









本篇技术博文摘要 🌟
- 基于树的定义和基本术语树的性质、二叉树的定义和基本术语各种二叉树的性质、二叉树的储存结构、二叉树的先中后序遍历、二叉树的层序遍历、由遍历序列构造二叉树、线索二叉树的概、念二叉树的线索化、在线索二叉树中找前驱后驱、树的储存结构树、和森林的遍历、BST、AVL、哈夫曼树、并查集、并查集的压缩路径的全方位的算法题试炼
引言 📘
- 在这个变幻莫测、快速发展的技术时代,与时俱进是每个IT工程师的必修课。
- 我是盛透侧视攻城狮,一名什么都会一丢丢的网络安全工程师,也是众多技术社区的活跃成员以及多家大厂官方认可人员,希望能够与各位在此共同成长。

上节回顾
目录

5.2二叉树基础算法题目:

- 已知一棵二叉树按顺序存储结构进行存储,设计一个算法,求编号分别为i和j的两个结点的最近的公共祖先结点的值.
- P144——5.2.4
知识补充:
- 首先,必须明确二叉树中任意两个结点必然存在最近的公共祖先结点,最坏的情况下是根结点(两个结点分别在根结点的左右分支中),而且从最近的公共祖先结点到根结点的全部祖先结点都是公共的。
- 由二叉树顺序存储的性质可知,任意一个结点i的双亲结点的编号为i/2。
代码算法实现思路:
- 求解i和j最近公共祖先结点的算法步骤如下(设从数组下标 1 开始存储):
- 1)若i>j,则结点i所在层次大于或等于结点j所在层次。结点i的双亲结点为结点 i/2,若 i/2=j,则结点 i/2 是原结点/和结点j的最近公共祖先结点,若 i/2j,则令 i=i/2,即以该结点i的双亲结点为起点,采用递归的方法继续查找。
- 2)若j>i,则结点j所在层次大于或等于结点i所在层次。结点j的双亲结点为结点j/2,若j/2=i,则结点j/2 是原结点i和结点j的最近公共祖先结点,若j/2!=i,则令j=j/2。
- 重复上述过程,直到找到它们最近的公共祖先结点为止。
#include <stdio.h>
#define MAXSIZE 100 // 假设二叉树顺序存储的最大容量
typedef char ElemType;
typedef ElemType SqTree[MAXSIZE]; // 顺序存储二叉树类型
// 在二叉树中查找结点i和结点j的最近公共祖先结点
ElemType Comm_Ancestor(SqTree T, int i, int j, int tree_size) {
// 检查结点编号是否越界
if (i < 1 || i > tree_size || j < 1 || j > tree_size) {
printf("结点编号越界\n");
return '\0';
}
// 检查结点是否存在(假设'#'表示空结点)
if (T[i] != '#' && T[j] != '#') {
while (i != j) { // 两个编号不同时循环
if (i > j) {
i = i / 2; // 向上找i的祖先
} else {
j = j / 2; // 向上找j的祖先
}
}
return T[i];
}
printf("结点不存在\n");
return '\0';
}
int main() {
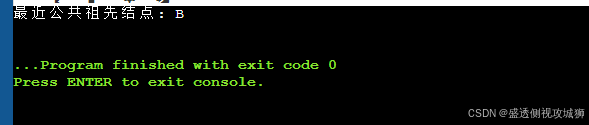
SqTree tree = {'#', 'A', 'B', 'C', 'D', 'E', 'F', 'G'}; // 示例二叉树(1号位置开始存储)
int size = 7; // 二叉树实际结点数
char ancestor = Comm_Ancestor(tree, 4, 5, size);
if (ancestor != '\0') {
printf("最近公共祖先结点: %c\n", ancestor);
}
return 0;
}
5.3二叉树的遍历和线索二叉树算法题目:
5.3.03题:
![]()
代码算法实现思路:
- 后序非递归遍历二叉树先访问左子树,再访问右子树,最后访问根结点。
- ①沿着根的左孩子,依次入栈,直到左孩子为空。
- ②读栈顶元素:若其右孩子不空且未被访问过,将右子树转执行①;
- 否则,栈顶元素出栈并访问。
注意:
第②步中必须分清返回时是从左子树返回的还是从右子树返回的,因此设定一个辅助指针r,用于指向最近访问过的结点。
也可在结点中增加一个标志域,记录是否已被访问。
核心代码实现:
void PostOrder(BiTree T) {
InitStack(S); // 初始化栈S
BiTNode *p = T; // 指针p指向根节点
BiTNode *r = NULL; // r记录最近访问过的节点,初始化为NULL
while (p || !IsEmpty(S)) { // 当p不为空或栈不为空时循环
if (p) { // 走到最左边
Push(S, p); // 将当前节点压入栈
p = p->lchild; // 向左子树移动
} else { // 处理向右的情况
GetTop(S, p); // 读取栈顶节点(不出栈)
if (p->rchild && p->rchild != r) { // 若右子树存在,且未被访问过
p = p->rchild; // 转向右子树
} else { // 否则,弹出节点并访问
Pop(S, p); // 将节点弹出栈
visit(p->data); // 访问该节点的数据
r = p; // 记录最近访问过的节点
p = NULL; // 节点访问完后,重置p指针,避免重复处理
}
}
}
}5.3.04题:
![]()
代码算法实现思路:
- 一般的二叉树层次遍历是自上而下、从左到右,这里的遍历顺序恰好相反。
- 利用原有的层次遍历算法,出队的同时将各结点指针入栈,在所有结点入栈后再从栈顶开始依次访问即为所求的算法。
- 具体实现如下:
- 1)把根结点入队列。
- 2)把一个元素出队列,遍历这个元素。
- 3)依次把这个元素的左孩子、右孩子入队列。
- 4)若队列不空,则跳到2),否则结束。
核心代码实现:
// 函数功能:对二叉树进行逆层次遍历(自下而上、从右到左)
void InvertLevel(BiTree bt) {
Stack s; // 定义栈,用于后续存储结点实现逆序
Queue Q; // 定义队列,用于层次遍历
if (bt != NULL) {
InitStack(s); // 初始化栈,栈中存放二叉树结点的指针
InitQueue(Q); // 初始化队列,队列中存放二叉树结点的指针
EnQueue(Q, bt); // 将根结点入队,启动层次遍历
BiTNode *p; // 声明指针p,用于操作当前处理的结点
while (!IsEmpty(Q)) { // 队列非空时,执行从上而下的常规层次遍历
DeQueue(Q, p); // 结点出队,取出当前访问的结点
Push(s, p); // 将出队的结点入栈,为逆序输出做准备
if (p->lchild)
EnQueue(Q, p->lchild); // 若左子树存在,左子树结点入队
if (p->rchild)
EnQueue(Q, p->rchild); // 若右子树存在,右子树结点入队
}
while (!IsEmpty(s)) { // 栈非空时,处理栈中结点实现逆序输出
Pop(s, p); // 栈顶结点出栈
visit(p->data); // 访问结点数据,实现自下而上、从右到左的层次遍历
}
}
}
5.3.05题:
![]()
代码算法实现思路:
- 采用层次遍历的算法,设置变量level记录当前结点所在的层数,设置变量last指向当前层的最右结点
- 每次层次遍历出队时与last指针比较,若两者相等,则层数加1,并让1ast指向下一层的最右结点,直到遍历完成。level 的值即为二叉树的高度。
核心代码实现:
int Btdepth(BiTree T) {
//采用层次遍历的非递归方法求解二叉树的高度
if (!T)
return 0; //树空,高度为0
int front = -1, rear = -1;
int last = 0, level = 0; //last指向当前层的最右结点
BiTree Q[MaxSize]; //设置队列Q,元素是二叉树结点指针且容量足够
Q[++rear] = T; //将根结点入队
BiTree p;
while (front < rear) { //队不空,则循环
p = Q[++front]; //队列元素出队,即正在访问的结点
if (p->lchild)
Q[++rear] = p->lchild; //左孩子入队
if (p->rchild)
Q[++rear] = p->rchild; //右孩子入队
if (front == last) { //处理该层的最右结点
level++; //层数增1
last = rear; //last指向下层
}
}
return level;
}补充:
- 求某层的结点个数、每层的结点个数、树的最大宽度等,都可采用与此题类似的思想。当然,此题可编写为递归算法,其实现如下:
int Btdepth2(BiTree T) { if (T == NULL) return 0; //空树,高度为0 int ldep = Btdepth2(T->lchild); //左子树高度 int rdep = Btdepth2(T->rchild); //右子树高度 if (ldep > rdep) return ldep + 1; //树的高度为子树最大高度加根结点 else return rdep + 1; }
5.3.06题:
代码算法实现思路:
- 根据完全二叉树的定义,具有n个结点的完全二叉树与满二叉树中编号从1~n的结点一一对应。
- 所以我们可以采用层次遍历算法,将所有结点加入队列(包括空结点)。遇到空结点时,查看其后是否有非空结点。若有,则二叉树不是完全二叉树。
核心代码实现:
bool IsComplete(BiTree T) {
// 本算法判断给定二叉树是否为完全二叉树
InitQueue(Q); // 初始化辅助队列Q
if (!T) {
return true; // 空树视为完全二叉树,直接返回true
}
EnQueue(Q, T); // 将根节点入队
while (!IsEmpty(Q)) {
DeQueue(Q, p); // 队头节点出队,赋值给p
if (p) {
// 若当前节点非空,将其左、右子树入队列
EnQueue(Q, p->lchild);
EnQueue(Q, p->rchild);
} else {
// 若当前节点为空,检查后续是否有非空节点
while (!IsEmpty(Q)) {
DeQueue(Q, p);
if (p) {
// 若后续存在非空节点,说明不是完全二叉树
return false;
}
}
}
}
return true; // 队列处理完毕,未发现非完全二叉树的情况,返回true
}
5.3.07题:

代码算法实现思路:
- 计算一棵二叉树b中所有双分支结点个数的递归模型f(b)如下:

核心代码实现:
// 函数功能:计算二叉树中双分支结点(同时有左孩子和右孩子的结点)的数量
int DSonNodes(BiTree b) {
// 若二叉树为空,双分支结点数量为0
if (b == NULL)
return 0;
// 若当前结点是双分支结点(左孩子和右孩子都不为空)
else if (b->lchild != NULL && b->rchild != NULL)
// 递归计算左子树双分支结点数 + 右子树双分支结点数 + 当前双分支结点(+1)
return DSonNodes(b->lchild) + DSonNodes(b->rchild) + 1;
else
// 若当前结点不是双分支结点,递归计算左子树和右子树的双分支结点数之和
return DSonNodes(b->lchild) + DSonNodes(b->rchild);
}
- 当然,本题也可以设置一个全局变量Num,每遍历到一个结点时,判断每个结点是否为分支结点(左、右结点都不为空,注意是双分支),若是则Num++。
5.3.08题:

代码算法实现思路:
- 采用递归算法实现交换二叉树的左、右子树
- 首先交换b结点的左孩子的左、右子树
- 然后交换b结点的右孩子的左、右子树
- 最后交换b结点的左、右孩子,当结点为空时递归结束(后序遍历的思想)。
核心代码实现:
void swap(BiTree b) {
// 本算法递归地交换二叉树的左、右子树
if (b) {
swap(b->lchild); // 递归调用函数,交换当前节点的左子树
swap(b->rchild); // 递归调用函数,交换当前节点的右子树
// 交换当前节点的左、右子树
BiTNode *temp; // 定义临时指针,用于暂存左子树指针
temp = b->lchild; // 保存左子树指针
b->lchild = b->rchild; // 将右子树指针赋值给左子树指针
b->rchild = temp; // 将暂存的左子树指针赋值给右子树指针
}
}5.3.09题:

代码算法实现思路:
- 设置一个全局变量i(初值为1)来表示进行先序遍历时,当前访问的是第几个结点。
- 然后可以借用先序遍历的代码模型,先序遍历二叉树。
- 当二叉树b为空时,返回特殊字符'#';当 k==i时,该结点即为要找的结点,返回b->data;
- 当k≠i时,递归地在左子树中查找,若找到则返回该值,否则继续递归地在右子树中查找,并返回其结果。
核心代码实现:
#include <stdio.h>
// 假设二叉树结点类型定义(需提前定义)
typedef struct BiTNode {
char data;
struct BiTNode *lchild, *rchild;
} BiTNode, *BiTree;
typedef char ElemType; // 假设元素类型为字符型
int i = 1; // 定义遍历序号的全局变量,用于记录当前访问到先序遍历的第几个结点
ElemType PreNode(BiTree b, int k) {
// 算法功能:查找二叉树先序遍历序列中第k个结点的值
if (b == NULL) { // 若当前结点为空结点
return '#'; // 返回特殊字符'#'表示空结点
}
if (i == k) { // 若当前遍历序号i与目标序号k相等
return b->data; // 当前结点即为先序遍历第k个结点,返回其数据
}
i++; // 遍历序号递增,准备访问下一个结点
ElemType ch;
ch = PreNode(b->lchild, k); // 递归在左子树中寻找先序遍历第k个结点
if (ch != '#') { // 若在左子树中找到目标结点(非空结点返回值)
return ch; // 返回左子树中找到的目标结点值
}
ch = PreNode(b->rchild, k); // 递归在右子树中寻找先序遍历第k个结点
return ch; // 返回右子树中找到的结果(可能是目标结点值或'#')
}补充:
- 本题实质上就是一个遍历算法的实现,只不过用一个全局变量来记录访问的序号,求其他遍历序列的第k个结点也采用相似的方法。
5.3.10题: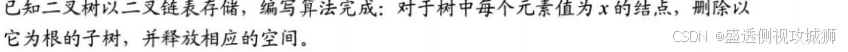
代码算法实现思路:
- 删除以元素值x为根的子树,只要能删除其左、右子树,就可以释放值为x的根结点,因此宜采用后序遍历。
- 删除值为x的结点,意味着应将其父结点的左(右)子女指针置空,用层次遍历易于找到某结点的父结点。
- 本题要求删除树中每个元素值为x的结点的子树,因此要遍历完整棵二叉树。
核心代码实现:
// 删除以bt为根的子树
void DeleteXTree(BiTree bt) {
if (bt) {
DeleteXTree(bt->lchild); // 递归删除bt的左子树
DeleteXTree(bt->rchild); // 递归删除bt的右子树
free(bt); // 释放被删结点所占的存储空间
}
}
// 在二叉树上查找所有以x为元素值的结点,并删除以其为根的子树
void Search(BiTree bt, ElemType x) {
BiTree Q[]; // Q是存放二叉树结点指针的队列,容量足够大
if (bt) {
if (bt->data == x) { // 若根结点值为x,则删除整棵树
DeleteXTree(bt);
exit(0);
}
InitQueue(Q);
EnQueue(Q, bt); // 根节点入队
while (!IsEmpty(Q)) {
DeQueue(Q, p); // 队头节点出队
// 处理左子树
if (p->lchild) { // 若左子女非空
if (p->lchild->data == x) { // 左子树符合条件则删除左子树
DeleteXTree(p->lchild);
p->lchild = NULL; // 父结点的左子女置空
} else {
EnQueue(Q, p->lchild); // 左子树入队列
}
}
// 处理右子树
if (p->rchild) { // 若右子女非空
if (p->rchild->data == x) { // 右子女符合则删除右子树
DeleteXTree(p->rchild);
p->rchild = NULL; // 父结点的右子女置空
} else {
EnQueue(Q, p->rchild); // 右子女入队列
}
}
}
}
}5.3.11.题:
- 在二叉树中查找值为x的结点,试编写算法(用C语言)打印值为x的结点的所有祖先,
代码算法实现思路:
- 采用非递归后序遍历,最后访问根结点,访问到值为x的结点时,栈中所有元素均为该结点的祖先,依次出栈打印即可。
核心代码实现:
// 定义栈的结构体,用于存储二叉树节点和访问标记
typedef struct{
BiTree t; // 存储二叉树节点指针
int tag; // tag=0表示左子女未被访问,tag=1表示右子女已被访问
} stack;
// 在二叉树bt中,查找值为x的结点,并打印其所有祖先
void Search(BiTree bt, ElemType x) {
stack s[]; // 定义栈s,容量足够大
int top = 0; // 栈顶指针初始化
while (bt != NULL || top > 0) { // 树未空或栈不为空时循环
// 沿左分支向下遍历,将路径入栈
while (bt != NULL && bt->data != x) {
s[++top].t = bt; // 节点入栈
s[top].tag = 0; // 标记左子女未访问
bt = bt->lchild; // 转向左子树
}
if (bt != NULL && bt->data == x) { // 找到值为x的节点
printf("所查结点的所有祖先结点的值为:\n");
for (int i = 1; i <= top; i++)
printf("%d ", s[i].t->data); // 输出所有祖先值
exit(1); // 找到目标后结束程序
}
// 处理栈顶元素(左子树遍历完成)
while (top != 0 && s[top].tag == 1)
top--; // 退栈(空遍历)
if (top != 0) { // 处理右子树
s[top].tag = 1; // 标记右子女已访问
bt = s[top].t->rchild; // 转向右子树继续遍历
}
}
}
- 因为查找的过程就是后序遍历的过程,所以使用的栈的深度不超过树的深度。
5.3.12题:
代码算法实现思路:
- 后序遍历最后访问根结点,即在递归算法中,根是压在栈底的。
- 本题要找p和q的最近公共祖先结点r,不失一般性,设p在q的左边。
- 思想:采用后序非递归算法,栈中存放二叉树结点的指针,当访问到某结点时,栈中所有元素均为该结点的祖先。
- 后序遍历必然先遍历到结点p,栈中元素均为p的祖先。
- 先将栈复制到另一辅助栈中。
- 继续遍历到结点q时,将栈中元素从栈顶开始逐个到辅助栈中去匹配,第一个匹配(即相等)的元素就是结点p和q的最近公共祖先。
核心代码实现:
// 定义栈的结构体,用于存储二叉树节点和访问标记
typedef struct{
BiTree t; // 存储二叉树节点指针
int tag; // tag=0表示左子女已被访问,tag=1表示右子女已被访问
} stack;
stack s[], s1[]; // 定义栈s和辅助栈s1,容量足够大
// 本算法求二叉树中p和q指向结点的最近公共结点
BiTree Ancestor(BiTree ROOT, BiTNode *p, BiTNode *q) {
int top = 0; // 栈顶指针初始化
BiTree bt = ROOT; // 从根节点开始遍历
while (bt != NULL || top > 0) { // 树未空且栈不为空时循环
// 沿左分支向下遍历,将路径入栈
while (bt != NULL) {
s[++top].t = bt; // 节点入栈
s[top].tag = 0; // 标记左子女未访问
bt = bt->lchild; // 转向左子树
}
// 处理栈顶元素(左子树遍历完成)
while (top != 0 && s[top].tag == 1) {
// 假定p在q的左侧,遇到p时,栈中元素均为p的祖先
if (s[top].t == p) { // 找到p节点
for (int i = 1; i <= top; i++) // 将栈s的元素转入辅助栈s1保存
s1[i] = s[i];
top1 = top; // 记录辅助栈s1的栈顶
}
if (s[top].t == q) { // 找到q节点
for (int i = top; i > 0; i--) { // 从栈顶开始匹配
for (int j = top1; j > 0; j--) {
if (s1[j].t == s[i].t) // 找到公共祖先
return s[i].t;
}
}
}
top--; // 退栈
}
if (top != 0) { // 处理右子树
s[top].tag = 1; // 标记右子女已访问
bt = s[top].t->rchild; // 转向右子树
}
}
return NULL; // p和q无公共祖先时返回
}5.3.13题:
代码算法实现思路:
- 采用层次遍历的方法求出所有结点的层次,并将所有结点和对应的层次放在一个队列中。
- 然后通过扫描队列求出各层的结点总数,最大的层结点总数即为二叉树的宽度。
核心代码实现:
// 定义队列结构体,用于层次遍历存储二叉树节点及其层次信息
typedef struct{
BiTree data[MaxSize]; // 存储队列中的二叉树结点指针,MaxSize为预设的足够大容量
int level[MaxSize]; // 记录data数组中对应下标结点所在的层次
int front, rear; // 队列的头指针和尾指针,用于队列操作
} Qu;
// 计算二叉树的宽度(即二叉树中结点数最多的层的结点个数)
int BTWidth(BiTree b) {
BiTree p; // 临时存储出队的二叉树节点
int k, max, i, n; // k:当前处理节点的层次;max:记录最大宽度;i:循环变量;n:统计当前层节点数
Qu.front = Qu.rear = -1; // 初始化队列,队头和队尾指针指向-1表示队列为空
Qu.rear++; // 先移动尾指针
Qu.data[Qu.rear] = b; // 将根结点指针入队
Qu.level[Qu.rear] = 1; // 根结点的层次设为1
// 层次遍历二叉树,处理每个节点的左右子树入队
while (Qu.front < Qu.rear) {
Qu.front++; // 队头节点出队
p = Qu.data[Qu.front]; // 获取出队的节点
k = Qu.level[Qu.front]; // 获取出队节点的层次
if (p->lchild != NULL) { // 左孩子存在则入队
Qu.rear++;
Qu.data[Qu.rear] = p->lchild;
Qu.level[Qu.rear] = k + 1; // 左孩子层次为当前层+1
}
if (p->rchild != NULL) { // 右孩子存在则入队
Qu.rear++;
Qu.data[Qu.rear] = p->rchild;
Qu.level[Qu.rear] = k + 1; // 右孩子层次为当前层+1
}
}
max = 0; i = 0; // 初始化最大宽度和遍历索引
k = 1; // 从第1层开始统计
// 遍历队列,统计每一层的节点数,找到最大宽度
while (i <= Qu.rear) {
n = 0; // 重置当前层节点数统计
// 统计当前层k的节点数
while (i <= Qu.rear && Qu.level[i] == k) {
n++;
i++;
}
k = Qu.level[i]; // 移动到下一层
if (n > max) max = n; // 更新最大宽度
}
return max; // 返回二叉树的最大宽度
}补充:
- 本题队列中的结点,在出队后仍需要保留在队列中,以便求二叉树的宽度,所以设置的队列采用非环形队列,否则在出队后可能被其他结点覆盖,无法再求二叉树的宽度。
5.3.14题:
代码算法实现思路:
- 对一般二叉树,仅根据先序或后序序列,不能确定另一个遍历序列。
- 但对满二叉树,任意一个结点的左、右子树均含有相等的结点数,同时,先序序列的第一个结点作为后序序列的最后一个结点,由此得到将先序序列pre[11..h1]转换为后序序列 post[12..h2]的递归模型如下:
#include <stdio.h> // 假设元素类型为字符型 typedef char ElemType; // 函数功能:根据先序和后序序列构建二叉树(核心转换逻辑) // pre: 先序序列数组;l1: 先序序列左边界;h1: 先序序列右边界 // post: 后序序列数组;l2: 后序序列左边界;h2: 后序序列右边界 void buildTree(ElemType pre[], int l1, int h1, ElemType post[], int l2, int h2) { if (h1 < l1) { // h1 < l1 时,当前子树无有效结点,不做处理 return; } post[h2] = pre[l1]; // 后序序列的最后一个结点(根结点)等于先序序列的第一个结点 if (l1 == h1) { // 若当前子树只有一个结点,处理完成 return; } int half = (h1 - l1) / 2; // 计算中间位置(假设左右子树结点数均分,实际需更精确逻辑,此处为简化示例) // 处理左子树:将先序左子树部分转换为后序左子树部分 buildTree(pre, l1 + 1, l1 + half, post, l2, l2 + half - 1); // 处理右子树:将先序右子树部分转换为后序右子树部分 buildTree(pre, l1 + half + 1, h1, post, l2 + half, h2 - 1); } int main() { ElemType pre[] = {'A', 'B', 'C'}; ElemType post[3]; buildTree(pre, 0, 2, post, 0, 2); for (int i = 0; i < 3; i++) { printf("%c ", post[i]); } return 0; }
核心代码实现:
// 将先序序列转换为后序序列的递归函数
// pre[]: 先序序列数组;ll: 先序序列左边界;hl: 先序序列右边界
// post[]: 后序序列数组;l2: 后序序列左边界;h2: 后序序列右边界
void PreToPost(ElemType pre[], int ll, int hl, ElemType post[], int l2, int h2) {
int half;
if (hl >= ll) {
post[h2] = pre[ll]; // 先序的第一个元素是根节点,放在后序的最后位置
half = (hl - ll) / 2; // 计算左右子树的长度分界
// 递归转换左子树:先序左子树范围 [ll+1, ll+half],后序左子树范围 [l2, l2+half-1]
PreToPost(pre, ll + 1, ll + half, post, l2, l2 + half - 1);
// 递归转换右子树:先序右子树范围 [ll+half+1, hl],后序右子树范围 [l2+half, h2-1]
PreToPost(pre, ll + half + 1, hl, post, l2 + half, h2 - 1);
}
}
// 示例代码
int main() {
ElemType *pre = "ABCDEFG"; // 定义先序序列
ElemType post[MaxSize]; // 存储后序序列的数组
// 调用转换函数:先序范围 [0, 6],后序范围 [0, 6]
PreToPost(pre, 0, 6, post, 0, 6);
printf("后序序列: ");
for (int i = 0; i <= 6; i++)
printf("%c", post[i]); // 输出后序序列
printf("\n");
return 0;
}5.3.15题:
代码算法实现思路:
- 通常使用的先序、中序和后序遍历对于叶结点的访问顺序都是从左到右,这里选择中序递归遍历。
- 思想:
- 设置前驱结点指针pre,初始为空。
- 第一个叶结点由指针 head 指向,遍历到叶结点时,就将它前驱的rchild指针指向它,最后一个叶结点的rchild为空。
核心代码实现:
LinkedList head, pre = NULL; // 全局变量,head存储链表头节点,pre指向链表中当前最后一个节点
// 中序遍历二叉树,将叶节点链入链表
LinkedList InOrder(BiTree bt) {
if (bt) {
InOrder(bt->lchild); // 递归中序遍历左子树
// 处理叶节点(左右子树均为空)
if (bt->lchild == NULL && bt->rchild == NULL) {
if (pre == NULL) { // 处理第一个叶节点
head = bt; // 第一个叶节点作为链表头
pre = bt; // pre指向头节点
} else {
pre->rchild = bt; // 将当前叶节点链到pre之后
pre = bt; // 更新pre到当前叶节点
}
}
InOrder(bt->rchild); // 递归中序遍历右子树
pre->rchild = NULL; // 设置链表尾,确保最后一个节点的rchild为空
}
return head; // 返回叶节点组成的链表头指针
}
// 算法时间复杂度为O(n),遍历每个节点;辅助变量head和pre,递归栈空间复杂度O(n)(最坏情况树退化为链表)5.3.16题:
代码算法实现思路:
- 采用递归的思想求解,若T?和T?都是空树,则相似
- 若有一个为空另一个不空,则必然不相似;否则递归地比较它们的左、右子树是否相似。
核心代码实现:
int similar(BiTree T1, BiTree T2) {
// 采用递归的算法判断两棵二叉树是否相似
int leftS, rightS;
if (T1 == NULL && T2 == NULL) {
// 若两棵树均为空,空树彼此相似,返回1
return 1;
} else if (T1 == NULL || T2 == NULL) {
// 若只有一棵树为空,另一棵非空,不相似,返回0
return 0;
} else {
// 递归判断左右子树是否相似
leftS = similar(T1->lchild, T2->lchild); // 递归判断左子树相似性
rightS = similar(T1->rchild, T2->rchild); // 递归判断右子树相似性
return leftS && rightS; // 只有左右子树都相似,整棵树才相似,返回逻辑与结果
}
}5.3.17题: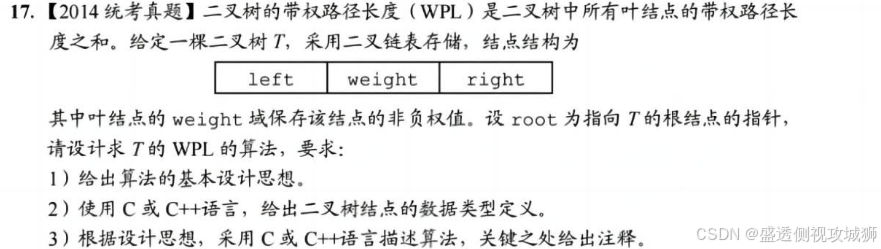
代码算法实现思路:
- ① 本问题可采用递归算法实现。
- 根据定义:二叉树的 WPL值 = 树中全部叶结点的带权路径长度之和=根结点左子树中全部叶结点的带权路径长度之和 +根结点右子树中全部叶结点的带权路径长度之和叶结点的带权路径长度 =该结点的 weight 域的值×该结点的深度设根结点的深度为0,若某结点的深度为d时,则其孩子结点的深度为d+1。
- 在递归遍历二叉树结点的过程中,若遍历到叶结点,则返回该结点的带权路径长度,否则返回其左右子树的带权路径长度之和。
- ② 若借用非叶结点的 weight 域保存其孩子结点中 weight 域值的和,则树的 WPL等于树中所有非叶结点 weight 域值之和。
- 采用后序遍历策略,在遍历二叉树T时递归计算每个非叶结点的 weight 域的值,则树 T的WPL等于根结点左子树的WPL加上右子树的WPL,再加上根结点中weight 域的值。
- 在递归遍历二叉树结点的过程中,若遍历到叶结点,则 return 0并且退出递归,否则递归计算其左右子树的 WPL和自身结点的权值。
核心代码实现:
// 定义二叉树节点结构体
typedef struct node{
int weight; // 节点的权值
struct node *left, *right; // 左右子树指针
} BTree;
// ① 基于方法1的算法实现:根据WPL定义的递归算法
int WPL(BTree *root) {
// 调用辅助函数WPL1,初始深度为0
return WPL1(root, 0);
}
// 计算带权路径长度的辅助函数
int WPL1(BTree *root, int d) { // d为当前节点的深度
// 若当前节点是叶子节点(左右子树均为空)
if(root->left == NULL && root->right == NULL)
return (root->weight * d); // 返回叶子节点的权值乘以深度
else
// 递归计算左子树和右子树的WPL,累加结果
return (WPL1(root->left, d + 1) + WPL1(root->right, d + 1));
}
// ② 基于方法2的算法实现:基于递归后序遍历的算法
int WPL(BTree *root) {
int w_l, w_r; // 存储左右子树的WPL
// 若当前节点是叶子节点
if(root->left == NULL && root->right == NULL)
return 0; // 叶子节点的WPL贡献初始为0
else {
w_l = WPL(root->left); // 递归计算左子树的WPL
w_r = WPL(root->right); // 递归计算右子树的WPL
// 更新非叶节点的weight为左右子节点weight之和(模拟构建哈夫曼树过程)
root->weight = root->left->weight + root->right->weight;
// 返回左右子树WPL之和加上当前非叶节点的weight(当前层路径和贡献)
return (w_l + w_r + root->weight);
}
}补充:
- 标答的报错:当遍历到度为1的结点时,会传入空指针,导致空指针异常
5.3.18题: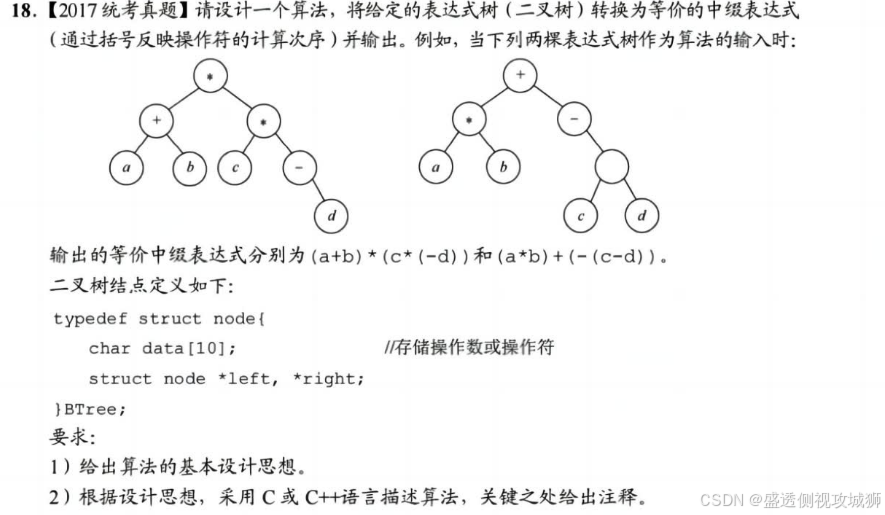
代码算法实现思路:
- 表达式树的中序序列加上必要的括号即为等价的中缀表达式。可以基于二叉树的中序遍历策略得到所需的表达式。
- 表达式树中分支结点所对应的子表达式的计算次序,由该分支结点所处的位置决定。为得到正确的中缀表达式,需要在生成遍历序列的同时,在适当位置增加必要的括号。
- 显然,表达式的最外层(对应根结点)和操作数(对应叶结点)不需要添加括号。
- 综上:
- 除根结点和叶结点外,遍历到其他结点时在遍历其左子树之前加上左括号,遍历完右子树后加上右括号。
核心代码实现:
// 假设BTree结构体已定义(含data等成员),以下为二叉树转换相关函数
void BtreeToE(BTree *root) {
BtreeToExp(root, 1); // 调用递归函数,初始化根节点高度为1
}
void BtreeToExp(BTree *root, int deep) {
if (root == NULL) return; // 若当前节点为空,直接返回
else if (root->left == NULL && root->right == NULL) { // 若为叶结点
printf("%s", root->data); // 输出操作数,叶子节点无需括号
} else {
if (deep > 1) printf("("); // 若不是第一层,输出左括号(表示子表达式开始)
BtreeToExp(root->left, deep + 1); // 递归处理左子树,深度+1
printf("%s", root->data); // 输出当前节点的操作符
BtreeToExp(root->right, deep + 1); // 递归处理右子树,深度+1
if (deep > 1) printf(")"); // 若不是第一层,输出右括号(表示子表达式结束)
}
}5.3.19题: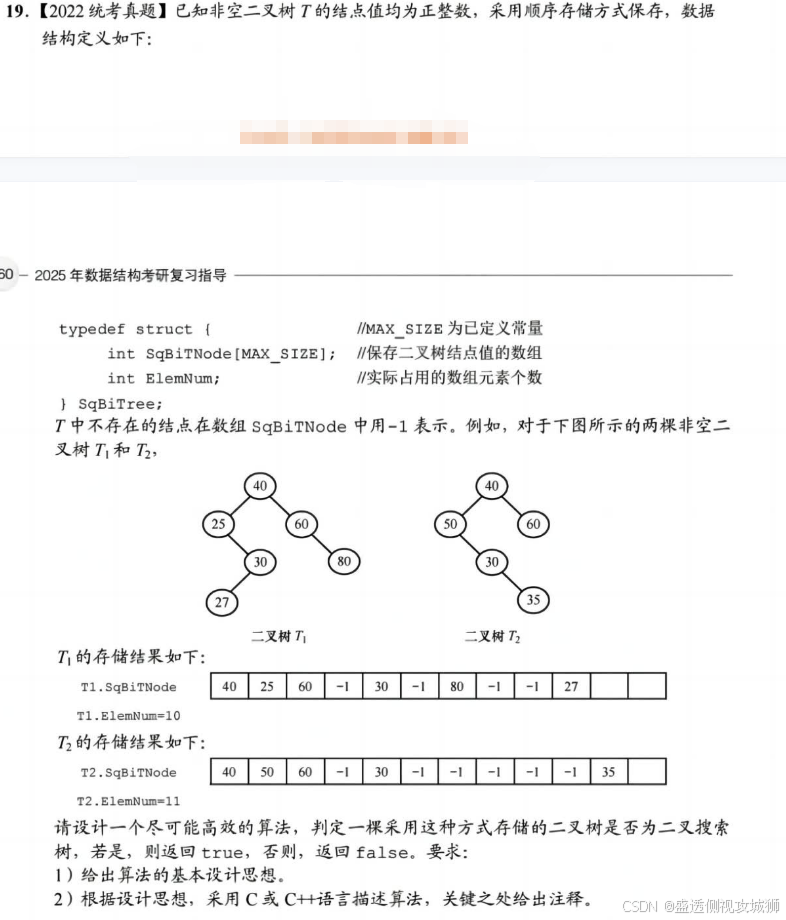
代码算法实现思路(1):
- 对于采用顺序存储方式保存的二叉树,根结点保存在 SqBiTNode[0]中;当某结点保存在SqBiTNode[i]中时,若有左孩子,则其值保存在 SqBiTNode[2i+1]中;若有右孩子,则其值保存在SqBiTNode[2i+2]中;若有双亲结点,则其值保存在SqBiTNode[(i-1)/2]中。
- 二叉搜索树需要满足的条件是:任意一个结点值大于其左子树中的全部结点值,小于其右子树中的全部结点值。中序遍历二叉搜索树得到一个升序序列。
- 综上:
- 使用整型变量val记录中序遍历过程中已遍历结点的最大值,初值为一个负整数。
- 若当前遍历的结点值小于或等于val,则算法返回false,否则,将 val的值更新为当前结点的值。
核心代码实现(1):
#define false 0
#define true 1
typedef int bool;
// 判断顺序存储的二叉树(SqBiTree)是否为二叉排序树
// bt: 顺序存储的二叉树;k: 当前节点下标;val: 用于记录上一个访问节点的值的指针
bool judgeInOrderBST(SqBiTree bt, int k, int *val) {
// 初始调用时k的值是0(从根节点开始判断)
if (k < bt.ElemNum && bt.SqBiTNode[k] != -1) { // 节点存在且在有效范围内
// 递归判断左子树是否满足二叉排序树性质
if (!judgeInOrderBST(bt, 2 * k + 1, val)) return false;
// 检查当前节点值是否大于上一个访问节点的值(中序遍历顺序)
if (bt.SqBiTNode[k] <= *val) return false;
*val = bt.SqBiTNode[k]; // 更新上一个访问节点的值为当前节点值
// 递归判断右子树是否满足二叉排序树性质
if (!judgeInOrderBST(bt, 2 * k + 2, val)) return false;
}
return true; // 所有检查通过,是二叉排序树
}代码算法实现思路(2):
- 由于二叉搜索树需要满足的条件是:任意一个结点值大于其左子树中的全部结点值,小于其右子树中的全部结点值。
- 所以我们设置两个数组 pmax和 pmin。
- 在数组 SqBiTNode 中从后向前扫描且描过程中逐一验证结点与子树之间是否满足下述的大小关系。
- 根据二叉搜索树的定义,SqBiTNode[i]中的值应该大于以SqBiTNode[2i+1]为根的子树中的最大值(保存在pmax[2i+1]中),小于以SqBiTNode[2i+2]为根的子树中的最小值(保存在 pmin[2i+1]中)。
- 初始时,用数组SqBiTNode 中前ElemNum个元素的值对数组 pmax和pmin初始化。
核心代码实现(2):
#include <stdlib.h>
#define false 0
#define true 1
typedef int bool;
// 函数功能:判断顺序存储的二叉树(SqBiTree)是否为二叉排序树(BST)
bool judgeBST(SqBiTree bt) {
int k, m, *pmin, *pmax;
// 分配内存,用于存储每个结点的最小可能值和最大可能值
pmin = (int *)malloc(sizeof(int) * (bt.ElemNum));
pmax = (int *)malloc(sizeof(int) * (bt.ElemNum));
// 辅助数组初始化:每个结点初始时的最小和最大可能值设为自身值
for (k = 0; k < bt.ElemNum; k++)
pmin[k] = pmax[k] = bt.SqBiNode[k];
// 从最后一个结点(叶结点方向)向根结点遍历
for (k = bt.ElemNum - 1; k > 0; k--) {
if (bt.SqBiNode[k] != -1) { // 若当前结点存在(假设-1表示空结点)
m = (k - 1) / 2; // 计算当前结点k的双亲结点索引m
// 若k是左孩子,检查双亲结点值是否大于k的最大值
if (k % 2 == 1 && bt.SqBiNode[m] > pmax[k]) {
pmin[m] = pmin[k]; // 更新双亲结点的最小值
}
// 若k是右孩子,检查双亲结点值是否小于k的最小值
else if (k % 2 == 0 && bt.SqBiNode[m] < pmin[k]) {
pmax[m] = pmax[k]; // 更新双亲结点的最大值
}
else {
return false; // 不满足BST条件,返回false
}
}
}
return true; // 遍历完成且所有条件满足,返回true
}
5.4树和森林算法题目
5.4.04题:
![]()
代码算法实现思路:
- 当森林(树)以孩子兄弟表示法存储时,若结点没有孩子(fch=NULL),则它必是叶子
- 总的叶结点个数是孩子子树(fch)上的叶子数和兄弟子树(nsib)上的叶结点个数之和。
核心代码实现:
// 定义树的节点结构体(孩子兄弟表示法)
typedef struct node {
ElemType data; // 数据域,存储节点的数据信息
struct node *fch, *nsib; // fch指向第一个孩子节点,nsib指向下一个兄弟节点
} *Tree; // Tree为指向node结构体的指针类型,用于表示树
// 计算以孩子兄弟表示法存储的森林的叶子结点数
int Leaves(Tree t) {
if (t == NULL) {
return 0; // 若树为空,叶子数为0
}
if (t->fch == NULL) {
// 若当前节点无孩子,说明该节点是叶子结点
return 1 + Leaves(t->nsib); // 返回当前叶子结点(1)与兄弟子树的叶子数之和
} else {
// 若当前节点有孩子,递归计算孩子子树和兄弟子树的叶子数之和
return Leaves(t->fch) + Leaves(t->nsib);
}
}
5.4.05题:
代码算法实现思路:
- 因为是孩子兄弟链表表示的树
- 所以我们可以采用递归算法,若树为空,高度为零;
- 否则,高度为第一子女树高度加1和兄弟子树高度的大者。
- 其非递归算法使用队列,逐层遍历树,取得树的高度。
核心代码实现:
int Height(CSTree bt) {
// 函数功能:递归计算以孩子兄弟链表(CSTree)表示的树的深度
// 参数bt:树的根节点指针,若为NULL表示空树
int hc, hs; // hc存储第一子女子树的高度,hs存储兄弟子树的高度
if (bt == NULL)
return 0; // 若树为空,深度为0
else {
// 递归计算第一子女子树的高度(第一子女子树的深度)
hc = Height(bt->firstchild);
// 递归计算兄弟子树的高度(兄弟子树的深度)
hs = Height(bt->nextsibling);
// 树的深度为“第一子女子树高度+1”(包含当前节点层)和“兄弟子树高度”中的较大值
if (hc + 1 > hs)
return hc + 1;
else
return hs;
}
}




















 7879
7879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











