



了解它,有啥用?
上一篇[《ANR系列 --- 触发机制》](https://blog.youkuaiyun.com/welthy/article/details/144833942?spm=1001.2014.3001.5501)分析了系统是如何发现当时发生了ANR的。那么在发生ANR后,系统是如何打扫战场的呢?现在咱来唠唠。ANR打扫战场的目的是:为了记录下发生ANR时,应用和系统此时发生了啥。
它会把这些信息统一打包起来,咱在分析ANR时,也主要是通过这些打包的信息来还原现场,了解并分析触发ANR的具体原因。但,可惜的是,这份记录的信息系统并不会交给应用。所以对于许多三方应用来说,如何在线上环境下,发生ANR时能将这份记录信息由应用自身发回给后台服务器,若能办得到的话,三方应用就可以分析线上的ANR,从而更好的提供应用稳定性。
所以,了解ANR打扫战场的过程,一方面是为了了解系统是如何记录这些信息?(是否有三方应用能插一脚的地方🐶);其次是探索记录了哪些信息?我们分析时可以从哪些角度排查?
它是怎么干的?
它有什么?
首先了解一下,系统打扫战场用了哪些工具?- AnrHelper:ANR辅助类,之前分析触发机制时,无论从何处发生的ANR,最终都会经过AnrHelper来进行后续处理;
- ProcessRecord:进程的抽象,和进程是一对一的关系,记录了它基本信息;
- ProcessErrorStateRecord:进程异常状态记录。记录了ANR/Crash等的状态时的相关处理;
- ActivityManagerService(AMS):这个老熟人了,在这里主要起到中转的作用;
- AnrController:Anr弹框显示的延时控制;
它怎么干?
有了这些工具,就可以梳理整个战场打扫的过程了: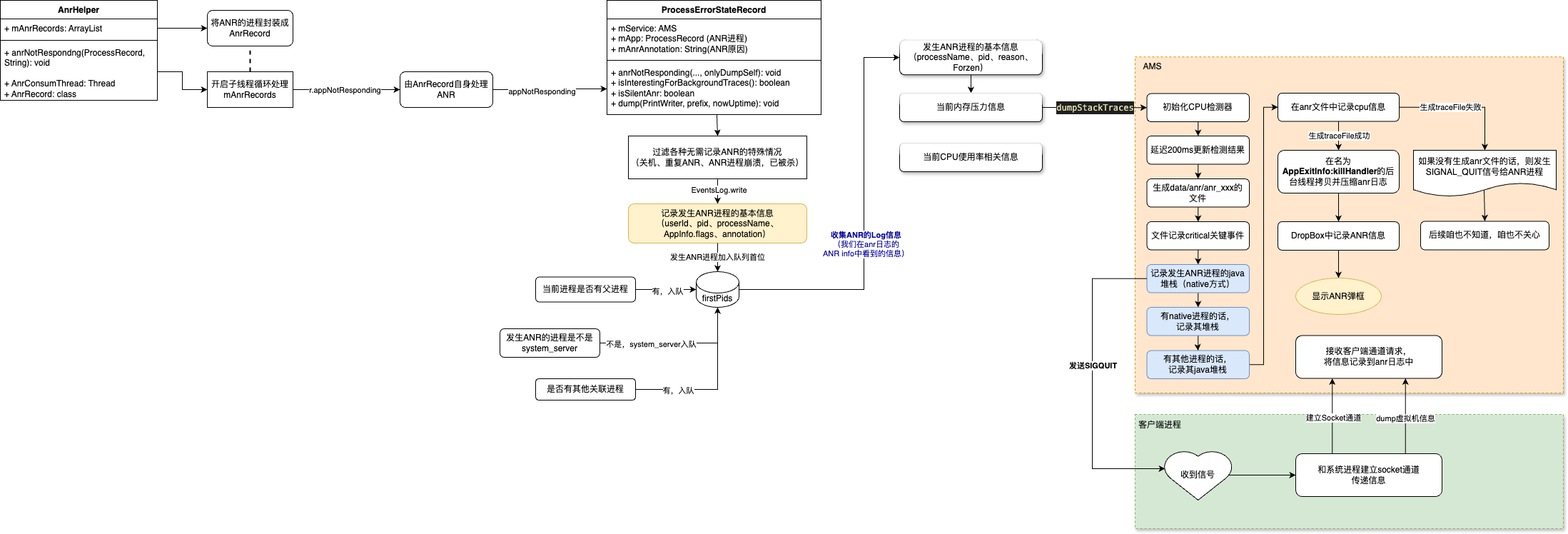
- 首先将ANR进程记录到AnrHelper的mAnrRecords集合中(加入之前会经过一轮筛选,如是否已经记录,是否进程id不对等);
- 循环遍历mAnrRecords集合,将错误处理交给发生Anr的进程对象ProcessRecord的错误状态记录对象ProcessErrorStateRecord;
- 然后,将当前进程id加入到firstIds集合中,其次将父进程(若有的话)加入集合,再将system_server的进程id加入集合,最后若有与当前进程关联的其他进程,则也将它们的进程id加入集合;(后续会根据该集合遍历进程id记录进程信息);
- ProcessErrorStateRecord排查一轮是否要记录该ANR状态(如进程是否已不存在、是否处于关机状态中等)。确定要记录时,则首先记录当前进程的基本信息(pid、processName等),同时打印日志(就是我们看到的ANR in那些信息);
- 搜集完后,系统开始记录当前的内存压力信息,CPU使用信息等;
- ☀️同时通知AMS生成/data/anr/anr_xxx日志文件,延迟200ms记录cpu的使用信息。遍历firstIds集合,记录当前进程的java堆栈、native进程堆栈(若有的话)、其他进程的java堆栈(若有的话)。将这些信息都记录在anr文件中;
- AMS生成anr文件成功后,会在后台线程(AppExltInfo:killHandler)中拷贝并压缩anr日志。同时记录anr信息到dropbox中;
- 记录完所有信息后,显示ANR弹框(“应用进程无响应”的弹框);
- AMS若生成anr文件失败的话,则会给当前进程发送SIGNAL_QUIT信号;(忽略,不是我们关心的内容);
小结:
打扫战场过程主要记录了3部分信息:系统环境信息(内存压力、CPU使用)、当前发生ANR进程的信息(java堆栈、native堆栈,虚拟机信息等)、与当前进程关联的其他进程信息(就是虚拟机的信息)。
插曲
在第6步中,AMS在dump各个进程信息的时候,其实也是需要和对应进程发生IPC通信,由该通信渠道记录对应进程虚拟机的状态信息。也是在这里各大厂商记录在线ANR发生的技术方案核心位置。在AMS需要记录发生ANR进程的虚拟机信息时,会发送SIGQUIT信号过去,客户端收到信号后和AMS建立socket通道,经由该通道传递虚拟机的信息。记录完后再回到AMS进程,继续记录后续的信息。该过程如下所示:
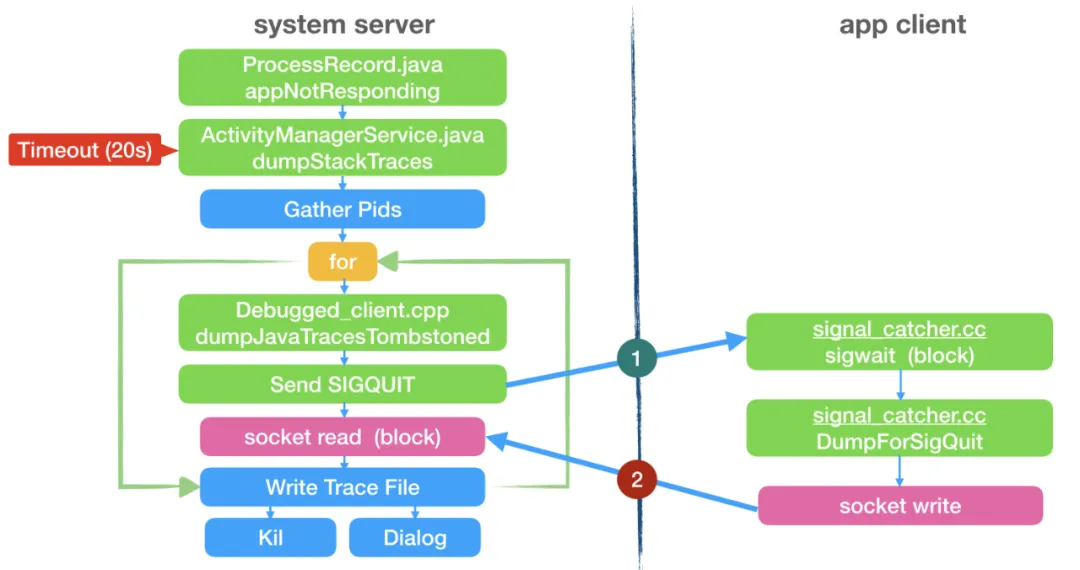
监控的详细方案会在后续单独一篇文章中记录。敬请期待~~~
我们能得到什么?
从上一篇《ANR系列 --- 触发机制》可知,发生ANR的原因是消息执行慢了,导致爆雷。消息执行慢的原因,有来自系统的原因;也有来自应用自身的原因;甚至可能来自其他应用的问题导致系统负载高,进而我们的应用去执行消息时,处理起来慢,最终咱爆雷了。。。(夭寿嘞~~~)无论是上述3类哪种原因,都需要系统信息、当前进程信息和其他进程的信息。所以系统发生ANR时,主要为咱记录的就是这几类信息。
那,有了这些信息后,咱要怎么看呢?(当然是用眼看啊,笨蛋!)这里我具体指的是,我怎么知道系统负载高了?我怎么知道是自己进程的问题导致ANR?甚至,我又咋知道是其他进程的问题导致ANR?
其实,这类问题就是性能问题,性能问题大家都懂的,并没有一刀切的具体方案,通常是根据一定的排查思路和经验去分析问题现场,来定位问题原因。
一个广播引发的血案
触发场景
//CustomReceiver
//咱也不搞太复杂,就直接在广播接收器里,读写文件
override fun onReceive(context: Context?, intent: Intent?) {
Log.d(TAG, "[onReceive] start")
val file = File(context?.filesDir?.absolutePath + "/test.txt")
if (!file.exists()) {
file.createNewFile()
}
Log.d(TAG, "file: ${file.absolutePath}")
val fileWriter = FileWriter(file)
for (i in 0..100000000000) {
fileWriter.write("This is line $i \n")
}
Log.w(TAG, "file write finish")
val sb = StringBuffer()
file.inputStream().use {
val available = it.available()
val cache = ByteArray(available)
it.read(cache)
sb.append(cache)
}
Log.d(TAG, "[onReceive] end")
}
//Activity中发一个有序广播
//MainActivty
btnSendBroadcastWithIo.setOnClickListener {
val intent = Intent("cn.wx.broadcast.custom")
intent.putExtra("IO", true)
sendOrderedBroadcast(intent, null)
}
问题分析
首先,导出anr日志。在日志中搜索am_anr关键字,结合问题发生的大致时间,确认日志中正确的ANR时间点

咱发生ANR就在最下面的那一条:
193827: 12-25 16:02:20.886 1000 1974 14637 I am_anr : [0,7926,com.example.ktapplication,550027078,Broadcast of Intent { act=cn.wx.broadcast.custom flg=0x2010 (has extras) }]
根据这条记录,再全局搜索ANR in关键字:
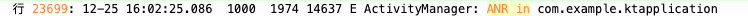
运气不错,就只有这一条信息,且时间点和am_anr搜索得到的问题时间点是对应的。那么从这里再查看相关信息:
12-25 14:03:55.294 1000 1974 32536 I ActivityManager: Done dumping
//1、发生ANR的进程
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: ANR in com.example.ktapplication
//2、发生ANR的进程ID
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: PID: 22794
//3、发生ANR的原因(如果是广播,此时就是对应的Intent信息)
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: Reason: Broadcast of Intent { act=cn.wx.broadcast.custom flg=0x2010 (has extras) }
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: Frozen: false
//4、内存在1s、5s、30s内因内存阻塞占用的时间占比
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: Load: 15.99 / 13.97 / 13.45
//5、内存压力信息。10s、60s、300s的平均内存占用情况
//some:至少有1个任务在运行的占用时长占总时长的占比
//full:全局非IDLE任务同时运行占用的时长占总时长的占比
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: ----- Output from /proc/pressure/memory -----
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: some avg10=1.24 avg60=1.45 avg300=0.40 total=1163559471
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: full avg10=1.20 avg60=1.39 avg300=0.39 total=532301783
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: ----- End output from /proc/pressure/memory -----
12-25 16:02:25.086 1000 1974 14637 E ActivityManager:
//6、以下是个进程占用CPU的情况。
//faults:缺页次数
//minor:较小内存碎片的缺页情况。可能因积累过多造成内存泄露等问题。过多的话,在GC时也会占用CPU较多的耗时
//major:严重的内存问题,数值较大说明IO问题较严重
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: CPU usage from 199151ms to 0ms ago (2024-12-25 14:00:33.280 to 2024-12-25 14:03:52.430):
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: 0.7% 22794/com.example.ktapplication: 0.6% user + 0% kernel / faults: 1249406 minor 209 major
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: 3.3% 1974/system_server: 2% user + 1.3% kernel / faults: 16191 minor 225 major
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: 1.4% 30608/kworker/u16:4-memlat_wq: 0% user + 1.4% kernel / faults: 43 minor
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: 1.2% 18492/adbd: 0.2% user + 0.9% kernel / faults: 1788 minor 4 major
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: 1.1% 928/logd: 0.3% user + 0.8% kernel / faults: 20 minor 4 major
补充说明:
- 第5点,内存压力信息说明,看下面的图更直观:
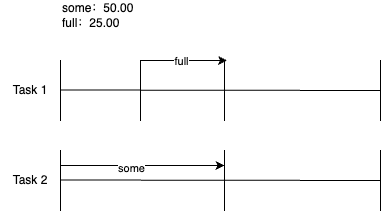
some就是至少有一个任务的耗时时长总和的时间占比。full就是所有非IDLE任务同时运行的耗时时长总和的时间占比
- 第6点,缺页次数:
GPT:当程序要访问的页面不在内存上,需要去磁盘上加载时,会发生一次缺页中断。缺页次数就是发生缺页中断的次数。
minor:简单理解,由内存管理本身进行内部调整即可,页面不需要从磁盘等外部存储调入物理内存。
major:简单理解,需要和物理存储进行交互了,将页面内容加载到内存中。
推论:
如上ANR in信息中的1、3可知发生ANR的原因是进程为"com.example.ktapplication"中的action为"cn.wx.broadcast.custom"的广播有异常造成了ANR。
并且,从4、5可知在发生ANR的最近1分钟内,内存压力还是挺大的。1分钟以后才逐渐缓解;从6可知,发生ANR进程的缺页次数情况也很严重,无论是minor还是major都远超其他进程(system_server进程因为涉及到anr日志读写,拷贝,打包等操作所以缺页次数也会相对较高)
其实,分析到这,已经可以推测是action为"cn.wx.broadcast.custom"的广播中存在耗时操作,并且是IO相关的操作导致ANR的发生。
当然,我们还能接着ANR in的内容接着往下看CPU使用率情况:
//该CPU使用率记录的时间段
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: CPU usage from 33ms to 412ms later (2024-12-25 14:03:52.464 to 2024-12-25 14:03:52.842):
//咱得进程CPU占用达到102%
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: 102% 22794/com.example.ktapplication: 97% user + 4% kernel / faults: 5397 minor
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: 93% 22794/e.ktapplication: 93% user + 0% kernel
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: 40% 1974/system_server: 15% user + 25% kernel / faults: 907 minor
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: 34% 32536/AnrConsumer: 9.4% user + 25% kernel
12-25 14:03:55.295 1000 1974 32536 E ActivityManager: 3.1% 4692/HwDualSensorEve: 3.1% user + 0% kernel
如上CPU使用率的信息可知,com.example.ktapplication进程占用CPU使用率达到102%,且用户态占用97%。结合上文,也可以推测,该进程在进行IO操作,自然占用CPU的使用率会较高。
一般,我们还需要往上排查日志,看看发生ANR前目标进程发生了啥,如:
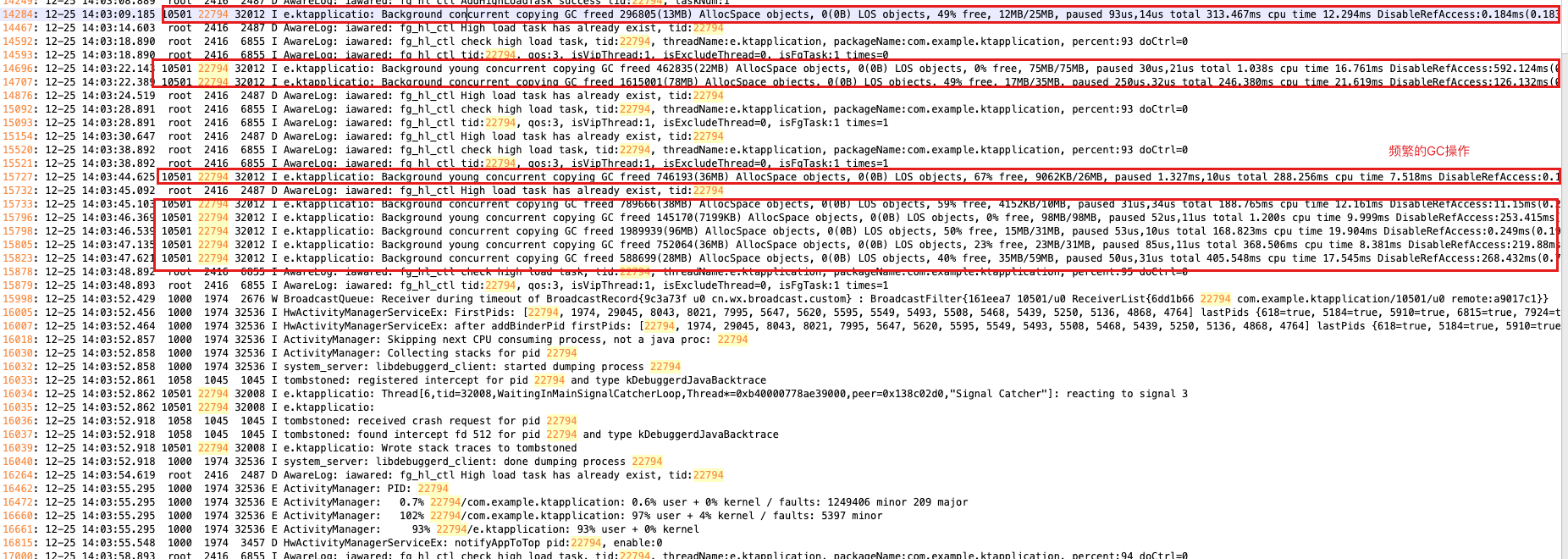
在频繁的进程GC操作,从这方面也可以得知目标进程的内存压力山大~~~
同时还能看目标进程中的线程信息,我们首先看主线程:
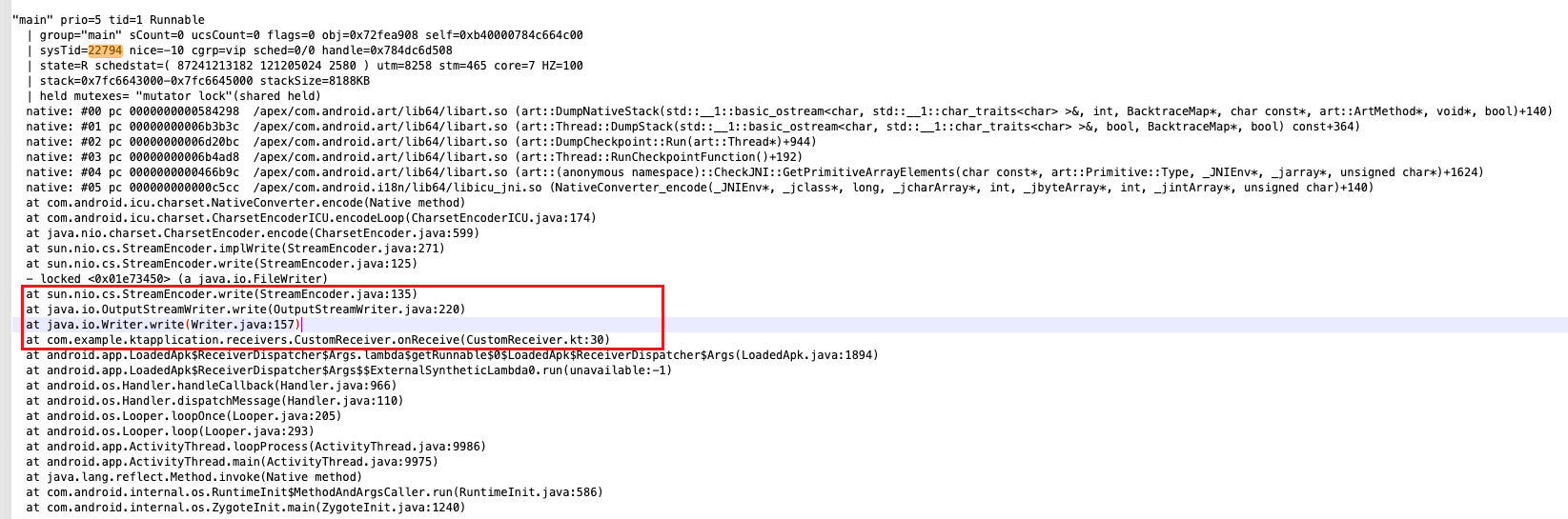
从主线程更清楚的能看到在广播接收器中,在进行IO操作。
😋插曲:
在排查目标进程日志的时候,看到了在打印ANR in之前的一段信息:

这个就是目标进程的Signal Cacher信号监听,收到了系统发送的signal 3也就是上文分析系统打扫战场过程中,系统通知目标进程dump虚拟机信息时发送的SIGQUIT信号。这在后续的监控方案整理中是重中之重了。
以上,是针对系统收集到的系统状态信息推测出发生ANR的原因。真实情况,往往会复杂的多。通常需要结合上下文查看当前用户的操作来还原触发现场。后面再分享各种案例积累经验。
在这要多一嘴,还是要多增加log,可以更快帮助我们定位问题,以及了解用户现场发生了啥。线上环境可采用native的方式记录日志,效率更高。
吐槽:
不过,系统记录的这些信息,往往并不能够帮助我们准确分析ANR原因,因为线上通常会遇到Looper消息阻塞的情况,但往往并不是当前的消息引起的ANR,而是消息队列中其他消息未结束,导致当前消息迟迟无法执行最终爆ANR了。这类问题,就需要建立良好的监控机制来辅助定位了。

















 894
894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









