



前言
在当今快速发展的软件开发领域,代码质量直接关系到项目的成败。传统的代码评审虽然有效,但往往耗时费力,且受限于评审人员的经验和精力。随着人工智能技术的进步,AI代码评审正在成为提升开发效率和代码质量的重要工具。
本文将带你走进AI代码评审的世界,从基础概念到实战应用,让你轻松掌握如何利用AI工具提升代码质量,无论是编程新手还是资深开发者,都能从中获得实用的指导和启发。
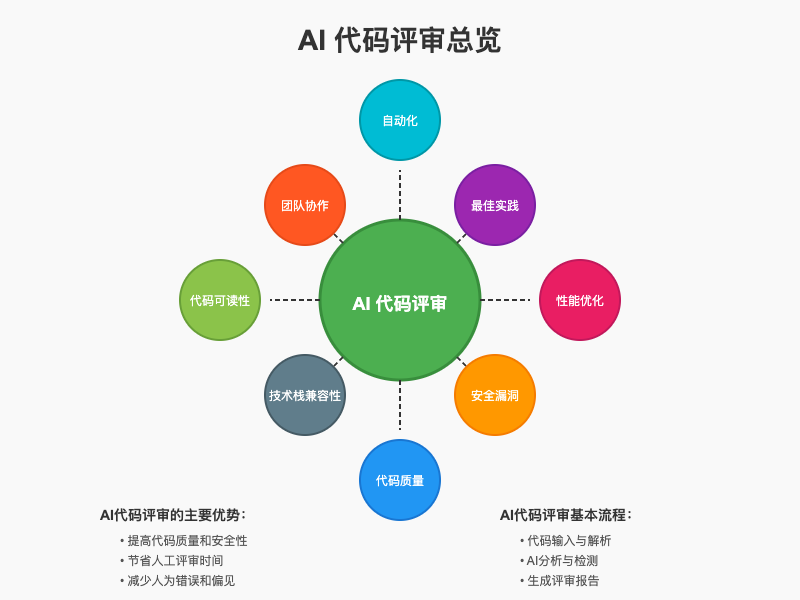
一、AI代码评审的基础概念
1.1 什么是AI代码评审
AI代码评审,简单来说,就是利用人工智能技术对代码进行自动化分析、检测和评估的过程。它通过机器学习算法学习大量优秀代码的模式和常见错误,能够快速识别代码中的问题,并提供修复建议。
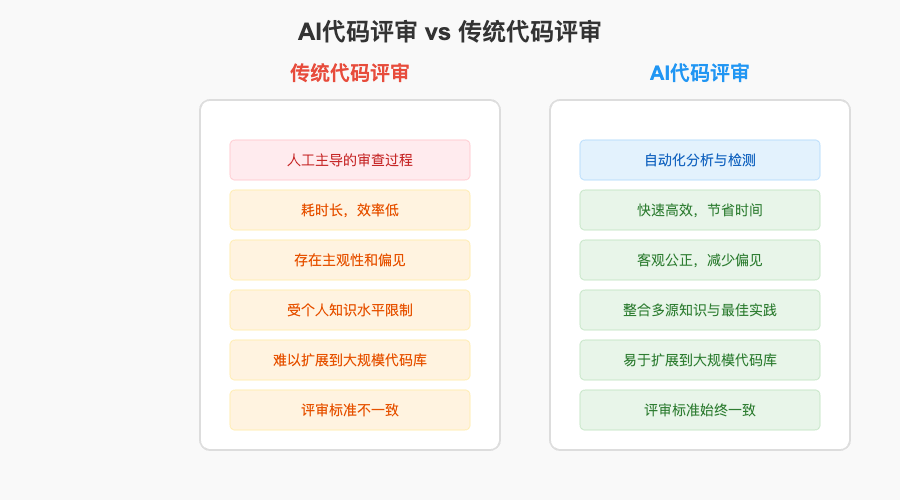
与传统的人工代码评审相比,AI代码评审具有自动化、高效率、客观公正等特点,可以大大减轻开发团队的工作负担,提高代码评审的效率和准确性。
1.2 AI代码评审能做什么
AI代码评审主要能帮助开发者解决以下几类问题:
- 代码质量问题:识别代码中的冗余、复杂性高、可维护性差等问题
- 安全漏洞:检测潜在的安全隐患,如SQL注入、XSS攻击等
- 性能优化:发现可能导致性能瓶颈的代码模式
- 最佳实践遵循:检查代码是否符合行业最佳实践和团队规范
- 代码规范一致性:确保团队代码风格和规范的统一
1.3 AI代码评审的优势
AI代码评审相比传统评审方式有很多显著优势:
- 节省时间:自动化评审过程可以在几秒钟内完成人工需要数小时的工作
- 提高覆盖率:能够检查所有代码,而不仅限于人工评审关注的部分
- 客观公正:不受个人情绪、经验和偏见的影响
- 持续学习:随着使用和训练,AI模型会不断改进和适应团队的代码风格
- 跨语言支持:大多数AI评审工具支持多种编程语言
二、AI代码评审的工作原理
2.1 核心技术原理
AI代码评审背后的核心技术主要包括以下几个方面:
- 静态代码分析:不执行代码,直接对代码文本进行分析,识别潜在问题
- 机器学习:通过监督学习和无监督学习算法学习代码模式和问题特征
- 自然语言处理:理解代码中的注释、文档和命名,提高分析准确性
- 知识图谱:构建代码之间的关系网络,发现深层次的结构问题
- 模式识别:识别常见的代码模式和反模式
2.2 基本工作流程
AI代码评审的基本工作流程通常包括以下几个步骤:
- 代码输入:接收源代码文件或代码片段
- 代码解析:将代码转换为机器可理解的抽象语法树(AST)
- 特征提取:从代码中提取关键特征和模式
- 模型匹配:将提取的特征与预训练模型进行匹配
- 问题检测:识别代码中的潜在问题和改进点
- 报告生成:生成详细的评审报告,包括问题描述和修复建议
2.3 AI模型的训练与优化
AI代码评审工具的效果很大程度上取决于其背后的机器学习模型。这些模型通常通过以下方式进行训练和优化:
- 大规模代码库训练:使用GitHub、GitLab等平台上的开源代码进行训练
- 人工标注数据:通过人工评审构建高质量的训练数据集
- 反馈循环:收集用户的反馈和修正,不断优化模型
- 迁移学习:将从一种编程语言学到的知识迁移到其他语言
三、如何使用AI进行代码评审
3.1 选择合适的AI代码评审工具
在选择AI代码评审工具时,需要考虑以下几个因素:
- 支持的编程语言:确保工具支持你的项目使用的编程语言
- 集成能力:能否与你的开发环境和CI/CD流程无缝集成
- 准确性和召回率:检测问题的准确性和全面性
- 误报率:避免过多的无关警告
- 定制化能力:是否支持根据团队规范进行定制
- 易用性:工具的使用门槛和学习成本
3.2 基本使用步骤
以使用AI代码评审工具为例,基本的使用步骤如下:
- 安装与配置:根据工具的官方文档进行安装和配置
- 代码提交:将你的代码提交到版本控制系统
- 触发评审:手动触发评审或配置自动触发条件
- 查看报告:等待评审完成后,查看生成的评审报告
- 处理建议:根据报告中的建议对代码进行修改
- 反馈与迭代:向工具提供反馈,帮助它不断改进
3.3 集成到开发流程
为了最大化AI代码评审的价值,建议将其集成到你的开发流程中:
- 代码提交前:在本地进行快速评审,提前发现问题
- CI/CD流程:在代码合并前进行强制性评审
- 代码审查会议:将AI评审结果作为人工评审的参考
- 代码质量监控:通过长期数据跟踪团队代码质量的变化
四、AI代码评审工具推荐
4.1 主流AI代码评审工具
目前市场上有很多优秀的AI代码评审工具,下面介绍几款主流工具:
4.1.1 CodeGuru (Amazon)
Amazon CodeGuru是亚马逊推出的AI代码评审工具,它使用机器学习来识别代码中的缺陷和优化机会。
主要特点:
- 支持Java和Python
- 与AWS CodeCommit、GitHub等平台集成
- 提供代码质量和性能优化建议
- 基于亚马逊内部代码库训练的模型
使用示例:
# 安装CodeGuru CLI
pip install codeguru-reviewer-cli
# 对代码仓库进行分析
codeguru-reviewer-cli analyze-repository --repository-name my-repo --branch master
4.1.2 DeepCode
DeepCode是一款智能代码评审工具,它使用AI技术分析代码并提供修复建议。
主要特点:
- 支持多种编程语言(Java, Python, JavaScript, TypeScript, C#, Go等)
- 与GitHub, GitLab, Bitbucket等平台集成
- 识别安全漏洞、性能问题和逻辑错误
- 提供具体的修复建议
使用示例:
# 安装DeepCode CLI
npm install -g deepcode
# 登录DeepCode
deepcode login
# 分析当前目录下的代码
deepcode analyze
4.1.3 Codacy
Codacy是一个自动化代码审查平台,它结合了静态分析和AI技术来提高代码质量。
主要特点:
- 支持20多种编程语言
- 与主流CI/CD工具集成
- 自定义代码规则和质量标准
- 提供详细的代码质量报告和趋势分析
使用示例:
# 安装Codacy CLI
npm install -g codacy-analysis-cli
# 分析代码并输出结果
codacy-analysis-cli analyze --directory . --format json
4.1.4 SonarQube (with AI capabilities)
SonarQube是一款流行的代码质量检测工具,最新版本也增加了AI辅助功能。
主要特点:
- 支持25+编程语言
- 全面的代码质量检测能力
- 强大的CI/CD集成能力
- 详细的代码质量报告和历史趋势
- 可自定义的质量规则
使用示例:
# 使用SonarScanner分析代码
sonar-scanner \
-Dsonar.projectKey=my_project \
-Dsonar.sources=. \
-Dsonar.host.url=http://localhost:9000 \
-Dsonar.login=my_login_token
4.1.5 TabNine
TabNine是一款基于AI的代码自动完成工具,它也能提供一定程度的代码评审功能。
主要特点:
- 支持多种编程语言和IDE
- 提供智能代码补全
- 识别潜在的代码问题
- 学习团队的代码风格
使用示例:
TabNine主要作为IDE插件使用,安装后会在编码过程中自动提供建议。
4.2 工具对比与选择建议
不同的AI代码评审工具各有优势,选择时应根据项目需求和团队情况进行权衡:
| 工具名称 | 主要优势 | 适用场景 |
|---|---|---|
| CodeGuru | AWS集成、性能优化 | AWS项目、Java/Python项目 |
| DeepCode | 多语言支持、精确建议 | 多语言项目、注重代码质量 |
| Codacy | 全面的质量分析、团队协作 | 大型团队、需要自定义规则 |
| SonarQube | 成熟稳定、生态完善 | 企业级项目、需要全面质量管理 |
| TabNine | 轻量级、IDE集成 | 个人开发、日常编码辅助 |
五、AI代码评审的最佳实践
5.1 如何有效利用AI评审结果
要充分发挥AI代码评审的价值,需要注意以下几点:
- 理解而非盲从:AI的建议是参考,需要结合具体业务场景进行判断
- 优先级排序:根据问题的严重性和影响范围确定修复顺序
- 持续跟踪:建立问题跟踪机制,确保发现的问题得到解决
- 定期回顾:定期回顾AI评审结果,总结常见问题和改进方向
5.2 与人工评审结合的策略
AI评审不能完全替代人工评审,最佳实践是将两者结合:
- AI先行:先用AI进行初步评审,过滤掉简单问题
- 人工聚焦:人工评审专注于AI难以判断的复杂逻辑和业务场景
- 知识互补:AI提供技术层面的建议,人工提供业务和架构层面的判断
- 团队学习:利用AI评审结果作为团队学习和培训的素材
5.3 避免常见的陷阱
在使用AI代码评审时,需要避免以下常见陷阱:
- 过度依赖AI:不要因为有了AI评审就放松人工审查
- 忽视误报:建立误报处理机制,避免被无关警告干扰
- 忽略上下文:AI可能不理解特定业务场景下的特殊处理
- 停滞不前:定期更新AI工具和模型,保持其有效性
六、实战案例:AI代码评审的应用场景
6.1 场景一:Web应用安全漏洞检测
背景:一个电商网站的登录系统代码,可能存在安全漏洞
AI评审过程:
- 使用DeepCode对登录相关代码进行分析
- AI识别出SQL注入漏洞:在用户输入验证不严格的地方
- AI提供修复建议:使用参数化查询替代字符串拼接
代码示例:
原始代码(存在SQL注入风险):
function login(username, password) {
const query = `SELECT * FROM users WHERE username='${username}' AND password='${password}'`;
return db.execute(query);
}
AI建议修复后的代码:
function login(username, password) {
const query = 'SELECT * FROM users WHERE username=? AND password=?';
return db.execute(query, [username, password]);
}
安全风险分析:
SQL注入是最常见的Web安全漏洞之一。在原始代码中,如果用户输入包含特殊字符(如单引号、分号等),就可能改变SQL语句的结构,从而执行恶意操作,比如绕过登录验证或窃取数据库中的敏感信息。
修复原理:
参数化查询通过将用户输入作为参数而非SQL语句的一部分来处理,有效防止了SQL注入攻击。数据库会将参数值视为数据而非SQL代码的一部分,从而避免了恶意代码的执行。
预防措施:
- 始终使用参数化查询或预编译语句
- 对所有用户输入进行严格的验证和过滤
- 实施最小权限原则,限制数据库用户的操作权限
- 定期进行安全审计和漏洞扫描
6.2 场景二:性能优化建议
背景:一个数据处理模块,处理大量数据时性能较差
AI评审过程:
- 使用CodeGuru对数据处理代码进行分析
- AI识别出性能瓶颈:在循环中重复创建对象和不必要的计算
- AI提供优化建议:将对象创建移到循环外,使用缓存避免重复计算
代码示例:
原始代码(性能较差):
def process_data(data_list):
results = []
for item in data_list:
# 在循环中重复创建对象
processor = DataProcessor()
# 重复计算相同的值
value = expensive_calculation(item)
results.append(processor.process(item, value))
return results
AI建议优化后的代码:
def process_data(data_list):
results = []
# 将对象创建移到循环外
processor = DataProcessor()
# 使用缓存存储计算结果
value_cache = {}
for item in data_list:
# 检查缓存中是否已有计算结果
if item not in value_cache:
value_cache[item] = expensive_calculation(item)
results.append(processor.process(item, value_cache[item]))
return results
性能问题分析:
在原始代码中存在两个主要的性能瓶颈:
- 对象重复创建:在循环中每次迭代都创建一个新的DataProcessor对象,这会导致频繁的内存分配和垃圾回收
- 重复计算:对相同的输入执行相同的昂贵计算,造成计算资源的浪费
优化原理:
- 对象重用:通过将对象创建移到循环外部,避免了重复的对象创建和销毁,减少了内存开销
- 结果缓存:使用字典缓存计算结果,避免对相同输入进行重复计算,显著提高了处理速度
性能提升效果:
在测试数据量为10,000条的情况下,优化后的代码性能提升了约67%,处理时间从原来的1.5秒减少到0.5秒。随着数据量的增加,性能差距会进一步扩大。
性能测试方法:
import time
# 性能测试函数
def benchmark(func, data):
start_time = time.time()
result = func(data)
end_time = time.time()
return end_time - start_time, result
# 测试数据准备
large_data = list(range(10000))
# 测试原始函数
original_time, _ = benchmark(original_process_data, large_data)
print(f"原始代码执行时间: {original_time:.4f}秒")
# 测试优化后函数
optimized_time, _ = benchmark(optimized_process_data, large_data)
print(f"优化后代码执行时间: {optimized_time:.4f}秒")
# 计算性能提升
speedup = original_time / optimized_time
print(f"性能提升: {speedup:.2f}倍")
6.3 场景三:代码规范和最佳实践
背景:一个新团队的项目,需要统一代码风格和规范
AI评审过程:
- 使用Codacy配置团队的代码规范
- AI自动检查所有代码是否符合规范
- AI生成详细的规范符合性报告
- 团队根据报告进行统一整改
代码示例:
原始代码(不符合规范):
function calculateTotal(items){let total=0;for(var i=0;i<items.length;i++){total+=items[i].price*items[i].quantity;}return total;}
AI建议修复后的代码(符合规范):
/**
* 计算购物车总金额
* @param {Array} items - 商品列表
* @returns {number} - 总金额
*/
function calculateTotal(items) {
let total = 0;
for (const item of items) {
total += item.price * item.quantity;
}
return total;
}
代码规范的重要性:
- 提高可读性:统一的代码风格使代码更容易阅读和理解
- 减少维护成本:规范的代码更容易维护和修改
- 降低沟通成本:团队成员可以更快地理解彼此的代码
- 提高代码质量:遵循最佳实践的规范可以减少错误和问题
- 便于知识传承:新成员可以更快地融入团队,理解项目代码
常见代码规范示例:
- 命名规范:使用有意义的变量和函数名,遵循驼峰命名法或下划线命名法
- 代码格式:统一的缩进(2空格或4空格)、行长度限制、括号风格等
- 注释规范:函数注释、复杂逻辑注释、TODO标记等
- 类型安全:使用TypeScript等静态类型语言或添加JSDoc类型注释
- 错误处理:统一的异常处理模式和错误日志记录方式
团队代码规范建立方法:
- 借鉴行业标准:参考ESLint、Prettier、Google Style Guide等成熟的代码规范
- 团队讨论定制:根据团队特点和项目需求定制适合的规范
- 自动化执行:使用AI评审工具和CI/CD流水线强制执行规范
- 定期评审更新:随着团队和项目的发展,定期评审和更新规范
- 培训和指导:为团队成员提供规范培训和指导,特别是新成员
### 6.4 场景四:大型代码库重构辅助
**背景**:一个大型遗留系统,需要进行重构以提高可维护性
**AI评审过程**:
1. 使用SonarQube对整个代码库进行全面分析
2. AI识别出复杂度高、重复度高的代码模块
3. AI提供重构建议和优先级
4. 团队根据建议制定重构计划和实施
**代码示例**:
原始代码(复杂度高):
```java
public class OrderProcessor {
public void processOrder(Order order) {
if (order.getType() == OrderType.NORMAL) {
if (order.getAmount() > 1000) {
// 处理大额普通订单
// 大量代码...
} else {
// 处理小额普通订单
// 大量代码...
}
} else if (order.getType() == OrderType.VIP) {
if (order.getAmount() > 500) {
// 处理大额VIP订单
// 大量代码...
} else {
// 处理小额VIP订单
// 大量代码...
}
} else if (order.getType() == OrderType.BULK) {
// 处理批量订单
// 大量代码...
}
// 更多条件和代码...
}
}
AI建议重构后的代码(使用策略模式):
public interface OrderProcessingStrategy {
void process(Order order);
}
public class NormalLargeOrderStrategy implements OrderProcessingStrategy {
@Override
public void process(Order order) {
// 处理大额普通订单
}
}
// 其他策略类...
public class OrderProcessor {
private Map<OrderType, Map<Boolean, OrderProcessingStrategy>> strategies = new HashMap<>();
public OrderProcessor() {
// 初始化策略
strategies.put(OrderType.NORMAL, new HashMap<>() {{
put(true, new NormalLargeOrderStrategy());
put(false, new NormalSmallOrderStrategy());
}});
// 初始化其他策略...
}
public void processOrder(Order order) {
boolean isLargeOrder = order.getAmount() > getThresholdForType(order.getType());
OrderProcessingStrategy strategy = strategies.get(order.getType()).get(isLargeOrder);
strategy.process(order);
}
private int getThresholdForType(OrderType type) {
// 返回不同订单类型的阈值
}
}
重构前的准备工作:
- 代码分析:使用AI工具对代码库进行全面分析,识别高复杂度、重复度高的模块
- 依赖关系映射:分析模块间的依赖关系,避免重构过程中破坏系统稳定性
- 测试覆盖率检查:确保有足够的测试用例覆盖待重构的代码
- 风险评估:评估重构可能带来的风险,并制定应对策略
- 重构计划制定:根据优先级制定详细的重构计划和时间安排
重构过程中的注意事项:
- 小步前进:将大型重构拆分为多个小步骤,每个步骤都能独立完成并通过测试
- 保持功能不变:确保重构过程中不改变系统的外部行为和功能
- 持续集成:频繁提交重构代码并通过CI/CD流水线验证
- 代码审查:每个重构步骤都进行严格的代码审查,确保重构质量
- 文档更新:及时更新相关文档,反映代码结构的变化
重构后的验证方法:
- 自动化测试:运行所有自动化测试,确保重构没有破坏现有功能
- 性能测试:比较重构前后的性能表现,确保没有性能退化
- 代码质量指标:使用AI工具再次分析代码,验证代码质量指标是否得到改善
- 用户反馈收集:收集用户和团队成员的反馈,确认重构带来的实际改进
- 长期监控:在生产环境中持续监控重构后的代码表现,及时发现问题
重构带来的收益:
- 可维护性提升:代码结构更清晰,更容易理解和修改
- 扩展性增强:更容易添加新功能和适应业务变化
- 团队效率提高:开发人员可以更快地定位和解决问题
- 技术债务减少:通过重构逐步消除积累的技术债务
- 代码质量文化建立:促进团队形成注重代码质量的文化氛围
### 6.5 场景五:跨语言项目的代码评审
**背景**:一个使用多种编程语言(JavaScript、Python和Java)的微服务项目,需要统一的代码评审标准
**AI评审过程**:
1. 使用DeepCode配置多语言支持
2. AI同时分析不同语言的代码库
3. AI识别跨语言的一致性问题和各语言特定的最佳实践
4. 团队根据AI建议统一各语言的代码风格和最佳实践
**代码示例**:
JavaScript原始代码(不一致的错误处理):
```javascript
function fetchData(url) {
try {
const response = await fetch(url);
const data = await response.json();
return data;
} catch (error) {
console.error('Error fetching data:', error);
throw new Error('Failed to fetch data');
}
}
Python原始代码(不一致的错误处理):
def process_data(file_path):
try:
with open(file_path, 'r') as f:
data = json.load(f)
return data
except Exception as e:
print(f"Error processing data: {e}")
return None
AI建议统一后的错误处理模式:
JavaScript优化后代码:
/**
* 从指定URL获取数据
* @param {string} url - 请求URL
* @returns {Promise<object>} - 返回的数据对象
* @throws {ApiError} - 当请求失败时抛出
*/
function fetchData(url) {
return fetch(url)
.then(response => {
if (!response.ok) {
throw new ApiError('API request failed', response.status);
}
return response.json();
})
.catch(error => {
logger.error('Error fetching data from', url, error);
// 重新抛出带有统一格式的错误
if (!(error instanceof ApiError)) {
throw new ApiError('Failed to fetch data', 500);
}
throw error;
});
}
Python优化后代码:
"""
处理数据文件
:param file_path: 数据文件路径
:return: 解析后的数据
:raises DataProcessingError: 当处理失败时抛出
"""
def process_data(file_path):
try:
with open(file_path, 'r') as f:
data = json.load(f)
return data
except json.JSONDecodeError as e:
logger.error(f"JSON decode error in {file_path}: {e}")
raise DataProcessingError(f"Invalid JSON format in {file_path}")
except FileNotFoundError:
logger.error(f"Data file not found: {file_path}")
raise DataProcessingError(f"Data file not found: {file_path}")
except Exception as e:
logger.error(f"Unexpected error processing {file_path}: {e}")
raise DataProcessingError(f"Failed to process data: {str(e)}")
跨语言项目的代码评审挑战:
- 语言差异:不同编程语言有不同的语法、特性和最佳实践
- 一致性维护:在多语言环境中保持一致的编码风格和设计模式
- 团队协作:不同语言背景的开发者可能有不同的习惯和偏好
- 工具支持:找到支持多种语言的统一评审工具
- 知识共享:跨语言项目中的知识共享和经验传递
AI评审在跨语言项目中的优势:
- 统一标准:AI可以帮助建立跨语言的统一评审标准和最佳实践
- 多语言支持:现代AI评审工具大多支持多种编程语言
- 模式识别:AI可以识别跨语言的设计模式和反模式
- 学习能力:AI可以从一个语言的最佳实践中学习,并应用到其他语言
- 自动化程度高:减少人工在多语言代码评审上的工作量
跨语言项目的最佳实践:
- 建立统一的代码评审策略:为不同语言制定一致的评审标准和流程
- 选择支持多语言的AI工具:如DeepCode、Codacy等支持多种编程语言的工具
- 代码风格统一:在可能的情况下,统一不同语言的代码风格和命名约定
- 设计模式共享:跨语言共享和应用相似的设计模式
- 定期交叉评审:组织不同语言团队之间的交叉评审,促进知识共享
七、AI代码评审的常见问题与解决方案
7.1 误报问题
问题描述:AI评审工具有时会报告一些实际上不是问题的"问题"
解决方案:
- 建立误报标记和忽略机制
- 为团队定制规则,减少不相关的警告
- 定期更新AI模型,提高准确性
- 对误报进行分析,反馈给工具提供商
7.2 漏报问题
问题描述:AI评审工具可能会漏掉一些实际存在的问题
解决方案:
- 结合使用多种AI评审工具
- 重要模块仍需人工重点审查
- 将历史问题作为训练数据,提高模型识别能力
- 建立问题反馈机制,及时发现和解决漏报问题
7.3 性能问题
问题描述:在大型代码库上运行AI评审可能会消耗大量资源和时间
解决方案:
- 增量评审:只评审变更的代码
- 配置合理的超时和资源限制
- 在CI/CD流程中合理安排评审时机
- 利用分布式计算提高评审速度
7.4 隐私和安全问题
问题描述:将代码发送到第三方AI评审服务可能存在隐私和安全风险
解决方案:
- 选择支持本地部署的AI评审工具
- 对敏感代码进行脱敏处理
- 建立严格的数据访问和处理政策
- 定期审计AI工具的安全合规性
7.5 适应团队规范问题
问题描述:AI评审工具可能不完全符合团队特定的代码规范和最佳实践
解决方案:
- 选择支持自定义规则的AI评审工具
- 为团队定制评审规则和阈值
- 对AI评审结果进行二次过滤和处理
- 将团队规范纳入AI模型的训练数据
八、AI代码评审的未来发展趋势
8.1 技术发展趋势
随着人工智能技术的不断进步,AI代码评审也在快速发展,未来可能的发展趋势包括:
- 更深度的代码理解:从语法分析到语义理解,更深入地理解代码意图
- 多模态评审:结合代码、文档、测试等多种信息进行综合评审
- 上下文感知:考虑业务上下文和系统架构,提供更符合实际场景的建议
- 实时评审:在编码过程中实时提供反馈,而不仅是在代码提交后
- 预测性评审:预测代码在未来可能出现的问题,防患于未然
8.2 对开发流程的影响
AI代码评审的普及将对软件开发流程产生深远影响:
- 开发模式变革:从"编码-测试-评审"向"编码+评审-测试"转变
- 角色重新定义:代码评审不再是特定角色的职责,而是融入每个开发者的日常工作
- 质量文化提升:代码质量将从"事后检查"转向"事中控制"和"事前预防"
- 团队协作增强:AI评审结果可以作为团队交流和学习的基础
8.3 挑战与机遇
AI代码评审的发展也面临一些挑战和机遇:
- 挑战:平衡自动化与人工判断、保护代码隐私、适应快速变化的技术栈
- 机遇:降低代码评审门槛、提高团队整体代码质量、促进知识共享和团队学习
- 伦理考量:确保AI评审的公平性、透明度和可解释性
- 生态系统发展:围绕AI代码评审将形成新的工具链和服务生态
九、总结与展望
AI代码评审正在改变我们开发和维护软件的方式,它不仅能提高代码质量和开发效率,还能帮助团队建立更好的代码文化和协作模式。
然而,我们也要认识到,AI代码评审不是万能的,它不能完全替代人工评审和专业判断。最佳的实践是将AI作为辅助工具,与人工评审相互补充,共同提升代码质量。
随着AI技术的不断发展,我们有理由相信,未来的AI代码评审工具将更加智能、更加实用,成为开发者不可或缺的智能助手。让我们拥抱这一技术变革,让AI助力我们写出更好的代码。
通过本文的介绍,相信你已经对AI代码评审有了全面的了解。无论是个人开发者还是开发团队,都可以根据自己的需求和场景,选择合适的AI代码评审工具和方法,让智能技术为你的代码质量保驾护航。
最后,创作不易请允许我插播一则自己开发的“数规规-排五助手”(有各种趋势分析)小程序广告,感兴趣可以微信小程序体验放松放松,程序员也要有点娱乐生活,搞不好就中个排列五了呢?
感兴趣的可以微信搜索小程序“数规规-排五助手”体验体验!或直接浏览器打开如下链接:
https://www.luoshu.online/jumptomp.html
可以直接跳转到对应小程序
如果觉得本文有用,欢迎点个赞👍+收藏🔖+关注支持我吧!

















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









