



颜色空间
cv2.imread 读取的图片默认为BGR模式
RGB
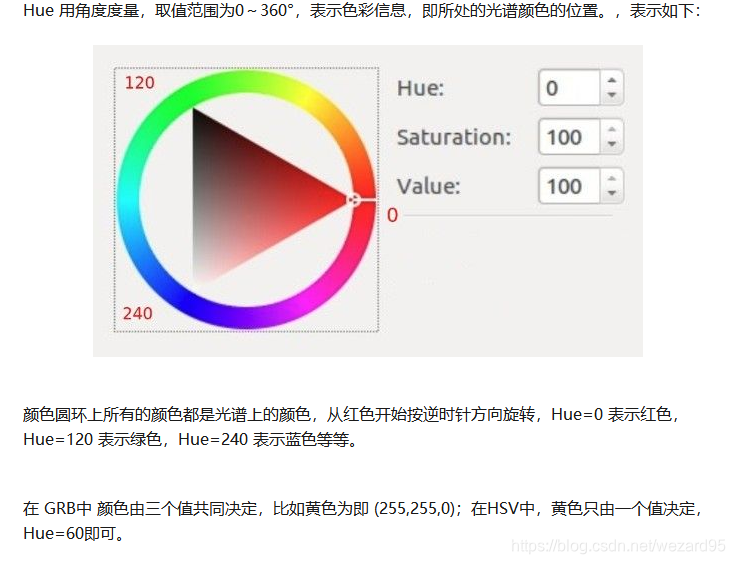
HSV:hue (色调,色相),saturation(饱和度), value (明度)
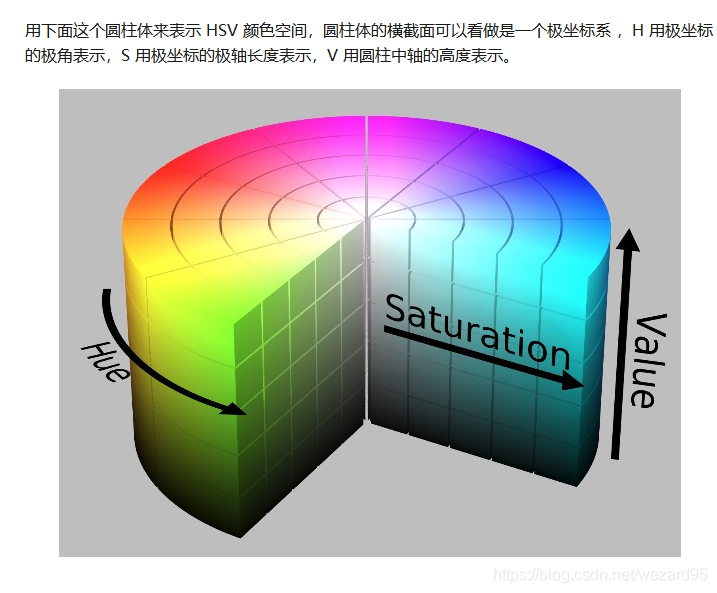
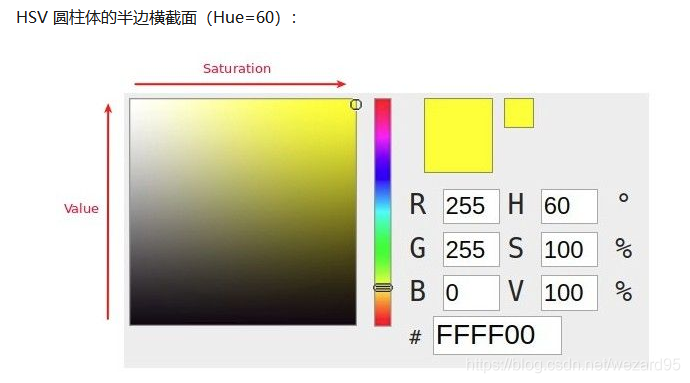
其中水平方向表示饱和度,饱和度表示颜色接近光谱色的程度。饱和度越高,说明颜色越深,越接近光谱色饱和度越低,说明颜色越浅,越接近白色。饱和度为0表示纯白色。取值范围为0~100%,值越大,颜色越饱和。
竖直方向表示明度,决定颜色空间中颜色的明暗程度,明度越高,表示颜色越明亮,范围是 0-100%。明度为0表示纯黑色(此时颜色最暗)。
可以通俗理解为:
在Hue一定的情况下,饱和度减小,就是往光谱色中添加白色,光谱色所占的比例也在减小,饱和度减为0,表示光谱色所占的比例为零,导致整个颜色呈现白色。
明度减小,就是往光谱色中添加黑色,光谱色所占的比例也在减小,明度减为0,表示光谱色所占的比例为零,导致整个颜色呈现黑色。
HSV 对用户来说是一种比较直观的颜色模型。我们可以很轻松地得到单一颜色,即指定颜色角H,并让V=S=1,然后通过向其中加入黑色和白色来得到我们需要的颜色。增加黑色可以减小V而S不变,同样增加白色可以减小S而V不变。例如,要得到深蓝色,V=0.4 S=1 H=240度。要得到浅蓝色,V=1 S=0.4 H=240度。
HSV 的拉伸对比度增强就是对 S 和 V 两个分量进行归一化(min-max normalize)即可,H 保持不变。
RGB颜色空间更加面向于工业,而HSV更加面向于用户,大多数做图像识别这一块的都会运用HSV颜色空间,因为HSV颜色空间表达起来更加直观!
HLS:hue(色相),lightness(亮度),saturation(饱和度)
HLS 中的 L 分量为亮度,亮度为100,表示白色,亮度为0,表示黑色;HSV 中的 V 分量为明度,明度为100,表示光谱色,明度为0,表示黑色。
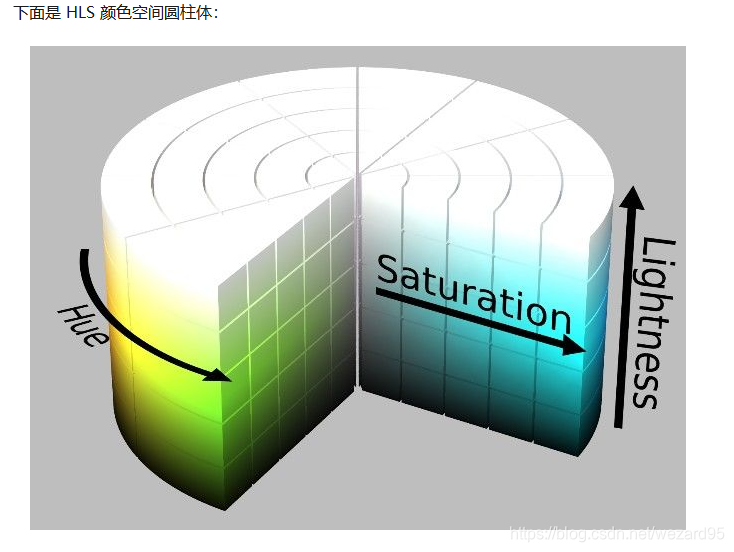
提取白色物体时,使用 HLS 更方便,因为 HSV 中的Hue里没有白色,白色需要由S和V共同决定(S=0, V=100)。而在 HLS 中,白色仅由亮度L一个分量决定。所以检测白色时使用 HSL 颜色空间更准确。
图片频域fft分析
import numpy as np
import matplotlib.pyplot as plt
import cv2
%matplotlib inline
# Read in the images
image_stripes = cv2.imread('images/stripes.jpg')
# Change color to RGB (from BGR)
image_stripes = cv2.cvtColor(image_stripes, cv2.COLOR_BGR2RGB)
# convert to grayscale to focus on the intensity patterns in the image
gray_stripes = cv2.cvtColor(image_stripes, cv2.COLOR_RGB2GRAY)
# perform a fast fourier transform and create a scaled, frequency transform image
def ft_image(norm_image):
'''This function takes in a normalized, grayscale image
and returns a frequency spectrum transform of that image. '''
f = np.fft.fft2(norm_image)
fshift = np.fft.fftshift(f)
frequency_tx = 20*np.log(np.abs(fshift)) #(换算成db)
return frequency_tx

Notice that this image has components of all frequencies. You can see a bright spot in the center of the transform image, which tells us that a large portion of the image is low-frequency; this makes sense since the body of the birds and background are solid colors. The transform image also tells us that there are two dominating directions for these frequencies; vertical edges (from the edges of birds) are represented by a horizontal line passing through the center of the frequency transform image, and horizontal edges (from the branch and tops of the birds’ heads) are represented by a vertical line passing through the center.
高通滤波器
主要用于边缘检测,图像先处理为grey,根据强度变化,放大图片的高频部分,低频部分置为黑色,
卷积核,矩阵元素和为0,否则滤波后图像亮度会改变
高通滤波器会强化噪声,一般需要先使用低通滤波器降噪
sobel滤波器
检测垂直边缘,即x和y轴方向的强度突变
np.array([[-1, 0, 1],
[-2, 0, 2],
[-1, 0,1]])
cv2.filter2D(grayscale_input_image,datadepth,kernal)
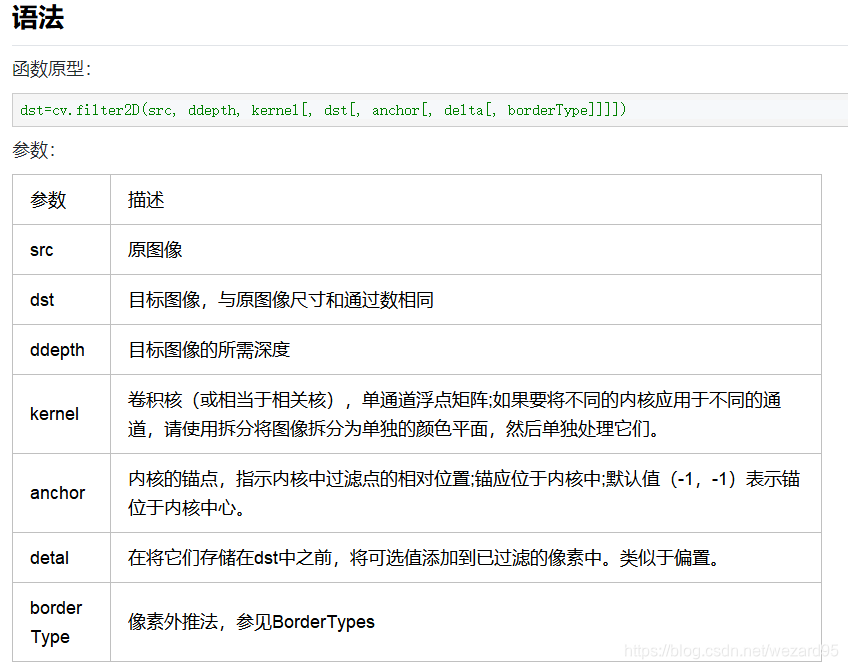
默认ddepth为-1,表示图像输入和输出一致
低通滤波器
取均值,卷积核矩阵和为1,保留图像亮度
高斯模糊(GaussianBlur)滤波器
距中心越近的pixel权重越大,边缘权重越小

二值化
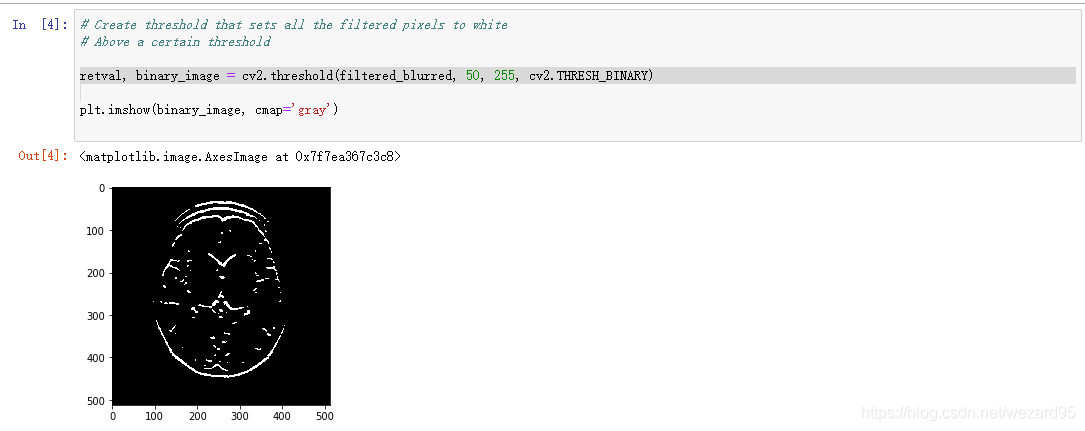
边缘检测
canny edge detection

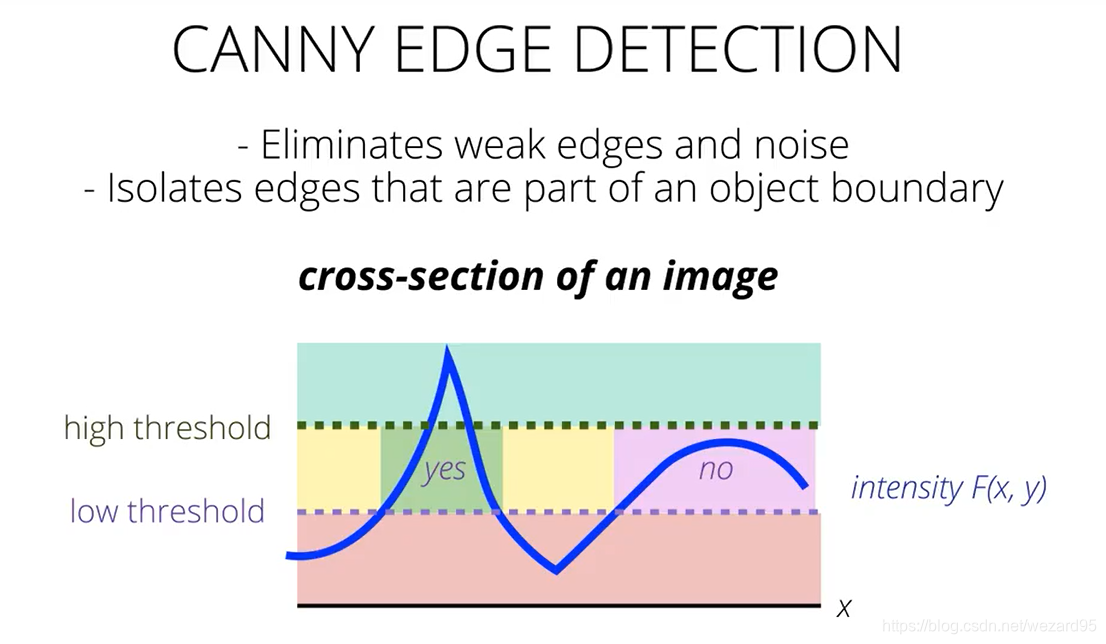
双阈值化操作:
只保留高于高阈值的边缘和与高边缘连接的两个阈值之间的部分
形状检测
hough transform
霍夫空间:点(m,b)即代表直线y=mx+b
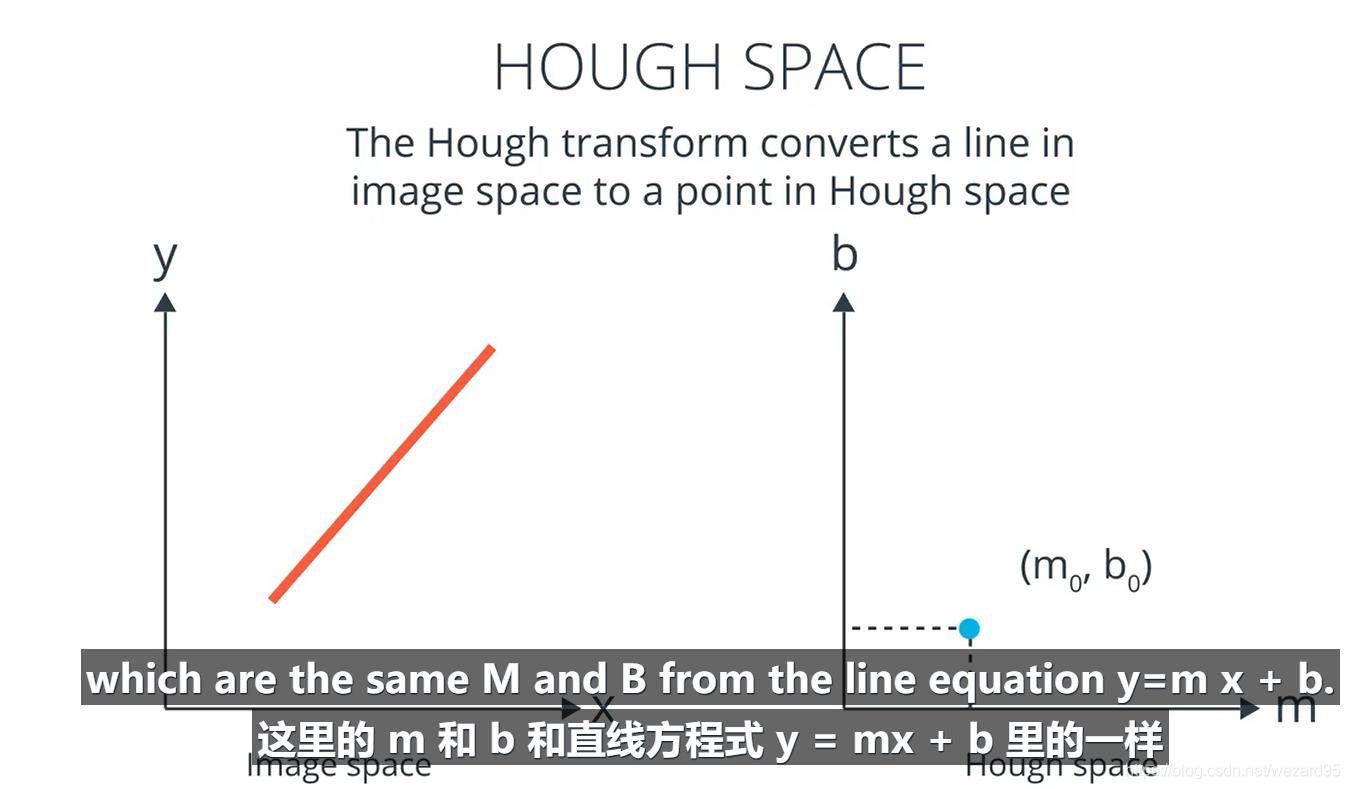
转化为极坐标

cv2.HoughLInesP()
需要先进行canny edge detection
# Define the Hough transform parameters
# Make a blank the same size as our image to draw on
rho = 1
theta = np.pi/180
threshold = 60
min_line_length = 100
max_line_gap = 5
line_image = np.copy(image) #creating an image copy to draw lines on
# Run Hough on the edge-detected image
lines = cv2.HoughLinesP(edges, rho, theta, threshold, np.array([]),
min_line_length, max_line_gap)
# Iterate over the output "lines" and draw lines on the image copy
for line in lines:
for x1,y1,x2,y2 in line:
cv2.line(line_image,(x1,y1),(x2,y2),(255,0,0),5)
plt.imshow(line_image)
threshold为在霍夫空间确定直线的最少相交数
图像识别
haar cascades
- 提取haar features:即梯度测量值,算法会观察某个特定像素区域周围的矩形区域,以某种方式减去该像素周围的矩形区域,从而产生像素差,可以检测边缘,线以及更复杂的矩形等模式

2. 根据某个特征检测器进行分类,舍弃判断为不是人脸的部分,级联多个这样的特征检测器
角点检测

形态运算
膨胀和腐蚀称为形态运算。通常在二元图像上执行,类似于轮廓检测。膨胀通过向图像中的对象的边缘添加像素,放大亮白区域。腐蚀正好相反:它会删除对象边缘的像素,并缩小对象的大小。
通常我们会按顺序执行这两种运算,以增强对象特性!
膨胀
要在 OpenCV 中膨胀图像,你可以使用 dilate 函数和三个输入:原始二元图像、确定膨胀大小的内核(均不会导致默认大小)以及进行膨胀的迭代次数(通常为 1)。在下面的示例中,我们用到一个 5x5 内核,它像过滤器一样在图像上移动,如果在 5x5 窗口中,像素周围的任何像素是白色,则使该像素变成白色!我们将使用简单的草写字母“j”作为示例。
# Reads in a binary image
image = cv2.imread('j.png', 0)
# Create a 5x5 kernel of ones
kernel = np.ones((5,5),np.uint8)
# Dilate the image
dilation = cv2.dilate(image, kernel, iterations = 1)
腐蚀
要腐蚀图像,我们将采用相同的步骤,但是使用 erode 函数。
# Erode the image
erosion = cv2.erode(image, kernel, iterations = 1)

open 开运算
先腐蚀,消除噪点,后膨胀
opening = cv2.morphologyEx(image, cv2.MORPH_OPEN, kernel)
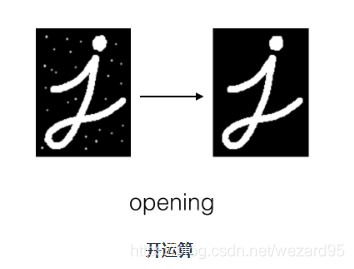
close 闭运算
先膨胀,后腐蚀,填充图像内部的黑点
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)

查找轮廓和特征
#生成一个用于寻找轮廓的二值图像
retval, binary = cv2.threshold(gray, 225, 255, cv2.THRESH_BINARY_INV)
# Find contours from thresholded, binary image 查找并画出轮廓
retval, contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# Draw all contours on a copy of the original image
contours_image = np.copy(image)
contours_image = cv2.drawContours(contours_image, contours, -1, (0,255,0), 3)
plt.imshow(contours_image)

cv2.findContours()函数
函数的原型为
cv2.findContours(image, mode, method[, contours[, hierarchy[, offset ]]]
opencv3会返回三个值,分别是img, countours, hierarchy
参数
第一个参数是寻找轮廓的图像;
第二个参数表示轮廓的检索模式,有四种(本文介绍的都是新的cv2接口):
cv2.RETR_EXTERNAL表示只检测外轮廓
cv2.RETR_LIST检测的轮廓不建立等级关系
cv2.RETR_CCOMP建立两个等级的轮廓,上面的一层为外边界,里面的一层为内孔的边界信息。如果内孔内还有一个连通物体,这个物体的边界也在顶层。
cv2.RETR_TREE建立一个等级树结构的轮廓。
第三个参数method为轮廓的近似办法
cv2.CHAIN_APPROX_NONE存储所有的轮廓点,相邻的两个点的像素位置差不超过1,即max(abs(x1-x2),abs(y2-y1))==1
cv2.CHAIN_APPROX_SIMPLE压缩水平方向,垂直方向,对角线方向的元素,只保留该方向的终点坐标,例如一个矩形轮廓只需4个点来保存轮廓信息
cv2.CHAIN_APPROX_TC89_L1,CV_CHAIN_APPROX_TC89_KCOS使用teh-Chinl chain 近似算法
返回值
cv2.findContours()函数返回两个值,一个是轮廓本身,还有一个是每条轮廓对应的属性。
cv2.findContours()函数首先返回一个list,list中每个元素都是图像中的一个轮廓,用numpy中的ndarray表示。这个概念非常重要。在下面drawContours中会看见.
hierarchy返回值
此外,该函数还可返回一个可选的hiararchy结果,这是一个ndarray,其中的元素个数和轮廓个数相同,每个轮廓contours[i]对应4个hierarchy元素hierarchy[i][0] ~hierarchy[i][3],分别表示后一个轮廓、前一个轮廓、父轮廓、内嵌轮廓的索引编号,如果没有对应项,则该值为负数。
cv2.drawContours()函数
cv2.drawContours(image, contours, contourIdx, color[, thickness[, lineType[, hierarchy[, maxLevel[, offset ]]]]])
第一个参数是指明在哪幅图像上绘制轮廓;
第二个参数是轮廓本身,在Python中是一个list。
第三个参数指定绘制轮廓list中的哪条轮廓,如果是-1,则绘制其中的所有轮廓。后面的参数很简单。其中thickness表明轮廓线的宽度,如果是-1(cv2.FILLED),则为填充模式。绘制参数将在以后独立详细介绍。
特征向量
ORB(Oriented FAST and rotated BRIEF)
- 在图像中找对应的key points
- 为每个key point 计算相应的特征向量(只包含0和1 ),表示key point周围的强度模式
FAST(Features from Accelerated Segment Test)
用于快速选择key points
给定一个pixel p,FAST会比较p周围小圆圈的16个像素,每个像素被分为三个种类,比p亮,比p暗或和p相似。像素的强度,intensity of pixel 称为Ip,给定阈值h,Ip+h,Ip-h分为三类,如果圆圈上有超过8个以上的相连像素暗于或亮于p,则选为关键点
优势:
搜索周围16个像素的时间和搜索圆圈中与p等距的4个像素效果是一样的,如果至少有一对连续像素的亮度高于或低于p,则选为key point
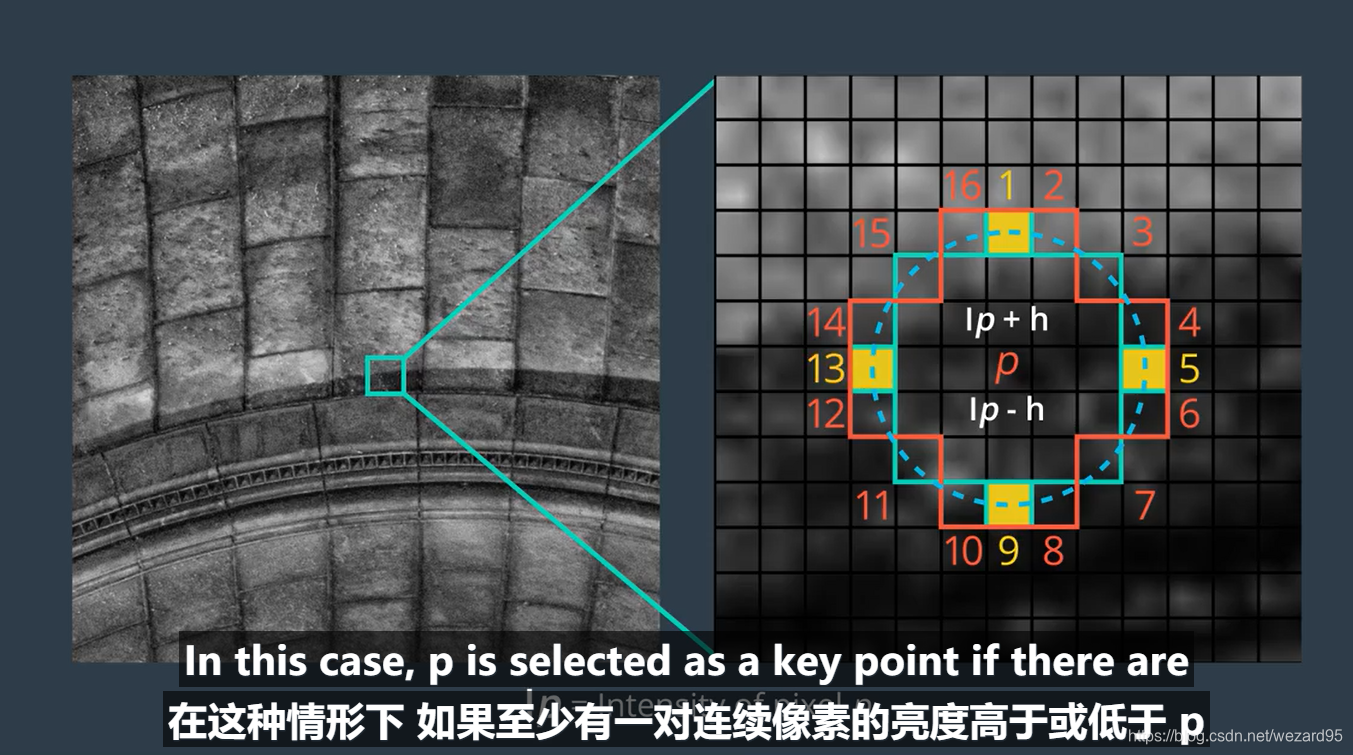
BRIEF(Binary Robust Independent Elementary Features)
根据一组key points创建二元特征向量,每个key point 由一个二元特征向量描述(高效存储,快速计算)
- 首先运用高斯核对图像进行平滑处理,以防描述符对高频噪点过于敏感
- 对key point周围的邻域(patch)随机选择一对像素,第一个为以key point 为中心的高斯分布中抽取的一个像素,标准差为σ,第二个标准差为σ/2,若第一个像素比第二个亮,则描述符中的相应位分配为1,否则0。重复此过程256次,得到该像素的特征向量。
ORB
- 构建图像金字塔,即单个图像的多尺度表示,金字塔的每个级别由上个级别图像的下采样组成。

- 从每个级别的图像中找到key points,实现部分缩放不变性
- 给每个key point分配一个梯度方向,取决于该点周围的强度是如何变化的(首先找到强度型心即平均强度所在的位置,从关键点出发与key point所在位置连成直线)
- 相同patach下,不同尺寸的图像的key point大小不同,用这些新的BRIEF创造特征向量(rBRIEF),使具有旋转不变性(使关键点和随机点的方向一致)
首先计算训练图的ORB,存储到内存中,然后计算并保存query image的ORB,比较关键点的汉明距离(二元描述符不同位数量),并匹配key point,返回最匹配的关键点对。适用于有很多连续特征,并不受图像背景影响的场景。
RB算法的第一步是定位训练图像中的所有关键点。找到关键点后,ORB会创建相应的二进制特征向量,并在ORB描述子中将它们组合在一起。
cv2.ORB_create()
我们要使用OpenCV的ORB类来定位关键点并创建相应的ORB描述子。另外,要使用ORB_create()函数设置ORB算法的参数。 ORB_create()函数的参数及其默认值如下:
cv2.ORB_create(nfeatures = 500, scaleFactor = 1.2, nlevels = 8, edgeThreshold = 31, firstLevel = 0, WTA_K = 2, scoreType = HARRIS_SCORE, patchSize = 31, fastThreshold = 20)
参数:
-
nfeatures - int
确定想要定位的特征(即关键点)的最大数量。 -
scaleFactor - float
金字塔抽取比率必须大于1。ORB会使用图像金字塔来查找特征,因此必须提供金字塔中每个层与金字塔所具有的级别数之间的比例因子。scaleFactor = 2表示经典金字塔,其中每个下一级别的像素比前一级少4倍。大比例因子将会减少检测到的特征数量。 -
nlevels - int
金字塔等级的数量。最小级别的线性大小等于input_image_linear_size / pow(scaleFactor,nlevels)。 -
edgeThreshold - - int
未检测到特征的边缘大小。由于关键点具有特定的像素大小,因此必须从搜索中排除图像的边缘。edgeThreshold的大小应等于或大于patchSize参数。 -
firstLevel - int
此参数用于确定应将哪个级别当做金字塔中的第一级别。它在当前实现中应为0。通常情况下,具有统一标度的金字塔等级被认为是第一级。 -
WTA_K - int
用于生成定向BRIEF描述子的每个元素的随机像素的数量。可能的值为2、3和4,其中2为默认值。例如,值3意味着一次选择三个随机像素来比较它们的亮度,并返回最亮像素的索引。由于有3个像素,因此返回的索引将为0、1或2。 -
scoreType - int
此参数可以设置为HARRIS_SCORE或FAST_SCORE。默认的HARRIS_SCORE表示Harris角点算法用于对特征进行排名。该分数仅用于保留最佳特征。 FAST_SCORE生成的关键点稳定性稍差,但计算起来要快一些。 -
patchSize - int
定向BRIEF描述子使用的补丁的大小。在较小的金字塔层级上,由特征覆盖的感知图像区域将更大。
我们可以看到,cv2. ORB_create()函数支持各种参数。前两个参数(nfeatures and scaleFactor)最有可能需要更改。其他参数只要保留其默认值,就可以获得不错的结果。
在下面的代码中,我们将使用ORB_create()函数将我们想要检测的关键点的最大数量设置为200,并将金字塔抽取比率设置为2.1。然后,使用.detectAndCompute (image)方法定位给定训练image中的关键点并计算其对应的ORB描述子。最后,使用cv2.drawKeypoints()函数把ORB算法找到的关键点可视化。
# Import copy to make copies of the training image
import copy
# Set the default figure size
plt.rcParams['figure.figsize'] = [14.0, 7.0]
# Set the parameters of the ORB algorithm by specifying the maximum number of keypoints to locate and
# the pyramid decimation ratio
orb = cv2.ORB_create(200, 2.0)
# Find the keypoints in the gray scale training image and compute their ORB descriptor.
# The None parameter is needed to indicate that we are not using a mask.
keypoints, descriptor = orb.detectAndCompute(training_gray, None)
# Create copies of the training image to draw our keypoints on
keyp_without_size = copy.copy(training_image)
keyp_with_size = copy.copy(training_image)
# Draw the keypoints without size or orientation on one copy of the training image
cv2.drawKeypoints(training_image, keypoints, keyp_without_size, color = (0, 255, 0))
# Draw the keypoints with size and orientation on the other copy of the training image
cv2.drawKeypoints(training_image, keypoints, keyp_with_size, flags = cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# Display the image with the keypoints without size or orientation
plt.subplot(121)
plt.title('Keypoints Without Size or Orientation')
plt.imshow(keyp_without_size)
# Display the image with the keypoints with size and orientation
plt.subplot(122)
plt.title('Keypoints With Size and Orientation')
plt.imshow(keyp_with_size)
plt.show()
# Print the number of keypoints detected
print("\nNumber of keypoints Detected: ", len(keypoints))
正如右图所示,每个关键点都有一个中心、一个大小和一个角度。这个中心会确定图像中每个关键点的位置,每个关键点的大小由BRIEF用来创建其特征向量的补丁大小决定,而角度会告诉我们由rBRIEF确定的关键点的方向。
找到训练图像的关键点并且计算了它们相应的ORB描述子之后,就可以对查询图像进行相同的操作。为了更清楚地查看ORB算法的属性,在下一部分中,我们将使用与我们的训练和查询图像相同的图像。
特征匹配
获得了训练和查询图像的ORB描述子之后,最后一步就是使用相应的ORB描述子在两个图像之间进行关键点匹配。这种匹配通常由匹配函数执行。最常用的匹配函数是Brute-Force。
在下面的代码中,我们将使用OpenCV的BFMatcher类来比较训练和查询图像中的关键点。使用cv2.BFMatcher()函数设置Brute-Force匹配程序的参数。 cv2.BFMatcher()函数的参数及其默认值如下:
cv2.BFMatcher(normType = cv2.NORM_L2, crossCheck = false)
参数:
-
normType
确定用于确定匹配质量的度量标准。默认情况下,normType = cv2.NORM_L2,它用于测量两个描述子之间的距离。但是,对于像ORB创建的二进制描述子一样,汉明度量更合适。汉明度量通过计算二进制描述子之间的不相似位的数量来确定距离。当使用WTA_K = 2创建ORB描述子时,要选择两个随机像素并在亮度上进行比较。最亮像素的索引返回为0或1。此类输出仅占用1位,因此应使用cv2.NORM_HAMMING度量。另一方面,如果使用WTA_K = 3创建ORB描述子,则选择三个随机像素并在亮度上进行比较。最亮像素的索引返回0、1或2。这样的输出将占用2位,因此应该使用汉明距离的特殊变体,即cv2.NORM_HAMMING2(2代表2位)。然后,对于所选择的任何度量,当比较训练和查询图像中的关键点时,具有较小度量(它们之间的距离)的对被认为是最佳匹配。 -
crossCheck - bool
布尔变量,可以设置为True或False。交叉验证对于消除错误匹配非常有用。交叉验证通过执行两次匹配过程来完成。第一次匹配中,将训练图像中的关键点与查询图像中的关键点进行比较;第二次匹配中,将查询图像中的关键点与训练图像中的关键点进行比较(即,反向进行比较)。启用交叉验证时,只有当训练图像中的关键点A是查询图像中关键点B的最佳匹配时,该匹配才被视为有效,反之亦然(即,如果查询图像中的关键点B 是训练图像中的关键点A,该匹配则是最佳匹配)。
设置了BFMatcher的参数之后,我们就可以使用.match(descriptors_train, descriptors_query)方法,使用它们的ORB描述子找到训练和查询图像之间的匹配关键点。最后,我们将使用cv2.drawMatches ()函数来可视化Brute-Force匹配程序找到的匹配关键点。此函数会水平堆叠训练和查询图像,并将训练图像中关键点的线条绘制到查询图像中对应的最佳匹配关键点。在这里,请注意,为了更清楚地查看ORB算法的属性,在以下示例中,我们将使用与我们的训练和查询图像相同的图像。
HOG(Histogram of Oriented Gradient)
方向梯度直方图,横坐标为各个梯度方向
顾名思义,HOG算法是一种基于从图像梯度的方向创建直方图的算法。 HOG算法是通过一系列步骤实现的,具体如下:
-
对于某个特定对象的图像,设置一个可以覆盖图像中整个对象的检测窗口或者你感兴趣的区域(参见图3)。
-
计算检测窗口中每个像素的梯度的大小和方向。
-
将检测窗口划分为连接的像素单元格 ,其中,所有单元格的大小相同(参见图3)。该单元格的大小是一个自由参数,通常选择它的目的在于匹配想要检测的特征的范围。例如,在64×128像素检测窗口中,6至8像素宽的正方形单元格适合于检测人体肢体。
-
为每个单元格创建直方图,首先将每个单元格中所有像素的渐变方向分组为特定数量的方向(角度)区间(bin);然后将每个角度区间中梯度的梯度大小相加(见图3)。直方图中的区间数是一个自由参数,通常设置为9个角度区间。
-
将相邻的单元格分组成块(见图3)。每个块中的单元格数是一个自由参数,所有块必须具有相同的大小。每个块之间的距离(称为步长)是一个自由参数,但通常设置为块大小的一半,在这种情况下,你将会获得重叠块(请查看下面的视频)。这样,HOG算法会根据经验更好地与重叠块一起运行。
-
使用每个块中包含的单元格来归一化该块中的单元格直方图(参见图3)。如果你有重叠块,这说明大多数单元格将根据不同的块进行归一化(请查看下面的视频)。因此,相同的单元格可以具有几种不同的归一化。
-
将所有块中的所有归一化直方图收集到称为HOG描述子的单个特征向量中。
-
使用来自相同类型对象的大量图像的结果HOG描述子来训练机器学习算法(例如SVM),进而检测图像中那些类型的对象。 例如,你可以使用来自行人的大量图像的HOG描述子来训练SVM,进而检测图像中的行人。其中,训练是通过你想要在图像中检测到的对象的正反面示例完成的。
-
训练完SVM之后,你需要使用滑动窗口方法来尝试检测和定位图像中的对象。 要想检测图像中的对象,你需要找到看起来类似于SVM所学习的HOG类型的图像部分。
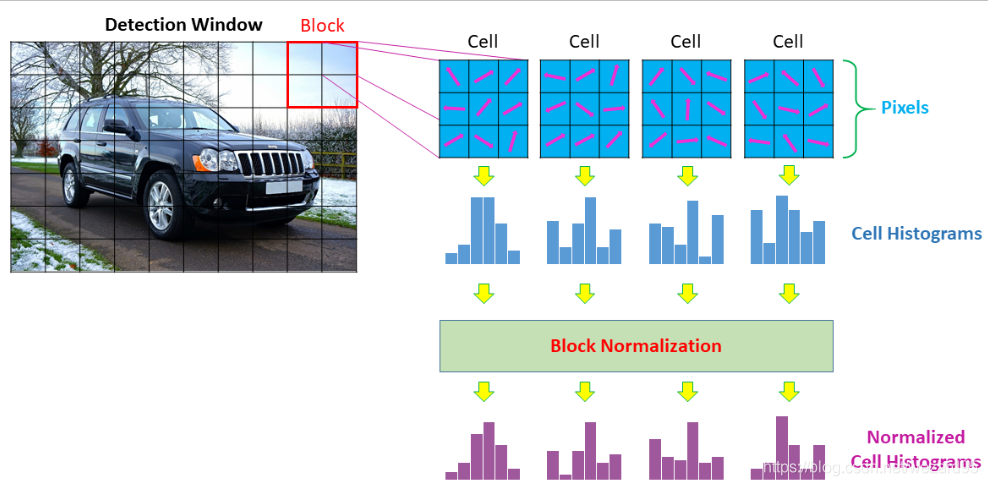
Fig. 3. - HOG Diagram.
为什么HOG算法如此有效
如上所述,HOG通过在称为单元格的图像的局部部分中添加特定方向的梯度的大小来创建直方图。这样做,我们保证了更强的梯度会对其各自的角度区间的大小产生更多影响,同时由噪声导致的较弱与随机定向梯度的影响被最小化。总之,直方图会以这种方式告诉我们每个单元格的主导梯度方向。
处理对比
现在,由于局部照明的变化以及背景和前景之间的对比度,主导方向的梯度差异会非常大。
为了弄清楚背景与前景对比度差异,HOG算法尝试在本地检测边缘。为了做到这一点,它定义了一组称为块的单元格,并使用这个本地单元格组对该直方图进行归一化。通过局部归一化,HOG算法可以非常可靠地检测每个块中的边缘。这就叫做块归一化。
除了使用块归一化之外,HOG算法还使用重叠块来提高其性能。通过使用重叠块,每个单元格向最终HOG描述子贡献若干独立分量,其中每个分量对应于相对于不同块归一化的单元格。这似乎是多余的,但是,经验证明,通过相对于不同的本地块对每个单元格进行几次归一化,HOG算法的性能会显著提高。
加载图像并导入资源
要创建HOG描述子,第一步是将所需的包加载到Python中并加载图像。
我们首先使用OpenCV加载三角形图块的图像。因为,cv2.imread()函数会将图像加载为BGR,而我们需要将图像转换为RGB,这样我们就可以使用正确的颜色显示它。与之前一样,我们会将BGR图像转换为灰度图像进行分析。
创建HOG描述子
我们将使用OpenCV的HOGDescriptor类来创建HOG描述子, 使用HOGDescriptor()函数设置HOG描述子的参数。HOGDescriptor()函数的参数及其默认值如下:
cv2.HOGDescriptor(win_size = (64, 128), block_size = (16, 16), block_stride = (8, 8), cell_size = (8, 8), nbins = 9, win_sigma = DEFAULT_WIN_SIGMA, threshold_L2hys = 0.2, gamma_correction = true, nlevels = DEFAULT_NLEVELS)
参数:
-
win_size – Size
检测窗口的大小(以像素为单位)(高度,宽度)。定义一个感兴趣的区域。它必须是单元格尺寸的整数倍。 -
block_size – Size
块大小(以像素为单位)(宽度,高度)。定义每个块中有多少个单元格。它必须是单元格尺寸的整数倍,并且必须小于检测窗口。块越小,你将获得的细节越详细。 -
block_stride – Size
以像素为单位块步长(水平,垂直)。它必须是单元格尺寸的整数倍。block_stride定义了相邻块之间的距离,例如,水平8个像素和垂直8个像素。block_stride越长,算法就会运行得越快(因为评估的块会越少),但算法也可能不再运行。 -
cell_size – Size
单元格大小,以像素为单位(宽度,高度)。确定格单元的大小。单元格越小,你将获得的细节越详细。 -
nbins – int
直方图的区间数。确定用于制作直方图的角度区间数量。使用的区间越多,就可以获取更多的渐变方向。 HOG使用无符号渐变,因此角度区间的值将介于0和180度之间。 -
win_sigma – double
高斯平滑窗口参数。通过在计算直方图之前对每个像素应用高斯空间窗口来平滑块边缘附近的像素,从而改善HOG算法的性能。 -
threshold_L2hys – double
L2-Hys(Lowe式限幅L2范数)归一化方法收缩率。 L2-Hys方法用于归一化块,它由L2范数和剪切以及重归一化组成。限幅会将每个块的描述子向量的最大值限制为具有给定阈值的值(默认为0.2)。限幅之后,如IJCV,60(2):91-110,2004中所述,重新归一化描述子矢量。 -
gamma_correction – bool
用于指定是否需要伽马校正预处理的标志。执行伽马校正可以在一定程度上提高HOG算法的性能。 -
nlevels – int
检测窗口增加的最大数量。
我们可以看到,cv2.HOGDescriptor()函数支持各种参数。前几个参数(block_size, block_stride, cell_size以及nbins)是最有可能更改的参数。其他参数都可以放心地保留其默认值,这样你会获得很不错的结果。
在下面的代码中,我们将使用 cv2.HOGDescriptor()函数来设置单元格大小、块大小、块步长以及HOG描述子的直方图区间数。然后,我们将使用.compute(image)方法计算给定image的HOG描述子(特征向量)。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









