



存储引擎在MySQL的逻辑架构中位于第三层,负责MySQL中的数据的存储和提取。MySQL存储引擎有很多,不同的存储引擎保存数据和索引的方式是不同的。每一种存储引擎都有它的优势和劣势。
可以使用 show engines; 命令来查看当前数据库所支持的所有的存储引擎。
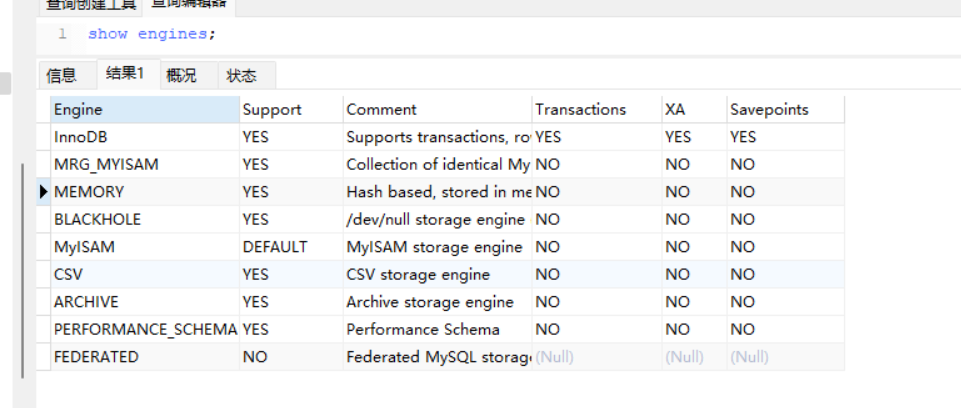
InnoDB
Innodb是mysql5.5及其以上版本默认的存储引擎。
InnoDB是默认的事务型存储引擎,也是最重要,使用最广泛的存储引擎。在没有特殊情况下,一般优先使用InnoDB存储引擎。
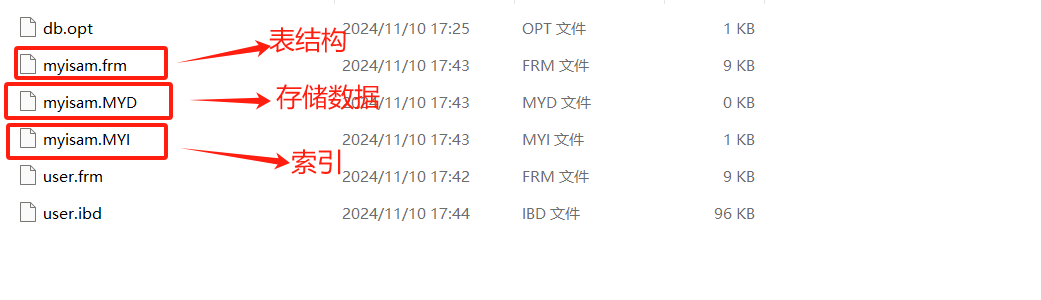
使用InnoDB时,会将数据表分为.frm(存储表结构)和 idb(存储表的数据和索引)两个文件进行存储。

InnoDB采用MVCC(多版本并发控制)来支持高并发,InnoDB实现了四个隔离级别,默认级别是REPETABLE READ,并通过间隙锁策略防止幻读的出现。
它的锁粒度是行锁。
InnoDB是典型的事务型存储引擎,并且通过一些机制和工具,支持真正的热备份。
InnoDB表是基于聚簇索引建立的,聚簇索引对主键的查询有很高的性能,不过他的二级索引(非主键索引)必须包含主键列,索引其他的索引会很大。
Mysql5.6版本之前默认是系统表空间,系统表空间不能收缩系统文件,浪费空间。5.6版本后使用独立表空间,可以收缩文件,节省空间。(下图展示的5.7的版本)
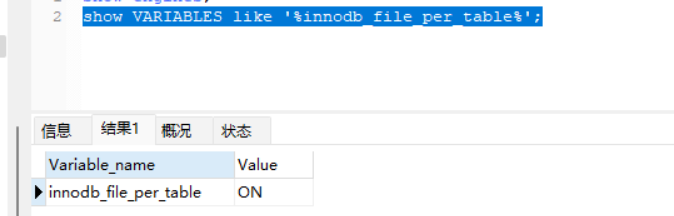
表空间有系统表空间和独立表空间 5.6之后就有了独立表空间了,可以收缩文件,空间更小
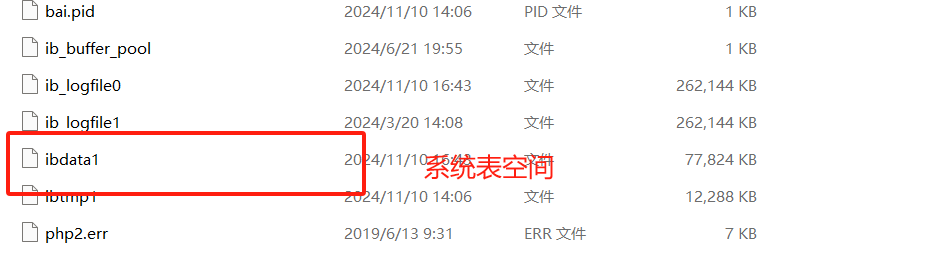
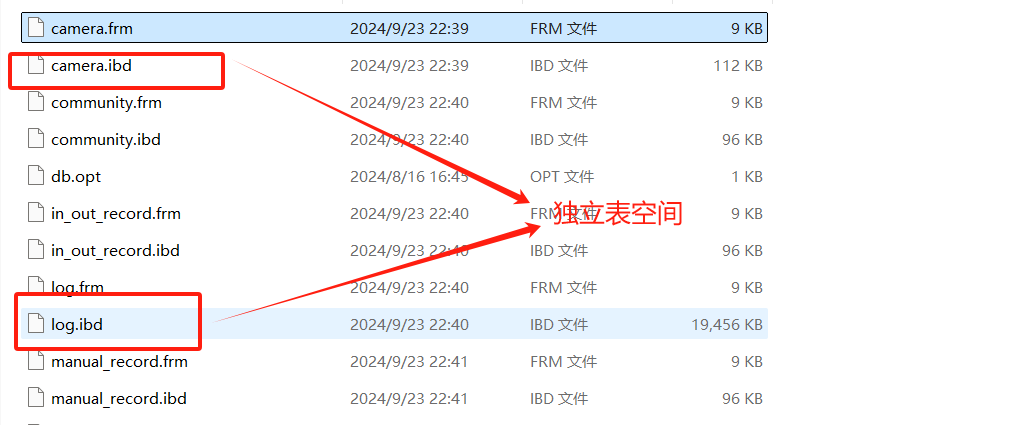
对表空间进行收缩
InnoDB支持事务、支持并发
InnoDB有.frm(表结构)和ibd(里面是索引和数据)文件
InnoDB采用MVCC(多版本并发控制)来支持高并发
幻读 虚读 不可重复读 四种隔离界别
MyISAM
MyISAM是5.5版本之前mysql数据库默认的存储引擎。
可以使用如下的sql语句创建数据库,采用MyISAM存储引擎。
|
CREATE TABLE `myisam_demo` ( `id` varchar(255) NOT NULL, `name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8; |
MyISAM采用的是索引与数据分离的形式,将数据保存在三个文件中
Frm 所有存储引擎都有的文件,存储表结构的文件
MYD 存储数据的文件
MYIs 存储索引的文件
MyISAM是基于非聚集索引进行存储的。
MyISAM不支持行锁,所以读取时对表加上共享锁,在写入是对表加上排他锁。由于是对整张表加锁,相比InnoDB,在并发写入时效率很低。
MyISAM不支持事务。
MyISAM提供了大量的特性,包括全文索引、压缩等。
进行压缩后的表是不能进行修改的,但是压缩表可以极大减少磁盘占用空间,因此也可以减少磁盘IO,从而提供查询性能。
全文索引,是一种基于分词创建的索引,可以支持复杂的查询。
myisam不支持并发所以不支持行锁 是基于非聚集索引进行存储的
增删改的效率低
分词器elsearch
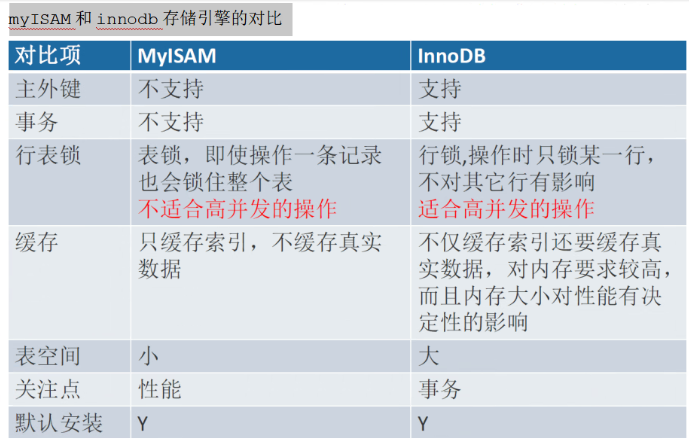
必须记住 myISAM和innodb存储引擎的对比
ARCHIVE
|
存储引擎 archive |
英[ˈɑːkaɪv] |
美[ˈɑːrkaɪv] |
翻译为: 档案; 档案馆; 档案室
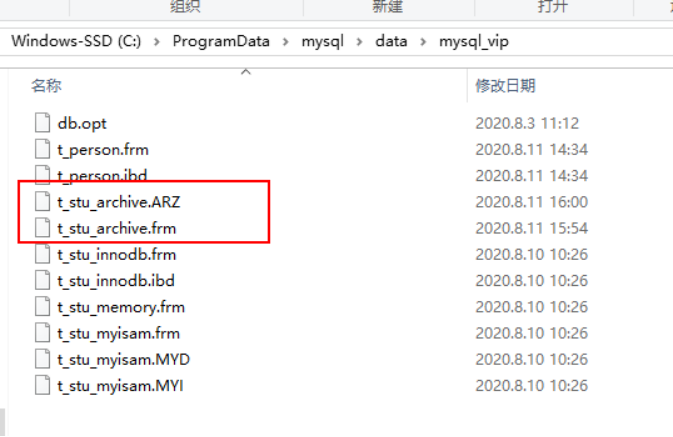
组成:以zlib对表数据进行压缩,磁盘I/O更少,数据存储在ARZ为后缀的文件中。
特点:
只支持insert和select操作,只允许在自增ID列上加索引。
Archive表比MyISAM表要小大约75%,比支持事务处理的InnoDB表小大约83%。当数据量非常大的时候Archive的插入性能表现会较MyISAM为佳。
较小的空间占用也能在你移植MySQL数据的时候发挥作用。当你需要把数据从一台MySQL服务器转移到另一台的时候,Archive表可以方便地移植到新的MySQL环境,你只需将保存Archive表的底层文件复制过去就可以了
应用场景:历史数据,数据采集应用。
存储的文件
档案
历史数据,数据采集应用
这个存储引擎主要用于放一些不经常用的数据
MEMORY
文件系统存储特点,也称HEAP存储引擎,所有的数据保存在内存中。
特点:
支持HASH索引和BTree索引
所有字段都是固定长度varchar(10) = char(10)
不支持Blog和Text等大字段
Memory存储引擎使用表级锁
最大大小由max_ heap_ _table_ size 参数决定
建表的语句
|
CREATE TABLE `t_stu_memory` ( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=MEMORY DEFAULT CHARSET=utf8; |
使用场景:
hash索引用于查找或者是映射表(邮编和地区的对应表)
用于保存数据分析中产生的中间表
用于缓存周期性聚合数据的结果表
memory数据易丢失,所以要求数据可再生
所有的数据保存在内存当中
支持hash索引和btree索引
所有的字段都是固定长度
不支持blog和text等大字段
使用场景:hash索引用于查找或者映射表 此存储引擎易丢失


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









