




第一部分:定义
模型蒸馏(Model Distillation) 是一种机器学习中的知识提炼技术,用于将一个大模型(通常被称为“教师模型”)的知识迁移到一个小模型(通常称为“学生模型”)中,同时尽量保持性能不下降。其主要目标是通过这种方式减少模型的参数量和计算需求,从而更高效地应用在资源受限的环境中(如移动设备、嵌入式系统等)。
第二部分:核心思想
在模型蒸馏中:①教师模型(Teacher Model):一个性能强大的模型,通常是一个深度网络或训练精度很高的模型。用于生成预测结果和软标签(Soft Labels)。②学生模型(Student Model):一个较小的模型,目标是通过学习教师模型的知识来提升自己的表现。与直接用数据训练相比,通过学习教师模型的预测可以更高效地捕获数据的特征。③软标签(Soft Labels):教师模型不仅提供最终的分类结果,还输出类别分布的概率向量。这些概率包含了类别之间的相似性等更多信息,相比硬标签(如0和1),这种“软知识”可以指导学生模型学习到更丰富的特征。④蒸馏温度(Temperature, T):用于控制教师模型输出的类别分布“平滑度”。较高的温度可以使模型的概率分布更加平滑,有助于学生模型更好地捕捉类别之间的关系。
第三部分:模型蒸馏的过程
训练教师模型,使其在训练数据上达到较高的性能。利用教师模型对训练数据生成软标签(即概率分布)。通过联合损失函数训练学生模型:学生模型需要同时最小化两部分损失:与训练数据硬标签(如分类目标)之间的损失。与教师模型生成的软标签之间的损失(通常采用Kullback-Leibler散度或交叉熵)。联合损失公式:

其中:α是平衡系数。
第四部分:模型蒸馏的优势
模型蒸馏的优势效率提升:通过蒸馏,学生模型的计算开销和参数数量可以大幅减少。
鲁棒性提升:蒸馏过程中捕捉了教师模型的知识,可以增强模型对噪声的鲁棒性。
易于部署:小模型更易部署到计算能力有限的设备。
第五部分:模型蒸馏的应用
模型压缩: 在保持精度的前提下,将大模型压缩为小模型。
知识迁移: 在迁移学习中,用复杂的教师模型指导小模型在目标任务上的表现。
边缘设备应用: 在移动设备和物联网设备上运行高效的小模型。
第六部分:实际案例(理论分析部分)
BERT模型蒸馏: Google通过蒸馏技术将大规模预训练模型BERT压缩为TinyBERT或DistilBERT,这些小模型在自然语言处理任务上保持了较高精度,同时大幅降低了计算复杂度。
深度学习中的图像分类: ResNet等大型网络的知识可以通过蒸馏传递给轻量级模型,如MobileNet。模型蒸馏是机器学习模型压缩与优化的一个重要方向。
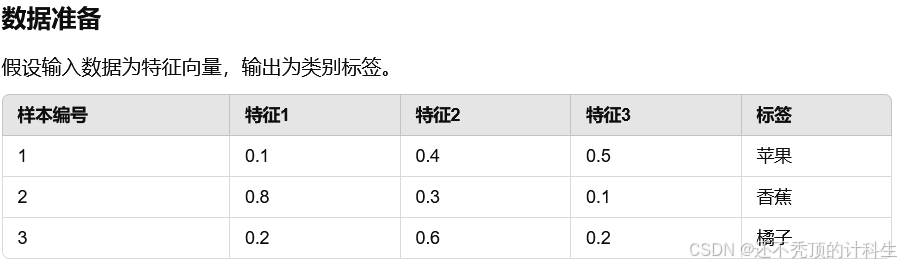
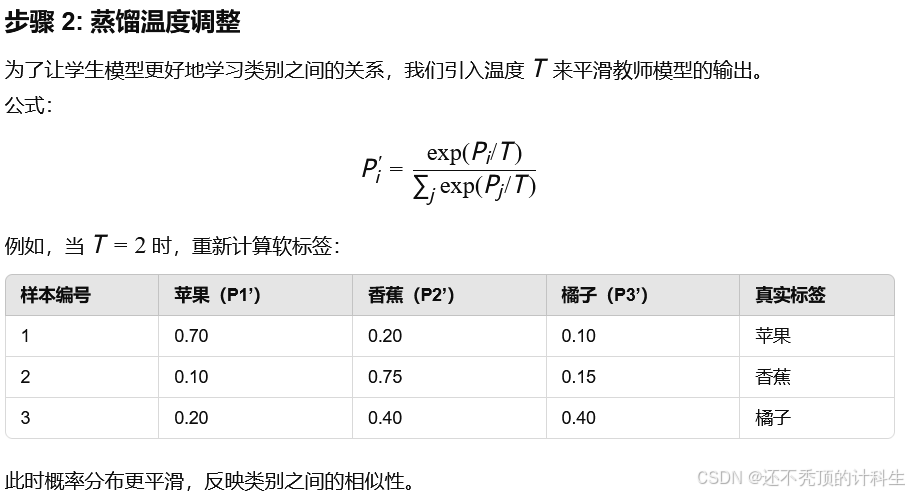
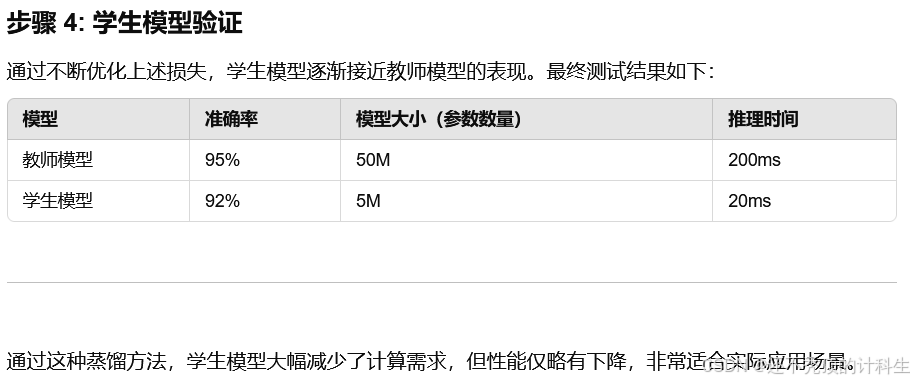
第七部分:生活具体例子























 345
345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











