



在游戏行业向长线运营转型的拐点上,我们正见证着前所未有的挑战:开放世界地图面积指数级增长,实时物理模拟复杂度飙升,多平台同步要求日益严苛。在游戏开发运维过程中,崩溃问题一直是令人头疼的难题。以一个DAU 50万的游戏为例,1%的崩溃率就意味着每天影响5000设备,产生1万+的崩溃次数。面对海量的崩溃堆栈数据,开发团队往往陷入“盲人摸象”式的分析困境。
崩溃治理的痛点:我们为何需要AI?
传统崩溃治理方式存在2大挑战:
1. 崩溃聚类问题
传统堆栈分类规则高度依赖人工,技术方法滞后,业务效果不佳。静态的堆栈哈希分组与固定规则难以应对复杂多变的风险行为,导致误报和漏报情况居高不下。
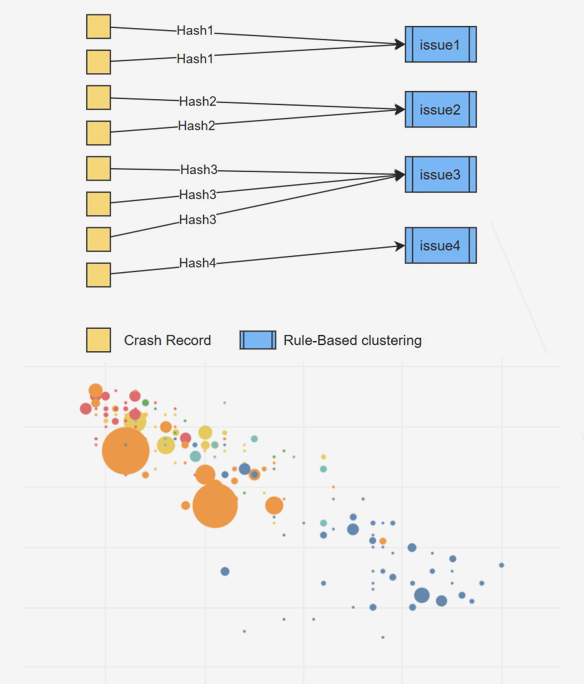
(数据分类零散,很多噪声导致聚类失败)
2. 根因分析困难
平均需排查10+个模块才能定位根因,70%的修复方案依赖资深工程师经验判断,问题排查和验证流程长,造成隐形业务损耗。

(传统crash分析链路)
技术突破:AI驱动的三大创新解决方案
1. 智能聚类与去重:从“噪声”中提取有效信号
腾讯CrashSight平台通过AI技术实现了崩溃issue的智能聚合与去重,有效解决了传统分类规则的局限性。在实际应用中,该技术展现了显著效果——错误issue分组数优化后最高减少70.08%,大幅提升了分类准确性。这种智能聚类技术的核心价值在于,它能够自动识别和过滤掉那些包含动态名称、UUID等变量的堆栈信息,避免了传统方法因固定规则导致的误分类问题。通过机器学习算法,系统可以理解堆栈的语义含义,而不仅仅是进行表面模式的匹配。
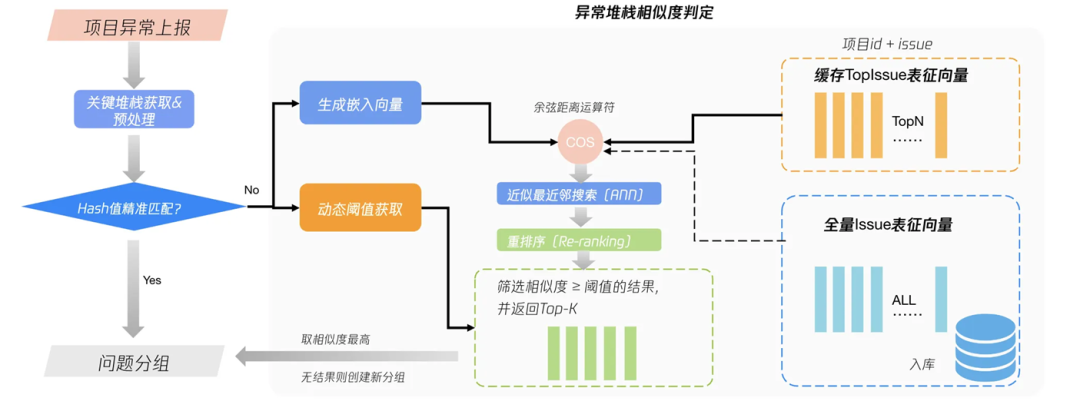
(异常堆栈相似度判定流程示意)
2. 减少人工依赖:根因智能辅助
通过自动化流水线聚合碎片化信息,CrashSight利用知识图谱和智能算法模拟高级工程师的调试思维,并紧密串联代码仓库与运行时数据,最终实现从“看到现象”到“定位根因并建议修复”的质变,是DevOps和AIOps理念的深度实践。
根因分析我们设计了“在线分析”和“离线分析”2个部分,在线部分基于检索增强生成(RAG)的多步推理框架,能够逐层分析崩溃堆栈,追踪错误传播路径,最终锁定根本原因。而离线部分支持本地部署代码片段获取模块,无需代码上传,即可快速匹配拉取Issue相关代码进行分析。最大程度保障业务代码和核心资产安全性。
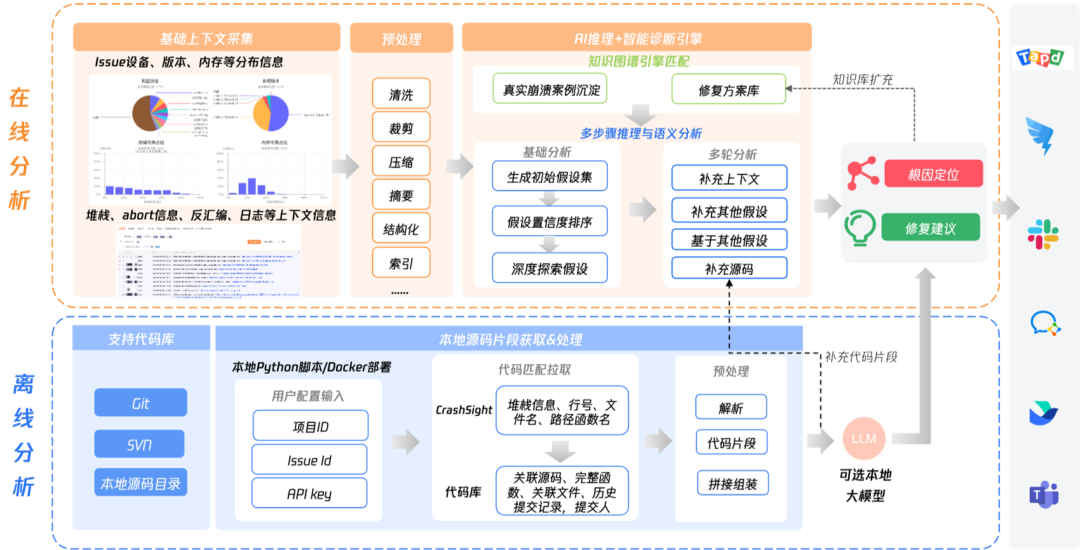
(根因智能辅助框架图)
3. 限制AI幻觉:混合推理框架应用
由于日志信息分散且不完整,大量重复日志掩盖关键信息,大模型处理长上下文时Token消耗大,容易使AI产生幻觉,影响准确性。CrashSight采用了创新的混合推理框架,将思维树与LATS方法相结合,构建了一个真正智能的多步骤推理引擎。这个引擎的工作流程始于多分支假设的生成与探索,系统会同时考虑多种可能的崩溃原因,而不是局限于单一方向。在假设生成后,引擎会启动证据驱动的动态评估机制,通过实时收集的崩溃数据、日志信息等证据来验证各个假设的合理性。
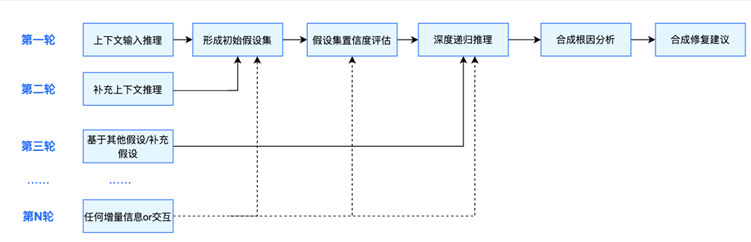
(多轮交互式的分析流程)
接下来是递归深度分析阶段,系统会对通过初步评估的假设进行层层深入的分析,从表面现象追溯到根本原因。这个过程模拟了资深工程师的排查思路,并且速度和精度都得到了极大提升。最终,系统会生成结构化的输出结果,确保每个结论都有完整的证据链支持,并且具有很好的可解释性。
它不仅能够定位到具体的文件、函数和崩溃点,还能提供直接可用的补丁代码,并按照紧急止血、根因修复、长期加固等优先级给出修复方案清单,真正实现了从“现象”到“真相”的智能跨越。
从“救火队”到“预言家”的转变
通过三阶段模型系统性地推进AI与工具的结合:在工具增强阶段实现单点任务的自动化,完成“点”的应用;在流程优化阶段将AI嵌入完整业务流程,实现“线”的应用;最终在战略赋能阶段让AI从“支持业务”转变为“驱动业务”,完成“面”的应用。

这种演进使得AI成为质量防线的“先知”与“哨兵”,通过智能核心引擎提供预测、诊断、归因等能力,无缝对接现有开发工具链,极大提升了开发者的工作效率和幸福感。
在AI技术快速发展的今天,跟进可能跟错,但不关注可能错过!错了可以再来,错过失去机会!游戏开发者和技术团队应该保持开放心态,积极拥抱AI技术带来的变革机遇。
随着AI技术的持续发展,游戏崩溃治理正在从被动应对转向主动预防。腾讯CrashSight平台将继续深化AI能力,为游戏开发者提供更智能、高效的崩溃治理解决方案。

(徐广庆老师在现场回答观众提问)
以上内容来自《游戏发行增值提效》线下专场活动中腾讯徐广庆老师的分享摘抄,获取完整分享材料、或申请试用请联系您的对接商务,或发送邮件至【wetest@tencent.com】联系我们。

















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









