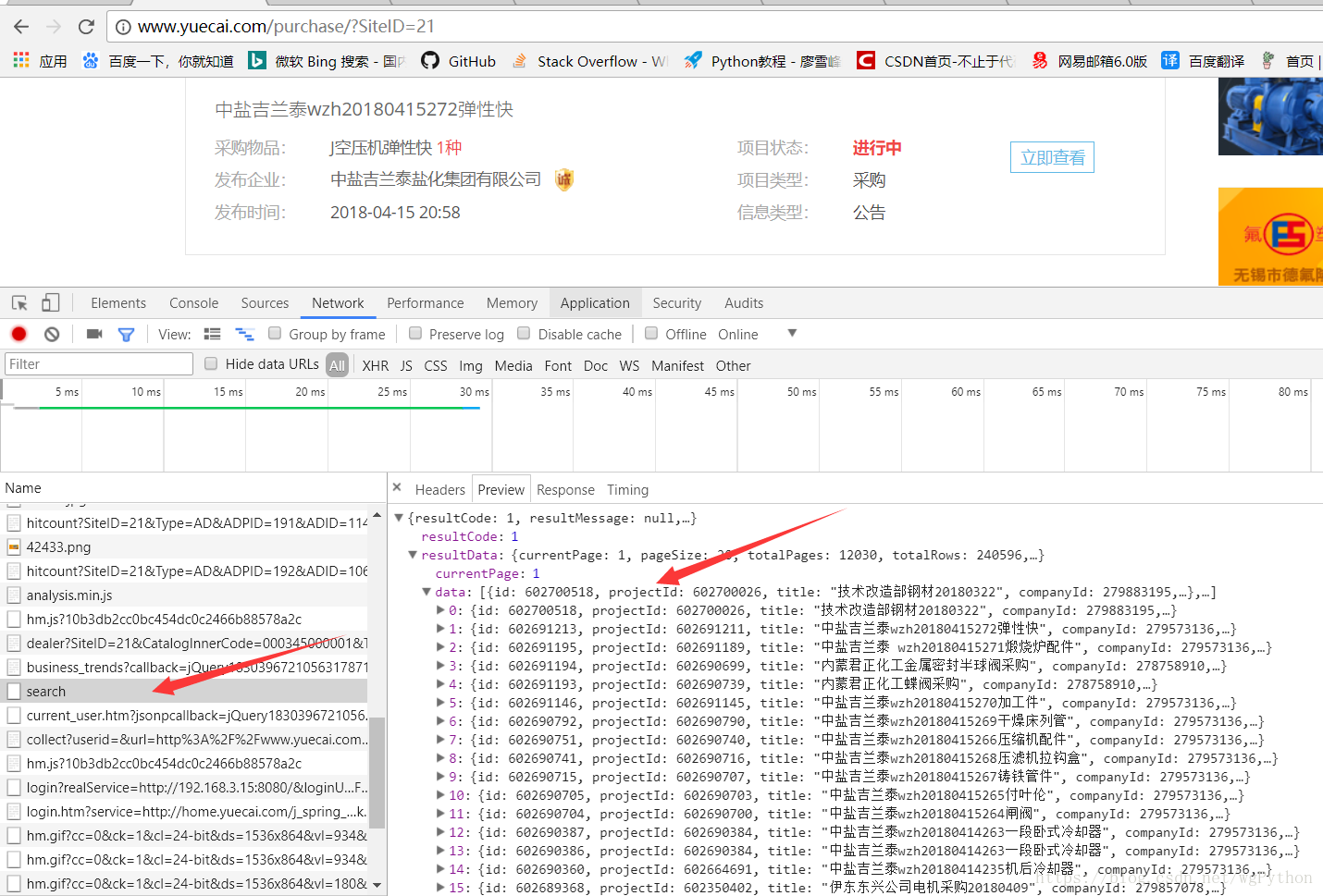
我们找到了别人的api接口,里面有公司的一些相关信息,可以拼接id访问每个公司url
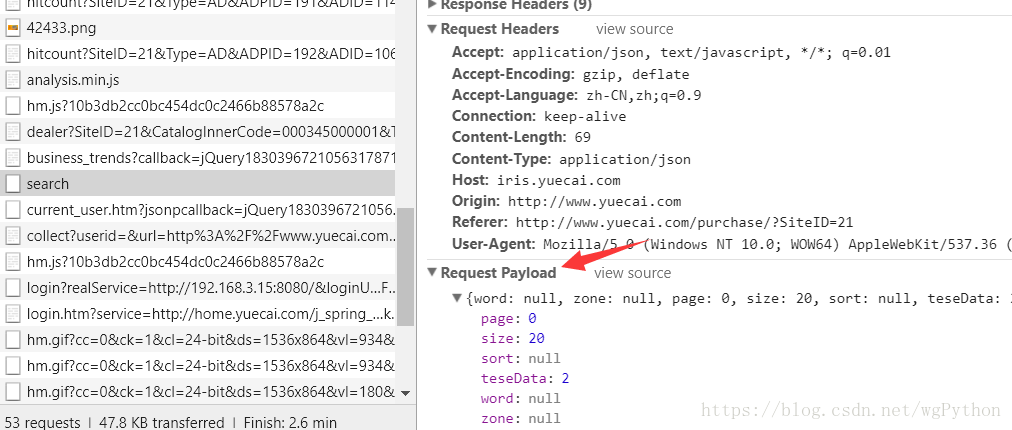
但是这里的url是一个post请求,而且需要Payload,我一开始没注意, 就当成普通的POST请求去使用,一直没有成功报400
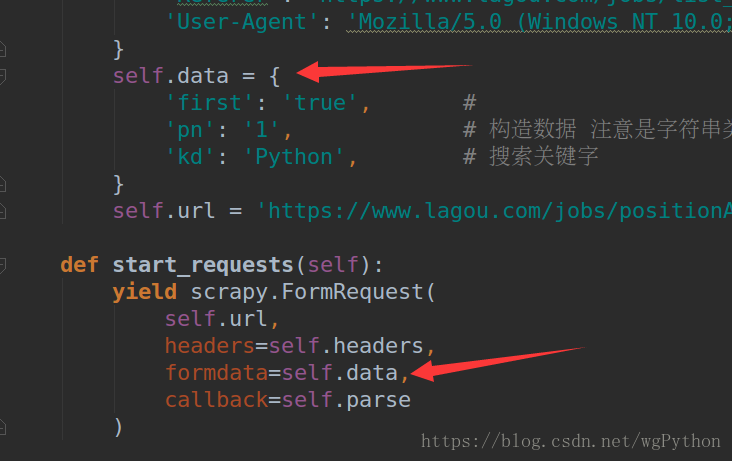
这是我爬取拉钩招聘信息的时候模拟POST请求发送的数据,也成功了, 我琢磨了好久为什么,才发现POST请求 需要的是Payload 有效载荷
我百度发现要把数据转换为json数据发送
import requests
import json
class YuecaiSpider(object):
def __init__(self):
self.headers = {
'Content-Type': 'application/json',
'Host': 'iris.yuecai.com',
'Origin': 'http://www.yuecai.com',
# 'Referer': 'http://www.yuecai.com/purchase/?SiteID=21',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
}
self.data = {
"page": 0,
"size": 20,
"sort": None,
"teseData": 2,
"word": None,
"zone": None,
}
def start_requests(self):
url = "http://iris.yuecai.com/iris/v1/purchase/search"
res = requests.post(url, headers=self.headers, data=json.dumps(self.data)) # 这里要转换为json数据
print(res.status_code)
print(res.text)
if __name__ == '__main__':
yuecai = YuecaiSpider()
yuecai.start_requests()
- 用requests写测试脚本的时候,一点问题没有,但是我改成scrapy后,一直没有数据。我不知道是为什么??
import scrapy
import json
class YuecaiSpider(scrapy.Spider):
name = 'yuecai'
allowed_domains = ['yuecai.com']
start_urls = ['http://iris.yuecai.com/iris/v1/purchase/search']
site_name = '悦采网数据平台'
version = '1.0'
def __init__(self):
super(YuecaiSpider, self).__init__()
self.headers = {
# 'Accept': 'application/json, text/javascript, */*; q=0.01',
# 'Accept-Encoding': 'gzip, deflate',
# 'Accept-Language': 'zh-CN,zh;q=0.9',
# 'Connection': 'keep - alive',
# 'Content - Length': '69',
'Content-Type': 'application/json',
'Host': 'iris.yuecai.com',
'Origin': 'http://www.yuecai.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
}
self.data = {
'word': None, # 'NULL'
'zone': None, # 注意这边特别坑的 有的就是需要'null'这种数据
'page': '1', # 参数该用字符用字符
'size': '20', #
'sort': None,
'teseData': '2',
}
def start_requests(self):
url = "http://iris.yuecai.com/iris/v1/purchase/search"
yield scrapy.Request(
url,
method="POST",
headers=self.headers,
body=json.dumps(self.data), # 这边数据也是要转换成json数据
dont_filter=True,
callback=self.parse,
)
def parse(self, response):
print("*" * 50)
print(response.status)
print(response.text)
print("*" * 50)
Scrapy 关于headers参数注意
# 有时候明明 requests 或者 postman 请求都是正常的, 但是改成scrapy就不行了,
# 原因往往出在headers里面,我不确定是不是scrapy做了过滤之类的操作,但是把不必要的参数注释就好了
# 写爬虫的话一定要对http协议有了解,知道headers里面那些参数什么意思,
# 比如referer (其实历史拼错的单词) 意思是从那个链接跳转来的,常用于图片等媒体资源防盗链,推荐一本名叫《图解http》的书
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
# 'Accept-Encoding': 'gzip, deflate', # 注释
# 'Accept-Language': 'zh-CN,zh;q=0.9', # 注释
# 'Connection': 'keep - alive', # 注释
# 'Content - Length': '69', # 务必要注释掉
'Content-Type': 'application/json',
'Host': 'iris.yuecai.com',
'Origin': 'http://www.yuecai.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
}
把上面的请求的参数加了引号, 需要’null’的改成None(但是有的网站POST请求参数就是’null’)
好吧看看我运行的结果把。
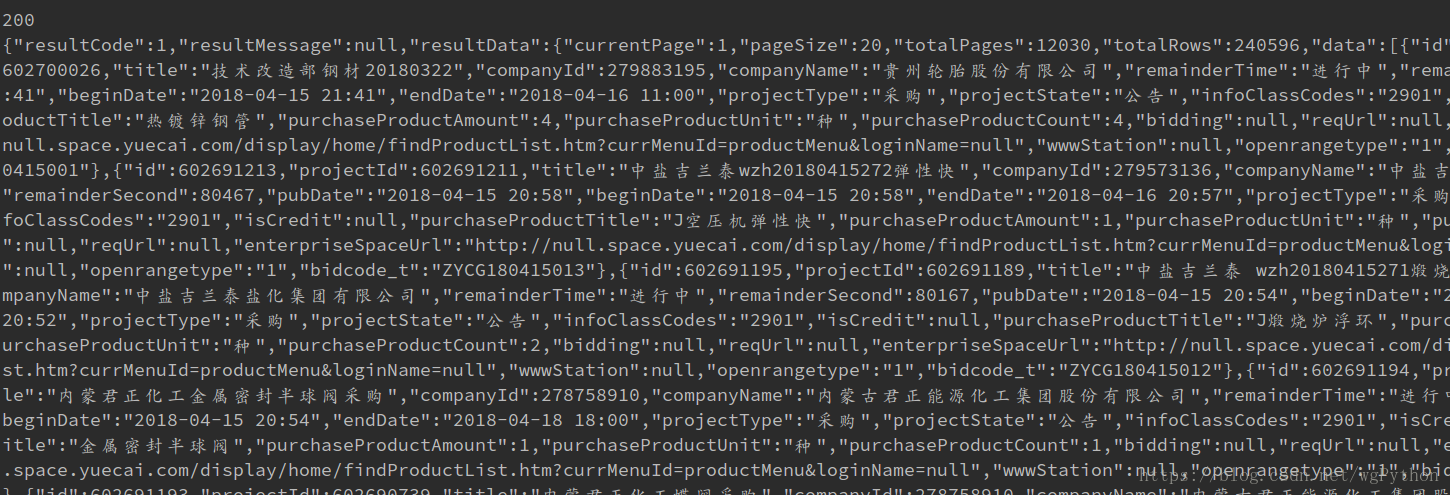
2018/11/29 更新
评论那位小哥! 我在我电脑上测试 没有问题, 由于评论下面贴代码,格式很乱,我就贴在文章里面了,效果图如下。
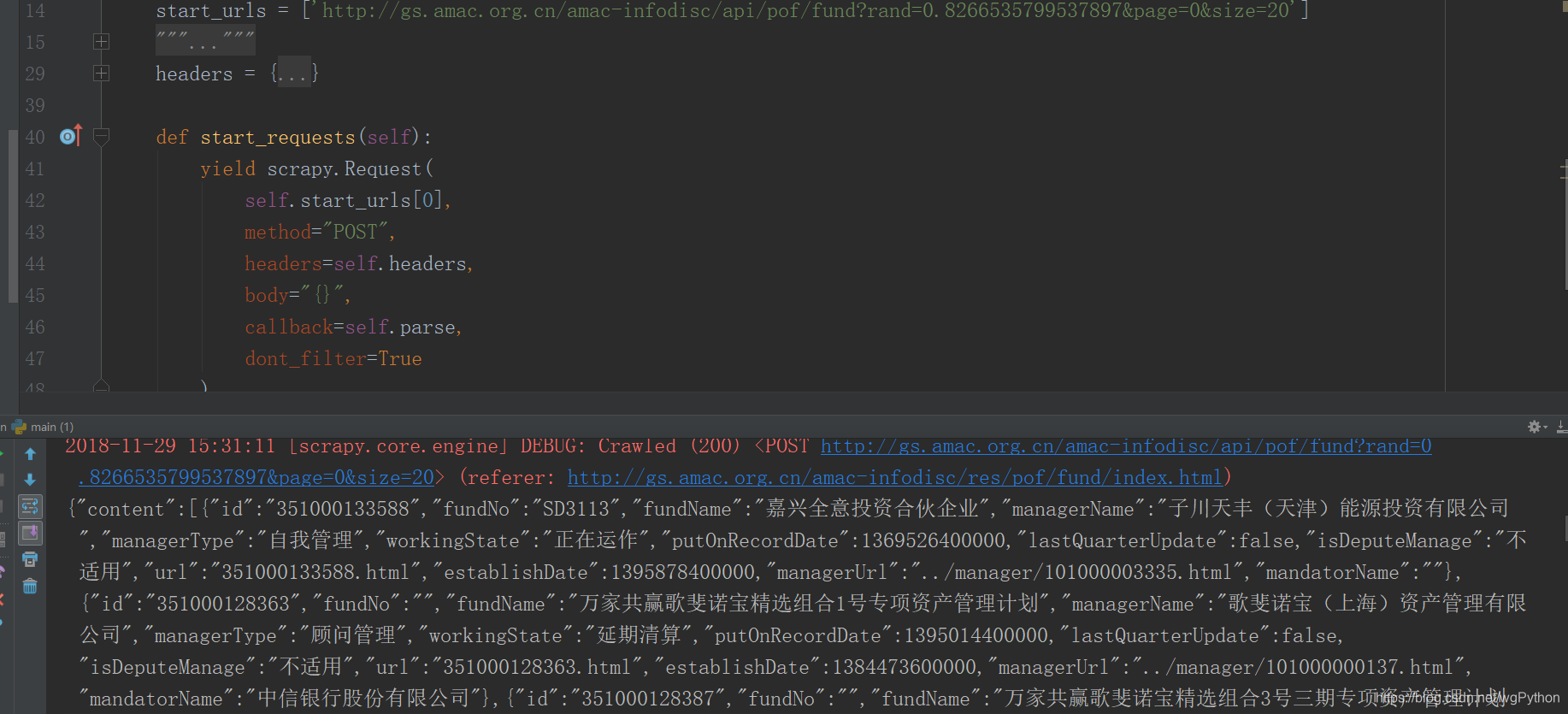
测试代码如下:
# -*- coding:utf-8 -*-
# @Author: wg
# @Time: 2018/11/29 15:02
# @Desc:
"""
"""
import scrapy
class TestCnSpider(scrapy.Spider):
name = 'test_cn'
allowed_domains = ['org.cn']
start_urls = ['http://gs.amac.org.cn/amac-infodisc/api/pof/fund?rand=0.8266535799537897&page=0&size=20']
"""
POST http://gs.amac.org.cn/amac-infodisc/api/pof/fund?rand=0.4768735209349304&page=0&size=20 HTTP/1.1
Host: gs.amac.org.cn
Proxy-Connection: keep-alive
Content-Length: 2
Accept: application/json, text/javascript, */*; q=0.01
Origin: http://gs.amac.org.cn
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36
Content-Type: application/json
Referer: http://gs.amac.org.cn/amac-infodisc/res/pof/fund/index.html
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
"""
headers = {
"Host": "gs.amac.org.cn",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Origin": "http://gs.amac.org.cn",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36",
"Content-Type": "application/json",
"Referer": "http://gs.amac.org.cn/amac-infodisc/res/pof/fund/index.html",
"Accept-Language": "zh-CN,zh;q=0.9",
}
def start_requests(self):
yield scrapy.Request(
self.start_urls[0],
method="POST",
headers=self.headers,
body="{}",
callback=self.parse,
dont_filter=True
)
def parse(self, response):
print(response.text)

















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









