 一站式大数据组件部署指南
一站式大数据组件部署指南





前言
此文涵盖了实时和离线仓库的主流组件,以 CentOS-7 作为虚拟机系统进行大数据组件部署,每个环节的部署都非常详细。并且经过反复的测试和验证来达到各个组件之间的协调性和集成性。
CentOS 安装步骤不再过多赘述,网上有很多教程,可以通过其他博客进行安装。
所需资料
CentOS-7 镜像文件:CentOS-7-x86_64-Minimal-2009 (自行选择)
组件安装包和配置文件:softwares(必选)
下载地址:https://www.123865.com/s/esiPvd-UY503?pwd=lulu#
提取码:lulu
前提条件
- 需要会一些常规的 Linux 命令
- 三台互通的虚拟机
- softwares 位于虚拟机目录 /opt/ 下,即 :/opt/softwares
集群设计:
| 主机 | IP地址 | 内存 | 用户名 | 密码 | 磁盘 |
|---|---|---|---|---|---|
| 主机1 | 192.168.122.100 | 6g | root | 123456 | 60g |
| 主机2 | 192.168.122.101 | 2g | root | 123456 | 30g |
| 主机3 | 192.168.122.102 | 2g | root | 123456 | 30g |
注意:以下环境部署替换为自己的 IP 地址,或者修改 IP 地址与本文保持一致
文章目录
- 前言
- 所需资料
- 前提条件
- 一、基础环境配置
- 二、Hadoop 集群部署
- 三、Zookeeper 集群部署
- 四、Mysql & Hive 组件部署
- 五、Hbase 集群部署
- 六、Scala & Spark 集群部署
- 七、Spark On Yarn 集群部署
- 八、Clickhouse 数据库部署
- 九、Hudi 组件部署
- 十、Azkaban 集群部署
- 十一、DolphinScheduler 集群部署
- 十二、Flume 组件部署
- 十三、Kafka 集群部署
- 十四、Flink & Yarn 集群部署
- 十五、Maxwell 组件部署
- 十六、Redis 数据库部署
- 致谢
一、基础环境配置
1.修改主机名
以下内容分别在所有节点上操作
修改主机名主要是为了在集群中分辨主次。
在第一台服务器上操作:
# 宿主:192.168.122.100
hostnamectl set-hostname master
#生效操作
bash
在第二台服务器上操作:
# 从节点:192.168.122.101
hostnamectl set-hostname slave1
#生效操作
bash
在第三台服务器上操作:
# 从节点:192.168.122.102
hostnamectl set-hostname slave2
# 生效操作
bash
执行以上操作,依次为每一台主机设置一个主机名。
2.修改 hosts 规则
三台机器下分别安装vim,用vim替代原生的vi:
yum -y install vim
以下内容在 master 节点上操作
修改 /etc/hosts 文件:
vim /etc/hosts
添加以下内容:
192.168.122.100 master
192.168.122.101 slave1
192.168.122.102 slave2
在尾部追加几条规则(IP地址和主机名),修改后的内容如图所示:

3.同步 hosts 规则
以下内容在 master 节点上操作
通过 scp 命令将 master 节点上已经修改过的 hosts 文件发送到 slave1 和 slave2,根据提示输入yes和密码:
# scp 源 目标 (如果目标已存在则覆盖)
scp /etc/hosts slave1:/etc/hosts
scp /etc/hosts slave2:/etc/hosts
如图所示:
4.关闭防火墙
以下内容分别在所有节点上操作
systemctl 用于控制服务,使用 systemctl 关闭防火墙:
# 命令格式:systemctl [要执行的操作] [服务名.service]
# 关闭防火墙
systemctl stop firewalld.service
# 禁止开机自启
systemctl disable firewalld.service
查看防火墙状态,确认上面执行的是否已经生效:
systemctl status firewalld.service
如图所示:
5.配置 SSH 免密登录
以下内容在master节点上操作
什么是 RSA 密钥?
生成一个 RSA 密钥,一直回车即可:
# ssh-keygen -t 密钥类型
ssh-keygen -t rsa
如图所示:
创建可信配置(SSH免密登录):
# 给自己添加可信配置呢,此举方便后面启动集群。
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
测试是否配置成功免密登录:
#测试连接slave1
ssh slave1
Ctrl + d 退出当前用户,或者 exit 退出
#测试连接slave2
ssh slave2
如图所示:
6.集群同步时间
这里直接配置三台机器定时同步阿里云服务器,以下内容在所有节点上操作
在所有主机上安装 ntp:
yum -y install ntp
因为默认下载后ntpd服务是关闭且关闭开机自启,所以我们直接编辑定时任务:
crontab -e
设置每分钟同步阿里云时间,因为系统同步时间后会自动发送文件,所以我们删除邮件:
#每分钟同步阿里云并删除邮件
*/1 * * * * /usr/sbin/ntpdate ntp.aliyun.com && cat /dev/null > /var/spool/mail/root
一分钟后查看任意节点是否是当前时间:
date
如图所示:

上图可见会向系统发送一个邮件,因此我们在三个节点上都禁止系统启动邮件检查:
# 在三个节点上分别运行
#禁止系统启动邮件检查
echo "unset MAILCHECK" >> /etc/profile
#生效一下
source /etc/profile
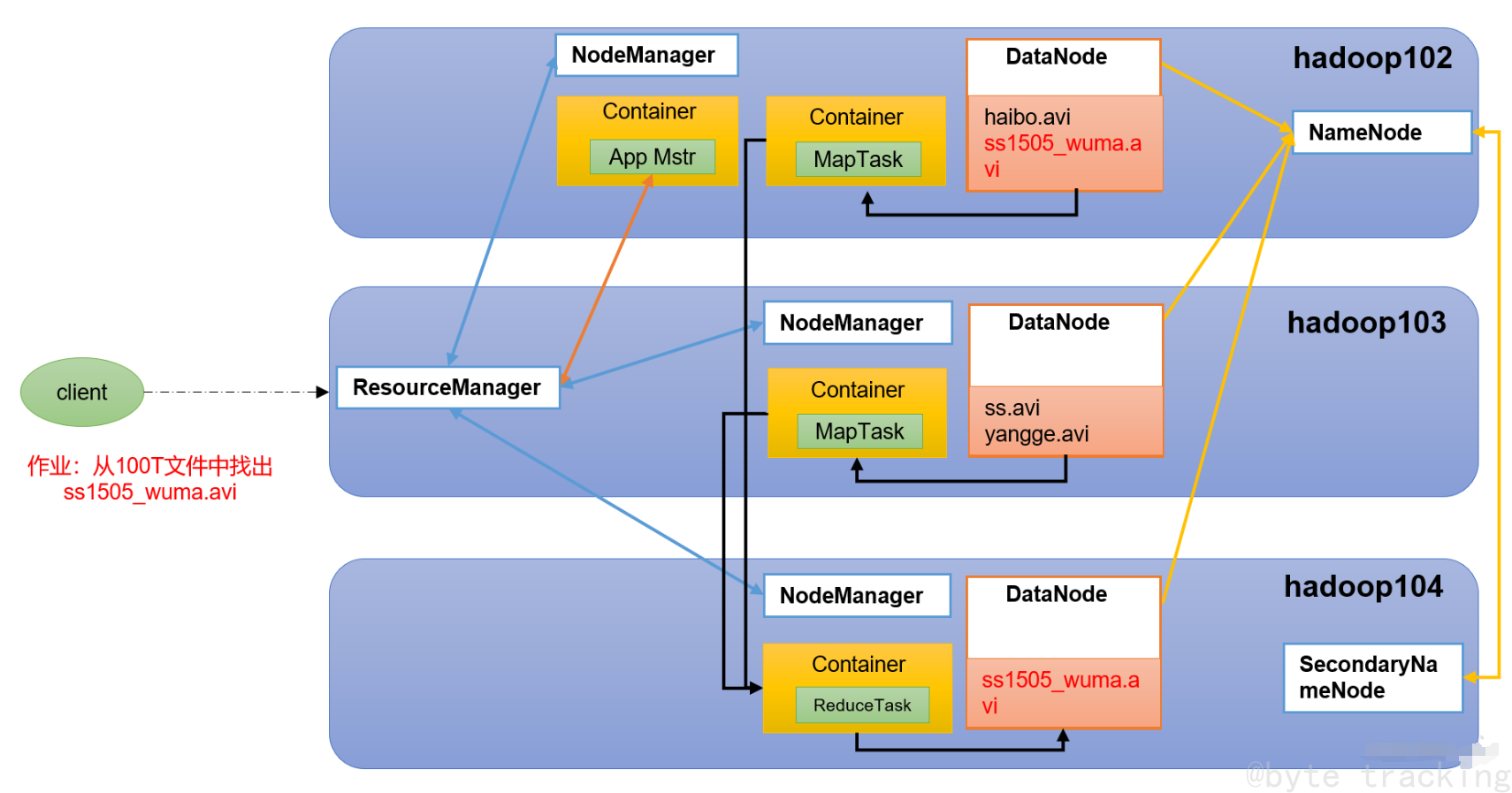
二、Hadoop 集群部署
介绍
- Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构。广义上来说,Hadoop 通常是指一个更广泛的概念——Hadoop 生态圈。
HDFS
- HDFS 是一个分布式文件系统。
NameNode
- 存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的 DataNode 等。
SecondaryNameNode
-
SecondaryNameNode 的作用是合并 fsimage 和 edits文件。
-
NameNode 的存储目录树的信息,而目录树的信息则存放在 fsimage 文件中,当 NameNode 启动的时候会首先读取整个 fsimage 文件,将信息装载到内存中。
-
edits 文件存储日志信息,在 NameNode 上所有对目录的操作,增加,删除,修改等都会保存到 edits 文件中,并不会同步到 fsimage 中,当 NameNode 关闭的时候,也不会将 fsimage 和 edits 进行合并。
-
所以当 NameNode 启动的时候,首先装载 fsimage 文件,然后按照 edits 中的记录执行一遍所有记录的操作,最后把信息的目录树写入 fsimage 中,并删掉 edits 文件,重新启用新的 edits 文件。
-
但是如果 NameNode 执行了很多操作的话,就会导致 edits 文件很大,那么在下一次启动的过程中,就会导致 NameNode 的启动速度很慢,慢到几个小时也不是不可能,所以出现了 SecondNameNode。
-
SecondaryNameNode 会按照一定的规则被唤醒,进行 fsimage 和 edits 的合并,防止文件过大。合并的过程是,将 NameNode 的 fsimage 和 edits 下载到 SecondryNameNode 所在的节点的数据目录,然后合并到 fsimage 文件,最后上传到 NameNode 节点。合并的过程中不影响 NameNode 节点的使用。
DataNode
- 在本地文件系统存储文件块数据,以及块数据的校验和。
Secondary NameNode
- 每隔一段时间对 NameNode 元数据备份。并非 NameNode 的热备。当 NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
YARN
- YARN 是一种资源协调者,是 Hadoop 的资源管理器。
ResourceManager
- 整个集群资源(内存、CPU等)的老大。
ApplicationMaster
- 单个任务运行的老大。
NodeManager
- 单个节点服务器资源老大。
Container
- 容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。
HDFS、Yarn、MapReduce 三者的关系图
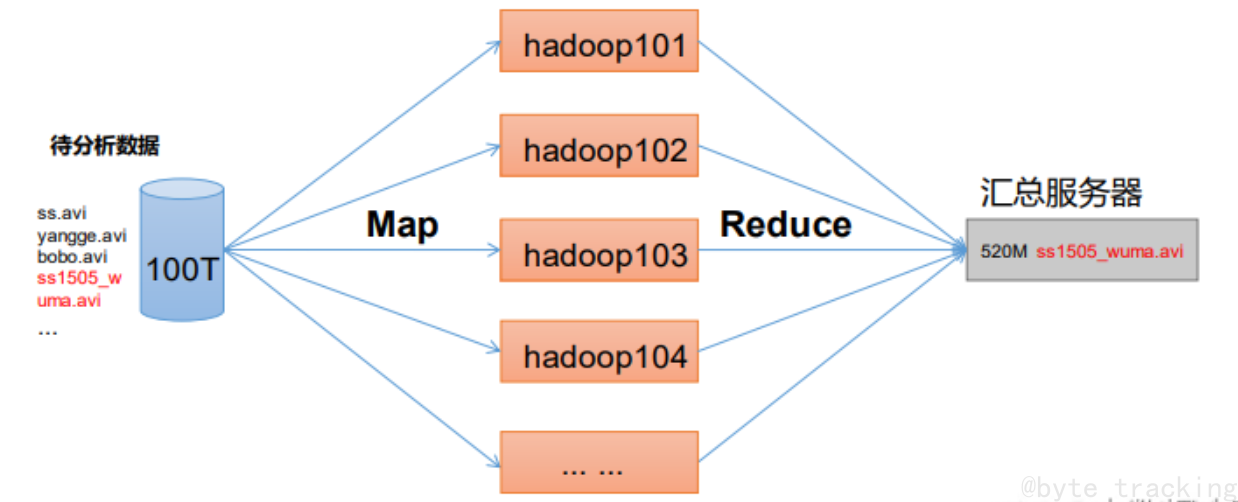
MapReduce
前提条件
- jdk-8u212-linux-x64.tar.gz(位于 /opt/softwares/ 下)
- hadoop-3.1.3.tar.gz(位于 /opt/softwares/ 下)
- 分布式部署
1.解压文件
以下内容在 master 节点上操作
进入目录:
cd /opt
新建 module 目录并进入:
mkdir module && cd module
解压文件:
# 解压 hadoop 和 jdk
tar -zxvf /opt/softwares/hadoop-3.1.3.tar.gz
tar -zxvf /opt/softwares/jdk-8u212-linux-x64.tar.gz
重命名文件:
# 重命名 jdk
mv jdk1.8.0_212/ jdk
# 重命名 hadoop
mv hadoop-3.1.3/ hadoop
2.配置环境变量
以下内容在 master 节点上操作
-
什么是环境变量? ,当一个用户登录 Linux 系统或使用 su 命令切换到另一个用户时,首先要确保执行的启动脚本就是
/etc/profile,此文件内部内部有一段代码会遍历执行/etc/profile.d/目录内部的所有脚本。 -
每次修改环境变量都很麻烦,但可以通过 alias 简化环境变量的修改和刷新:
编辑 /etc/profile.d/myenv.sh 文件:
# 此文件虽然不存在,但直接编辑就相当于新建文件
vim /etc/profile.d/myenv.sh
在末尾写入以下内容:
alias env-edit='vim /etc/profile.d/myenv.sh'
alias env-update='source /etc/profile.d/myenv.sh'
使其立即生效:
source /etc/profile.d/myenv.sh
这样一来我们就“创造”了两个新的命令,其中:
- env-edit 命令用来编辑环境变量
- env-update 命令用来生效您对环境变量的修改
然后我们就可以开始配置 hadoop 的环境变量了。编辑环境变量:
env-edit
写入以下内容:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
刷新环境变量:
env-update
测试 jdk 环境变量:
java -version
如图所示:

测试 hadoop 环境变量:
hadoop version
如图所示:

3.配置 hadoop-env.sh
以下内容在 master 节点上操作
进入到 hadoop 配置文件的目录下:
cd $HADOOP_HOME/etc/hadoop/
由于 hadoop 运行时依赖 Java,所以我们需要在此文件里为 hadoop 配置环境变量;我们还需要在此文件里指定启动 namenode、datanode、secondary namenode、resource manager、node manager 时所使用的用户。
编辑 hadoop-env.sh:
vim hadoop-env.sh
在文件末尾追加以下内容:
# Java 环境变量
export JAVA_HOME=/opt/module/jdk
# Hadoop 执行命令时使用的用户名
export HADOOP_SHELL_EXECNAME=root
# NameNode 用户名
export HDFS_NAMENODE_USER=root
# DataNode 用户名
export HDFS_DATANODE_USER=root
# Secondary NameNode 用户名
export HDFS_SECONDARYNAMENODE_USER=root
# Yarn Resource Manager 用户名
export YARN_RESOURCEMANAGER_USER=root
# Yarn NodeManager 用户名
export YARN_NODEMANAGER_USER=root
4.配置 core-site.xml
以下内容在 master 节点上操作
我们需要在此文件里设置 hadoop 用于接收各种请求的端口和 hadoop 的缓存目录。
编辑 core-site.xml:
vim core-site.xml
修改后:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 HDFS 运行时 namenode 的工作地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9820</value>
</property>
<!-- 指定 hadoop 数据的临时存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/tmp</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 root-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
<!---------- hiveserver2的代理用户认证 ----------->
<!--配置所有节点的 root 用户都可作为代理用户-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!--配置 root 用户能够代理的用户组为任意组-->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!--配置 root 用户能够代理的用户为任意用户-->
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
<!--------------------------------------------------------------------->
| 参数名 | 默认值 | 参数解释 |
|---|---|---|
| fs.defaultFS | file:// | 文件系统主机和端口 |
| io.file.bufffer.size | 4096 | 流文件的缓冲区大小 |
| hadoop.tmp.dir | /tmp/hadoop-${user_name} | 临时目录 |
5.配置 hdfs-site.xml
以下内容在 master 节点上操作
我们需要在此文件内设置 hadoop 集群容灾备份数量、名称节点(namenode)数据存储目录、数据节点(datanode)数据存储目录、辅助名称节点(secondary namenode)节点地址和端口。
编辑 hdfs-site.xml:
vim hdfs-site.xml
修改后:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 容灾备份数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--namenode web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!-- SecondaryNameNode 工作在 master 上 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9868</value>
</property>
</configuration>
| 参数名 | 默认值 | 参数解释 |
|---|---|---|
| dfs.replication | 3 | 缺省的块复制数量 |
| dfs.webhdfs.enabled | true | 是否通过http协议读取hdfs文件(不安全) |
| dfs.namenode.name.dir | file://${hadoop.tmp.dir}/dfs/name | dfs名称节点存储位置 |
| dfs.namenode.secondary.http-address | master:9868 | NN的HTTP地址 |
| dfs.datanode.data.dir | file://${hadoop.tmp.dir}/dfs/data | dfs数据节点存储数据块的位置 |
6.配置 mapred-site.xml
以下内容在 master 节点上操作
我们需要在此文件内配置 hadoop 集群使用 yarn 进行 mapreduce 计算。
编辑 mapred-site.xml:
vim mapred-site.xml
修改后:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 使用 yarn 集群框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
| 参数名 | 默认值 | 参数解释 |
|---|---|---|
| mapreduce.framework.name | local | 取 local | classic | yarn 其中之一,若非 yarn 则不会使用 yarn 集群来实现资源的分配。 |
| mapreduce.jobhistory.address | 0.0.0.0:10020 | 定义历史服务器的地址和端口,通过历史服务器查看已经运行完的 Mapreduce 作业记录。 |
| mapreduce.jobhistory.webapp.address | 0.0.0.0:19888 | 定义历史服务器 web 应用访问地址和端口。 |
7.配置 yarn-site.xml
以下内容在 master 节点上操作
我们需要在此文件内配置集群的资源管理节点(resourcemanager)、为 node manager 添加一些自定义服务、配置 yarn 的 classpath。
编辑 yarn-site.xml:
vim yarn-site.xml
修改后:
<?xml version="1.0"?>
<configuration>
<!-- 把 yarn 集群的资源管理者设置为 master -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- 自定义服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
获取 hadoop 的 classpath:
hadoop classpath
将输出内容复制下来,马上要用。
编辑 yarn-site.xml:
vim yarn-site.xml
修改后:
<?xml version="1.0"?>
<configuration>
<!-- 把 yarn 集群的资源管理者设置为 master -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- 自定义服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>此处填入刚才复制的内容</value>
</property>
</configuration>
| 参数名 | 默认值 | 参数解释 |
|---|---|---|
| yarn.resourcemanager.address | 0.0.0.0:8032 | ResourceManager提供给客户端访问的地址. 客户端通过该地址向RM提交应用程序,杀死应用程序等 |
| yarn.resourcemanager.scheduler.address | 0.0.0.0:8030 | 定义历史服务器的地址和端口,通过历史服务器查看已经运行完的 Mapreduce 作业记录 |
| yarn.resourcemanager.resource-tracker.address | 0.0.0.0:8031 | ResourceManager 提供给 NodeManager 的地址. NodeManager 通过该地址向 RM 汇报心跳,领取任务等 |
| yarn.resourcemanager.admin.address | 0.0.0.0:8033 | ResourceManager提供给管理员的访问地址. 管理员通过该地址向 RM 发送管理命令等 |
| yarn.resourcemanager.webapp.address | 0.0.0.0:8088 | ResourceManager对 web 服务提供地址. 用户可通过该地址在浏览器中查看集群各类信息 |
| yarn.nodemanager.aux-services | org.apache.hadoop.mapred.ShuffleHandler | 通过该配置项,用户可以自定义一些服务,例如 Map-Reduce 的 shuffle 功能就是采用这种方式实现的,这样就可以在 NodeManager 上扩展自己的服务 |
8.配置 workers
以下内容在 master 节点上操作
包含在此文件内的主机名,都将被 master 认为是集群里的一个节点。所以我们需要在此文件内写入所有节点的主机名,这样 master 才知道集群里都有哪些主机。
编辑 workers:
vim workers
更改为所有节点:
master
slave1
slave2
9.分发文件
以下内容在 master 节点上操作
下发 module 目录到 slave1 和 slave2 节点:
# 在后台给 slave1 发送文件
# 命令后方加一个 '&' 可以理解为后台运行
scp -r /opt/module/ slave1:/opt/ &
# 在前台给 slave2 发送文件
scp -r /opt/module/ slave2:/opt/
下发环境变量文件:
# pwd 命令返回当前所在目录
# 可以理解为 $() 把 pwd 命令的输出转为了字符串
cd /etc/profile.d/
scp ./myenv.sh slave1:$(pwd)/
scp ./myenv.sh slave2:$(pwd)/
# 以上三条命令等价于这两条命令
scp /etc/profile.d/myenv.sh slave1:/etc/profile.d/
scp /etc/profile.d/myenv.sh slave2:/etc/profile.d/
10.生效环境变量
以下内容在所有节点上操作
source /etc/profile.d/myenv.sh
11.启动 Hadoop 集群
以下内容在 master 节点上操作
格式化元数据:(仅在 master 节点上执行一次此命令)
hdfs namenode -format
如果不小心多次执行了此命令,或在发送文件到 hdfs 时遇到问题,请执行以下命令,尝试在所有节点上清空您在 core-site.xml 里配置的数据缓存目录并重新格式化 namenode 解决:
# 在所有节点上执行
rm -rf $HADOOP_HOME/tmp
#再次执行格式化,在master节点上执行
hdfs namenode -format
正常输出:
启动所有进程:
start-all.sh
12.检查启动情况
以下内容在所有节点上运行
检查 hadoop :
jps
master:

slave1:

slave2:

我们已经在前面建立了 master 的 hosts 规则,但是我们的实体机没有建立 hosts 规则,所以并不认识 master,只需要把 master 替换成对应的 IP 地址即可
检查端口启动状态的方法有很多种,这里我们使用最简单的浏览器测试法:
访问 http://192.168.122.100:9870/ ,可见此处有三个工作节点:
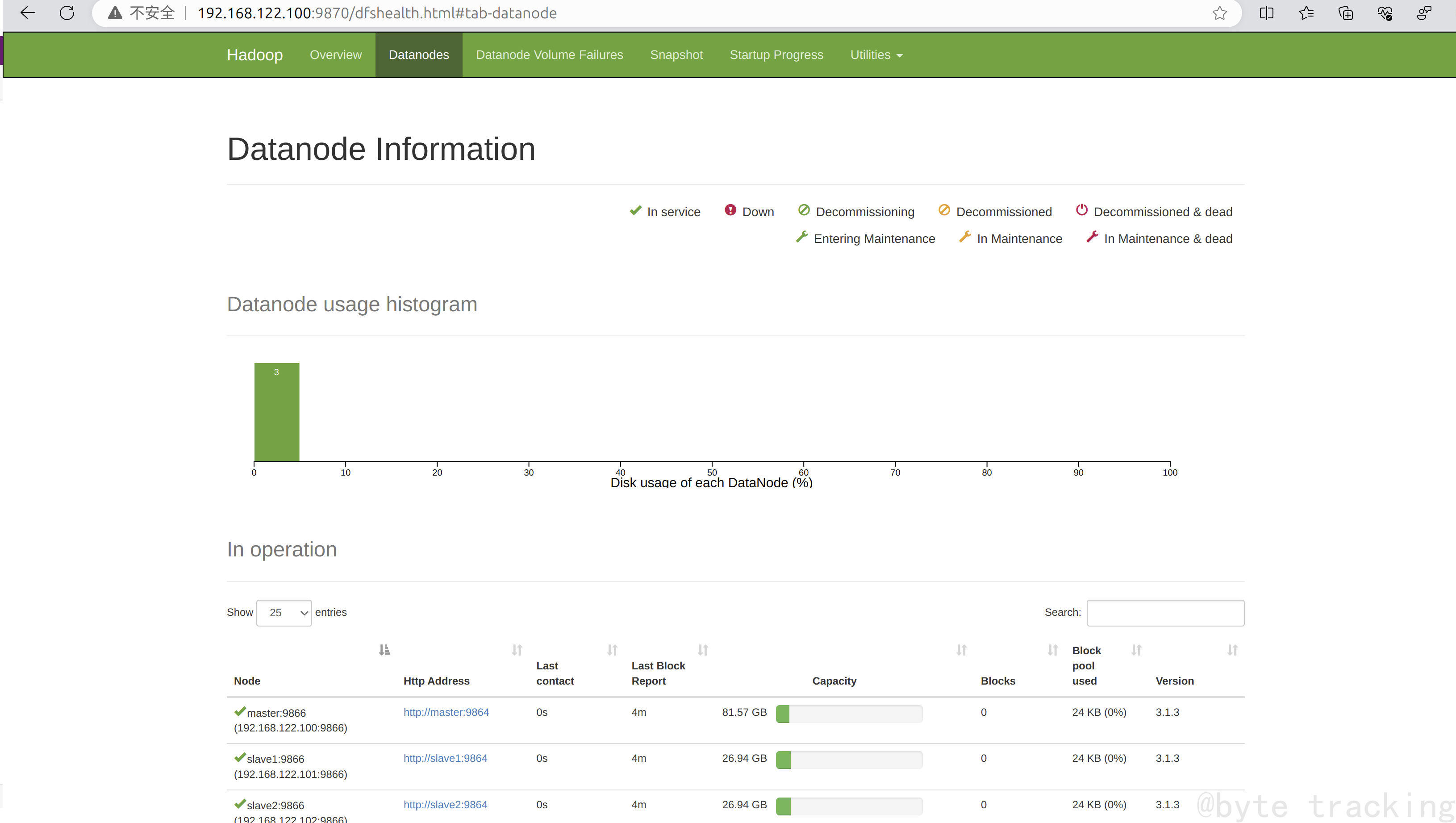
访问 http://192.168.122.100:8088/ :
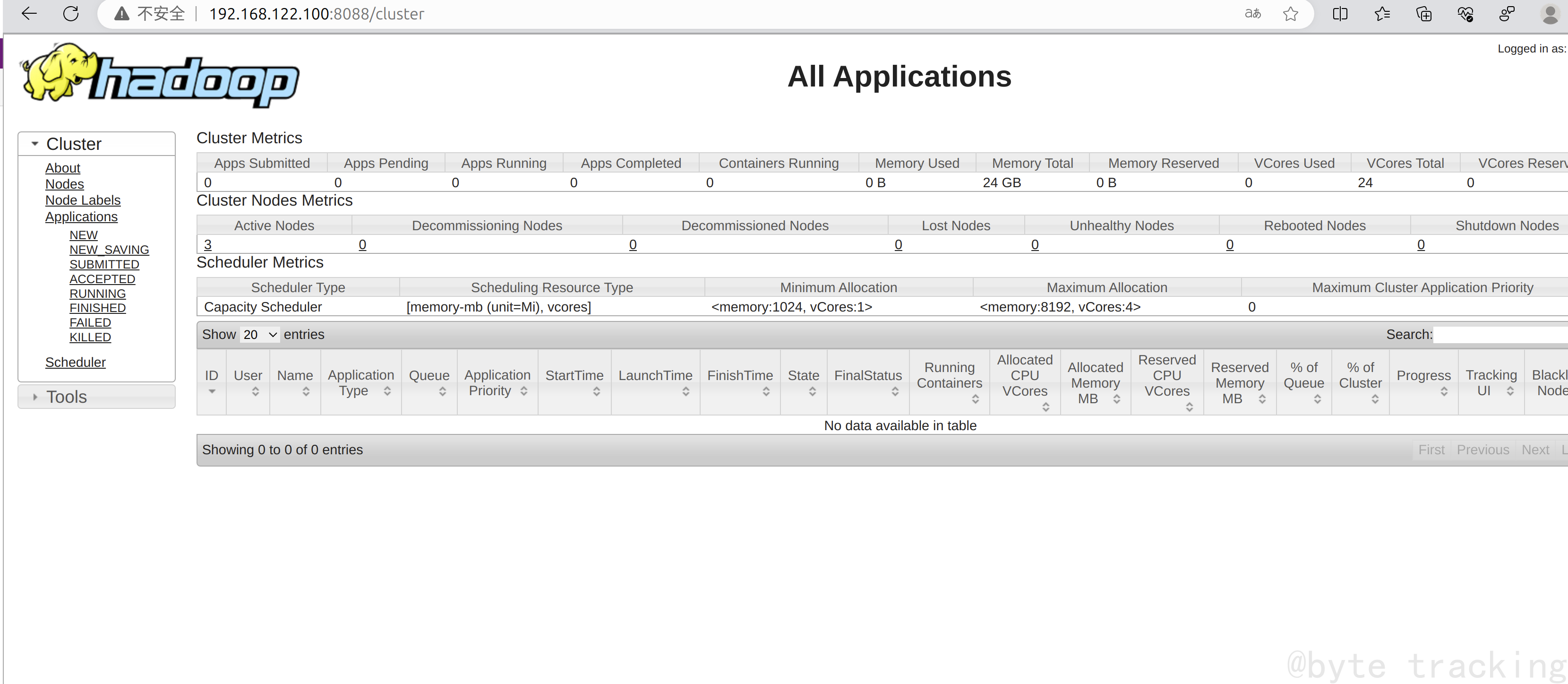
访问 http://192.168.122.100:9820/ :
以上代表正常工作。
然后在所有节点上关闭安全模式:
# 在所有节点执行一次
hdfs dfsadmin -safemode leave
13.测试 Hadoop
以下内容在 master 节点上操作
计算测试:
# 切换目录
cd $HADOOP_HOME/share/hadoop/mapreduce/
# 来一波 mapreduce 计算测试
hadoop jar hadoop-mapreduce-examples-3.1.3.jar pi 5 5
最终计算结果是 Estimated value of Pi is 3.68000000000000000000:

如果进程启动都没有问题,但是在计算测试时报错,可能是由于yarn的内存检测问题
- 编辑文件:
vim /opt/module/hadoop/etc/hadoop/yarn-site.xml
- 添加以下配置:
<!-- 关闭 yran 内存检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
- 分发文件
# 发送给slave1
scp /opt/module/hadoop/etc/hadoop/yarn-site.xml slave1:/opt/module/hadoop/etc/hadoop/
# 发送给slave2
scp /opt/module/hadoop/etc/hadoop/yarn-site.xml slave2:/opt/module/hadoop/etc/hadoop/
- 重启Hadoop集群
#关闭集群
stop-all.sh
#开启集群
start-all.sh
- 重新执行以上测试的命令
查看 hdfs 报告:
hdfs dfsadmin -report
三、Zookeeper 集群部署
介绍
- ZooKeeper 是一个开源的分布式协调服务,由雅虎创建,是 Google Chubby 的开源实现。分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、配置维护,名字服务、分布式同步、分布式锁和分布式队列等功能。
前提条件
- apache-zookeeper-3.5.7-bin.tar.gz(位于 /opt/softwares/ 下)
- 分布式部署
1.解压 zookeeper
以下内容在 master 节点上操作
进入目录:
cd /opt/module/
解压文件:
# 解压 apache-zookeeper-3.5.7-bin.tar.gz 到当前目录
tar -zxvf /opt/softwares/apache-zookeeper-3.5.7-bin.tar.gz
重命名:
mv apache-zookeeper-3.5.7-bin/ zookeeper
2.配置 zookeeper
以下内容在 master 节点上操作
创建 data 目录用于存储数据:
mkdir /opt/module/zookeeper/data
创建 logs 目录用于存储日志:
mkdir /opt/module/zookeeper/logs
进入配置文件夹:l
cd /opt/module/zookeeper/conf
以 zoo_sample.cfg 为模板创建配置:
cp zoo_sample.cfg zoo.cfg
打开配置文件:
vim zoo.cfg
修改后:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/module/zookeeper/data
dataLogsDir=/opt/module/zookeeper/logs
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
#安装zookeeper后, 发现端口8080被占用, 分享如何解决. zookeeper部署后, 3.5以后的版本, 会自动占用8080端口
admin.serverPort=8888
3.配置环境变量
以下内容在 master 节点上操作
注意:jdk 环境变量必须在 zookeeper 环境变量之后配置 ,否则在启动zookeeper后会提示端口占用
- 方案1:将 jdk 环境变量放到文件末尾
- 方案2:在 zookeeper 环境变量后面加上 $JAVA_HOME/bin
- 这里采用方案2
编辑环境变量:
# 这个命令是我们在 hadoop 篇通过 alias 创建的,除此之外还有一个 env-update 用于更新环境变量
env-edit
在末尾追加以下内容:
#ZOOKEEPER_HOME
export ZK_HOME=/opt/module/zookeeper
export PATH=$PATH:$ZK_HOME/bin:$JAVA_HOME/bin
刷新环境变量:
env-update
测试环境变量:
zkServer.sh
如图所示:

4.分发文件
以下内容在 master 节点上操作
下发 zookeeper:
scp -r $ZK_HOME slave1:/opt/module/
scp -r $ZK_HOME slave2:/opt/module/
下发环境变量:
scp /etc/profile.d/myenv.sh slave1:/etc/profile.d/myenv.sh
scp /etc/profile.d/myenv.sh slave2:/etc/profile.d/myenv.sh
当然,如果你足够了解 shell 的话,可以使用这种方法简化路径:
cd /etc/profile.d/
scp ./myenv.sh slave1:$(pwd)/
scp ./myenv.sh slave2:$(pwd)/
5.生效环境变量
以下内容在 slave1 和 slave2 上操作
env-update
6.配置 myid
以下内容在 master 节点上操作
每台服务器的 myid 必须是唯一的。其实我们上一步已经为每一节点分配好了 myid!它在[zoo.cfg]配置 zookeepe 最下方:
# server.myid=主机名:2888:3888
# master 节点的 myid 是 1
server.1=master:2888:3888
# slave1 节点的 myid 是 2
server.2=slave1:2888:3888
# slave2 节点的 myid 是 3
server.3=slave2:2888:3888
所以我们直接设置即可
设置 master 节点的 myid:
echo 1 > /opt/module/zookeeper/data/myid
设置 slave1 节点的 myid:
# 远程执行命令:ssh [主机名@]地址 "要远程执行的命令"
ssh slave1 "echo 2 > /opt/module/zookeeper/data/myid"
设置 slave2 节点的 myid:
ssh slave2 "echo 3 > /opt/module/zookeeper/data/myid"
7.启动与测试
以下内容大部分在 master 节点上操作,小部分需要在所有节点上操作
在所有节点上执行此命令来启动 zookeeper:
# zkServer.sh 支持下列参数:
# start | start-foreground | stop | restart | status | upgrade | print-cmd
zkServer.sh start
在 master 节点打开 zookeeper cli:
zkCli.sh
在 master 节点的 zookeeper cli 里执行此命令:
create /test "hello"
如图所示:
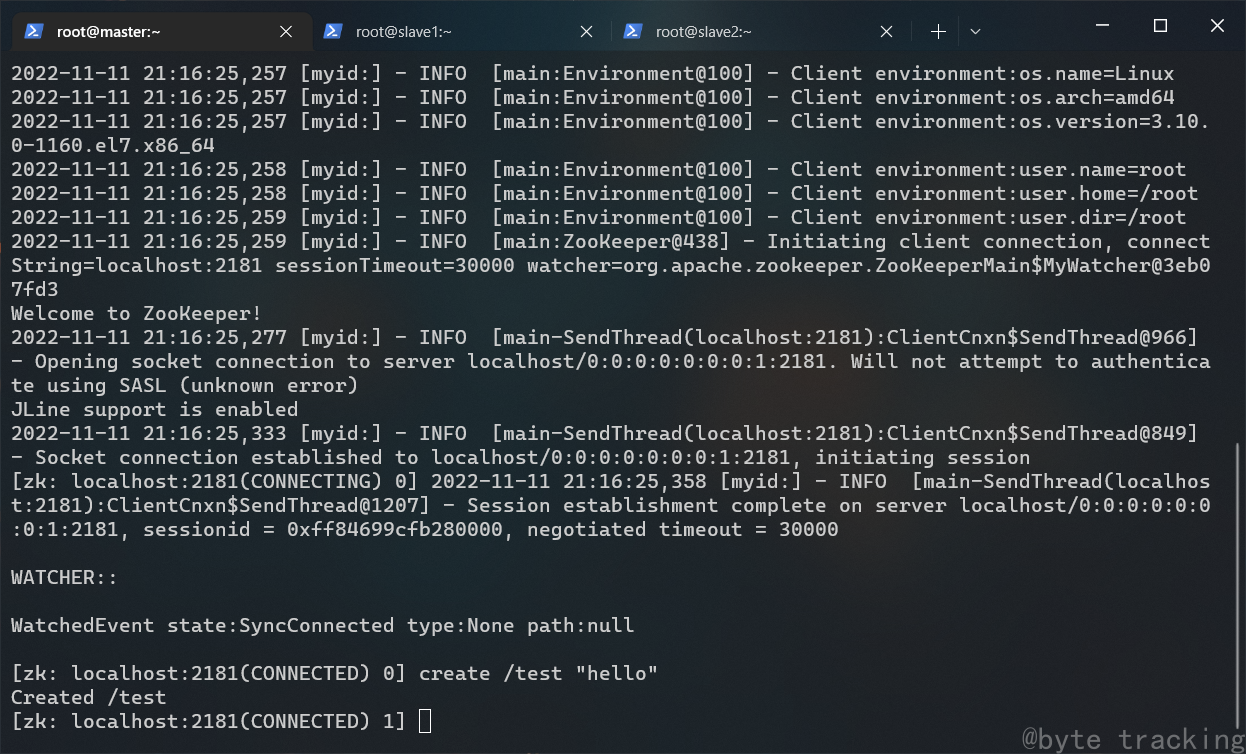
在 slave1 节点打开 zookeeper cli:
zkCli.sh
在 slave1 节点的 zookeeper cli 执行此命令:
get /test
如图所示:
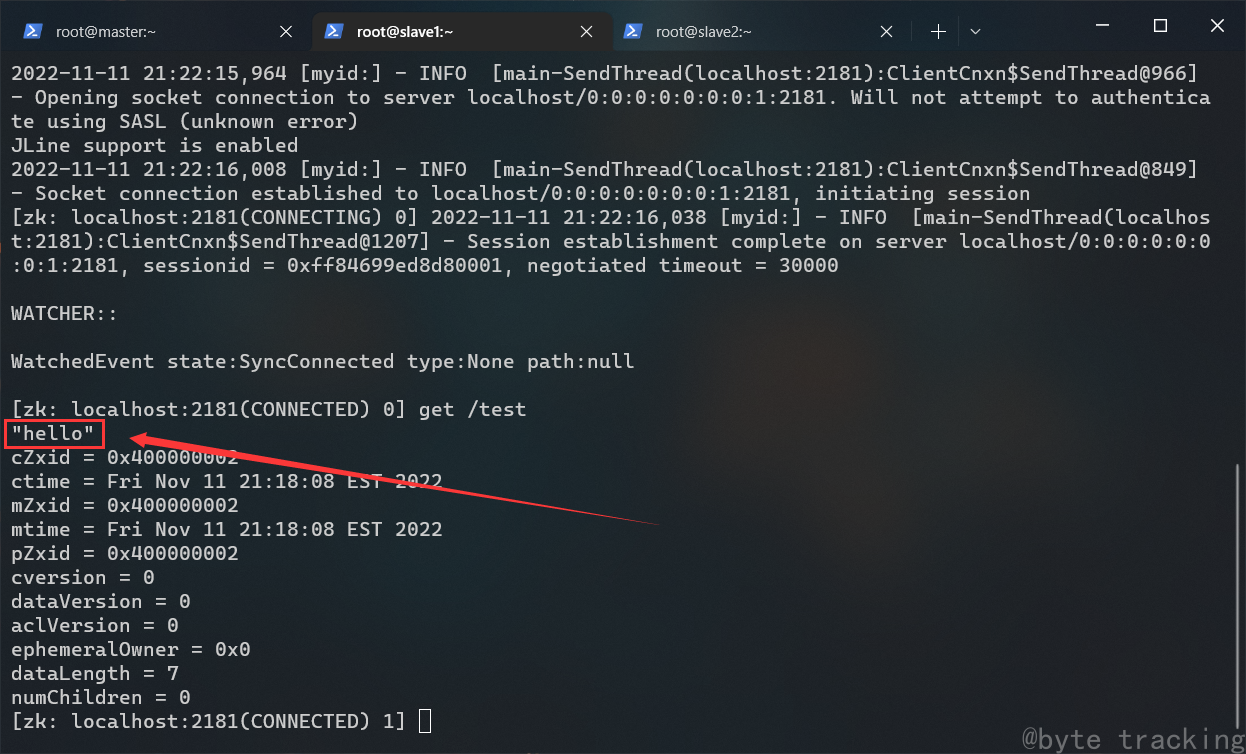
在 slave2 节点打开 zookeeper cli:
zkCli.sh
在 slave2 节点的 zookeeper cli 执行此命令:
get /test
如图所示:
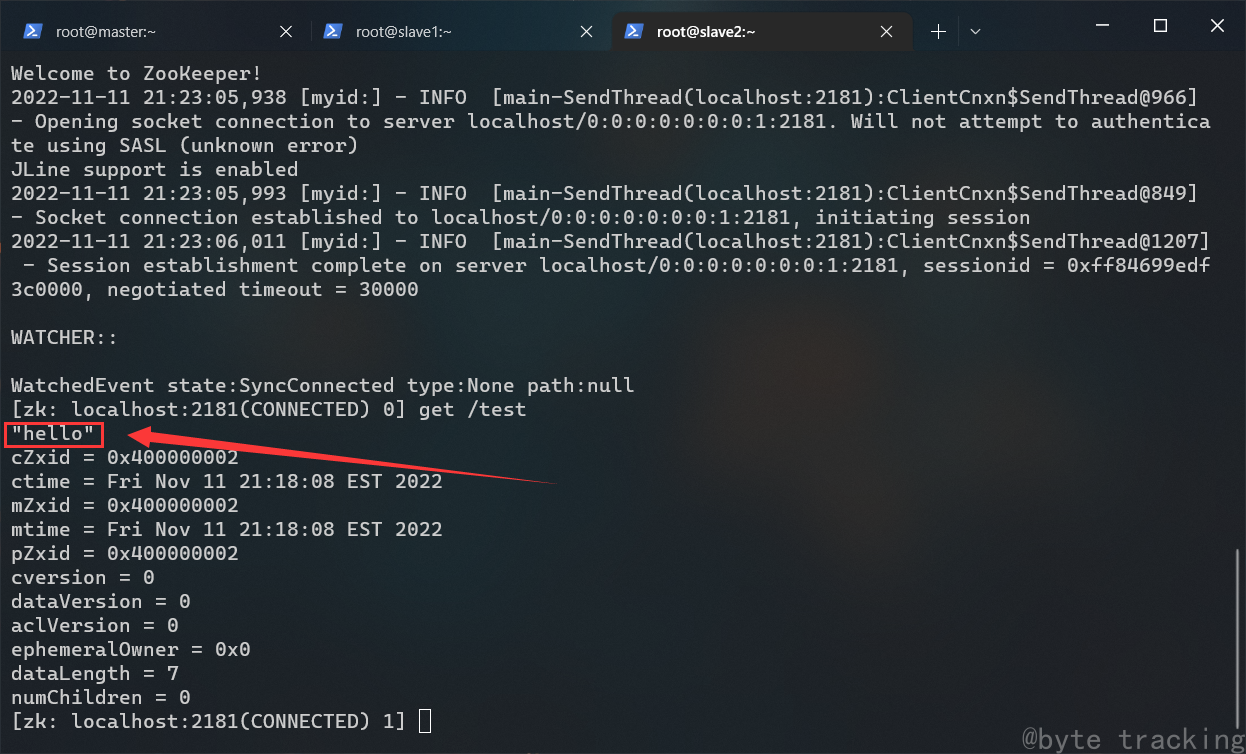
slave1 与 slave2 均出现 “hello” 即视为部署成功。
8.配置zk脚本文件
以下内容在 master 节点上操作
每次启动Zookeeper都需要在每台机器上操作,那为什么不配一个一键启动,查看和关闭的脚本呢?
首先进入Zookeeper的脚本文件中:
cd /opt/module/zookeeper/bin/
创建脚本文件:
vim zk.sh
编写脚本文件,将以下内容添加到文件当中:
#!/bin/bash
for host in master slave1 slave2 #节点名称
do
case $1 in
"start"){
echo "------------ $host start -----------"
ssh $host "/opt/module/zookeeper/bin/zkServer.sh start"
};;
"stop"){
echo "------------ $host stop -----------"
ssh $host "/opt/module/zookeeper/bin/zkServer.sh stop"
};;
"status"){
echo "------------ $host status -----------"
ssh $host "/opt/module/zookeeper/bin/zkServer.sh status"
};;
esac
done
给脚本文件添加权限:
chmod 777 zk.sh
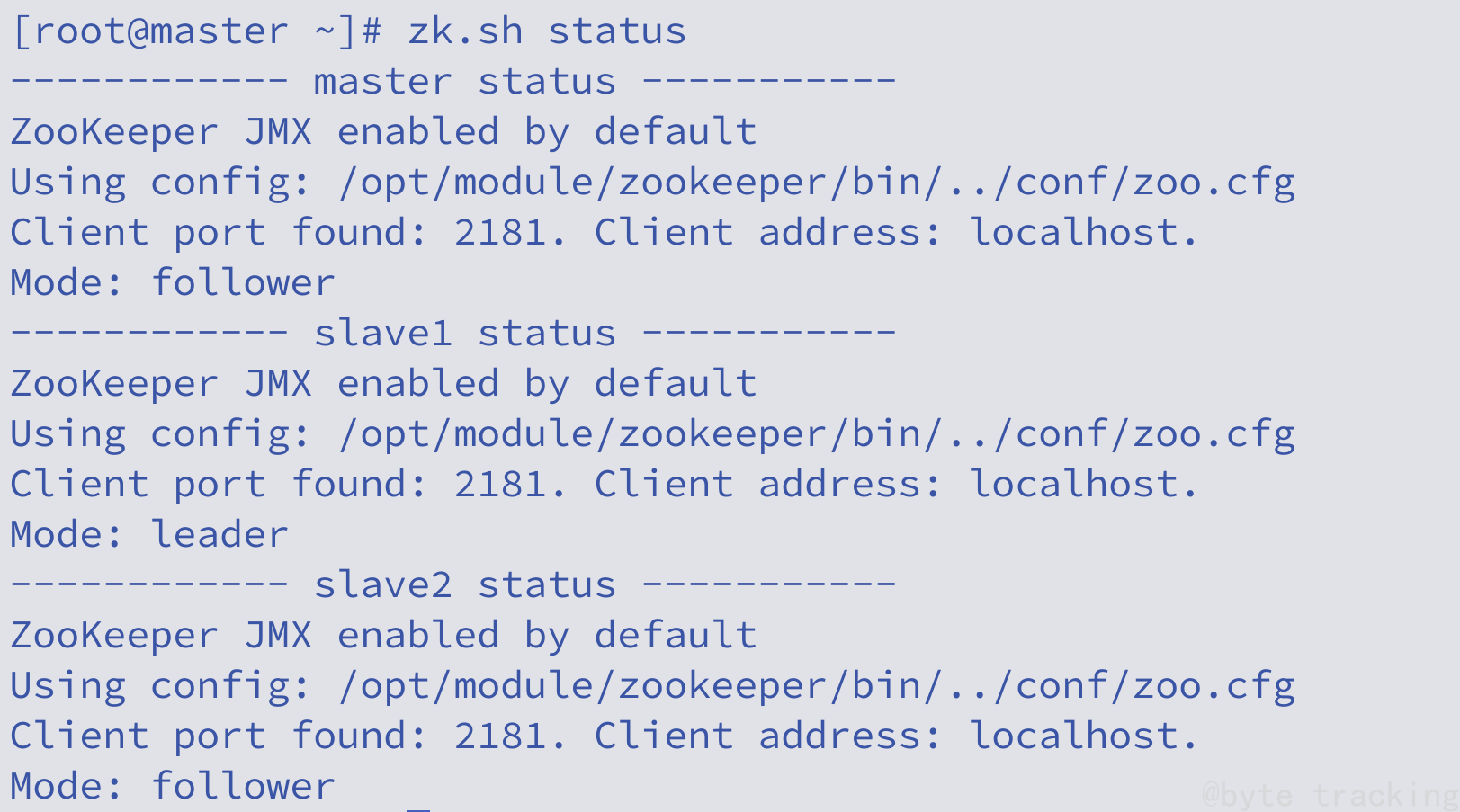
查看状态测试:
zk.sh status
如图所示,( leder 领导者,follower 追随者 ):
四、Mysql & Hive 组件部署
MySQL 数据库部署
以下内容全部在 master 节点上操作
前提条件
- mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar(位于 /opt/softwares/mysqlhome/ 下)
- mysql-community-client-5.7.28-1.el7.x86_64.rpm(位于 /opt/softwares/mysqlhome/ 下)
- mysql-community-common-5.7.28-1.el7.x86_64.rpm(位于 /opt/softwares/mysqlhome/ 下)
- mysql-community-devel-5.7.28-1.el7.x86_64.rpm(位于 /opt/softwares/mysqlhome/ 下)
- mysql-community-embedded-5.7.28-1.el7.x86_64.rpm(位于 /opt/softwares/mysqlhome/ 下)
- mysql-community-embedded-compat-5.7.28-1.el7.x86_64.rpm(位于 /opt/softwares/mysqlhome/ 下)
- mysql-community-embedded-devel-5.7.28-1.el7.x86_64.rpm(位于 /opt/softwares/mysqlhome/ 下)
- mysql-community-libs-5.7.28-1.el7.x86_64.rpm(位于 /opt/softwares/mysqlhome/ 下)
- mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm(位于 /opt/softwares/mysqlhome/ 下)
- mysql-community-server-5.7.28-1.el7.x86_64.rpm(位于 /opt/softwares/mysqlhome/ 下)
- mysql-community-test-5.7.28-1.el7.x86_64.rpm(位于 /opt/softwares/mysqlhome/ 下)
- 非分布式部署
1.安装软件包
进入 /opt/softwares/MySQL/ 目录内:
cd /opt/softwares/mysqlhome/
查看当前目录内的文件:
ls
如图所示:
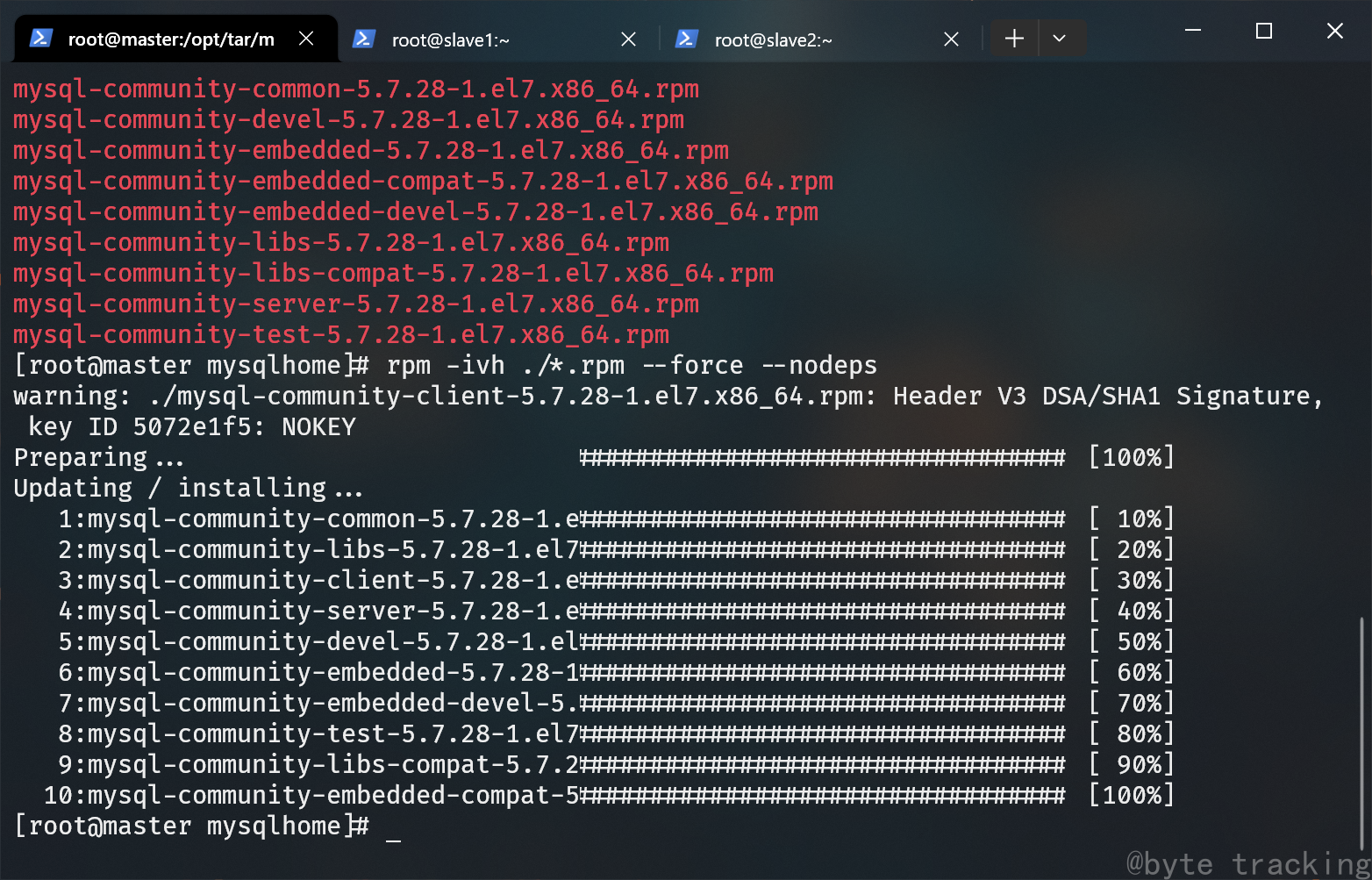
使用 rpm 包管理器安装当前目录所有 .rpm 软件包:
命令参数解释:
- -ivh:复合写法
- -i:安装
- -v:可视化安装
- -h:显示进度
- –force:忽略软件包及文件的冲突
- –nodeps:不处理依赖问题,强行安装(无网络环境下安装)
rpm -ivh ./*.rpm --force --nodeps
如图所示:
2.启动MySQL & 设置开机自启
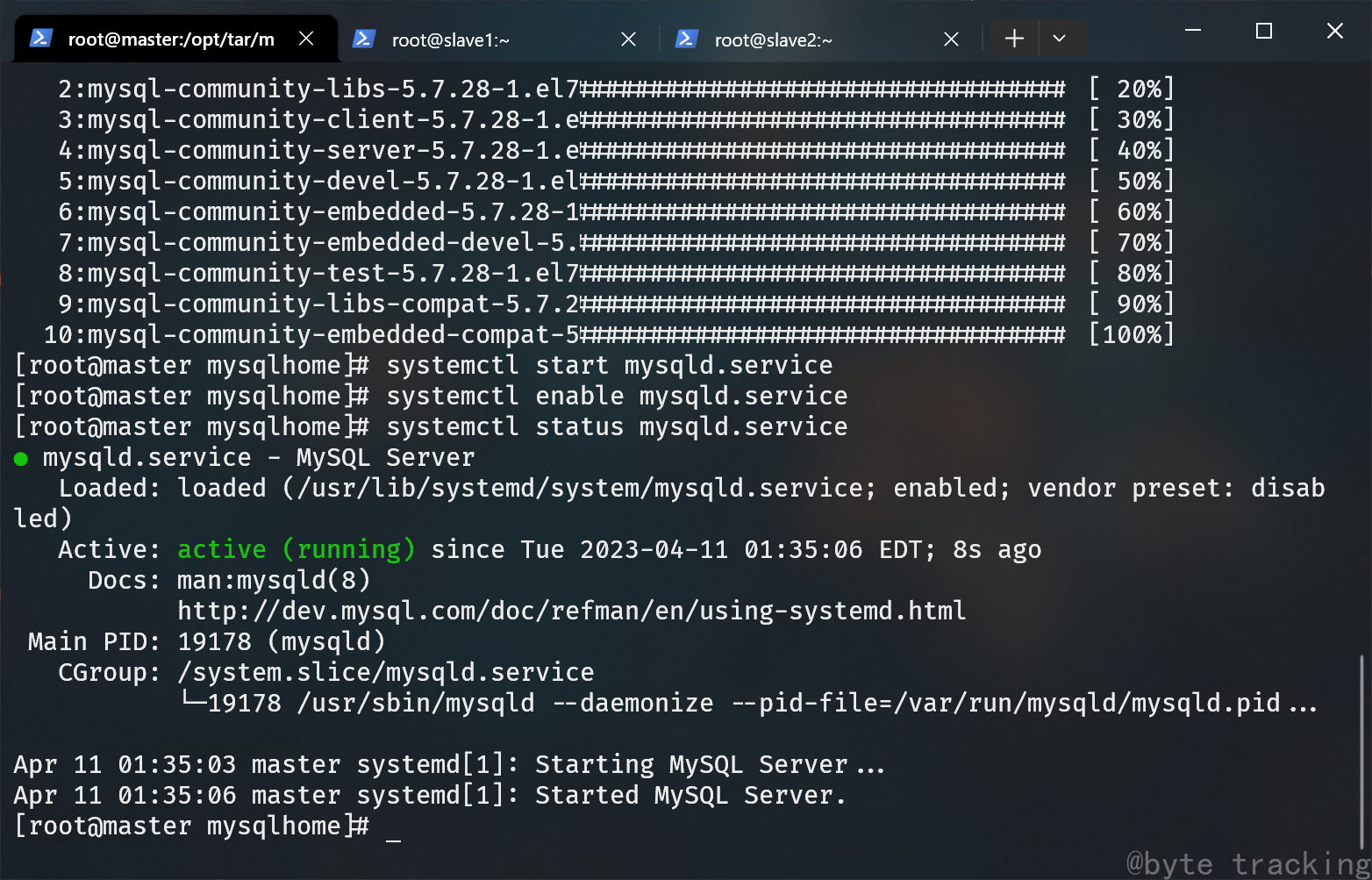
查看 mysqld 守护进程状态:
systemctl status mysqld.service
如果 mysqld 没有启动,则手动启动它:
systemctl start mysqld.service
设置开机启动 mysqld 守护进程:
systemctl enable mysqld.service
再次查看 mysqld 守护进程状态:
systemctl status mysqld.service
如图所示:
3.配置 MySQL
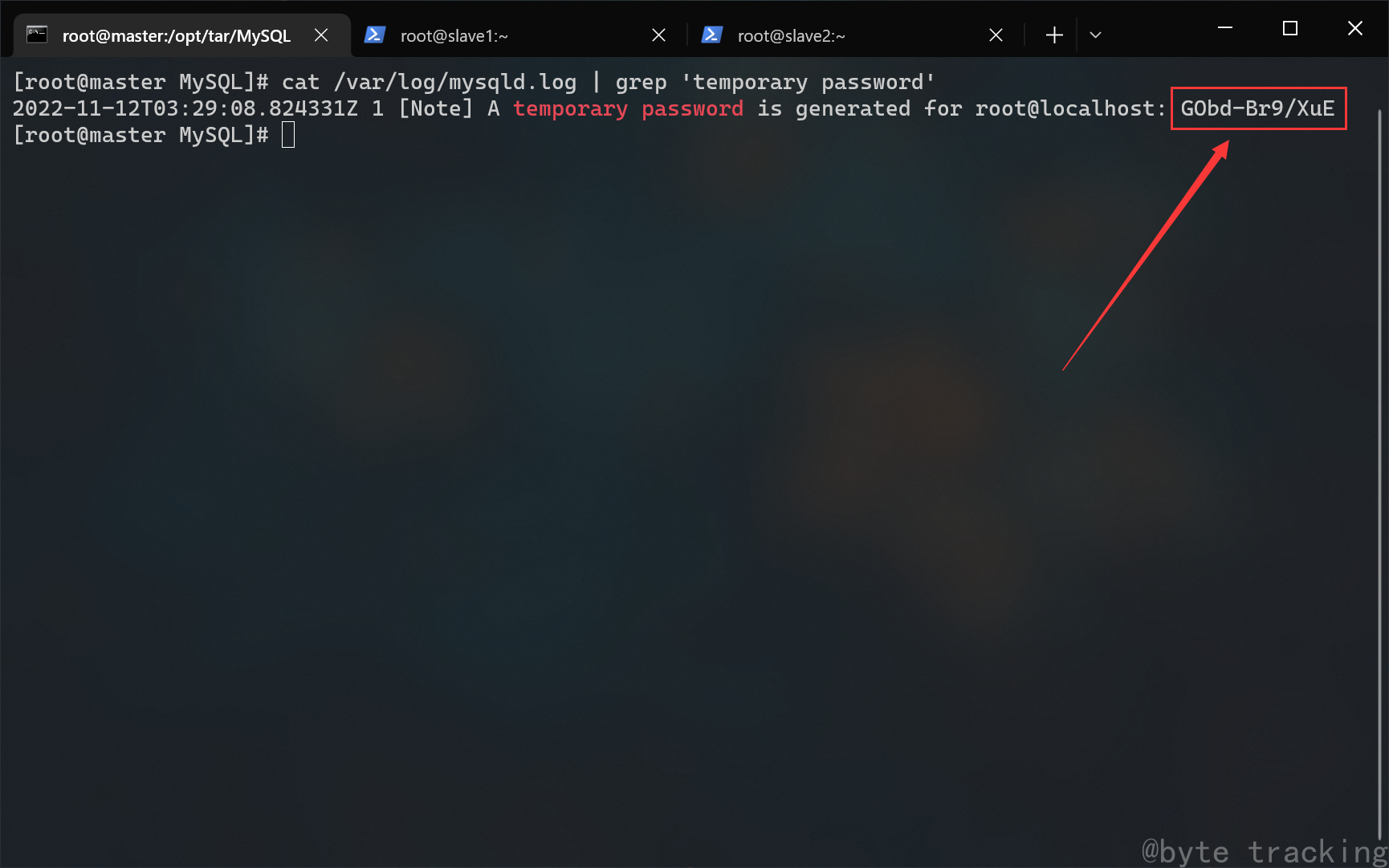
MySQL启动时,会在 /var/log/mysqld.log 输出日志。默认密码就在日志中。
使用 grep 命令查找日志中的密码:
grep 'temporary password' /var/log/mysqld.log
# 或
cat /var/log/mysqld.log | grep 'temporary password'
如图所示:
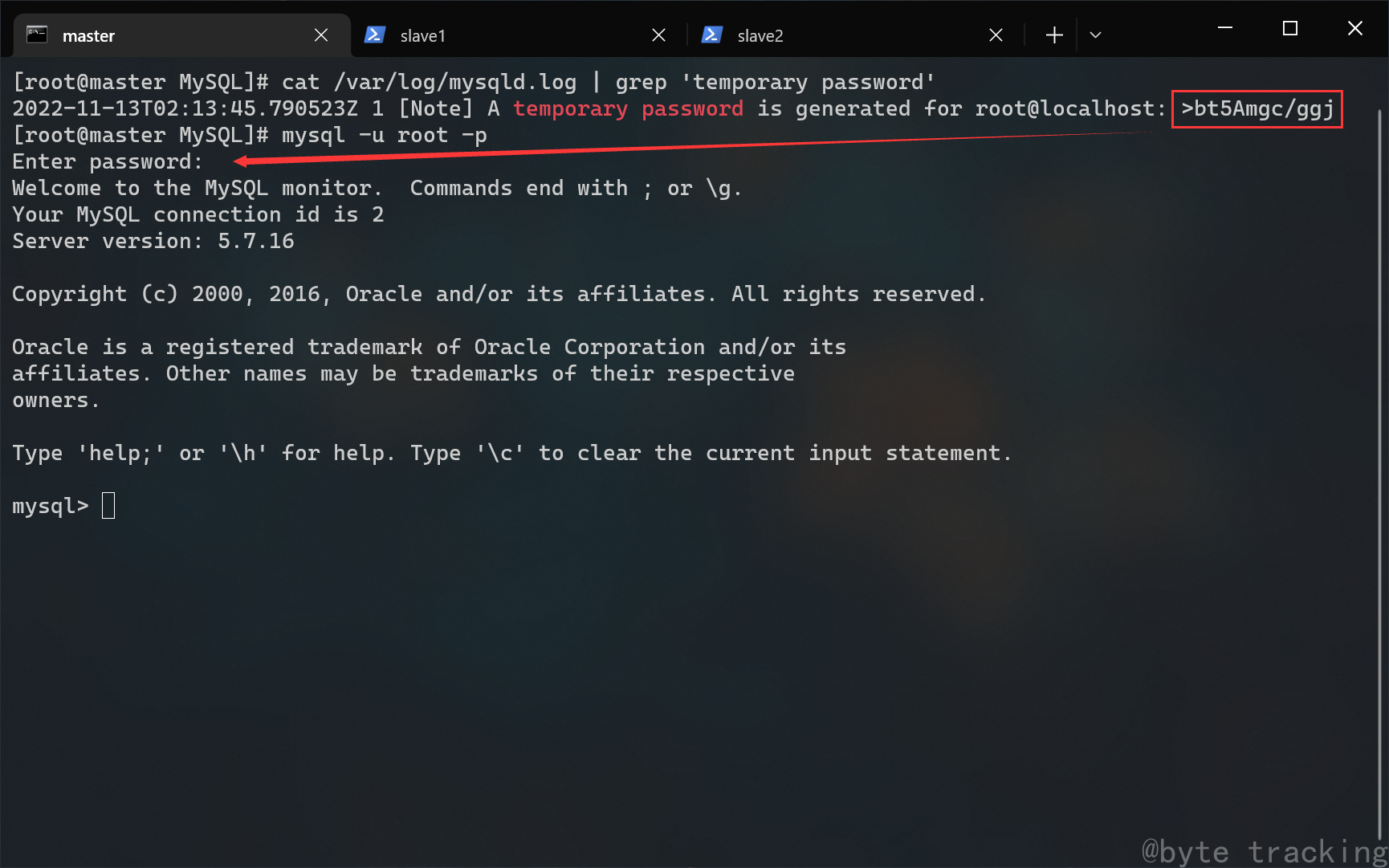
复制临时密码,以 root 身份登录到 mysql:
mysql -u root -p
如图所示:
密码强度限制调整为低级:
SET GLOBAL validate_password_policy=0;
调整密码最低长度限制:
SET GLOBAL validate_password_length=6;
修改 root@localhost(本地 root) 登录 的密码
下面我将mysql密码设置为:123456
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
创建一个用于远程登陆的用户:
/*
在开发环境建议这么做,在生产环境上是很危险的操作
'root'@'%' 表示任何主机的 root 账户
*/
CREATE USER 'root'@'%' IDENTIFIED BY '123456';
完全允许 root 远程连接:
命令解释:
- GRANT:赋权命令
- ALL PRIVILEGES:当前用户的所有权限
- ON:介词
- *.*:当前用户对所有数据库和表的操作权限
- TO:介词
- ‘root’@‘%’:权限赋给 root 用户,所有 ip 都能连接
- WITH GRANT OPTION:允许级联赋权
-- 在开发环境建议这么做,在生产环境上是很危险的操作。
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
刷新权限:
FLUSH PRIVILEGES;
修改字符集和时区:
vim /etc/my.cnf
在文件中的 [mysqld] 下面添加如下内容:
character-set-server=utf8mb4
default-time-zone='+08:00'
重启mysql服务:
systemctl restart mysqld.service
Hive 部署
以下内容全部在 master 节点上操作
介绍
Hive 是什么
- Apache Hive 是建立在 Hadoop 之上的一个由 Facebook 实现并开源的数据仓库系统。它可以将存储在 Hadoop 上的结构化数据、半结构化数据文件映射为一张数据表,并基于表提供了类似 SQL 的查询语法(HQL)用于访问和分析存储在 Hadoop 上的大型数据集。Hive 的核心是将 HQL 语句转为 MapReduce 程序,然后将程序提交到 Hadoop 集群执行。
Hive 与 Hadoop 的关系
- Hive 作为一个数据仓库系统具备存储和分析数据的能力,只不过 Hive 利用了 Hadoop 实现了数据存储的能力。简而言之就是 Hive 利用 Hadoop 的 HDFS 存储数据,利用 Mapreduce 查询分析数据。
Hive 出现的意义
- Hive 使得开发者专注于编写 HQL 进行数据分析,避免了 MapReduce 高昂的学习成本,提升了数据分析的效率。
前提条件
- apache-hive-3.1.2-bin.tar.gz(位于/opt/softwares下)
- mysql-connector-java-5.1.37.jar(位于/opt/softwares下)
- Hadoop 集群已经启动,Mysql 已部署完毕
- 非分布式部署
1.解压 hive
进入目录:
cd /opt/module
解压文件:
# 解压 apache-hive-3.1.2-bin.tar.gz 到当前目录
tar -zxvf /opt/softwares/apache-hive-3.1.2-bin.tar.gz
重命名:
mv apache-hive-3.1.2-bin/ hive
2.置入 jar 包
因为 hive 元数据库需要操作 mysql,所以需要将 java 连接 mysql 需要用到的驱动复制到 hive/lib/ 下:
cp /opt/softwares/mysql-connector-java-8.0.16.jar /opt/module/hive/lib/
guava 内部提供了很多高级的数据结构,如不可变的集合、图库,以及并发、I/O、散列、缓存、基元、字符串等实用工具。而 hive 与 hadoop 则使用到了其中的一些功能。但是随着版本的更新,其中的一些代码与旧版本不可以互通,所以我们需要使 hive 和 hadoop 依赖的 guava 版本保持一致:
进入 hive 的 jar 目录:
cd /opt/module/hive/lib
删除 hive 里的 guava:
rm -rf guava-19.0.jar
从 hadoop 复制高版本的 guava 到 hive:
cp $HADOOP_HOME/share/hadoop/common/lib/guava-27.0-jre.jar ./
3.配置环境变量
编辑环境变量:
env-edit
在文件末尾添加:
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
生效环境变量
env-update
4.配置 hive-env.sh
进入到 hive 配置文件的目录下:
cd $HIVE_HOME/conf
拷贝模板:
cp ./hive-env.sh.template ./hive-env.sh
编辑 hive-env.sh:
vim ./hive-env.sh
在文件末尾添加:
export JAVA_HOME=/opt/module/jdk
export HADOOP_HOME=/opt/module/hadoop
export HIVE_HOME=/opt/module/hive
export HIVE_CONF_DIR=$HIVE_HOME/conf
修改堆内存:
注意:新版本的 Hive 启动的时候,默认申请的 JVM 堆内存大小为 256M,JVM 堆内存申请的太小 ,导 致 后 期 开 启 本 地 模 式 , 执 行 复 杂 的 SQL 时 经 常 会 报 错:java.lang.OutOfMemoryError: Java heap space,因此最好提前调整一下 HADOOP_HEAPSIZE 这个参数
将参数 export HADOOP_HEAPSIZE 取消注释并修改为 2048
export HADOOP_HEAPSIZE=2048
5.配置 hive-site.xml
请确保您已进入 Hive 的配置目录
拷贝模板:
cp ./hive-default.xml.template ./hive-site.xml
编辑 hive-site.xml:
vim ./hive-site.xml
修改以下配置:
直接在 hive-site.xml 文件查找对应项修改参数,没有的则添加,切勿全部删除!!!
vi / vim 编辑器命令模式下使用 “/关键字” 搜索,按 N 键跳转到下一个搜索结果。
<!--配置数据库地址-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hivedb?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<!--配置数据库驱动-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--配置数据库用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--配置MySQL数据库root的密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- 在 hibe cli 内显示当前所在的数据库 -->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!-- 在 hibe cli 内显示表头 -->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!-- 关闭版本验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- 以本地模式运行 -->
<property>
<name>hive.exec.mode.local.auto</name>
<value>true</value>
</property>
<!-- 开启此参数可以提高hiveserver2的启动速度 -->
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>
<!-- 添加如下内容 -->
<!-- 指定 hiveserver2 连接的 host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>master</value>
</property>
<!-- 指定 hiveserver2 连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!--指定存储元数据要连接的地址,配置后就是远程模式,每次启动hive需要在master启动元数据服务
虽然hive是单击部署,但是后续的spark是集群部署,可以把hive-site.xml文件拷贝到spark集群,只要在master启动元数据服务之后,两台从节点就可以通过master获取到元数据信息-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
<!----------------------------------------------------->
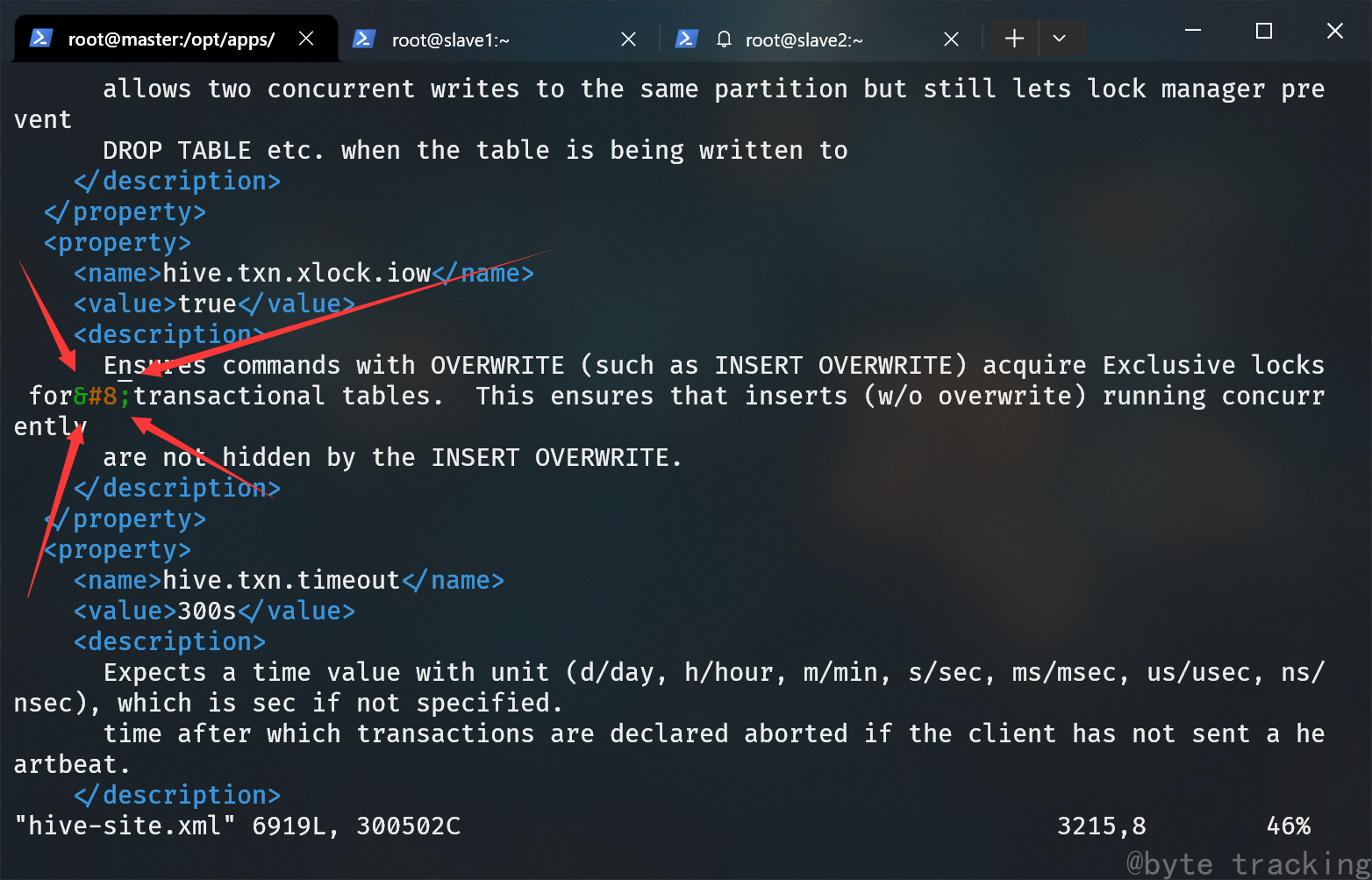
修改完配置后输入 :3215 来快速跳转到第 3215 行,或者使用 “/” 关键字搜索 hive.txn.xlock.iow
删掉  这四个字符。
6.配置 log4j.properties
请确保您已进入 Hive 的配置目录
拷贝模板即可:
cp hive-log4j2.properties.template hive-log4j2.properties
7.schema 初始化
执行初始化:
schematool -dbType mysql -initSchema
如图所示:

8.启动 hive
启动 hive :
hive
如果出现这个报错:(绝对URI中的相对路径)
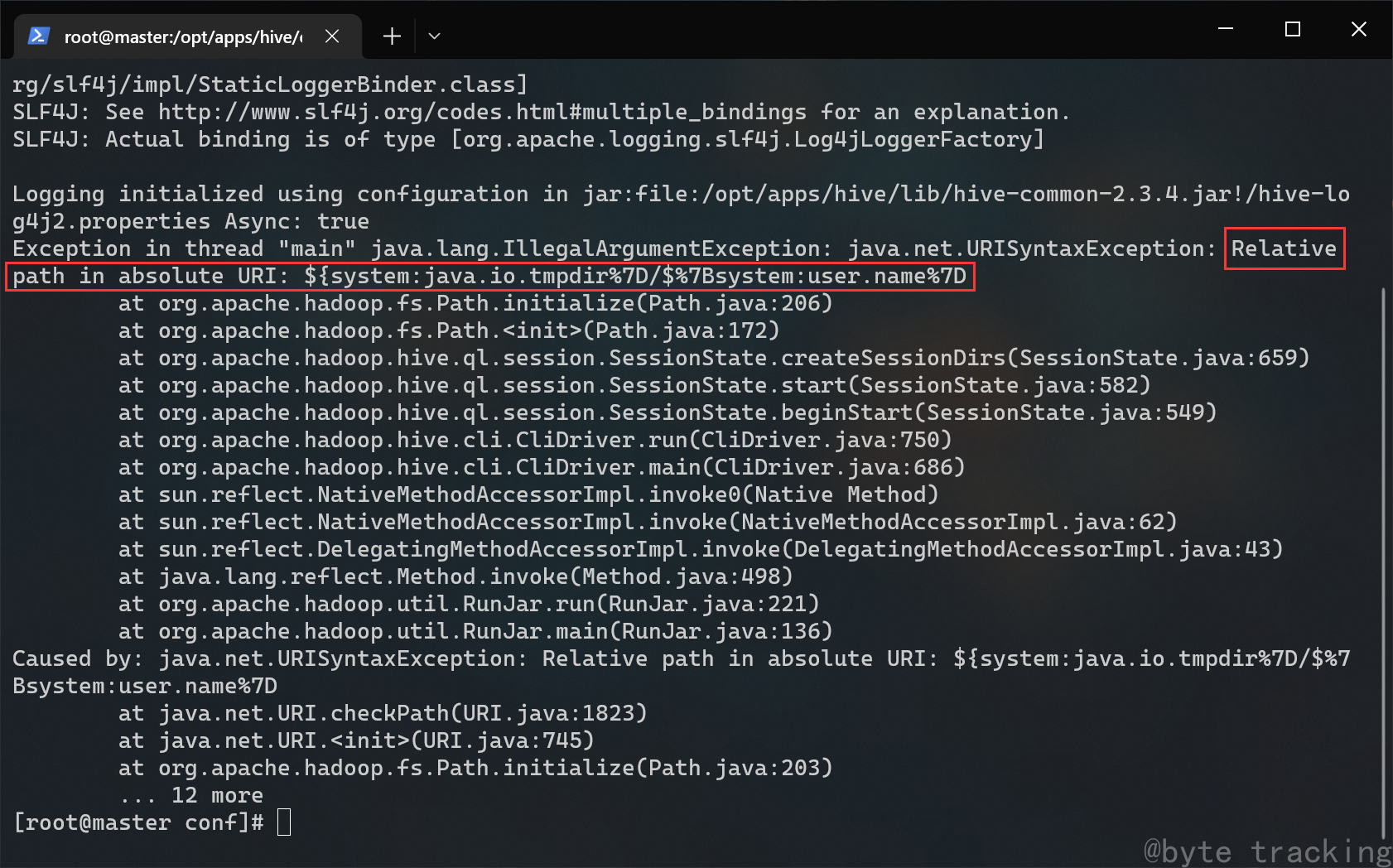
解决方案是 ctrl + d 退出 hive cli,然后把hive-site.xml 文件中绝对路径字眼 “system:” 全部删掉:
# sed 命令用于批量替换文本内容
# sed -i "s/要替换的/替换为/g" 目标文件路径
sed -i "s/system://g" /opt/module/hive/conf/hive-site.xml
启动hive元数据服务
nohup hive --service metastore &
再次尝试启动 hive:
hive
如图所示:
输入 exit; 或按下 ctrl + d 退出 hive cli。
9.使用 hive
目的:使用 hive 处理存储在 hdfs 内的结构化数据,使得我们可以通过 SQL 语句操作这些数据。
我们先来创建一个结构化的数据:
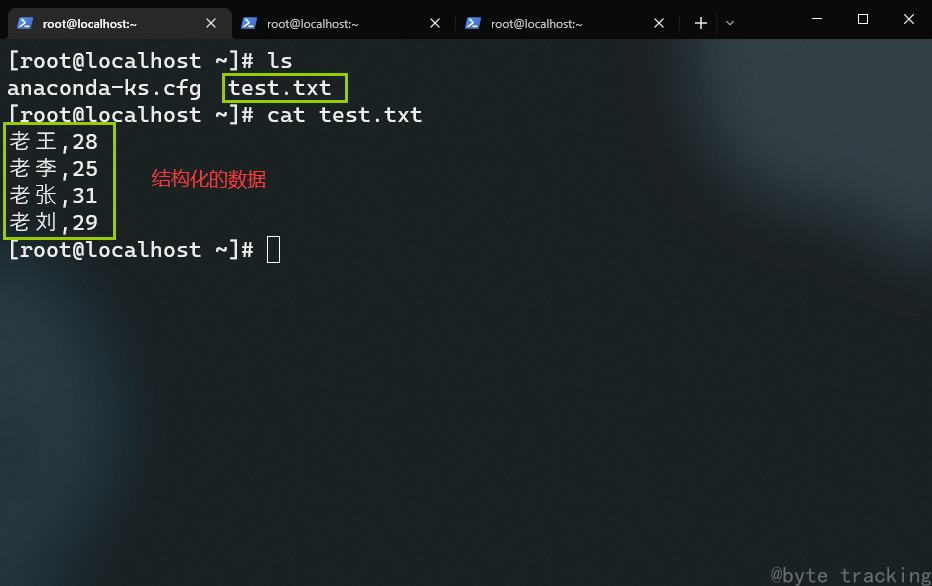
vim ~/test.txt
写入这些东西:
老王,28
老李,25
老张,31
老刘,29
如图所示:
在 hdfs 里创建一个 test_hive 目录:
hdfs dfs -mkdir /test_hive
把我们刚刚写的 test.txt 发送到 hdfs 文件系统的 /test_hive 目录里 :
hdfs dfs -put ~/test.txt /test_hive/
如果发送文件到hdfs时遇到错误,请尝试重启您的hadoop。
# 停止 hadoop 集群
stop-all.sh
# 启动 hadoop 集群
start-all.sh
如果还是不行,请尝试此方案(会清空 hdfs 内所有的数据):
# 停止 hadoop 集群
stop-all.sh
# 清空您在 core-site.xml 里设置的 hadoop.tmp.dir 目录(在所有节点上执行这句)
rm -rf $HADOOP/tmp
# 重新格式化 namenode(在 master 节点上执行这句)
hdfs namenode -format
# 启动 hadoop 集群
start-all.sh
回到正题,cat一下,证明已经发送到hdfs里了
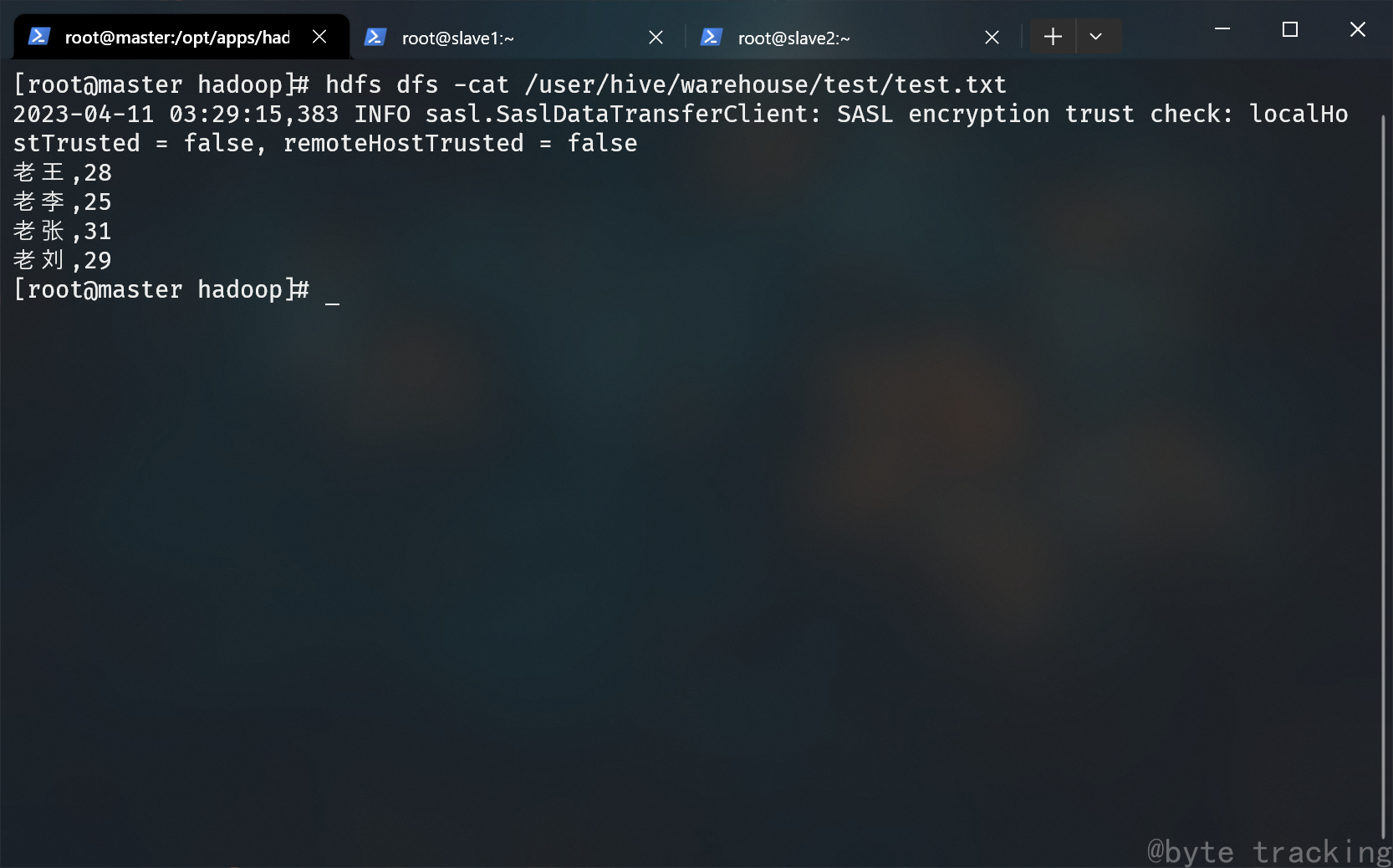
hdfs dfs -cat /test_hive/test.txt
如图所示:
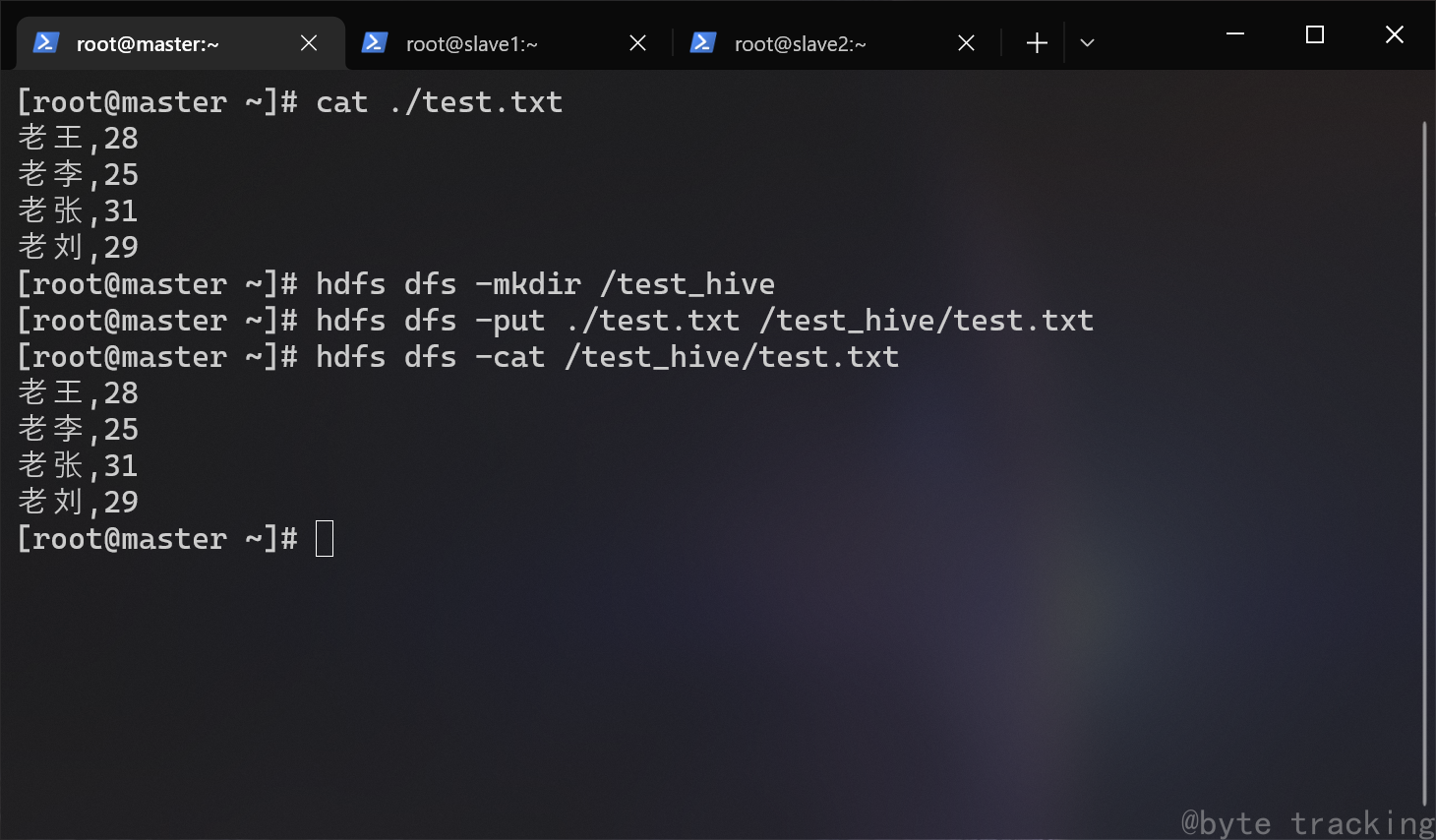
启动 hive :
hive
创建一个拥有两个字段 name 和 age 的数据表 test。这个表以 “,” 分隔列、以换行符分隔行:
CREATE TABLE test (
name string,
age int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ",";
如图所示:
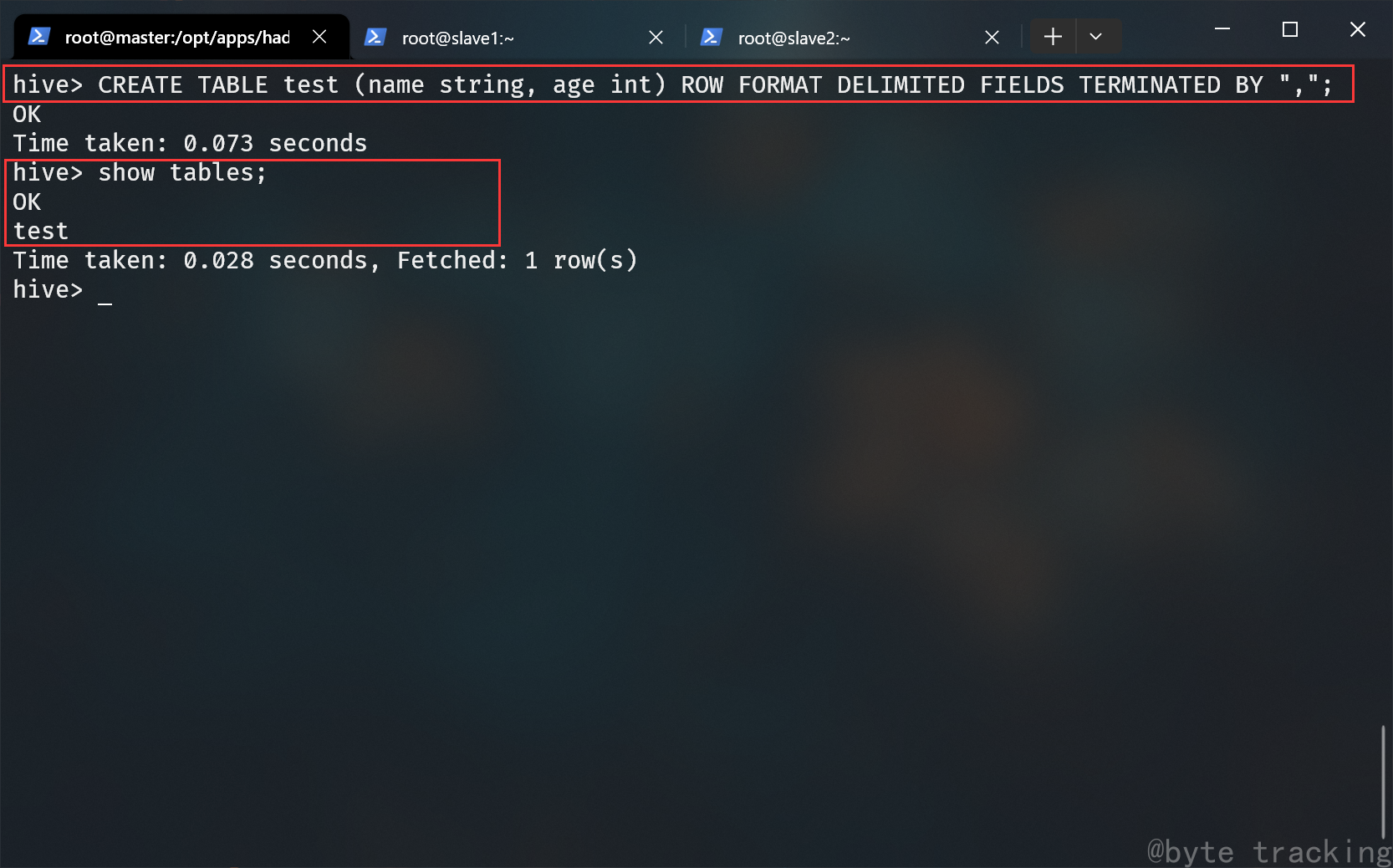
从 hdfs 导入 /test_hive/test.txt 内的数据到 test 数据表:
-- LOAD DATA INPATH 'hdfs 路径' INTO TABLE 表名;
LOAD DATA INPATH '/test_hive/test.txt' INTO TABLE test;
如图所示:
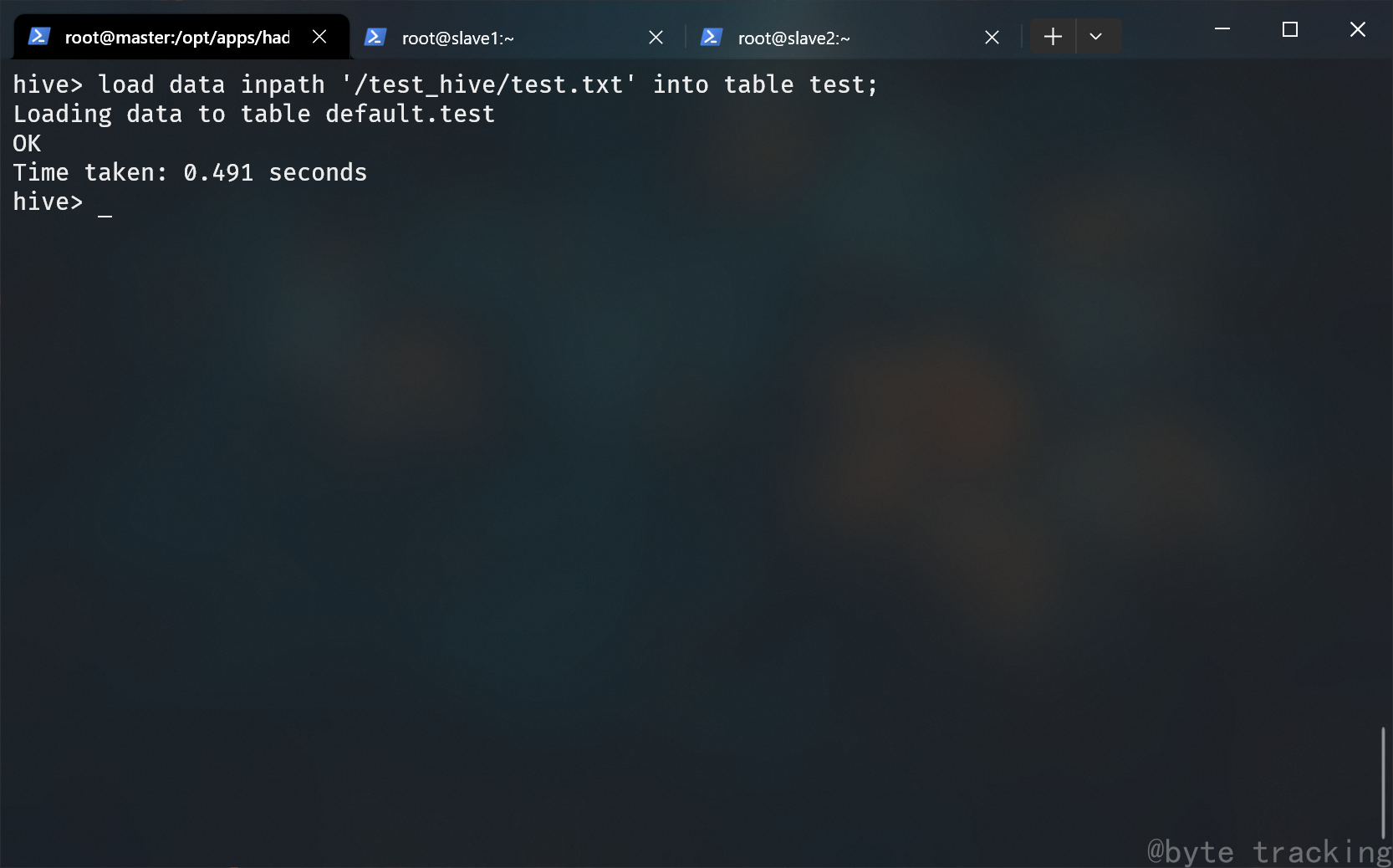
执行一个大家熟悉的命令来验证下:
SELECT * FROM test;
如图所示:
输入 exit 或按下 ctrl + d 退出 hive cli:
exit;
在 hdfs 里可查看到 hive 的数据表信息:
hdfs dfs -cat /user/hive/warehouse/test/test.txt
如图所示:
五、Hbase 集群部署
介绍
-
HBase是一个开源的非关系型分布式数据库,它参考了谷歌的BigTable建模,实现的编程语言为Java。它是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,为 Hadoop 提供类似于BigTable 规模的服务。因此,它可以容错地存储海量稀疏的数据。
-
HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌BigTable的开源实现,主要用来存储非结构化和半结构化的松散数据。HBase的目标是处理非常庞大的表,可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行数据和数百万列元素组成的数据表。
前提条件
- hbase-2.2.3-bin.tar.gz(位于/opt/softwares/ 下)
- 集群时间已经同步
- Hadoop 和 Zookeeper 集群已经启动
- 分布式部署
1.解压文件
以下内容在 master 节点上操作
进入目录:
cd /opt/module/
解压 hbase-2.2.3-bin.tar.gz 到当前目录:
tar -zxvf /opt/softwares/hbase-2.2.3-bin.tar.gz
重命名 hbase :
mv hbase-2.2.3/ hbase
2.配置环境变量
以下内容在 master 节点上操作
编辑环境变量:
env-edit
在文件末尾添加:
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase
export PATH=$PATH:$HBASE_HOME/bin
生效环境变量
env-update
3.修改配置文件
以下内容在 master 节点上操作
进入配置文件目录:
cd /opt/module/hbase/conf/
编辑 hbase-env.sh:
vim hbase-env.sh
找到并取消注释,然后修改:
# 配置 Java 环境变量
export JAVA_HOME=/opt/module/jdk/
# 使用独立部署的 zookeeper
export HBASE_MANAGES_ZK=false
# 禁止 Hbase 查找 Hadoop 的 Classs 以防止冲突问题
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="false"
配置 hbase-site.xml:
vim hbase-site.xml
配置后:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- hbase 的数据保存在 hdfs 对应目录下 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9820/hbase</value>
</property>
<!-- 是否是分布式环境 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 冗余度 自己的生产环境设置 1 即可,不需要那么多的备份占用空间-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 连接 zookeeper -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<!-- zookeeper 数据目录 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper/data</value>
</property>
<!-- 配置 zookeeper 数据目录的地址,三个节点都启动 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<!--
关闭 hbase kerberos 认证(使用本地文件系统存储,不使用 HDFS 的情况下需要将此配置设置为 false)
当时找了好久才解决🙍:https://blog.youkuaiyun.com/qq_58768870/article/details/121111992
-->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
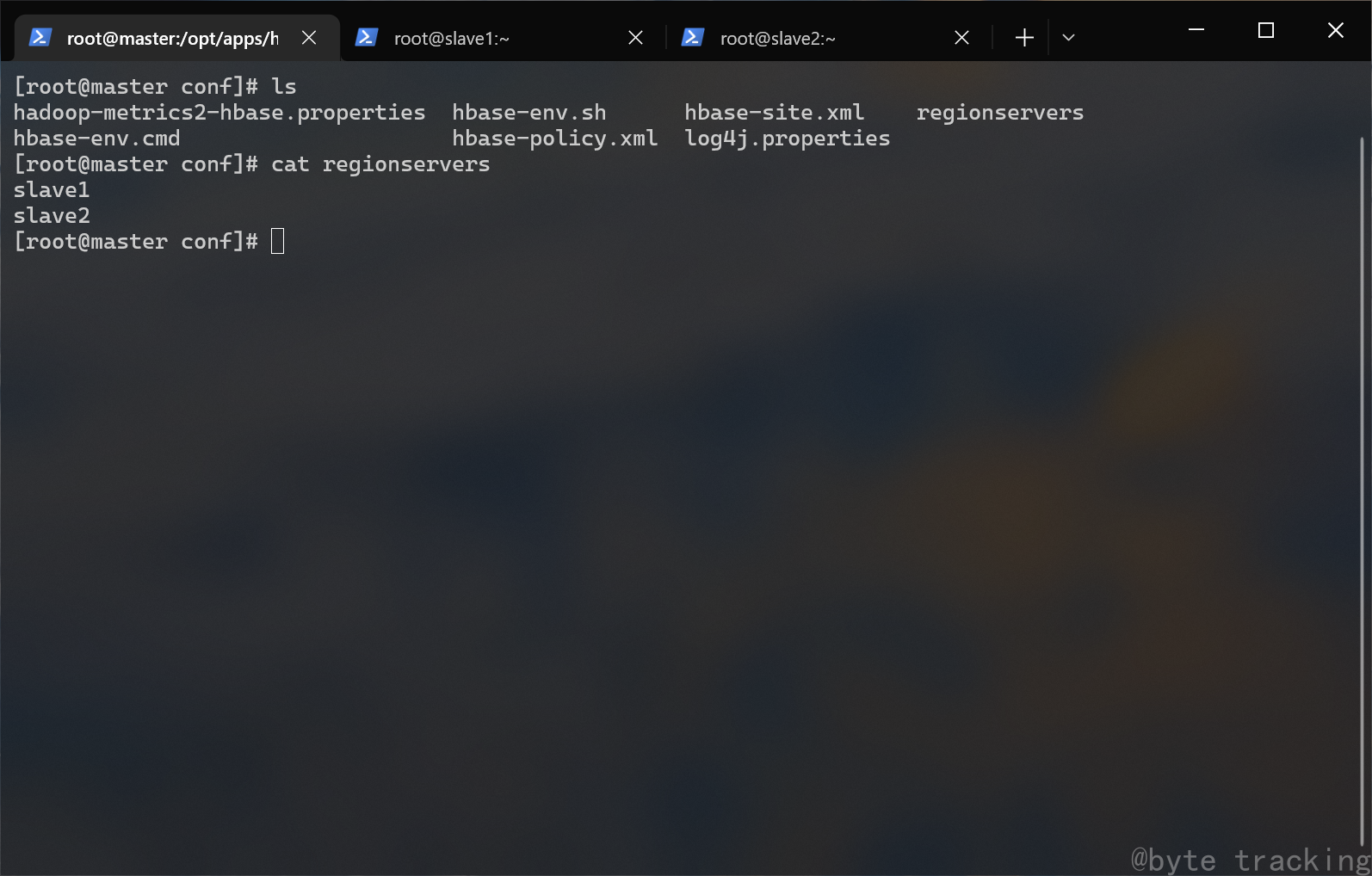
修改配置文件(master 节点):
vim regionservers
删掉默认的内容并将内容改为:
master
slave1
slave2
如图所示:
进入此目录将相应的 jar 包重命名,否则会与 Hadoop 冲突:
cd $HBASE_HOME/lib/client-facing-thirdparty/
mv ./slf4j-log4j12-1.7.25.jar slf4j-log4j12-1.7.25.jar.bak
4.分发文件
以下内容在 master 节点上操作
分发文件到 slave1、slave2 :
#分发hbase文件
scp -r /opt/module/hbase slave1:/opt/module/
scp -r /opt/module/hbase slave2:/opt/module/
#分发环境变量
scp -r /etc/profile.d/myenv.sh slave1:/etc/profile.d
scp -r /etc/profile.d/myenv.sh slave2:/etc/profile.d
5.生效环境变量
以下内容在 slave1 和 slave2 上操作
env-update
6.启动测试
master 节点上启动:
start-hbase.sh
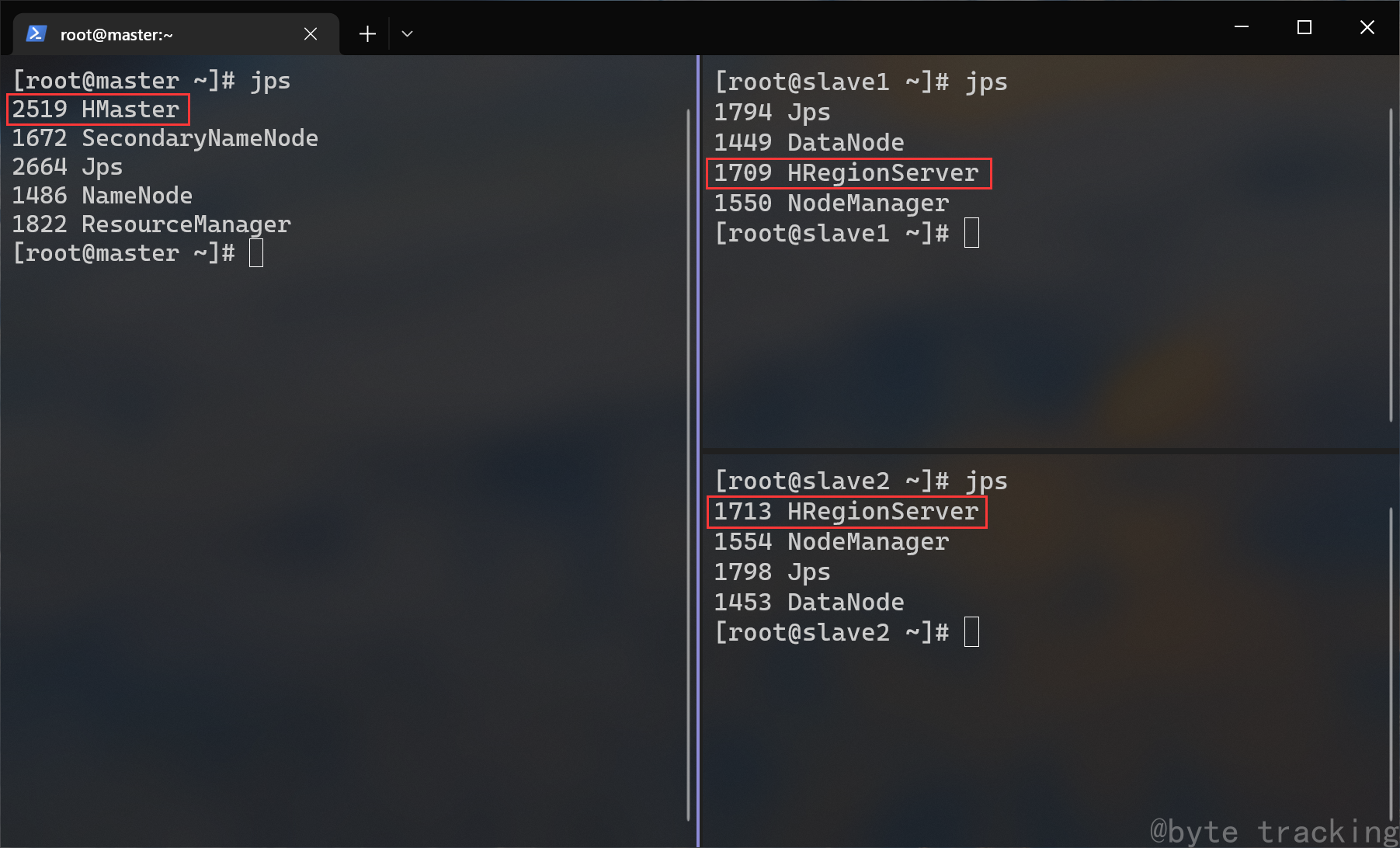
检查进程(三个节点):
jps
master 节点从出现 Hmaster,HregionServer 进程,slave1、slave2 上出现 HregionServer 进程:
访问 http://192.168.122.100:16010/ 查看 hbase 的 WebUI 启动情况:
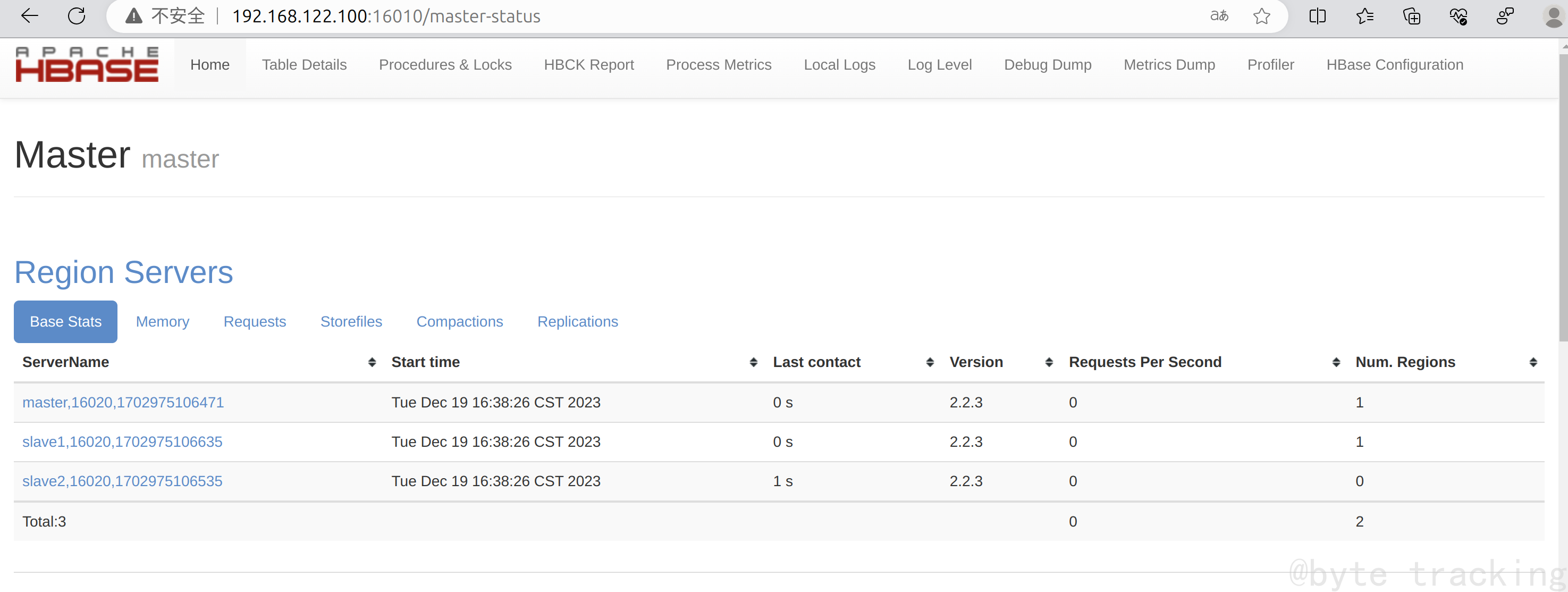
注意: 如果Hbase没有正常启动,请检查自己的集群时间是否同步确保所有节点的时区一致、时间误差±3s。如果没有同步,请移步基础环境配置
7.Hbase shell
以下内容在 master 节点上操作
确保您已经启动了 hadoop 和 zookeeper
进入 hbase 命令行:
hbase shell
常用命令 - 表操作:
| 行为 | 命令 |
|---|---|
| 创建表 | create '表名', '列簇名1', '列簇名2', '列簇名N' |
| 添加列簇 | alter '表名', '列簇名' |
| 删除列簇 | alter '表名', {NAME=>'列簇名', METHOD=>'delete'} |
| 启用/禁用表 | enable/disable '表名' |
| 是否启用/禁用 | is_enabled/is_disabled |
| 删除表 | 仅能删除已被禁用的表:drop '表名' |
| 查看表结构 | describe '表名' |
| 检查表是否存在 | exists '表名' |
常用命令 - 增删改查:
| 行为 | 命令 |
|---|---|
| 添加记录 | put '表名', '行键', '列簇:列名', '值' |
| 删除记录 | delete '表名', '行键', '列簇:列名' |
| 删除整行的值 | deleteall '表名', '行键' |
| 更新记录 | 再添加一次,覆盖原来的(put) |
| 查看记录 | get '表名', '行键' |
| 查看表中记录数 | count '表名' |
常用命令 - 搜索:
| 行为 | 命令 |
|---|---|
| 扫描整张表 | scan '表名' |
| 扫描整个列簇 | scan '表名', {COLUMN=>'列簇'} |
| 查看某表某列所有数据 | scan '表名', {COLUMN=>'列簇:列名'} |
| 限制查询结果行数(先根据 RowKey 定位 Region,再向后扫描) | scan '表名', {STARTROW=>'起始行名', LIMIT=>行数, VERSIONS=>版本数} |
| 限制查询结果行数(先根据 RowKey 定位 Region,再向后扫描) | scan '表名', {STARTROW=>'起始行名', STOPROW=>终止行名, VERSIONS=>版本数} |
| 限制查询结果行数(先根据 RowKey 定位 Region,再向后扫描) | scan '表名', {TIMERANGE=>[起始时间戳(毫秒), 终止时间戳(毫秒)], VERSIONS=>版本数} |
| 使用等值过滤进行搜索 | scan '表名', FILTER=>"ValueFilter(=, 'binary': 值)" |
| 使用值包含子串过滤进行搜索 | scan '表名', FILTER=>"ValueFilter(=, 'subsreing': 字串)" |
| 使用列名的前缀进行搜索 | scan '表名', FILTER=>"ColumnPrefixFilter('前缀')" |
| 使用 RowKey 的前缀进行搜索 | scan '表名', FILTER=>"PrefixFilter('前缀')" |
ctrl + d 退出 hbase 命令行:
六、Scala & Spark 集群部署
Scala & Spark集群部署与Spark On Yarn集群部署 根据个人需求二选一即可
介绍
-
Spark是一种快速、通用、可扩展的大数据分析引擎,于2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。
-
Spark是基于内存计算的大数据并行计算框架。除了扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。Spark适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理。
-
“Scala & Spark 集群部署” 的核心是 “基于 Scala 环境,搭建 Spark 分布式集群”,其特点围绕 “部署模式灵活、依赖简洁、架构轻量、适配不同规模场景” 展开,本质是为 Spark 提供 “分布式运行的基础设施”,同时继承 Scala 与 Spark 本身的语言 / 框架特性。
前提条件
- scala-2.12.11.tgz(位于/opt/softwares/ 下)
- spark-3.1.1-bin-hadoop3.2.tgz(位于/opt/softwares/ 下)
- mysql-connector-java-8.0.16.jar (位于 /opt/softwares/ 下)
- Hadoop 集群已经启动
- Hbase,hive已部署完成
- 分布式部署
1.解压文件
以下内容在 master 节点上操作
进入目录:
cd /opt/module
分别解压 scala 与 spark 到当前目录:
# scala
tar -zxvf /opt/softwares/scala-2.12.11.tgz
# spark
tar -zxvf /opt/softwares/spark-3.1.1-bin-hadoop3.2.tgz
重命名 scala 与 spark :
mv scala-2.12.11/ scala
mv spark-3.1.1-bin-hadoop3.2/ spark
2.配置环境变量
以下内容在 master 节点上操作
编辑环境变量:
env-edit
在文件末尾添加:
#SCALA_HOME && SPARK_HOME
export SCALA_HOME=/opt/module/scala
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin
生效环境变量:
env-update
3.配置 spark-env.sh
以下内容在 master 节点上操作
进入配置目录:
cd $SPARK_HOME/conf
使用预置模板:
cp ./spark-env.sh.template ./spark-env.sh
编辑它:
vim ./spark-env.sh
在末尾添加这些:
export SCALA_HOME=/opt/module/scala
export JAVA_HOME=/opt/module/jdk
export HADOOP_CONF_DIR=/opt/module/hadoop/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_HOST=master
export SPARK_WORKER_PORT=7078
4.配置 slaves
以下内容在 master 节点上操作
确保在 /opt/module/spark/conf 目录下
使用预置模板:
cp ./workers.template ./workers
编辑它:
vim ./workers
删掉默认存在的 localhost,在末尾写入这些:
master
slave1
slave2
5.拷贝并修改文件
以下内容在 master 节点上操作
确保在 /opt/module/spark/conf 目录下
将hive中conf下面的hive-site.xml传输到spark的conf下,使其读取hive:
cp /opt/module/hive/conf/hive-site.xml ./
因为下面要分发到另外两台主机,所以我们拷贝后对其进行修改,将 localhost 全部替换为 master ( 或者 IP ):
# sed 命令用于批量替换文本内容
# sed -i "s/要替换的/替换为/g" 目标文件路径
sed -i "s/localhost/master/g" /opt/module/spark/conf/hive-site.xml
进入 spark 的 jars 目录:
cd /opt/module/spark/jars
将mysql驱动放到spark的jars目录中:
cp /opt/softwares/mysql-connector-java-8.0.16.jar ./
将hbase的jar包放到spark的jars目录,使其可以操作hbase的数据:
cp /opt/module/hbase/lib/hbase*.jar ./
cp /opt/module/hbase/lib/guava-11.0.2.jar ./
cp /opt/module/hbase/lib/client-facing-thirdparty/htrace-core4-4.2.0-incubating.jar ./
6.分发文件
以下内容在 master 节点上操作
分发 scala、spark 到 slave1、slave2:
#scala
scp -r $SCALA_HOME slave1:/opt/module/
scp -r $SCALA_HOME slave2:/opt/module/
#spark
scp -r $SPARK_HOME slave1:/opt/module/
scp -r $SPARK_HOME slave2:/opt/module/
分发环境变量文件到 slave1、slave2(正常版):
scp /etc/profile.d/myenv.sh slave1:/etc/profile.d/
scp /etc/profile.d/myenv.sh slave2:/etc/profile.d/
分发环境变量文件到 slave1、slave2(骚操作):
cd /etc/profile.d/
scp ./myenv.sh slave1:$(pwd)/
scp ./myenv.sh slave2:$(pwd)/
7.生效环境变量
以下内容在 slave1和slave2 上操作
env-update
8.启动与测试
以下内容在 master 节点上操作
进入目录:
cd /opt/module/spark/sbin
启动命令:
./start-all.sh
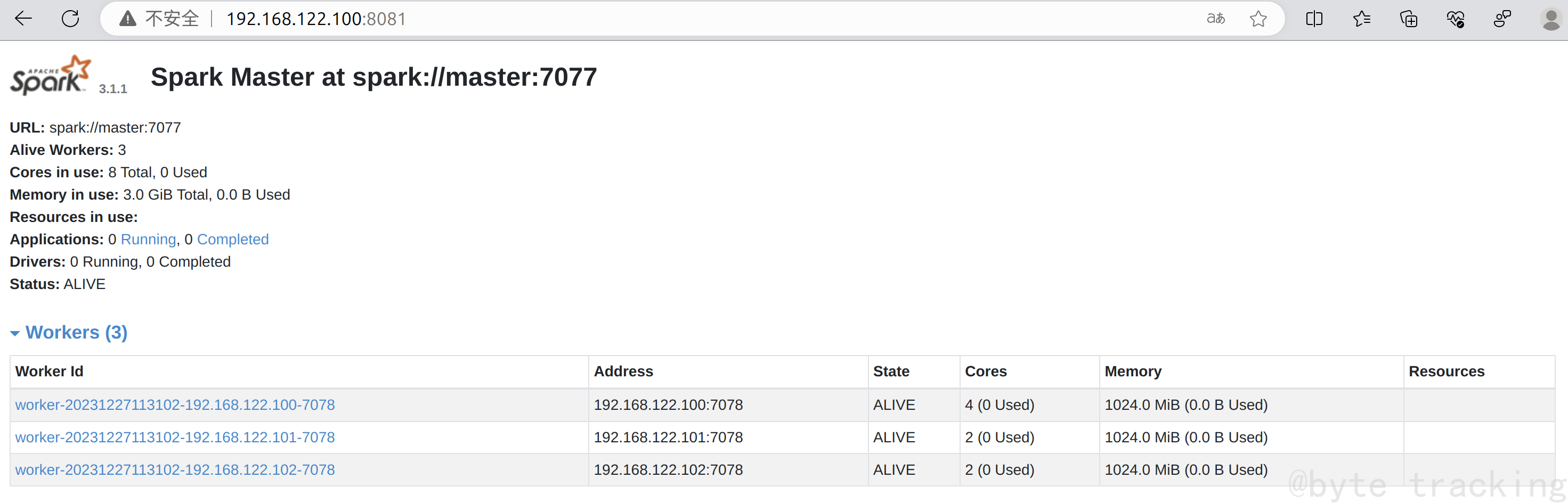
如图所示,一个master,三个worker:

访问 http://192.168.122.100:8080/ 界面,查看一下,如图所示:
测试是否可以读取hive数据
进入spark shell:
spark-shell
查看数据库:
spark.sql("SHOW DATABASES").show
如图所示:

然后我们再开一个master节点,启动hive:
hive
在Hive CLI(hive命令行)创建一个数据库:
CREATE DATABASE test;
此时我们切换另一个master节点,在spark命令行中再次查询数据库:
spark.sql("SHOW DATABASES").show
如图所示,此时代表spark可以同步hive中的数据:

ctrl + d 退出spark-shell
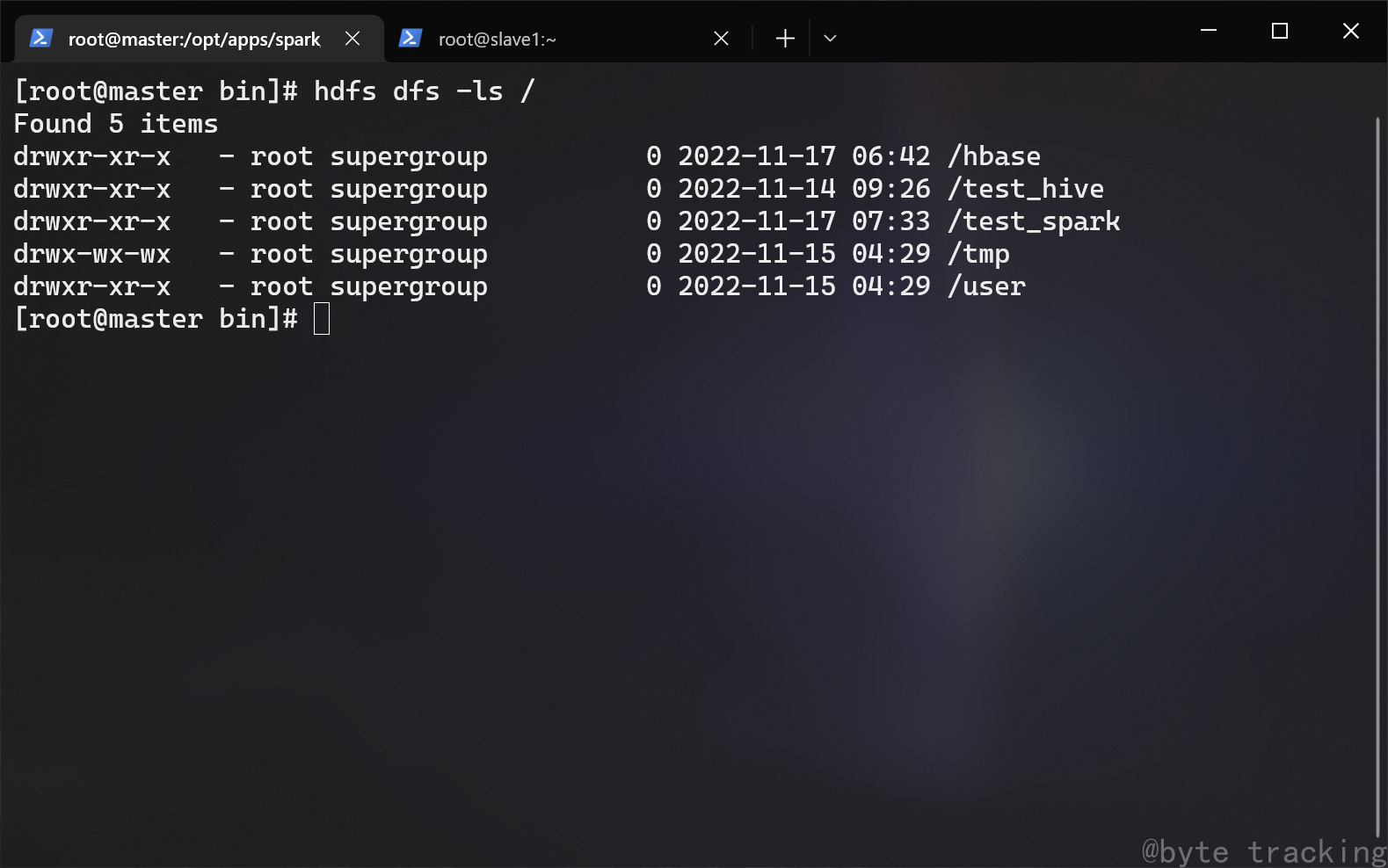
然后往 hdfs 内创建一个测试目录:
hdfs dfs -mkdir /test_spark
查看是否创建成功:
hdfs dfs -ls /
如图所示:
随便写一个测试文件:
vim ~/data.txt
将下面内容添加到文件中
lkh
wyy
wcx
jsy
如图所示:

发送到 hdfs 的 test_spark 目录内:
hdfs dfs -put ~/data.txt /test_spark/
查看一下是否发送成功:
hdfs dfs -cat /test_spark/data.txt
如图所示:

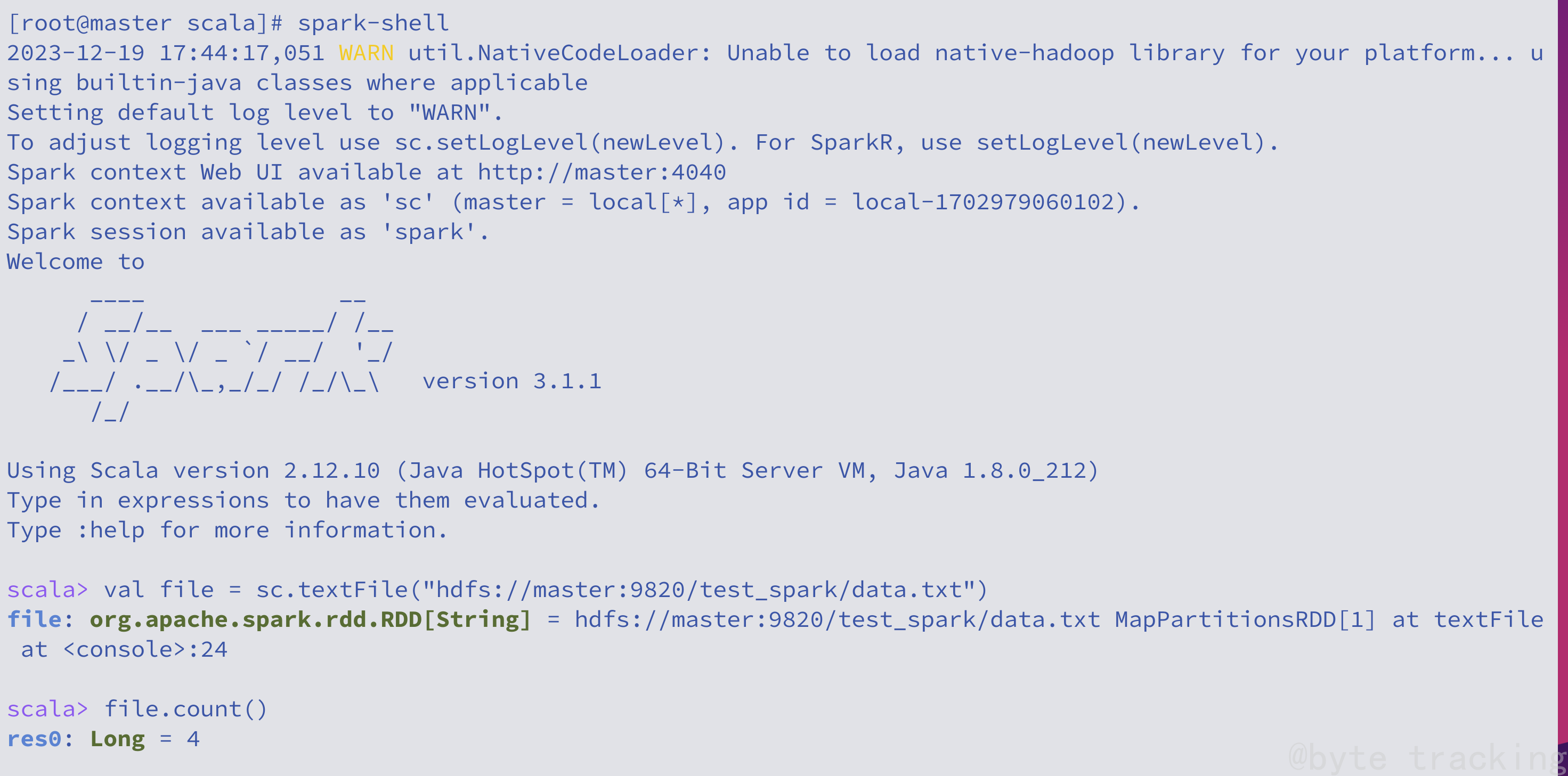
再次进入 spark shell :
spark-shell
统计 hdfs 内的 /test_spark/data.txt 有多少行:
// 读取文件
val file = sc.textFile("hdfs://master:9820/test_spark/data.txt")
// 获取行数
file.count()
如图所示:
ctrl + d退出 spark-shell
七、Spark On Yarn 集群部署
Scala & Spark集群部署与Spark On Yarn集群部署 根据个人需求二选一即可
介绍
-
Spark是一种快速、通用、可扩展的大数据分析引擎,于2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。
-
Spark是基于内存计算的大数据并行计算框架。除了扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。Spark适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理。
-
Spark on YARN 是生产环境中最主流的 Spark 运行模式(没有之一),核心特点围绕 “资源统一调度、集群复用、稳定可靠、适配大规模场景” 展开,本质是将 Spark 的计算能力与 YARN 的资源管理能力深度结合,既保留 Spark 快速计算的优势,又继承 YARN 成熟的集群管理特性。
前提条件
- spark-3.1.1-bin-hadoop3.2.tgz(位于/opt/softwares/ 下)
- mysql-connector-java-8.0.16.jar (位于 /opt/softwares/ 下)
- Hadoop 集群已经启动
- 分布式部署
1.解压文件
以下内容在 master 节点上操作
进入目录:
cd /opt/module
解压 spark 到当前目录:
tar -zxvf /opt/softwares/spark-3.1.1-bin-hadoop3.2.tgz
重命名 spark :
mv spark-3.1.1-bin-hadoop3.2/ spark-yarn
2.配置环境变量
以下内容在 master 节点上操作
编辑环境变量:
env-edit
在文件末尾添加:
#SPARK_HOME
export SPARK_HOME=/opt/module/spark-yarn
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
生效环境变量:
env-update
3.配置 yarn-site.xml
编辑文件:
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
新增内容如下:
<!--关闭物理内存检测-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--关闭虚拟内存检测-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
4.分发文件
以下内容在 master 节点上操作
分发yarn-site.xml到 slave1、slave2 :
#slave1
scp -r $HADOOP_HOME/etc/hadoop/yarn-site.xml slave1:$HADOOP_HOME/etc/hadoop/
#slave2
scp -r $HADOOP_HOME/etc/hadoop/yarn-site.xml slave2:$HADOOP_HOME/etc/hadoop/
5.配置 spark-env.sh
以下内容在 master 节点上操作
进入配置目录:
cd $SPARK_HOME/conf
使用预置模板:
cp ./spark-env.sh.template ./spark-env.sh
编辑它:
vim ./spark-env.sh
在末尾添加这些:
export JAVA_HOME=/opt/module/jdk
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop
6.重启 Hadoop 集群测试
以下内容在 master 节点上操作
重启集群:
# 停止集群
stop-all.sh
#启动集群
start-all.sh
进入目录:
cd /opt/module/spark-yarn/sbin
启动命令:
./start-all.sh
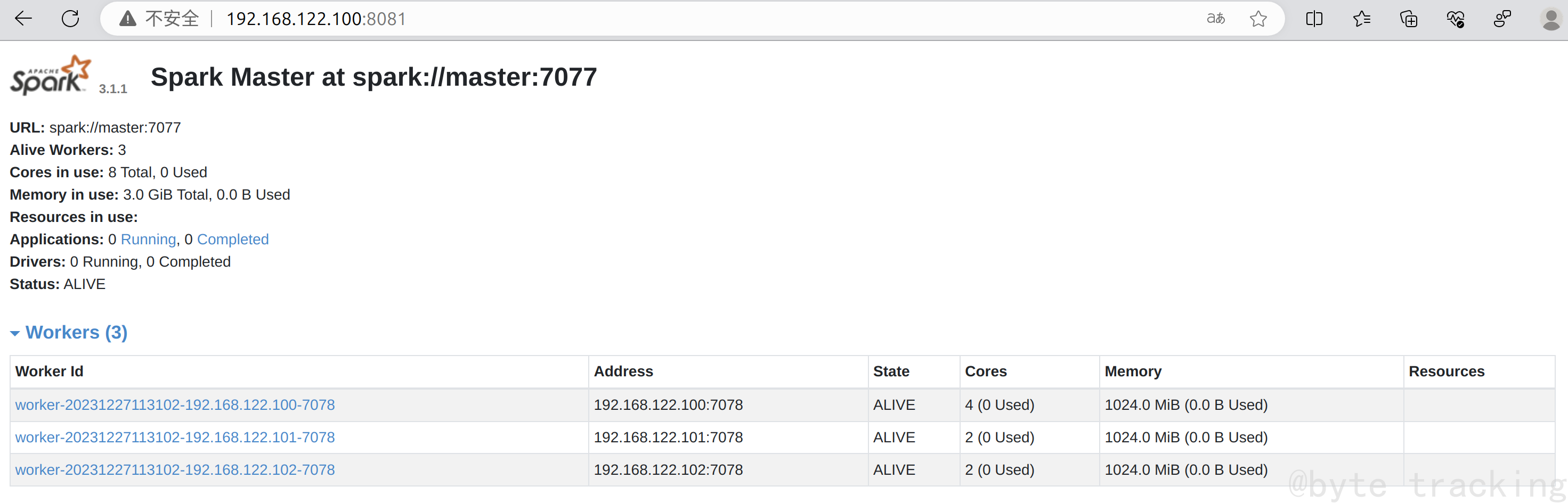
如图所示,一个master,一个worker:

访问 http://192.168.122.100:8081/ 界面,查看一下,如图所示:
进入目录:
cd /opt/module/spark-yarn
运行 jar 包测试
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client $SPARK_HOME/examples/jars/spark-examples_2.12-3.1.1.jar 10
–deploy-mode 指定工作模式
- client 模式:在这种模式下,Driver 程序(Spark 应用程序的入口点)运行在提交作业的客户端机器上 (会将Pi的输出结果打印在控制台)
- cluster 模式:在这种模式下,Driver 程序运行在集群中的一个 Worker 节点上,而不是在提交作业的客户端机器上。(通过yarn查看)
输出可见屏幕上有 Pi 的运行结果:

八、Clickhouse 数据库部署
以下内容全部在 master 节点上操作
介绍
-
ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的列式存储数据库(DBMS),使用 C++语言编写,主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告。
-
ClickHouse 将数据划分为多个 partition,每个 partition 再进一步划分为多个 indexgranularity(索引粒度),然后通过多个 CPU核心分别处理其中的一部分来实现并行数据处理。在这种设计下,单条 Query 就能利用整机所有 CPU。极致的并行处理能力,极大的降低了查询延时。
-
所以,ClickHouse 即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端就是对于单条查询使用多 cpu,就不利于同时并发多条查询。所以对于高 qps 的查询业务,ClickHouse 并不是强项。
前提条件
- clickhouse-client-21.9.4.35.tgz (位于/opt/softwares/ 下)
- clickhouse-common-static-21.9.4.35.tgz (位于/opt/softwares/ 下)
- clickhouse-common-static-dbg-21.9.4.35.tgz (位于/opt/softwares/ 下)
- clickhouse-server-21.9.4.35.tgz (位于/opt/softwares/ 下)
- 非分布式部署
1.解压文件
进入目录:
cd /opt/module
创建 clickhouse 目录并进入:
mkdir clickhouse && cd clickhouse
依次将这四个安装包解压,并且每解压一个,执行一下解压文件夹下的install下的doinst.sh
#解压
tar -zxvf /opt/softwares/clickhouse-common-static-21.9.4.35.tgz
#运行doinst.sh
./clickhouse-common-static-21.9.4.35/install/doinst.sh
tar -zxvf /opt/softwares/clickhouse-common-static-dbg-21.9.4.35.tgz
./clickhouse-common-static-dbg-21.9.4.35/install/doinst.sh
tar -zxvf /opt/softwares/clickhouse-server-21.9.4.35.tgz
#运行下面脚本时会让设置默认密码,直接回车即可,不设置密码
./clickhouse-server-21.9.4.35/install/doinst.sh
tar -zxvf /opt/softwares/clickhouse-client-21.9.4.35.tgz
./clickhouse-client-21.9.4.35/install/doinst.sh
一些配置信息:
- /etc/clickhouse-server clickhouse服务的配置文件目录,包括:config.xml和users.xml
- /etc/clickhouse-client clickhouse客户端的配置文件目录,里面只有一个config.xml并且默认为空
- /var/lib/clickhouse: clickhouse默认数据目录
- /var/log/clickhouse-server: clickhouse默认日志目录
- /etc/init.d/clickhouse-server: clickhouse启动shell脚本,用来方便启动服务的
- /etc/security/limits.d/clickhouse.conf 最大文件打开数的配置,这个在config.xml也可以配置
- /etc/cron.d/clickhouse-server: clickhouse定时任务配置,默认没有任务,但是如果文件不存在启动会报错.
- /usr/bin clickhouse编译好的可执行文件目录,主要有下面几个:
- clickhouse: clickhouse主程序可执行文件
- clickhouse-compressor:
- clickhouse-client: 是一个软链指向clickhouse,主要是客户端连接操作使用
- clickhouse-server: 是一个软链接指向clickhouse,主要是服务操作使用
2.修改配置文件
编辑文件:
vim /etc/clickhouse-server/config.xml
配置clickhouse可以被远程ip访问,进入文件时输入 /:: 进行搜索
将下面内容的注释打开,保存的时候 wq! 强制执行
修改后如图:

3.启动clickhouse
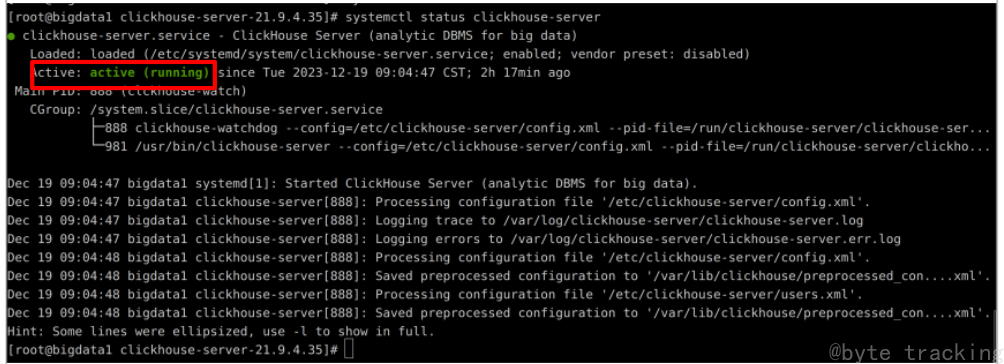
systemctl start clickhouse-server
查看进程状态:
systemctl status clickhouse-server
如图所示:
测试是否可以进行远程连接
浏览器访问 http://192.168.122.100:8123/ ,如图所示:

4.登录clickhouse
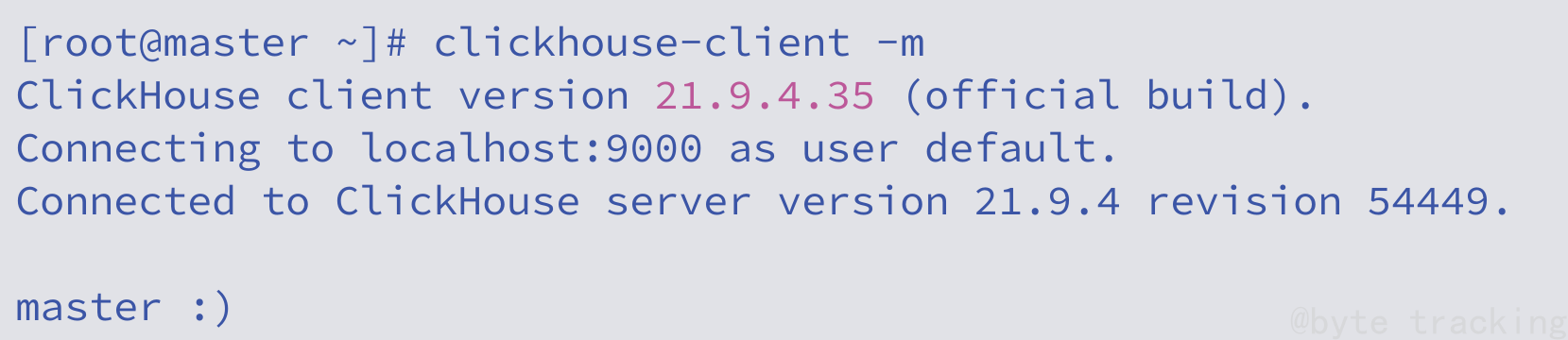
进入clickhouse命令行:
- 命令选项参数
- -m 可以在clickhouse命令中输入多行命令
- -h 指定连接主机 (默认为本地连接)
- –port 指定连接端口 (默认9000端口)
clickhouse-client -m -h IP地址 --port 端口号
默认写法:
clickhouse-client -m
如图所示:
5.关闭开机自启
生产环境下不要关闭。根据个人需求选择是否关闭,关闭后每次开机启动clickhouse都需要执行
systemctl start clickhouse-server 这条命令
关闭开机自启动:
systemctl disable clickhouse-server
九、Hudi 组件部署
以下内容全部在 master 节点上操作
介绍
Hudi简介
- Apache Hudi(Hadoop Upserts Delete and Incremental)是下一代流数据湖平台。ApacheHudi 将核心仓库和数据库功能直接引入数据湖。Hudi 提供了表、事务、高效的 upserts/delete、高级索引、流摄取服务、数据集群/压缩优化和并发,同时保持数据的开源文件格式。Apache Hudi 不仅非常适合于流工作负载,而且还允许创建高效的增量批处理管道。Apache Hudi 可以轻松地在任何云存储平台上使用。Hudi 的高级性能优化,使分析工作负载更快的任何流行的查询引擎,包括 Apache Spark、Flink、Presto、Trino、Hive 等。
Hudi发展历史
- 2015 年:发表了增量处理的核心思想/原则(O’reilly 文章)。
- 2016 年:由 Uber 创建并为所有数据库/关键业务提供支持。
- 2017 年:由 Uber 开源,并支撑 100PB 数据湖。
- 2018 年:吸引大量使用者,并因云计算普及。
- 2019 年:成为 ASF 孵化项目,并增加更多平台组件。
- 2020 年:毕业成为 Apache 顶级项目,社区、下载量、采用率增长超过 10 倍。
- 2021 年:支持 Uber 500PB 数据湖,SQL DML、Flink 集成、索引、元服务器、缓存
Hudi特性
- 可插拔索引机制支持快速 Upsert/Delete。
- 支持增量拉取表变更以进行处理。
- 支持事务提交及回滚,并发控制。
- 支持 Spark、Presto、Trino、Hive、Flink 等引擎的 SQL 读写。
- 自动管理小文件,数据聚簇,压缩,清理。
- 流式摄入,内置 CDC 源和工具。
- 内置可扩展存储访问的元数据跟踪
前提条件
- apache-maven-3.6.3-bin.tar.gz(位于/opt/softwares/hudi/ 下)
- hudi-0.12.0.src.tgz(位于/opt/softwares/hudi/ 下)
- common-config-5.3.4.jar (位于/opt/softwares/hudi/ 下)
- common-utils-5.3.4.jar (位于/opt/softwares/hudi/ 下)
- kafka-avro-serializer-5.3.4.jar (位于/opt/softwares/hudi/ 下)
- kafka-schema-registry-client-5.3.4.jar (位于/opt/softwares/hudi/ 下)
- 非分布式部署
1.解压文件
进入目录:
cd /opt/module
解压文件:
# 解压maven
tar -zxvf /opt/softwares/hudi/apache-maven-3.6.3-bin.tar.gz
#解压hudi
tar -zxvf /opt/softwares/hudi/hudi-0.12.0.src.tgz
重命名:
mv apache-maven-3.6.3/ maven
mv hudi-0.12.0/ hudi
2.配置环境变量
编辑环境变量:
env-edit
在文件末尾添加:
#MAVEN_HOME
export MAVEN_HOME=/opt/module/maven
export PATH=$PATH:$MAVEN_HOME/bin
生效环境变量:
env-update
测试一下安装结果:
mvn -v
如图所示:

3.Maven修改为阿里镜像
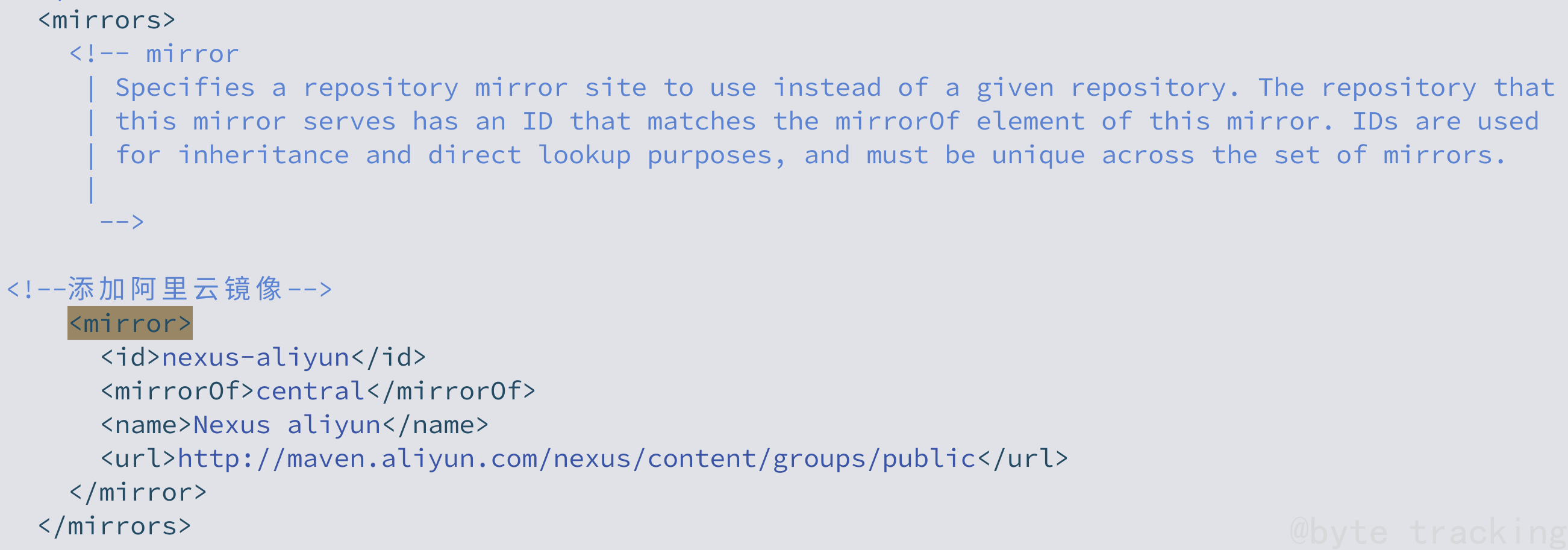
修改setting.xml,指定为阿里仓库地址:
vim /opt/module/maven/conf/settings.xml
输入/mirrorId ,进行搜索定位,然后取消注释并修改
修改如下:
<!-- 添加阿里云镜像-->
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
修改后如图所示:
4.修改Hudi配置
修改pom文件:
vim /opt/module/hudi/pom.xml
输入/repositories ,进行搜索定位,在此标签内新增下载加速依赖:
<!-- 下载加速依赖 -->
<repository>
<id>nexus-aliyun</id>
<name>nexus-aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
修改后如图所示:

修改依赖的组件版本
输入/<hadoop.version,进行搜索定位
修改为:
<hadoop.version>3.1.3</hadoop.version>
<hive.version>3.1.2</hive.version>
修改后如图所示:

Hudi 默认依赖的 hadoop2,要兼容 hadoop3,除了修改版本,还需要修改源码兼容 Hadoop3.x:
vim /opt/module/hudi/hudi-common/src/main/java/org/apache/hudi/common/table/log/block/HoodieParquetDataBlock.java
修改第110行,原先只有一个参数,添加第二个参数null:
# 在命令行输入以下命令,定位到110行
:110
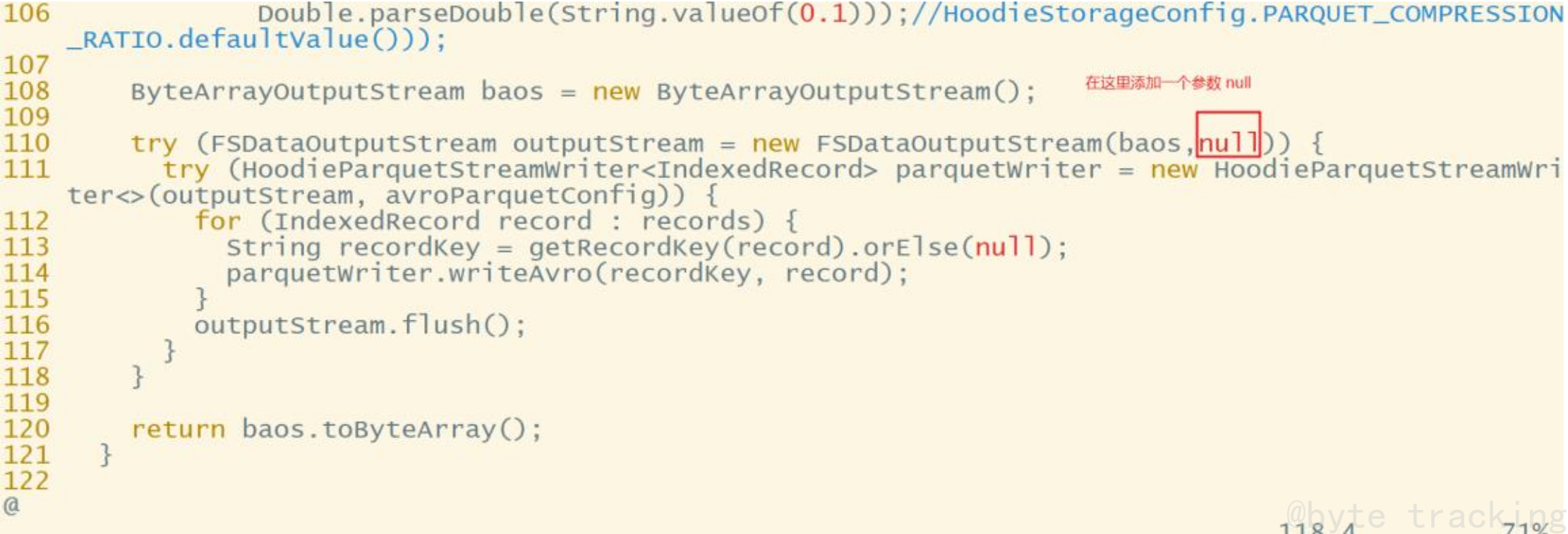
否则会因为 hadoop2.x 和 3.x 版本兼容问题,报错如下:

5.手动安装Kafka依赖
有几个 kafka 的依赖需要手动安装,否则编译报错如下:

进入到 /opt/softwares/hudi 目录中:
cd /opt/softwares/hudi
分别运行以下命令,install 到 maven 本地仓库:
# common-config-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=common-config -Dversion=5.3.4 -Dpackaging=jar -Dfile=./common-config-5.3.4.jar
# common-utils-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=common-utils -Dversion=5.3.4 -Dpackaging=jar -Dfile=./common-utils-5.3.4.jar
# kafka-avro-serializer-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-avro-serializer -Dversion=5.3.4 -Dpackaging=jar -Dfile=./kafka-avro-serializer-5.3.4.jar
# kafka-schema-registry-client-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-schema-registry-client -Dversion=5.3.4 -Dpackaging=jar -Dfile=./kafka-schema-registry-client-5.3.4.jar
6.解决 spark 模块依赖冲突
解决 hudi 本身用的 0.9.4,而 Hive 版本为 3.1.2,其携带的 jetty 是 0.9.3,存在的依赖冲突。
修改 hudi-spark-bundle的pom文件。排除低版本jetty,添加hudi指定版本的jetty:
vim /opt/module/hudi/packaging/hudi-spark-bundle/pom.xml
输入 /Hive 进行定位,修改后如下:
<!-- Hive -->
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-service</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<artifactId>servlet-api</artifactId>
<groupId>javax.servlet</groupId>
</exclusion>
<!-------------------新增部分:--------------------->
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>*</artifactId>
</exclusion>
<!-------------------------------------------->
</exclusions>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-service-rpc</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
<!----------------------新增部分:-------------------->
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
<!--------------------------------------------------->
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-metastore</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-common</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
<!----------------新增部分:------------------>
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty.orbit</groupId>
<artifactId>javax.servlet</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
<!------------------------------------------>
</dependency>
<!-----------------新增部分:------------------->
<!--增加hudi配置版本的jetty-->
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-server</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-util</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-webapp</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-http</artifactId>
<version>${jetty.version}</version>
</dependency>
<!---------------------------------------------->
否则在使用 spark 向 hudi 表插入数据时,会报错如下:
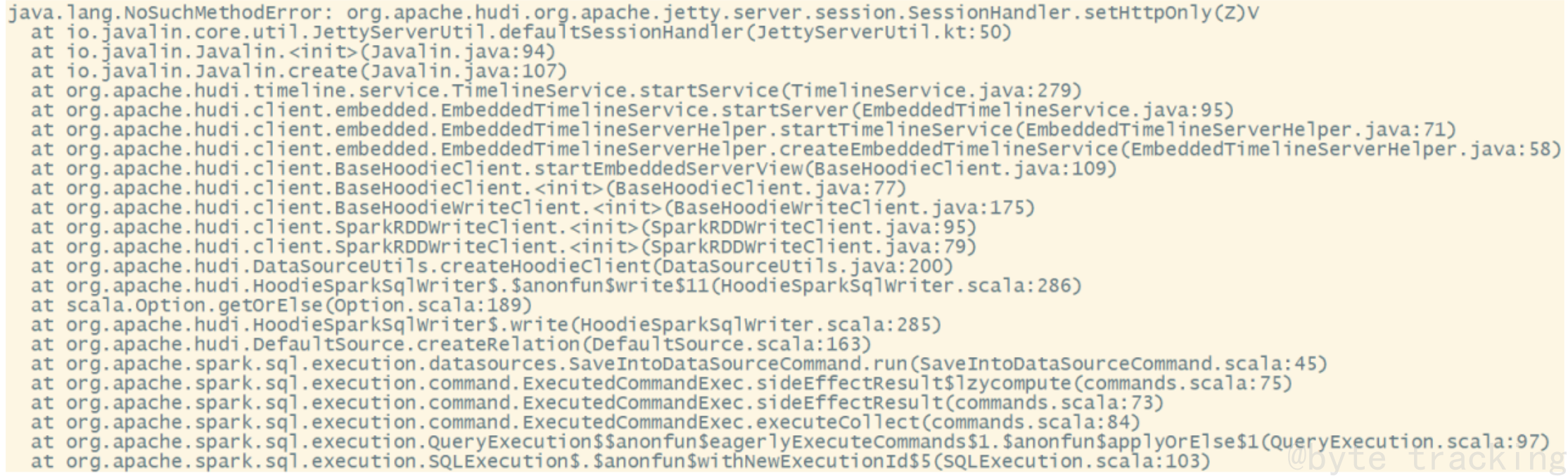
修改 hudi-utilities-bundle 的 pom 文件,排除低版本 jetty ,添加 hudi 指定版本的 jetty:
vim /opt/module/hudi/packaging/hudi-utilities-bundle/pom.xml
输入 /Hoodie 进行定位,修改后如下:
<!-- Hoodie -->
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-common</artifactId>
<version>${project.version}</version>
<!------------------新增部分:--------------------->
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
<!---------------------------------------------->
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-client-common</artifactId>
<version>${project.version}</version>
<!------------------新增部分:--------------------->
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
<!----------------------------------------------->
</dependency>
<!--退出编辑模式输入 /Hive 进行定位-->
<!-- Hive -->
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-service</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
<!------------------新增部分:--------------------->
<exclusions>
<exclusion>
<artifactId>servlet-api</artifactId>
<groupId>javax.servlet</groupId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
<!------------------------------------------------>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-service-rpc</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
<!------------------新增部分:--------------------->
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
<!------------------------------------------------->
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-metastore</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
<!------------------新增部分:--------------------->
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.datanucleus</groupId>
<artifactId>datanucleus-core</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
</exclusions>
<!--------------------------------------------->
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-common</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
<!------------------新增部分:--------------------->
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty.orbit</groupId>
<artifactId>javax.servlet</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
<!------------------------------------------------->
</dependency>
<dependency>
<groupId>org.apache.htrace</groupId>
<artifactId>htrace-core</artifactId>
<version>${htrace.version}</version>
<scope>compile</scope>
</dependency>
<!-- 增加 hudi 配置版本的 jetty -->
<!------------------新增部分:--------------------->
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-server</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-util</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-webapp</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-http</artifactId>
<version>${jetty.version}</version>
</dependency>
<!------------------------------------------------>
否则在使用 DeltaStreamer 工具向 hudi 表插入数据时,也会报 Jetty 的错误。
7.执行编译命令
进入 /opt/module/hudi 目录下:
cd /opt/module/hudi
执行编译:
mvn clean package -DskipTests -Dspark3.1 -Dflink1.14 -Dscala-2.12 -Dhadoop.version=3.1.3 -Pflink-bundle-shade-hive3
可能得编译几个小时。。。慢慢等吧,摸鱼时间 (dog) 手动狗头
8.编译成功
确保在 /opt/module/hudi 目录下,进入 hudi 客户端:
hudi-cli/hudi-cli.sh
编译后,进入 hudi-cli 说明成功:
按 ctrl + d 退出 hudi 客户端,然后执行以下命令,进入packaging目录
cd /opt/module/hudi/packaging
编译完成后,相关的包在 packaging 目录的各个模块中:

此时我们将 hudi 编译的 spark 的相关 jar 包放到 spark 的 jars 目录下
进入编译后的 spark 目录:
cd hudi-spark-bundle/target/
拷贝相关 jar 包放到 spark 的对应目录下
cp hudi-spark3.1-bundle_2.12-0.12.0.jar /opt/module/spark/jars/
发送hudi的jar包到从节点,让其都可以操作数据
#slave1
scp hudi-spark3.1-bundle_2.12-0.12.0.jar slave1:/opt/module/spark/jars/
#slave2
scp hudi-spark3.1-bundle_2.12-0.12.0.jar slave1:/opt/module/spark/jars/
拷贝相关 jar 包放到 hive 的 lib 目录下
进入编译好的 hadoop 目录下:
cd hudi-hadoop-mr-bundle/target/
拷贝文件:
cp hudi-hadoop-mr-bundle-0.12.0.jar /opt/module/hive/lib/
进入编译号的 hive目录
cd hudi-hive-sync-bundle/target
拷贝文件:
cp hudi-hive-sync-bundle-0.12.0.jar /opt/module/hive/lib/
启动 spark-shell ,复制 spark 3.1 启动项即可:
#spark-shell 命令:
#针对 Spark 3.2
spark-shell \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalo
g.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessio
nExtension'
#针对 Spark 3.1
spark-shell \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.legacy.parquet.datetimeRebaseModeInRead=LEGACY' \
--conf 'spark.sql.legacy.avro.datetimeRebaseModeInWrite=LEGACY'
#------------------------------------------------------------------------
#spark-sql 命令:
#针对 Spark 3.2
spark-sql \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalo
g.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessio
nExtension'
#针对 Spark 3.1
spark-sql \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.legacy.parquet.datetimeRebaseModeInRead=LEGACY' \
--conf 'spark.sql.legacy.avro.datetimeRebaseModeInWrite=LEGACY'
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessio
nExtension' \
命令解释:
-
spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension : 在启动 Spark 作业时,为其注册了 Hudi 的 Spark SQL 扩展,从而使得 Spark 可以与 Hudi 集成并利用其提供的功能
-
spark.serializer=org.apache.spark.serializer.KryoSerializer : 是 Apache Spark 中的一个配置选项,用于指定序列化/反序列化对象时使用的序列化器,插入数据的时候必须加这个选项,否则会报序列化问题
-
spark.sql.legacy.parquet.datetimeRebaseModeInRead=LEGACY : 是为了使用 Spark 的旧版本行为来处理日期和时间字段,而不是使用新版本的 Parquet 标准。
-
spark.sql.legacy.avro.datetimeRebaseModeInWrite=LEGACY : 这个配置选项是用来控制当写入 Avro 文件时,Spark 会使用旧的方式来处理日期和时间字段,而不是使用新版本的 Avro 标准。
9.测试案例
启动完成后运行下面的案例:
创建数据库
spark.sql("create database spark_hudi")
使用数据库
spark.sql("use spark_hudi")
复制以下代码来设置表名,基本路径和数据生成器。不需要单独建表,如果表不存在,第一批写表将创建该表。
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips_cow"
val basePath = "hdfs://master:9820/user/hive/warehouse/spark_hudi.db/hudi_trips_cow"
val dataGen = new DataGenerator
复制以下代码新增数据,生成一些数据,将其加载到 DataFrame 中,然后将 DataFrame 写入 Hudi 表:
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts,
2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts"). //预聚合字段,去重,类似版本
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)
复制以下代码将其转换成 DF :
val tripsSnapshotDF = spark.read.
format("hudi").
load(basePath)
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
查询:
spark.sql(" select fare,begin_lon,begin_lat,ts from hudi_trips_snapshot where fare > 20.0").show()
如图所示:

查询:
spark.sql("select _hoodie_commit_time,_hoodie_record_key,_hoodie_partition_path,rider,driver,fare from hudi_trips_snapshot").show()
如图所示:

十、Azkaban 集群部署
介绍
-
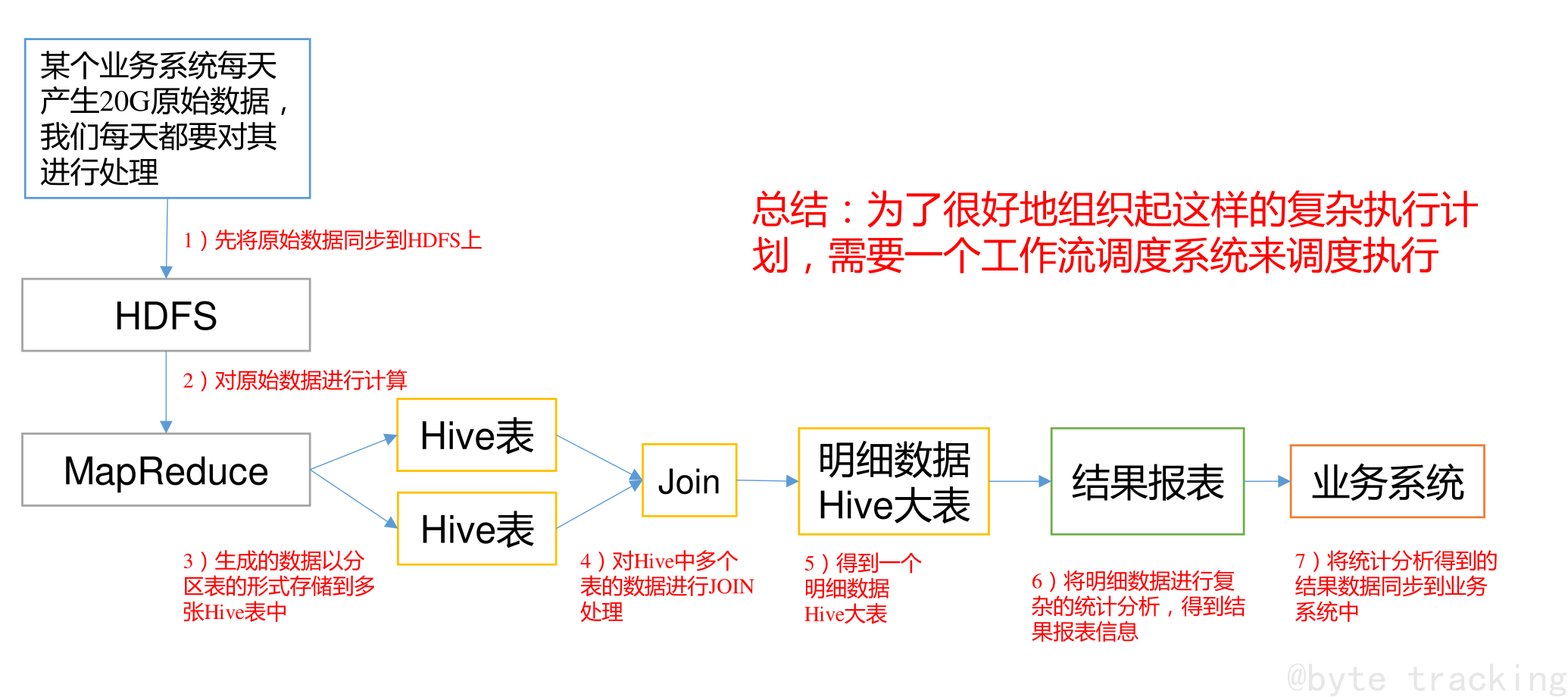
一个完整的数据分析系统通常都是由大量任务单元组成:Shell 脚本程序,Java 程序,MapReduce 程序、Hive 脚本等
-
各任务单元之间存在时间先后及前后依赖关系
-
为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行;
前提条件
- azkaban-db-3.84.4.tar.gz(位于/opt/softwares/azkaban/ 下)
- azkaban-exec-server-3.84.4.tar.gz(位于/opt/softwares/azkaban/ 下)
- azkaban-web-server-3.84.4.tar.gz (位于/opt/softwares/azkaban/ 下)
- Mysql部署完成
- 分布式部署
1.解压文件
以下内容在 master 节点上操作
新建目录并进入:
mkdir /opt/module/azkaban && cd /opt/module/azkaban
#为两个从节点创建文件夹
ssh slave1 mkdir /opt/module/azkaban
ssh slave2 mkdir /opt/module/azkaban
解压文件:
#azkaban-db-3.84.4.tar.gz
tar -zxvf /opt/softwares/azkaban/azkaban-db-3.84.4.tar.gz
#azkaban-exec-server-3.84.4.tar.gz
tar -zxvf /opt/softwares/azkaban/azkaban-exec-server-3.84.4.tar.gz
#azkaban-web-server-3.84.4.tar.gz
tar -zxvf /opt/softwares/azkaban/azkaban-web-server-3.84.4.tar.gz
重命名:
mv azkaban-exec-server-3.84.4/ azkaban-exec
mv azkaban-web-server-3.84.4/ azkaban-web
2.配置 MySQL
以下内容在 master 节点上操作
启动 MySQL (启动时直接指定用户和密码) :
mysql -uroot -p123456
创建 Azkaban 数据库 (用于存放元数据):
CREATE DATABASE azkaban;
创建 azkaban 用户并赋予权限:
# 设置密码有效长度4位及以上
SET GLOBAL VALIDATE_PASSWORD_LENGTH=4;
# 设置密码策略最低级别
SET GLOBAL VALIDATE_PASSWORD_POLICY=0;
# 创建 Azkaban 用户,任何主机都可以访问,密码设为 123456
CREATE USER 'azkaban'@'%' IDENTIFIED BY '123456';
# 赋予 Azkaban 用户增删改查权限
GRANT SELECT,INSERT,UPDATE,DELETE ON azkaban.* to 'azkaban'@'%' WITH GRANT OPTION;
初始化元数据:
# 使用数据库
USE azkaban;
# 添加相关表(元数据信息)
SOURCE /opt/module/azkaban/azkaban-db-3.84.4/create-all-sql-3.84.4.sql;
完成后 ctrl + d 退出 MySQL
更改 MySQL 包大小;防止 Azkaban 连接 MySQL 阻塞:
vim /etc/my.cnf
在第四行左右的 [mysqld] 下面添加如下内容:
max_allowed_packet=1024M
修改后如图:

重启 MySQL:
systemctl restart mysqld
3.配置 Executor Server
以下内容在 master 节点上操作
Azkaban Executor Server 处理工作流和作业的实际执行。
编辑 azkaban.properties:
vim /opt/module/azkaban/azkaban-exec/conf/azkaban.properties
修改以下属性,修改后为:
default.timezone.id=Asia/Shanghai
<!--修改端口号,避免与spark冲突-->
jetty.port=8082
<!--修改web端口号,避免与spark冲突-->
azkaban.webserver.url=http://master:8082
mysql.host=master
mysql.password=123456
<!--下面这个属性需要自己增加,另起一行加到哪里都可以-->
executor.port=12321
4.分发文件
以下内容在 master 节点上操作
同步 azkaban-exec 到从节点:
scp -r /opt/module/azkaban/azkaban-exec/ slave1:/opt/module/azkaban/
scp -r /opt/module/azkaban/azkaban-exec/ slave2:/opt/module/azkaban/
5.启动并激活
以下内容在三个节点上分别操作
三台节点都进入 /opt/module/azkaban/azkaban-exec 目录下,并启动 executorserver:
#三个节点分别运行
cd /opt/module/azkaban/azkaban-exec && bin/start-exec.sh
任选一台主机查看一下目录,如果在 /opt/module/azkaban/azkaban-exec 目录下出现 executor.port 文件,说明启动成功:
ls
激活 executor发送get请求:
#以下内容可以分别运行,也可以只在master节点运行
#上面已经进入到相对应的目录了,所以直接启动
curl -G "master:12321/executor?action=activate" && echo
curl -G "slave1:12321/executor?action=activate" && echo
curl -G "slave2:12321/executor?action=activate" && echo
如果出现以下提示,则表示激活成功:
{"status":"success"}
6.配置 Web Server
以下内容在 master 节点上操作
- Azkaban Web Server 用于处理项目管理,身份验证,计划和执行触发。
编辑 azkaban.properties:
vim /opt/module/azkaban/azkaban-web/conf/azkaban.properties
修改以下属性,修改后为:
default.timezone.id=Asia/Shanghai
<!--修改web端口号,避免与spark进行冲突-->
jetty.port=8082
mysql.host=master
mysql.password=123456
<!--多个executor情况下,判断选哪个执行任务-->
azkaban.executorselector.filters=StaticRemainingFlowSize,CpuStatus
说明:
- StaticRemainingFlowSize:正在排队的任务数;
- CpuStatus:CPU 占用情况
- MinimumFreeMemory:内存占用情况。测试环境,必须将 MinimumFreeMemory 删除掉,否则它会认为集群资源不够,不执行。
修改 azkaban-users.xml 文件:
vim /opt/module/azkaban/azkaban-web/conf/azkaban-users.xml
添加用户 (密码和用户名随意,roles 必须为 admin):
<!--最后的标签一定要加 / 否则,web 进程无法启动-->
<user password="你的密码" roles="admin" username="你的用户名"/>
添加后如图所示:

进入到 master 的 /opt/module/azkaban/azkaban-web 路径,启动 web server:
cd /opt/module/azkaban/azkaban-web/ && bin/start-web.sh
7.测试连接
访问 http://192.168.122.100:8082 并登陆你自己的用户
如图所示便为部署成功:
十一、DolphinScheduler 集群部署
此组件部署引用于千锋教育的部署文档
介绍
关于DolphinScheduler
-
Apache DolphinScheduler 是一个分布式易扩展的可视化DAG工作流任务调度开源系统。适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。
-
Apache DolphinScheduler 旨在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种 OPS 编排中的关系。 解决数据研发ETL依赖错综复杂,无法监控任务健康状态的问题。 DolphinScheduler 以 DAG(Directed Acyclic Graph,DAG)流式方式组装任务,可以及时监控任务的执行状态,支持重试、指定节点恢复失败、暂停、恢复、终止任务等操作。
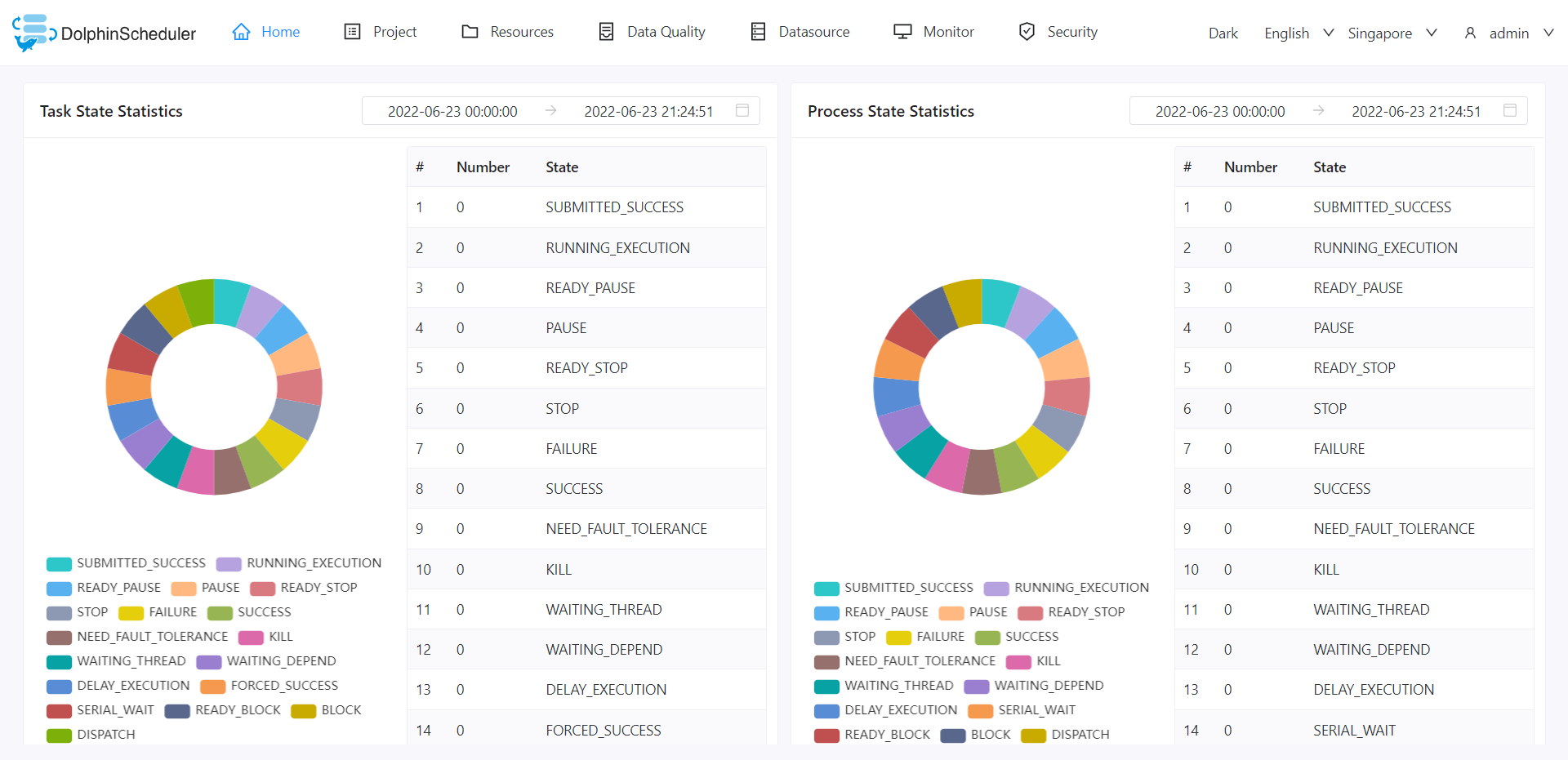
特性
-
简单易用
- 可视化 DAG: 用户友好的,通过拖拽定义工作流的,运行时控制工具
- 模块化操作: 模块化有助于轻松定制和维护。
-
丰富的使用场景
- 支持多种任务类型: 支持Shell、MR、Spark、SQL等10余种任务类型,支持跨语言,易于扩展
- 丰富的工作流操作: 工作流程可以定时、暂停、恢复和停止,便于维护和控制全局和本地参数。
-
High Reliability
- 高可靠性: 去中心化设计,确保稳定性。 原生 HA 任务队列支持,提供过载容错能力。 DolphinScheduler 能提供高度稳健的环境。
-
High Scalability
- 高扩展性: 支持多租户和在线资源管理。支持每天10万个数据任务的稳定运行。
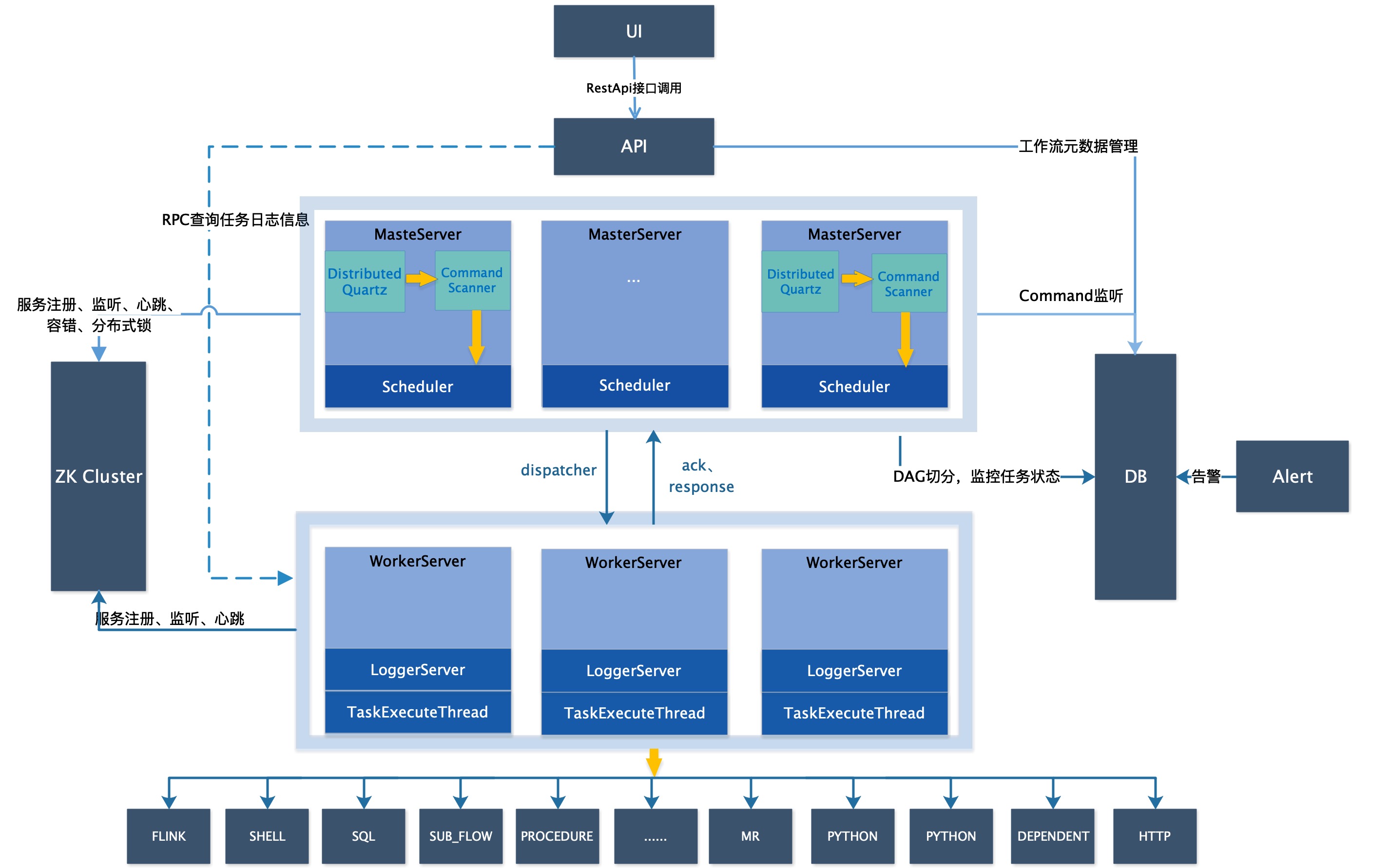
系统架构图
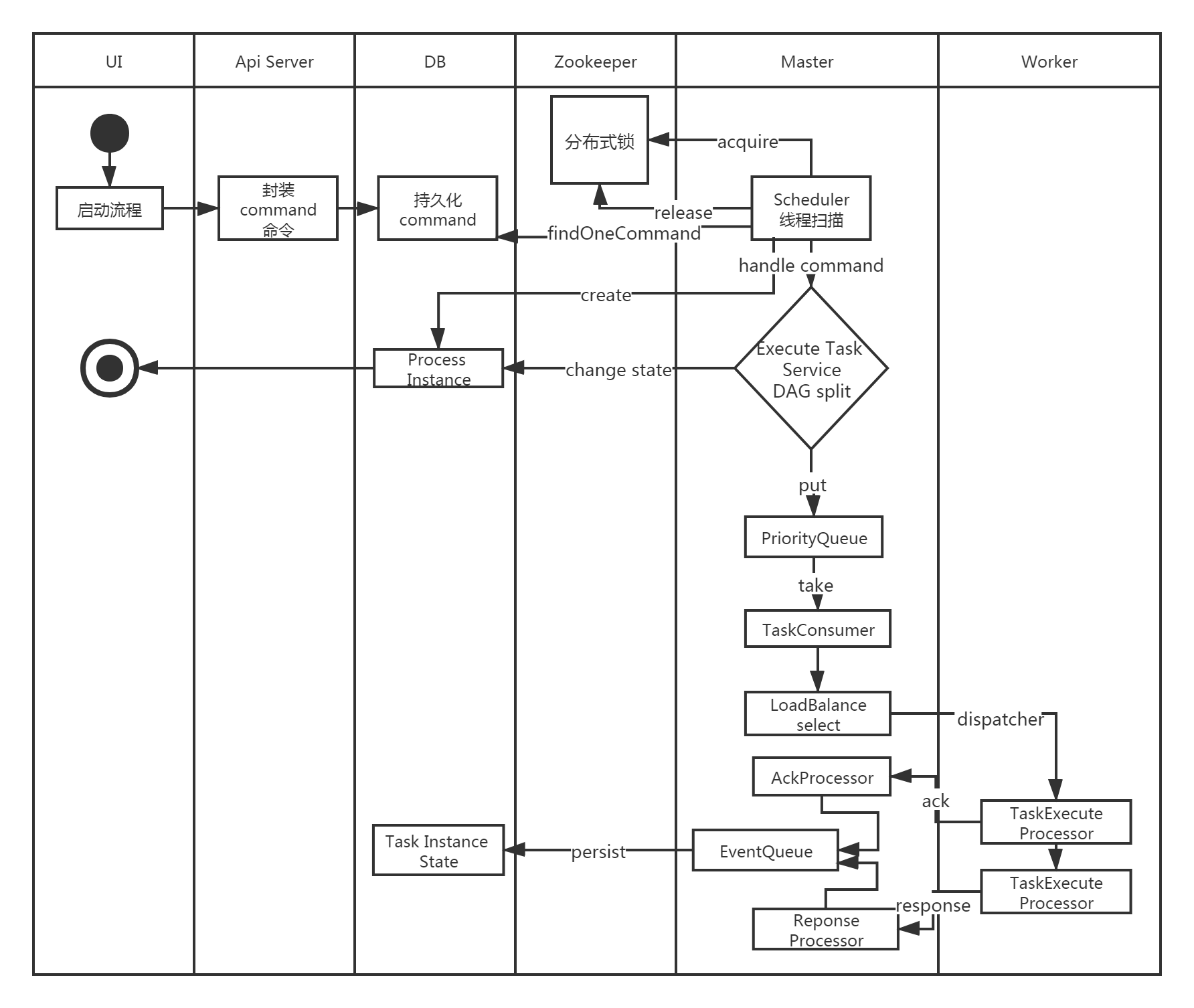
启动流程活动图
中心化思想
中心化的设计理念比较简单,分布式集群中的节点按照角色分工,大体上分为两种角色:
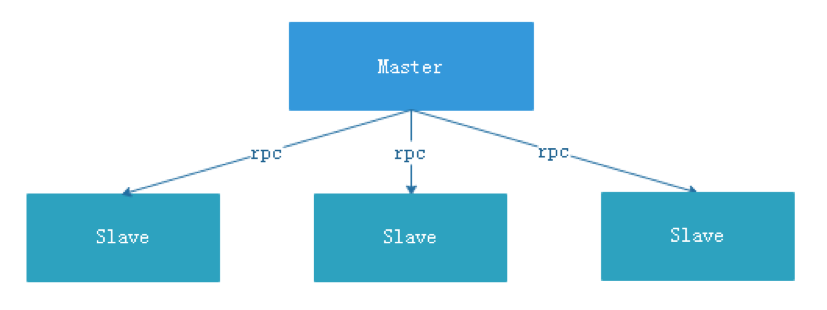
- Master的角色主要负责任务分发并监督Slave的健康状态,可以动态的将任务均衡到Slave上,以致Slave节点不至于“忙死”或”闲死”的状态。
- Worker的角色主要负责任务的执行工作并维护和Master的心跳,以便Master可以分配任务给Slave。
中心化思想设计存在的问题:
- 一旦Master出现了问题,则群龙无首,整个集群就会崩溃。为了解决这个问题,大多数Master/Slave架构模式都采用了主备Master的设计方案,可以是热备或者冷备,也可以是自动切换或手动切换,而且越来越多的新系统都开始具备自动选举切换Master的能力,以提升系统的可用性。
- 另外一个问题是如果Scheduler在Master上,虽然可以支持一个DAG中不同的任务运行在不同的机器上,但是会产生Master的过负载。如果Scheduler在Slave上,则一个DAG中所有的任务都只能在某一台机器上进行作业提交,则并行任务比较多的时候,Slave的压力可能会比较大。
去中心化
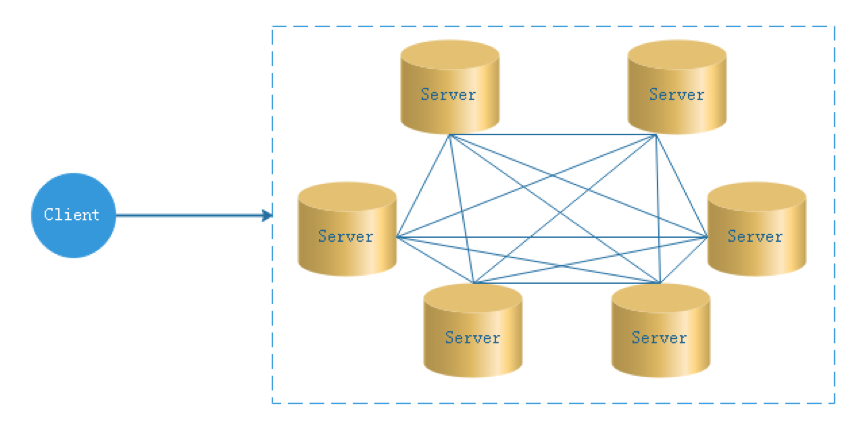
- 在去中心化设计里,通常没有Master/Slave的概念,所有的角色都是一样的,地位是平等的,全球互联网就是一个典型的去中心化的分布式系统,联网的任意节点设备down机,都只会影响很小范围的功能。
- 去中心化设计的核心设计在于整个分布式系统中不存在一个区别于其他节点的”管理者”,因此不存在单点故障问题。但由于不存在” 管理者”节点所以每个节点都需要跟其他节点通信才得到必须要的机器信息,而分布式系统通信的不可靠性,则大大增加了上述功能的实现难度。
- 实际上,真正去中心化的分布式系统并不多见。反而动态中心化分布式系统正在不断涌出。在这种架构下,集群中的管理者是被动态选择出来的,而不是预置的,并且集群在发生故障的时候,集群的节点会自发的举行"会议"来选举新的"管理者"去主持工作。最典型的案例就是ZooKeeper及Go语言实现的Etcd。
- DolphinScheduler的去中心化是Master/Worker注册到Zookeeper中,实现Master集群和Worker集群无中心,并使用Zookeeper分布式锁来选举其中的一台Master或Worker为“管理者”来执行任务。
还有很多设计思想,这里不再过多赘述
安装部署建议
1.软硬件环境配置建议
DolphinScheduler 作为一款开源分布式工作流任务调度系统,可以很好地部署和运行在 Intel 架构服务器及主流虚拟化环境下,并支持主流的Linux操作系统环境
2.Linux 操作系统版本要求
| 操作系统 | 版本 |
|---|---|
| Red Hat Enterprise Linux | 7.0 及以上 |
| CentOS | 7.0 及以上 |
| Oracle Enterprise Linux | 7.0 及以上 |
| Ubuntu LTS | 16.04 及以上 |
注意:
- 以上 Linux 操作系统可运行在物理服务器以及 VMware、KVM、XEN 主流虚拟化环境上
3.服务器建议配置
DolphinScheduler 支持运行在 Intel x86-64 架构的 64 位通用硬件服务器平台。对生产环境的服务器硬件配置有以下建议:
生产环境
| CPU | 内存 | 硬盘类型 | 网络 | 实例数量 |
|---|---|---|---|---|
| 4核+ | 8 GB+ | SAS | 千兆网卡 | 1+ |
注意:
- 以上建议配置为部署 DolphinScheduler 的最低配置,生产环境强烈推荐使用更高的配置
- 硬盘大小配置建议 50GB+ ,系统盘和数据盘分开
4.网络要求
DolphinScheduler正常运行提供如下的网络端口配置:
| 组件 | 默认端口 | 说明 |
|---|---|---|
| MasterServer | 5678 | 非通信端口,只需本机端口不冲突即可 |
| WorkerServer | 1234 | 非通信端口,只需本机端口不冲突即可 |
| ApiApplicationServer | 12345 | 提供后端通信端口 |
注意:
- MasterServer 和 WorkerServer 不需要开启网络间通信,只需本机端口不冲突即可
- 管理员可根据实际环境中 DolphinScheduler 组件部署方案,在网络侧和主机侧开放相关端口
5.安装部署介绍
DolphinScheduler提供了4种安装部署方式:
-
单机部署(Standalone):Standalone 仅适用于 DolphinScheduler 的快速体验。如果你是新手,想要体验 DolphinScheduler 的功能,推荐使用[Standalone]方式体检。
-
伪集群部署(Pseudo-Cluster):伪集群部署目的是在单台机器部署 DolphinScheduler 服务,该模式下 master、worker、api server 都在同一台机器上。如果你想体验更完整的功能,或者更大的任务量,推荐使用伪集群部署。
-
集群部署(Cluster):集群部署目的是在多台机器部署 DolphinScheduler 服务,用于运行大量任务情况。如果你是在生产中使用,推荐使用集群部署或者kubernetes。
-
Kubernetes 部署:Kubernetes部署目的是在Kubernetes集群中部署 DolphinScheduler 服务,能调度大量任务,可用于在生产中部署。
注意:
-
Standalone仅建议20个以下工作流使用,因为其采用内存式的H2 Database, Zookeeper Testing Server,任务过多可能导致不稳定,并且如果重启或者停止standalone-server会导致内存中数据库里的数据清空。 如果您要连接外部数据库,比如mysql或者postgresql。
-
Kubernetes部署先决条件:Helm3.1.0+ ;Kubernetes1.12+;PV 供应(需要基础设施支持)
集群设计
1.集群部署规划
集群模式下,可配置多个Master及多个Worker。通常可配置2~3个Master,若干个Worker。由于集群资源有限,此处配置一个Master,三个Worker,集群规划如下。
| 主机名 | ip | 服务 | 内存 | 备注 |
|---|---|---|---|---|
| master | 192.168.122.100 | master,worker | 8g | |
| slave1 | 192.168.122.101 | worker | 3g | 该服务器也可以安装master,资源有限只配一个master |
| slave2 | 192.168.122.102 | worker | 3g |
2.集群准备工作
-
操作系统:linux centos 7.0
-
部署版本:apache-dolphinscheduler-3.1.4-bin
-
JDK:配置Java环境,将JAVA_HOME配置于PATH中,推荐版本使用jdk8+
-
数据库:本文使用的是MySQL 5.7 版本,也可以使用5.7版本及以上,如 MySQL 则需要 JDBC Driver 8.0.16 ( 用5.1.37版本的会报错 )
-
注册中心:zookeeper(3.5.7)
-
其他大数据相关组件:Hadoop 3.1.3 、Hive 3.1.2 、Spark 3.1.1等
前提条件
- apache-dolphinscheduler-3.1.4-bin.tar.gz(位于 /opt/softwares/ 下)
- mysql-connector-java-8.0.16.jar (位于 /opt/softwares/ 下)
- Hadoop 和 Zookeeper 集群启动成功
- 需手动将master内存设置为8g,slave1和slave2最低为3g,否则会安装不成功
- 分布式部署
1.创建部署用户
以下内容在三台节点上分别操作
- 创建部署用户,并为该用户配置免登录,以创建 dolphinscheduler 用户为例:
# 三个节点分别创建用户
useradd dolphinscheduler
# 添加密码,实际生产环境中密码应为复杂一些
echo "123456" | passwd --stdin dolphinscheduler
# 配置sudo(系统管理命令)免密
sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers
sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers
注意:
-
因为任务执行服务是以
sudo -u {linux-user}切换不同 linux 用户的方式来实现多租户运行作业,所以部署用户需要有 sudo 权限,而且是免密的。初学习者不理解的话,完全可以暂时忽略这一点 -
如果发现
/etc/sudoers文件中有 “Defaults requirett” 这行,也请注释掉,一般情况下是没有的
配置机器SSH免密登陆
以下内容在master节点上操作
由于安装的时候需要向不同机器发送资源,所以要求各台机器间能实现SSH免密登陆。配置免密登陆的步骤如下:
# master节点配置免密,根据提示输入创建用户时的密码(123456)
su dolphinscheduler
ssh-keygen -t rsa
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
任选一台测试是否免密成功:
ssh slave1
如图所示:

按两次 ctrl + d 退出到当前root用户
2.启动相关集群
以下内容在master节点上操作
- 请确保 Hadoop 集群,Zookeeper 集群已经启动
启动 Hadoop集群命令,master节点运行:
start-all.sh
启动zookeeper集群,使用上文配置过相关脚本,进行启动,单节点启动方式这里不再赘述:
# 启动集群
zk.sh start
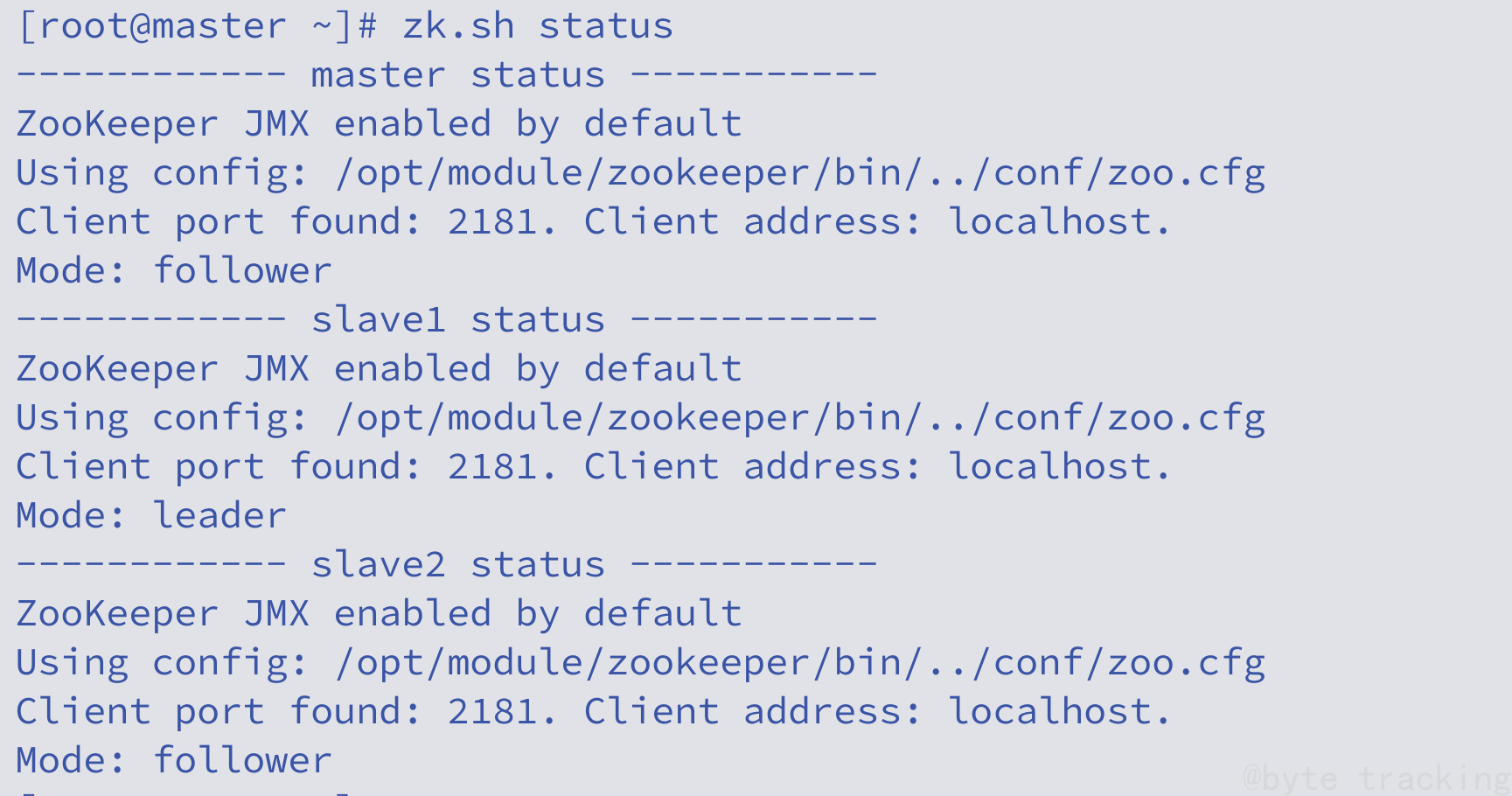
使用脚本命令查看一下状态,以防有节点没有启动起来
zk.sh status
如图所示:
3.初始化数据库
以下内容在master节点上操作
DolphinScheduler 元数据存储在关系型数据库中,目前支持 PostgreSQL 和 MySQL。下面介绍如何使用 MySQL 初始化数据库。
进入 Mysql:
# 进入MySQL命令行
mysql -uroot -p123456
创建数据库、用户和授权:
-- 创建dolphinscheduler的数据库用户和密码,并限定登陆范围
set global validate_password_policy=LOW;
set global validate_password_length=6;
CREATE USER 'dolphinscheduler'@'%' IDENTIFIED BY '123456';
-- 创建dolphinscheduler的元数据库,并指定编码
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
-- 为dolphinscheduler数据库授权
grant all privileges on dolphinscheduler.* to 'dolphinscheduler'@'%';
-- 刷新权限
flush privileges;
ctrl + d 退出 Mysql 客户端
4.解压文件
以下内容在master节点上操作
创建文件夹并进入:
mkdir /opt/module/dolphinscheduler && cd /opt/module/dolphinscheduler
解压文件到当前目录:
tar -zxvf /opt/softwares/apache-dolphinscheduler-3.1.4-bin.tar.gz
重命名文件:
mv apache-dolphinscheduler-3.1.4-bin/ dolphinscheduler-3.1.4-bin
修改目录权限,确保在当前文件夹下,使得部署用户对二进制包解压后的 dolphinscheduler-bin 目录有操作权限:
chown -R dolphinscheduler:dolphinscheduler dolphinscheduler-3.1.4-bin
5.添加MySQL驱动
以下内容在master节点上操作
将对应的mysql-connector-java驱动(5.1.37)移动到 DolphinScheduler 的每个模块的 libs 目录下,其中包括 api-server/libs 和 alert-server/libs 和 master-server/libs 和 worker-server/libs和tools/libs
# 复制mysql的驱动到对应libs目录中
# api-server/libs
cp /opt/softwares/mysql-connector-java-8.0.16.jar /opt/module/dolphinscheduler/dolphinscheduler-3.1.4-bin/api-server/libs/
# alert-server/libs
cp /opt/softwares/mysql-connector-java-8.0.16.jar /opt/module/dolphinscheduler/dolphinscheduler-3.1.4-bin/alert-server/libs/
# master-server/libs
cp /opt/softwares/mysql-connector-java-8.0.16.jar /opt/module/dolphinscheduler/dolphinscheduler-3.1.4-bin/master-server/libs/
# worker-server/libs
cp /opt/softwares/mysql-connector-java-8.0.16.jar /opt/module/dolphinscheduler/dolphinscheduler-3.1.4-bin/worker-server/libs/
# tools/libs
cp /opt/softwares/mysql-connector-java-8.0.16.jar /opt/module/dolphinscheduler/dolphinscheduler-3.1.4-bin/tools/libs/
6.修改配置文件
以下内容在master节点上操作
文件 ./bin/env/dolphinscheduler_env.sh 描述了下列配置:
- DolphinScheduler 的数据库配置,将username和password改成你在上一步中设置的用户名和密码
- 一些任务类型外部依赖路径或库文件,如
JAVA_HOME和SPARK_HOME都是在这里定义的 - 注册中心
zookeeper - 服务端相关配置,比如缓存,时区设置等
如果您不使用某些任务类型,您可以忽略任务外部依赖项,但您必须根据您的环境更改 JAVA_HOME、注册中心和数据库相关配置。
编辑文件,并修改内容:
vim /opt/module/dolphinscheduler/dolphinscheduler-3.1.4-bin/bin/env/dolphinscheduler_env.sh
修改后内容如下:
# JAVA_HOME, will use it to start DolphinScheduler server
# 改为自己的JDK路径
export JAVA_HOME=${JAVA_HOME:-/opt/module/jdk}
# Database related configuration, set database type, username and password
# MySQL数据库连接信息
export DATABASE=${DATABASE:-mysql}
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL="jdbc:mysql://master:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=false&allowPublicKeyRetrieval=true"
export SPRING_DATASOURCE_USERNAME=${SPRING_DATASOURCE_USERNAME:-"dolphinscheduler"}
export SPRING_DATASOURCE_PASSWORD=${SPRING_DATASOURCE_PASSWORD:-"123456"}
# DolphinScheduler server related configuration
# 不用修改
export SPRING_CACHE_TYPE=${SPRING_CACHE_TYPE:-none}
export SPRING_JACKSON_TIME_ZONE=${SPRING_JACKSON_TIME_ZONE:-UTC}
export MASTER_FETCH_COMMAND_NUM=${MASTER_FETCH_COMMAND_NUM:-10}
# Registry center configuration, determines the type and link of the registry center
# zookeeper集群信息
export REGISTRY_TYPE=${REGISTRY_TYPE:-zookeeper}
export REGISTRY_ZOOKEEPER_CONNECT_STRING=${REGISTRY_ZOOKEEPER_CONNECT_STRING:-master:2181,slave1:2181,slave2:2181}
# Tasks related configurations, need to change the configuration if you use the related tasks.
# 对已有可以正常配置,没有的保持默认即可,修改后如下
export HADOOP_HOME=${HADOOP_HOME:-/opt/module/hadoop}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/opt/module/hadoop/etc/hadoop}
export SPARK_HOME1=${SPARK_HOME1:-/opt/module/spark}
export SPARK_HOME2=${SPARK_HOME2:-/opt/module/spark}
export PYTHON_HOME=${PYTHON_HOME:-/opt/soft/python}
export HIVE_HOME=${HIVE_HOME:-/opt/module/hive}
export FLINK_HOME=${FLINK_HOME:-/opt/soft/flink}
export DATAX_HOME=${DATAX_HOME:-/opt/soft/datax}
export SEATUNNEL_HOME=${SEATUNNEL_HOME:-/opt/soft/seatunnel}
export CHUNJUN_HOME=${CHUNJUN_HOME:-/opt/soft/chunjun}
# 下面不用修改
export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$FLINK_HOME/bin:$DATAX_HOME/bin:$PATH
7.初始化元数据
以下内容在master节点上操作
进入目录:
cd /opt/module/dolphinscheduler/dolphinscheduler-3.1.4-bin/
执行一下命令初始化元数据:
sh ./tools/bin/upgrade-schema.sh
如图所示:
8.修改安装环境配置
以下内容在master节点上操作
完成基础环境和元数据库初始化的准备后,需要根据你的机器环境修改配置文件。配置文件可以在目录 bin/env 中找到,他们分别是 install_env.sh 和 dolphinscheduler_env.sh。
修改 install_env.sh 文件:
vim /opt/module/dolphinscheduler/dolphinscheduler-3.1.4-bin/bin/env/install_env.sh
文件 install_env.sh 描述了哪些机器将被安装 DolphinScheduler 以及每台机器对应安装哪些服务。您可以在路径 bin/env/install_env.sh 中找到此文件,可通过以下方式更改env变量,export <ENV_NAME>=,配置详情如下:
# ---------------------------------------------------------
# INSTALL MACHINE
# ---------------------------------------------------------
# A comma separated list of machine hostname or IP would be installed DolphinScheduler,
# including master, worker, api, alert. If you want to deploy in pseudo-distributed
# mode, just write a pseudo-distributed hostname
# Example for hostnames: ips="ds1,ds2,ds3,ds4,ds5", Example for IPs: ips="192.168.8.1,192.168.8.2,192.168.8.3,192.168.8.4,192.168.8.5"
ips=${ips:-"master,slave1,slave2"}
# Port of SSH protocol, default value is 22. For now we only support same port in all `ips` machine
# modify it if you use different ssh port
sshPort=${sshPort:-"22"}
# A comma separated list of machine hostname or IP would be installed Master server, it
# must be a subset of configuration `ips`.
# Example for hostnames: masters="ds1,ds2", Example for IPs: masters="192.168.8.1,192.168.8.2"
# masters可以是一台,也可以是多台,根据自己机器配置决定
masters=${masters:-"master"}
# A comma separated list of machine <hostname>:<workerGroup> or <IP>:<workerGroup>.All hostname or IP must be a
# subset of configuration `ips`, And workerGroup have default value as `default`, but we recommend you declare behind the hosts
# Example for hostnames: workers="ds1:default,ds2:default,ds3:default", Example for IPs: workers="192.168.8.1:default,192.168.8.2:default,192.168.8.3:default"
workers=${workers:-"master:default,slave1:default,slave2:default"}
# A comma separated list of machine hostname or IP would be installed Alert server, it
# must be a subset of configuration `ips`.
# Example for hostname: alertServer="ds3", Example for IP: alertServer="192.168.8.3"
alertServer=${alertServer:-"slave2"}
# A comma separated list of machine hostname or IP would be installed API server, it
# must be a subset of configuration `ips`.
# Example for hostname: apiServers="ds1", Example for IP: apiServers="192.168.8.1"
apiServers=${apiServers:-"master"}
# The directory to install DolphinScheduler for all machine we config above. It will automatically be created by `install.sh` script if not exists.
# Do not set this configuration same as the current path (pwd). Do not add quotes to it if you using related path.
#最终安装路径
installPath=${installPath:-"/opt/module/dolphinscheduler/dolphinscheduler-3.1.4"}
# The user to deploy DolphinScheduler for all machine we config above. For now user must create by yourself before running `install.sh`
# script. The user needs to have sudo privileges and permissions to operate hdfs. If hdfs is enabled than the root directory needs
# to be created by this user
deployUser=${deployUser:-"dolphinscheduler"}
# The root of zookeeper, for now DolphinScheduler default registry server is zookeeper.
zkRoot=${zkRoot:-"/dolphinscheduler"}
9.安装DolphinScheduler
以下内容在master节点上操作
使用上面创建的部署用户运行以下命令完成部署,部署后的运行日志将存放在 安装目录下的logs 文件夹内
确保在 /opt/module/dolphinscheduler/dolphinscheduler-3.1.4-bin 目录下,安装
sh ./bin/install.sh
注意:第一次部署的话,可能出现 5 次sh: bin/dolphinscheduler-daemon.sh: No such file or directory相关信息,为非重要信息直接忽略即可。
第一次安装后会自动启动所有服务的,如有服务问题或者后续需要启停。下面的操作脚本都在dolphinScheduler安装目录bin下。
命令如下:
# 一键停止集群所有服务
sh /opt/module/dolphinscheduler/dolphinscheduler-3.1.4/bin/stop-all.sh
# 一键开启集群所有服务
sh /opt/module/dolphinscheduler/dolphinscheduler-3.1.4/bin/start-all.sh
# 启停 Master
sh /opt/module/dolphinscheduler/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh stop master-server
sh /opt/module/dolphinscheduler/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh start master-server
# 启停 Worker
sh /opt/module/dolphinscheduler/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh start worker-server
sh /opt/module/dolphinscheduler/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh stop worker-server
# 启停 Api
sh /opt/module/dolphinscheduler/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh start api-server
sh /opt/module/dolphinscheduler/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh stop api-server
# 启停 Logger
sh /opt/module/dolphinscheduler/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh start logger-server
sh /opt/module/dolphinscheduler/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh stop logger-server
# 启停 Alert
sh /opt/module/dolphinscheduler/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh start alert-server
sh /opt/module/dolphinscheduler/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh stop alert-server
# 启停 Python Gateway
sh /opt/module/dolphinscheduler/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh start python-gateway-server
sh /opt/module/dolphinscheduler/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh stop python-gateway-server
注意:
- 每个服务在路径
<service>/conf/dolphinscheduler_env.sh中都有dolphinscheduler_env.sh文件,这是可以为微服务需求提供便利。意味着您可以基于不同的环境变量来启动各个服务,只需要在对应服务中配置<service>/conf/dolphinscheduler_env.sh然后通过<service>/bin/start.sh命令启动即可。但是如果您使用命令/bin/dolphinscheduler-daemon.sh start <service>启动服务器,它将会用文件bin/env/dolphinscheduler_env.sh覆盖<service>/conf/dolphinscheduler_env.sh然后启动服务,目的是为了减少用户修改配置的成本.
10.登录 DolphinScheduler
浏览器访问地址 http://192.168.122.100:12345/dolphinscheduler/ui 即可登录系统UI。默认的用户名和密码是 admin/dolphinscheduler123
登录如下图所示:
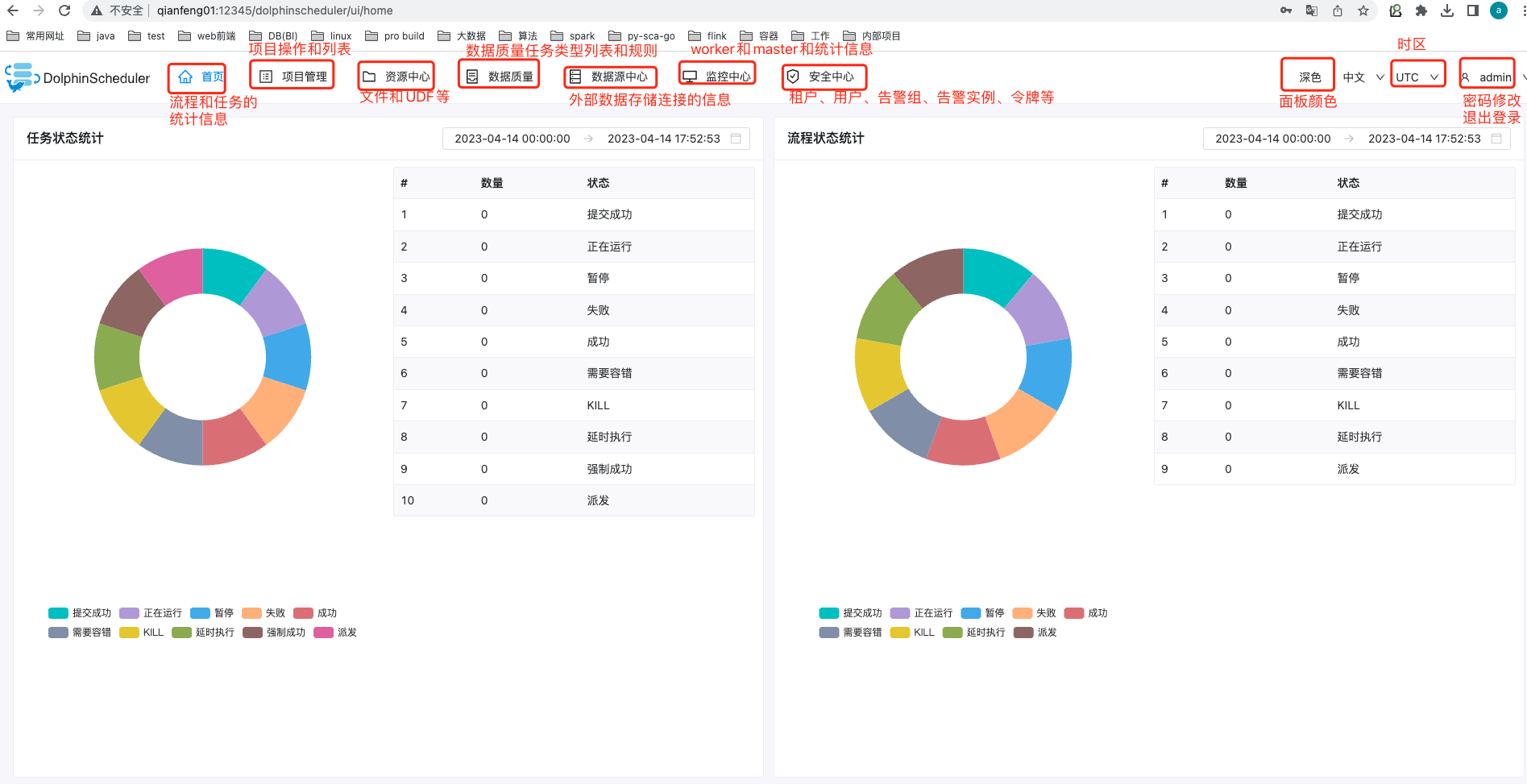
去监控中心查看Masters,如下图所示:
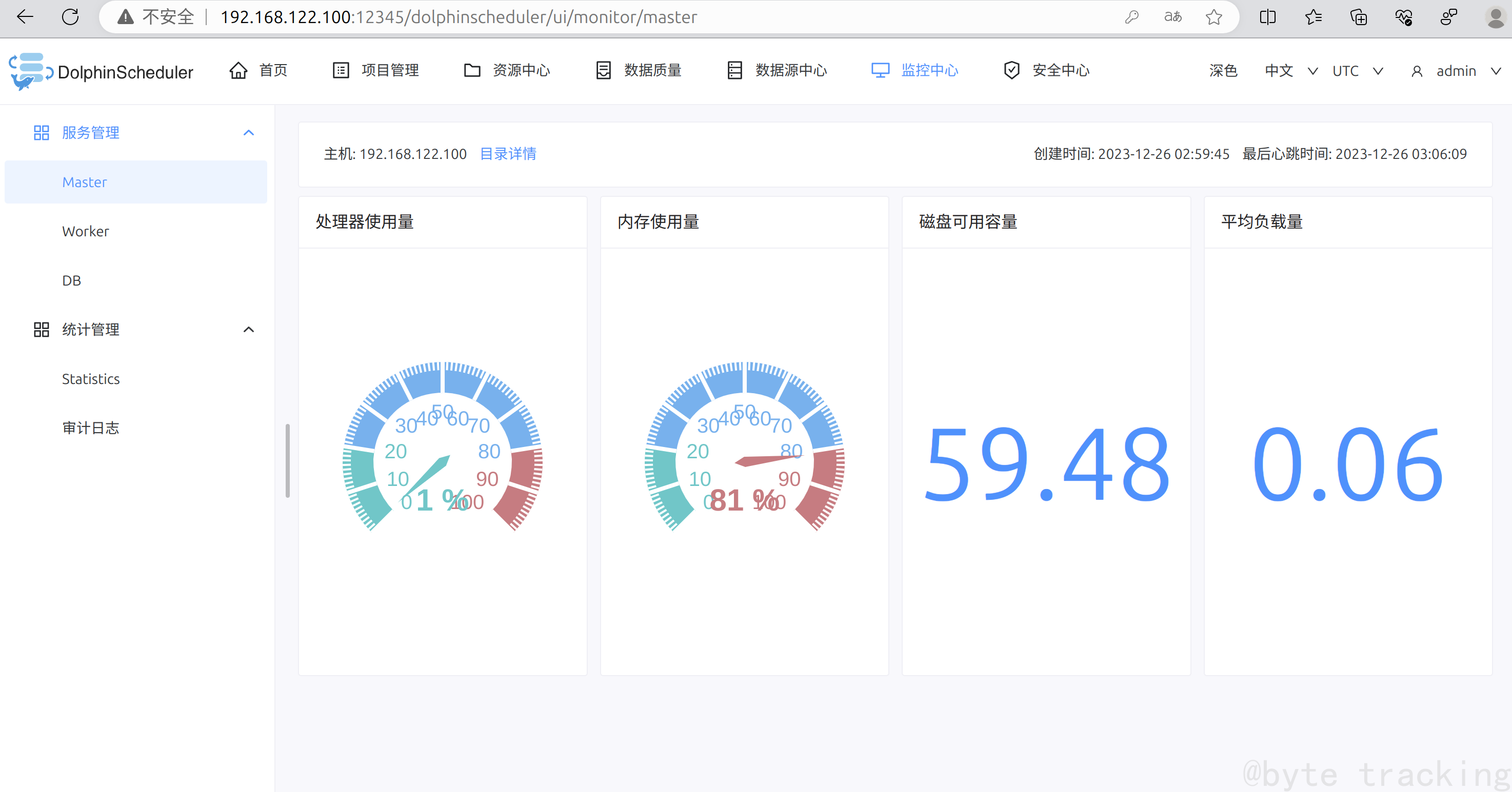
去监控中心查看workers,可见三个节点,如下图所示:
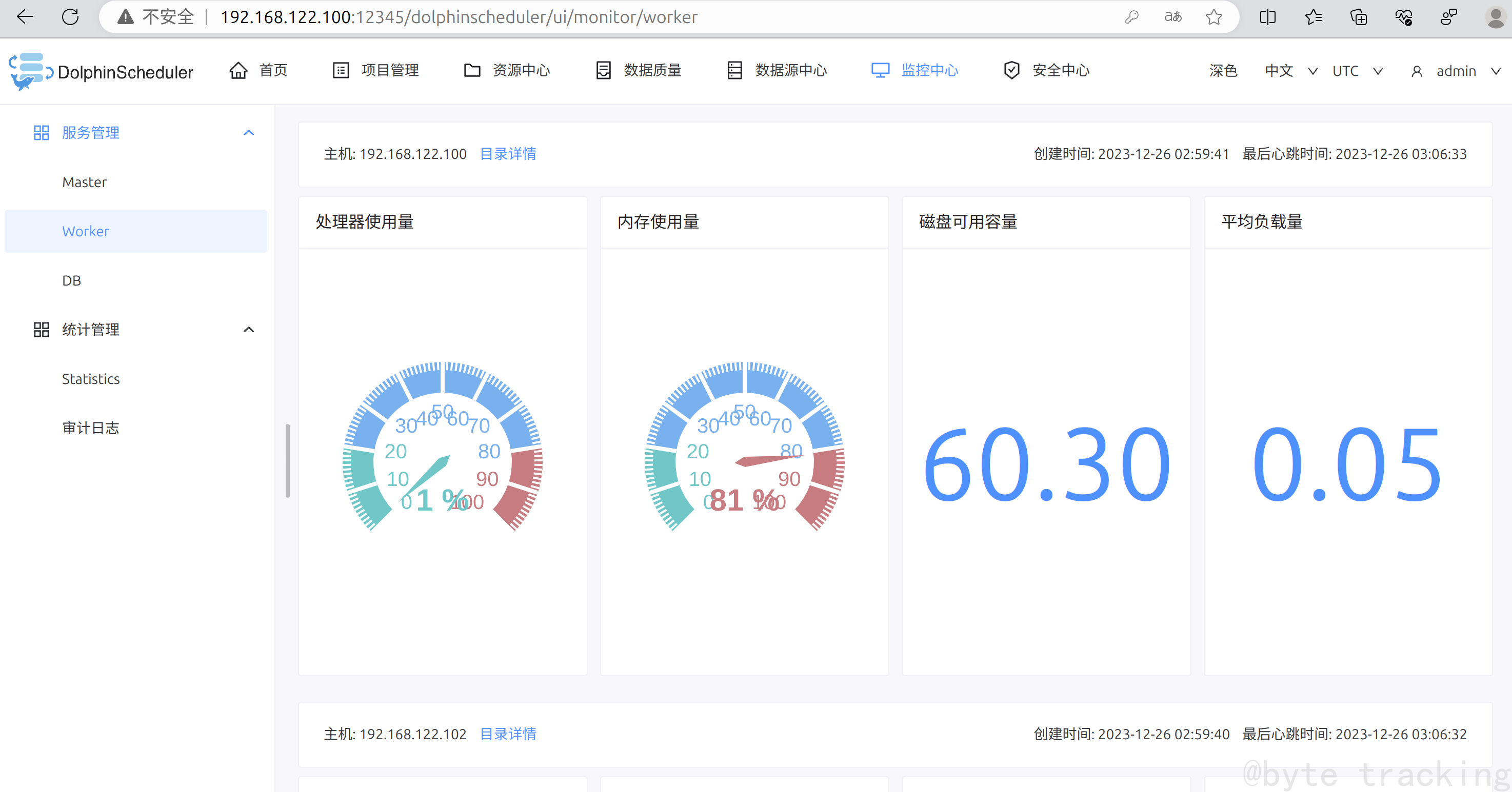
到此为止,DolphinScheduler 集群安装部署就完成了。
配置存储
以下内容在 master 节点上操作
1.资源中心简介
资源中心通常用于上传文件、UDF 函数和任务组管理。那资源上传到那儿呢?具体如下:
-
对于 Standalone 环境,可以选择本地文件目录作为上传文件夹(此操作不需要Hadoop部署)。
-
当然,你也可以 选择上传到 Hadoop 或者 S3 或者阿里云OSS 等。 在这种情况下,您需要有 Hadoop(2.6+)或等相关环境。
2.资源中心配置
-
如果您以
集群模式或者伪集群模式部署DolphinScheduler,需要对接分布式或远端存储并对以下路径的文件进行配置:api-server/conf/common.properties和worker-server/conf/common.properties; -
当需要使用资源中心进行相关文件的创建或者上传操作时,所有的文件和资源都会被存储在分布式文件系统
HDFS或者远端的对象存储。所以需要进行以下配置:
注意:
-
如果只配置了
api-server/conf/common.properties的文件,则只是开启了资源上传的操作,并不能满足正常使用。如果想要在工作流中执行相关文件则需要额外配置worker-server/conf/common.properties。 -
如果用到资源上传的功能,那么安装部署中,部署用户需要有这部分的操作权限。
进入目录:
cd /opt/module/dolphinscheduler/dolphinscheduler-3.1.4
分别编辑 common.properties 文件:
vim api-server/conf/common.properties
vim worker-server/conf/common.properties
均修改内容如下(出现的就是修改的,未出现的不要修改):
# user data local directory path, please make sure the directory exists and have read write permissions
data.basedir.path=/opt/module/dolphinscheduler/dolphinscheduler-3.1.4/data
# resource view suffixs
#resource.view.suffixs=txt,log,sh,bat,conf,cfg,py,java,sql,xml,hql,properties,json,yml,yaml,ini,js
# resource storage type: HDFS, S3, OSS, NONE
resource.storage.type=HDFS
# resource store on HDFS/S3 path, resource file will store to this base path, self configuration, please make sure the directory exists on hdfs and have read write permissions. "/dolphinscheduler" is recommended
resource.storage.upload.base.path=/dolphinscheduler
# if resource.storage.type=HDFS, the user must have the permission to create directories under the HDFS root path
resource.hdfs.root.user=root
# if resource.storage.type=S3, the value like: s3a://dolphinscheduler; if resource.storage.type=HDFS and namenode HA is enabled, you need to copy core-site.xml and hdfs-site.xml to conf dir
resource.hdfs.fs.defaultFS=hdfs://master:9820
# resourcemanager port, the default value is 8088 if not specified
resource.manager.httpaddress.port=8088
# if resourcemanager HA is enabled, please set the HA IPs; if resourcemanager is single, keep this value empty
yarn.resourcemanager.ha.rm.ids=
# if resourcemanager HA is enabled or not use resourcemanager, please keep the default value; If resourcemanager is single, you only need to replace ds1 to actual resourcemanager hostname
yarn.application.status.address=http://master:%s/ws/v1/cluster/apps/%s
# job history status url when application number threshold is reached(default 10000, maybe it was set to 1000)
yarn.job.history.status.address=http://master:19888/ws/v1/history/mapreduce/jobs/%s
将修改的文件分发到其它服务器:
# 分发./api-server/conf/common.properties
# slave1
scp ./api-server/conf/common.properties slave1:/opt/module/dolphinscheduler/dolphinscheduler-3.1.4/api-server/conf/
# slave2
scp ./api-server/conf/common.properties slave2:/opt/module/dolphinscheduler/dolphinscheduler-3.1.4/api-server/conf/
# 分发 ./worker-server/conf/common.properties
# slave1
scp ./worker-server/conf/common.properties slave1:/opt/module/dolphinscheduler/dolphinscheduler-3.1.4/worker-server/conf/
# slave2
scp ./worker-server/conf/common.properties slave2:/opt/module/dolphinscheduler/dolphinscheduler-3.1.4/worker-server/conf/
创建对应目录:
# master节点创建HDFS目录
hdfs dfs -mkdir /dolphinscheduler
在三个节点上分别创建目录
mkdir /opt/module/dolphinscheduler/dolphinscheduler-3.1.4/data
3.重启DolphinScheduler服务
以下内容在 master 节点上操作
#停止ds服务
sh /opt/module/dolphinscheduler/dolphinscheduler-3.1.4/bin/stop-all.sh
#启动ds服务
sh /opt/module/dolphinscheduler/dolphinscheduler-3.1.4/bin/start-all.sh
十二、Flume 组件部署
以下内容全部在 master 节点上运行
介绍
- Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输系统。Flume 基于流式架构,灵活简单。
Source 组件
- 负责接收数据到 Flume Agent 的组件。
Channel 组件
- Channel 是位于 Source 和 Sink 之间的缓冲区。Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适用。File Channel 将所有事件写到磁盘。
Sink 组件
- Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或 索引系统、或者被发送到另一个 Flume Agent。
注意
- Source 可以搭配多个 Channel;但一个 Sink 只能搭配一个 Channel。
前提条件
- apache-flume-1.9.0-bin.tar.gz(位于 /opt/softwares/ 下)
- Hadoop已经启动
- 非分布式部署
1.解压
进入 /opt/module/ 目录内:
cd /opt/module/
解压 apache-flume-1.9.0-bin.tar.gz 到当前目录:
tar -zxvf /opt/softwares/apache-flume-1.9.0-bin.tar.gz
重命名:
mv apache-flume-1.9.0-bin/ flume
2.配置环境变量
编辑环境变量:
env-edit
在文件末尾添加:
#FLUME_HOME
export FLUME_HOME=/opt/module/flume
export PATH=$PATH:$FLUME_HOME/bin
3.生效环境变量
env-update
测试如下:
flume-ng version
如图所示:

4.修改配置文件
进入配置文件目录:
cd $FLUME_HOME/conf
使用预置模板:
cp ./flume-env.sh.template ./flume-env.sh
编辑文件:
vim ./flume-env.sh
在文件末尾添加:
export JAVA_HOME=/opt/module/jdk
5.本地测试
监控指定目录,当目录有新的日志产生时,收集它。
创建用于测试的目录:
mkdir ~/flume_test
进入目录:
cd /opt/module/flume
创建并进入文件夹:
mkdir agent && cd agent
在 agent 目录内编写一个文件:
自定义文件名称不能有下划线
vim ./test.conf
内容如下:
# 其中 test 为任务名
# 自定义 Agent 的名称
test.sources = testSource
test.channels = testChannel
test.sinks = testSink
# 描述 Channel 组件属性
test.channels.testChannel.type = memory
# 描述 Source 组件属性
test.sources.testSource.channels = testChannel
test.sources.testSource.type = spooldir
test.sources.testSource.spoolDir = /root/flume_test
# 描述 Sink 组件属性
test.sinks.testSink.channel = testChannel
test.sinks.testSink.type = logger
启动 Flume Agent :
-n任务名-cflume 配置文件目录-f文件路径-Dflume.root.logger=INFO,console输出日志级别
flume-ng agent \
-n test \
-c /opt/module/flume/conf \
-f /opt/module/flume/agent/test.conf \
-Dflume.root.logger=INFO,console
启动后我们再开一台master,然后进入测试目录写一个日志:
在新开的master节点上运行
# 进入测试目录
cd ~/flume_test
# 随便写一个后缀为 log 的文件
echo "123" > data.log
查看测试目录变化:
ls ~/flume_test
如图所示:
在启动 Agent 的终端窗口可以看到刚刚采集的消息内容(不显示也没关系)。另外,对于 Spooling Directory 中的文件,其内容写入 Channel 后,该文件将会被标记并且增加 .COMPLETED 的后缀。
测试完成后将旧窗口的 master,ctrl + c 结束即可
6.hdfs 测试
监控指定目录,当目录有新的日志产生时,把日志保存到 hdfs。
- flume 与 hadoop 都使用到了 guava 库其中的一些功能,但是随着 guava 版本的更新,其中的一些代码与旧版本不可以互通,所以我们需要使 flume 与 hadoop 依赖的 guava 版本保持一致:
进入 flume 的 lib 目录:
cd /opt/module/flume/lib
删除 flume 中的 guava:
rm -rf guava-11.0.2.jar
从 hadoop 复制高版本的 guava 到 flume:
cp $HADOOP_HOME/share/hadoop/common/lib/guava-27.0-jre.jar $FLUME_HOME/lib/
创建用于测试的目录:
mkdir ~/flume_test_hdfs
在 agent 目录内写一个新的配置文件:
# 进入 agent 目录
cd /opt/module/flume/agent/
# 创建一个新的配置文件
vim ./test_hdfs.conf
内容如下:
# 其中 test_hdfs 为任务名
# 自定义 Agent 的名称
test_hdfs.sources = testHDFSSource
test_hdfs.channels = testHDFSChannel
test_hdfs.sinks = testHDFSSink
# 描述 Channel 组件属性
test_hdfs.channels.testHDFSChannel.type = memory
test_hdfs.channels.testHDFSChannel.capacity = 10000
test_hdfs.channels.testHDFSChannel.transactionCapacity = 100
# 描述 source 组件属性
test_hdfs.sources.testHDFSSource.channels = testHDFSChannel
test_hdfs.sources.testHDFSSource.type = spooldir
test_hdfs.sources.testHDFSSource.spoolDir = /root/flume_test_hdfs
# 定义拦截器并为消息添加时间戳
test_hdfs.sources.testHDFSSource.interceptors = i1
test_hdfs.sources.testHDFSSource.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
# 描述 Sink 组件属性
test_hdfs.sinks.testHDFSSink.channel = testHDFSChannel
test_hdfs.sinks.testHDFSSink.type = hdfs
test_hdfs.sinks.testHDFSSink.hdfs.path = hdfs://master:9820/flume_test_hdfs/%Y%m%d
test_hdfs.sinks.testHDFSSink.hdfs.filePrefix = events-
test_hdfs.sinks.testHDFSSink.hdfs.fileType = DataStream
# 不按照条数生成文件
test_hdfs.sinks.testHDFSSink.hdfs.rollCount = 0
# hdfs 上的临时文件达到 128mb 时生成一个 hdfs 文件
test_hdfs.sinks.testHDFSSink.hdfs.rollSize = 134217728
# 每隔 60 秒生成一个新的 hdfs 文件
test_hdfs.sinks.sink2.hdfs.rollInterval = 60
启动 flume agent:
flume-ng agent \
-n test_hdfs \
-c /opt/module/flume/conf \
-f /opt/module/flume/agent/test_hdfs.conf \
-Dflume.root.logger=INFO,console
进入测试目录写一个日志:
在新开的master节点上操作
# 进入测试目录
cd ~/flume_test_hdfs
# 随便写一个后缀为 log 的文件
echo "hello flume" > data.log
# 查看
ls
如图所示:
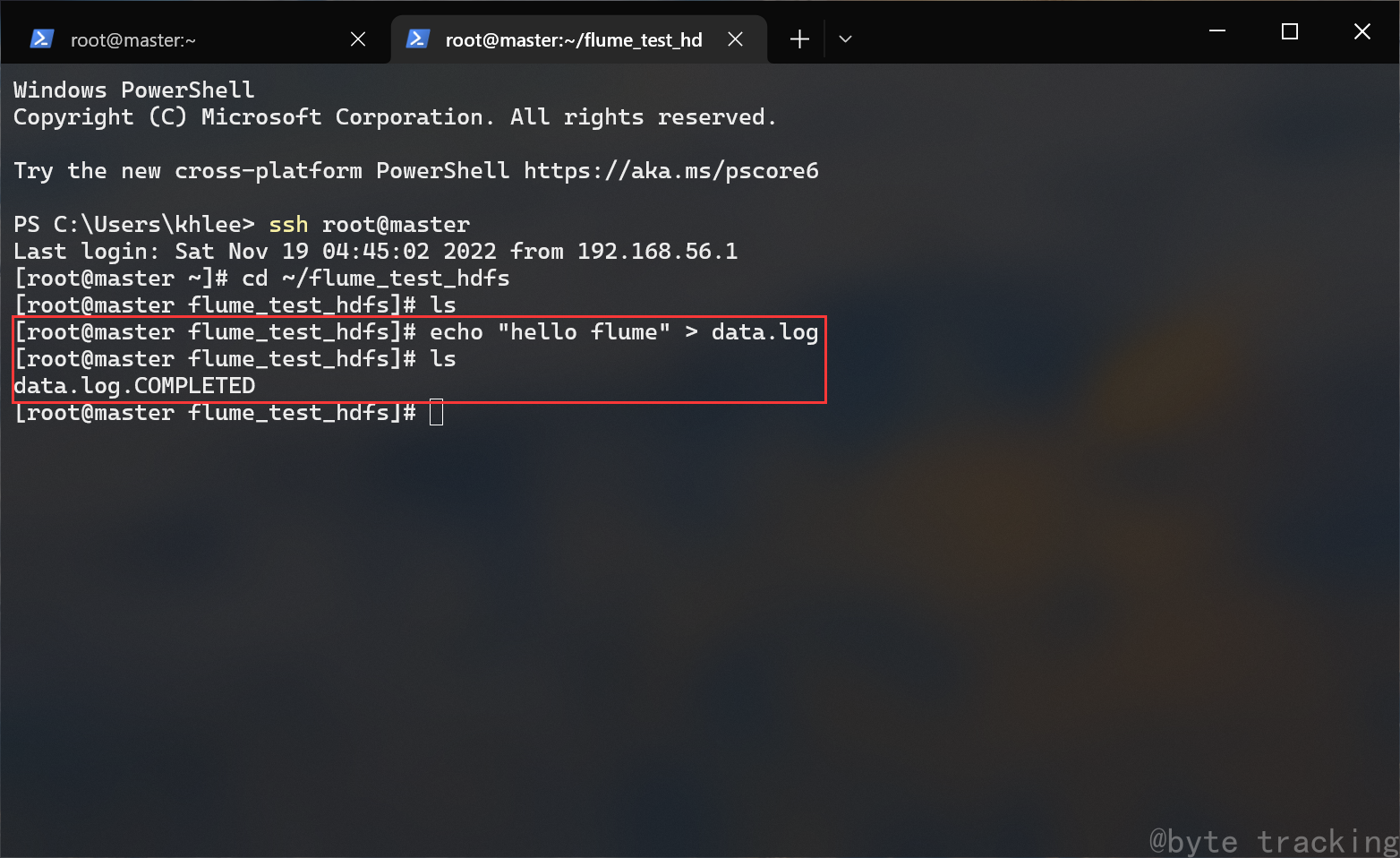
登录hdfs web界面查看 hdfs 目录变化:
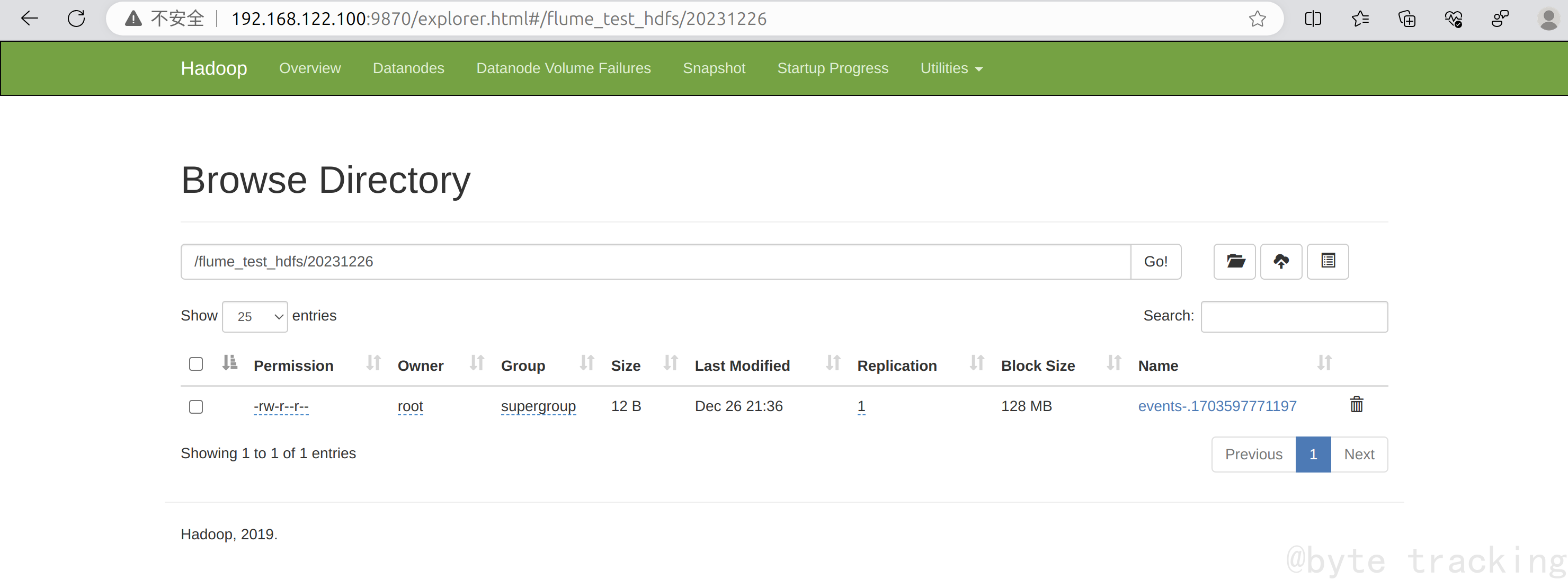
十三、Kafka 集群部署
介绍
- 是由 Linkedin 公司开发的。它是一个分布式的、支持多分区、多副本、基于 Zookeeper 的分布式消息流平台,它同时也是一款开源的基于发布订阅模式的消息引擎系统。KAFKA 因为根据自身需要,并未严格遵循 MQ(Message Queue) 规范,而是基于 TCP\IP 自行封装了一套协议,通过网络 socket 接口进行传输,实现了 MQ(Message Queue) 的功能。
Broker
- 消息服务器,作为 Server 提供消息核心服务。
Producer
- 消息生产者,业务的发起方,负责生产消息传输给 Broker。
Consumer
- 消息消费者,业务的处理方,负责从 Broker 获取消息并进行业务逻辑处理。
Topic
- 主题,发布订阅模式下的消息统一汇集地,不同生产者向 Topic 发送消息,由 MQ 服务器分发到不同的订阅者,实现消息的广播。
Queue
- 队列。PTP 模式下,特定生产者向特定 Queue 发送消息,消费者订阅特定的 Queue 完成指定消息的接收。
Message
- 消息体,根据不同通信协议定义的固定格式进行编码的数据包,来封装业务数据,实现消息的传输。
发布-订阅消息传递
- KAFKA 工作在此模式下,发布者发送到 Topic 的消息,只有订阅了 Topic 的订阅者才会收到消息。
前提条件
- kafka_2.12-2.4.1.tgz(位于 /opt/softwares/ 下)
- Hadoop 和 Zookeeper 集群已经启动
- 分布式部署
1.解压
以下内容在 master 节点上操作
进入目录:
cd /opt/module
解压文件到当前目录:
tar -zxvf /opt/softwares/kafka_2.12-2.4.1.tgz
重命名 kafka :
mv kafka_2.12-2.4.1/ kafka
2.配置环境变量
以下内容在 master 节点上操作
编辑环境变量:
env-edit
在文件末尾添加:
# KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
3.生效环境变量
以下内容在master节点上操作
env-update
4.修改配置文件
以下内容在 master 节点上操作
创建 kafka 的日志目录:
mkdir $KAFKA_HOME/logs
进入配置文件目录:
cd $KAFKA_HOME/config
使用 vim 编辑 server.properties:
vim server.properties
找到并修改以下内容:
# 日志目录(确保这个目录存在)
log.dirs=/opt/module/kafka/logs
# 节点
zookeeper.connect=master:2181,slave1:2181,slave2:2181/kafka
5.分发文件
以下内容在 master 节点上操作
下发 kafka 目录到 slave1 和 slave2 节点:
scp -r /opt/module/kafka slave1:/opt/module/
scp -r /opt/module/kafka slave2:/opt/module/
下发环境变量文件到 slave1 和 slave2 节点:
scp -r /etc/profile.d/myenv.sh slave1:/etc/profile.d/
scp -r /etc/profile.d/myenv.sh slave2:/etc/profile.d/
当然,如果你足够了解 shell 的话,可以使用这种方法简化路径:
cd /etc/profile.d
scp ./big_data_env.sh slave1:$(pwd)/
scp ./big_data_env.sh slave2:$(pwd)/
6.生效环境变量
以下内容在 slave1 和 slave2 上操作
env-update
7.设置 Broker ID
以下内容在master节点上操作
进入配置文件目录:
cd $KAFKA_HOME/config
通过 cat 组合 grep 看一下 server.properties 文件内 broker.id 的默认值是什么:
cat server.properties | grep "broker.id"
如图所示:
那我们就规划以下三个节点的 Broker ID:
- master -> 0(无需修改了)
- slave1 -> 1
- slave2 -> 2
将 slave1 的 broker.id 修改为 1:
ssh slave1 "sed -i 's/broker.id=0/broker.id=1/g' $KAFKA_HOME/config/server.properties"
将 slave2 的 broker.id 修改为 2:
ssh slave2 "sed -i 's/broker.id=0/broker.id=2/g' $KAFKA_HOME/config/server.properties"
查看一下是否修改成功:
#slave1
ssh slave1 "cat $KAFKA_HOME/config/server.properties | grep 'broker.id'"
#slave2
ssh slave2 "cat $KAFKA_HOME/config/server.properties | grep 'broker.id'"
如图所示:

8.启动 Kafka
以下内容在master节点上操作
启动 Kafka(后面跟上 & 是为了使它后台运行):
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties &
通过 jps 可以看到 Kafka:
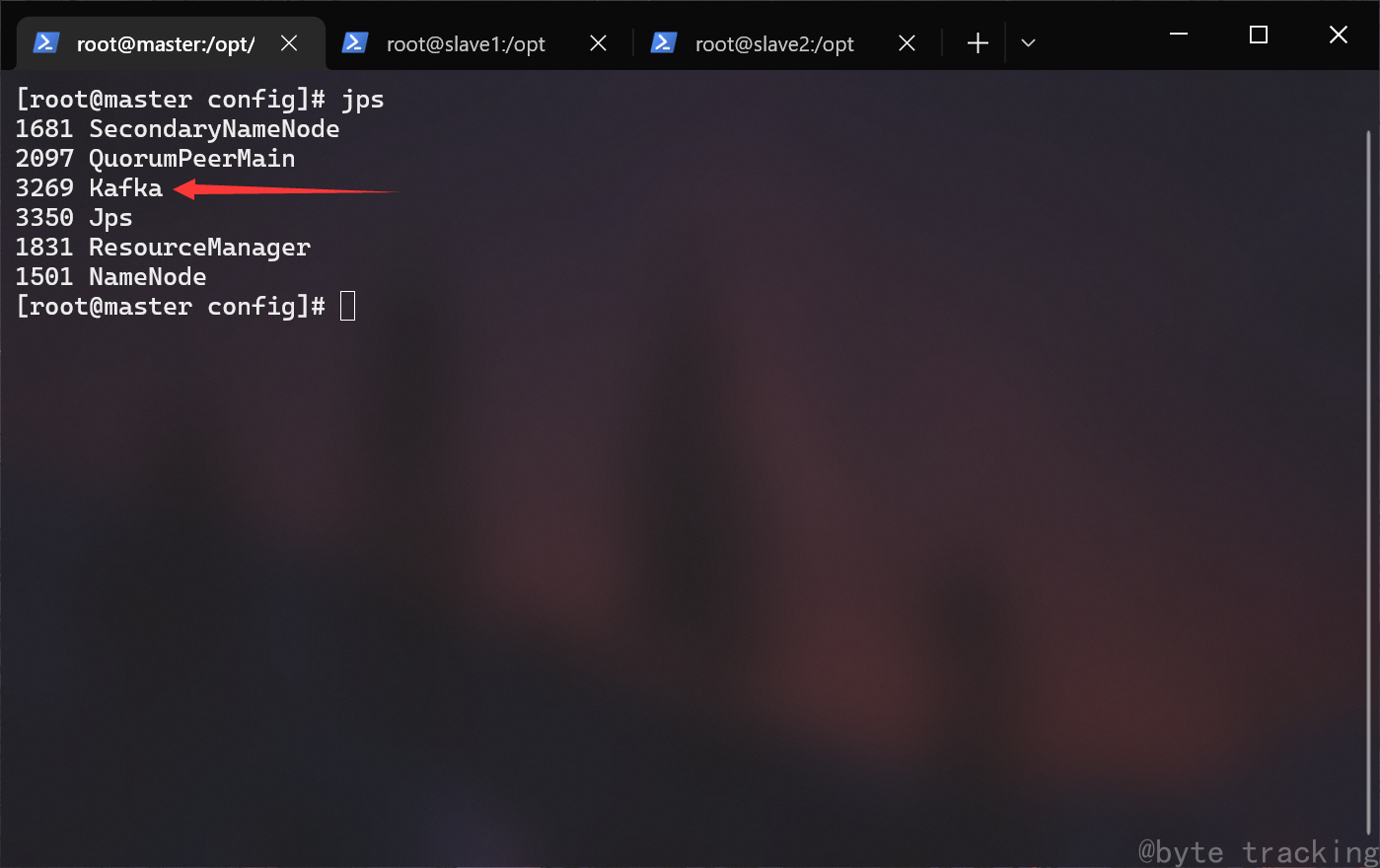
9.测试
请确保您的 hadoop 集群、zookeeper、kafka 已经启动
新建一个名为 test 的 Topic :
kafka-topics.sh --create \
--zookeeper master:2181/kafka \
--partitions 2 \
--replication-factor 1 \
--topic test
如图所示:
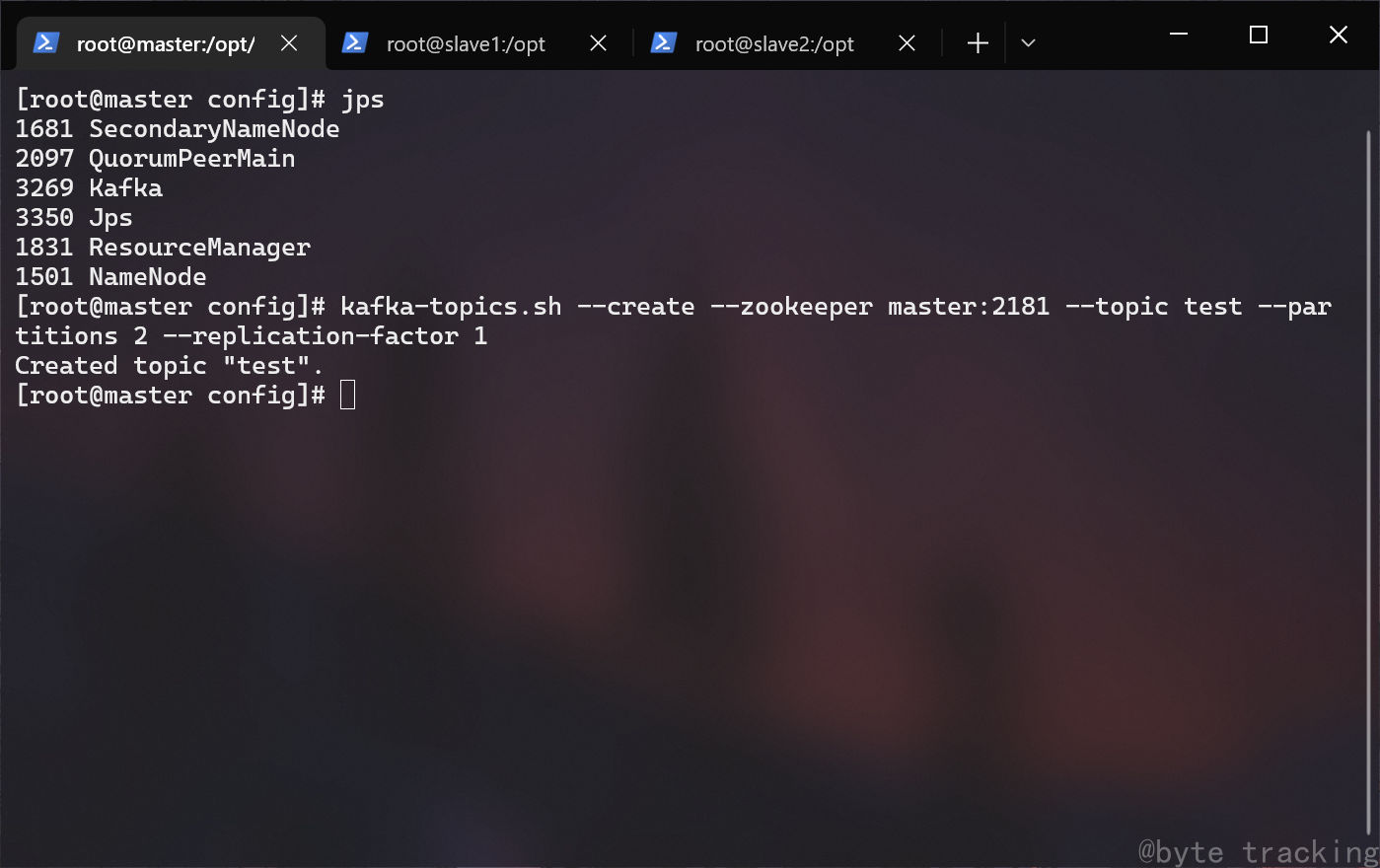
查看 Topic :
kafka-topics.sh --list --zookeeper master:2181/kafka
如图所示:
在 master 节点上发送消息:
kafka-console-producer.sh --broker-list master:9092 --topic test
在 master 以外的任意节点上接收消息:
# --from-beginning 同步历史消息
kafka-console-consumer.sh --bootstrap-server master:9092 --topic test --from-beginning
在生产者终端输入一些内容按下回车,就会发现消费者终端已经接收到了来自生产者的消息(其中 “asd” 消息是之前发送过的历史消息,因为我们加了 --from-beginning 参数,所以也被同步回来了):
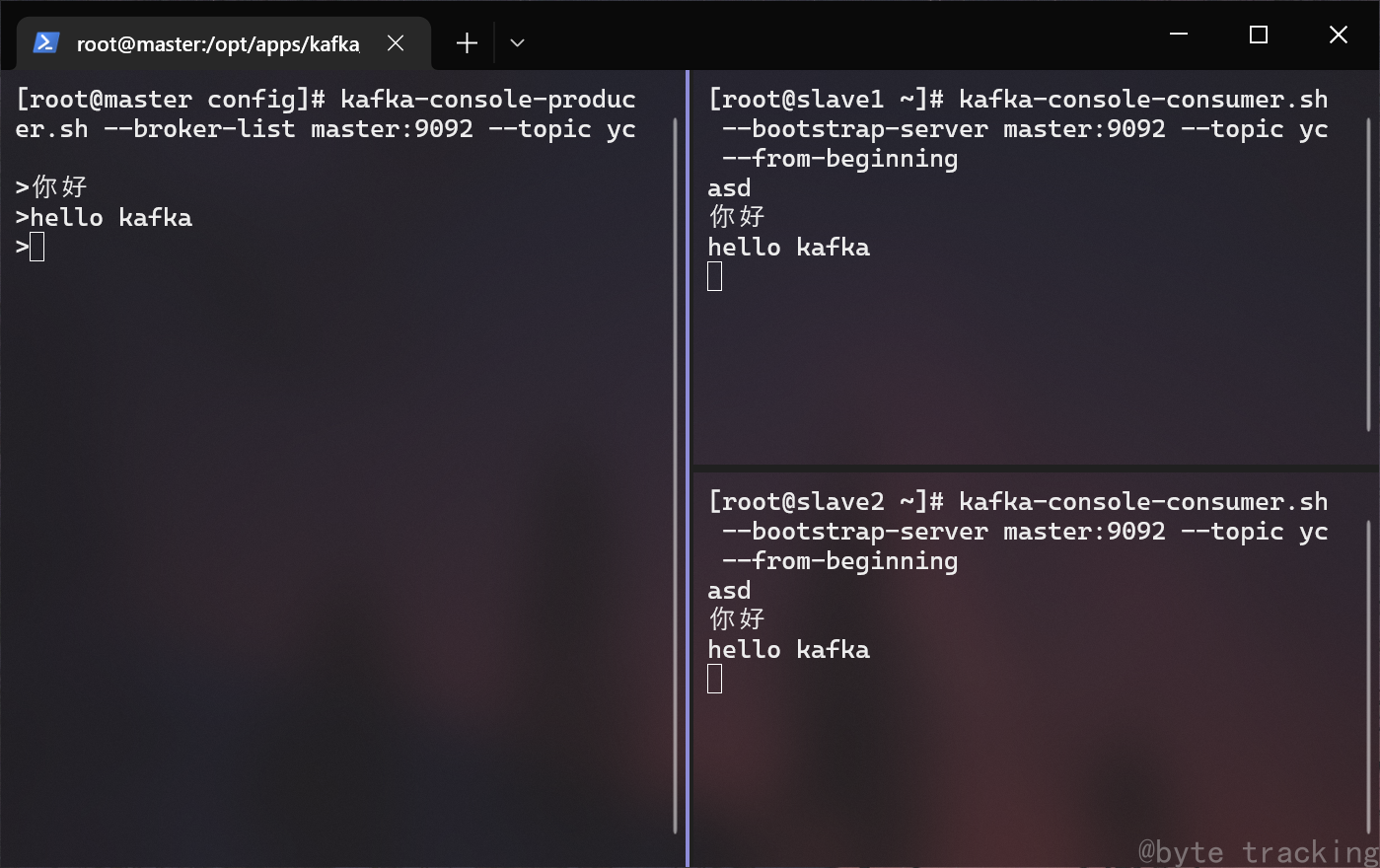
测试完成后 ctrl + c 结束即可
10.其他
解释:
- Topic:消息名称
- Partition:分区号(从 0 开始)
- Leader:所在分区的 broker 编号,负责处理消息的读写。(从所有节点中随机选择)
- Replicas:列出了所有的副本节点,不管节点是否在服务中。
- Isr:正在服务中的节点。
查看某个 Topic(例如 test):
kafka-topics.sh --zookeeper master:2181 --describe –topic test
删除某个 Topic(例如 test):
kafka-topics.sh --delete --zookeeper master:2181 --topic test
十四、Flink & Yarn 集群部署
介绍
-
Apache Flink 是一个分布式流批一体化的开源平台。Flink 的核心是一个提供数据分发、通信以及自动容错的流计算引擎。Flink 在流计算之上构建批处理,并且原生的支持迭代计算,内存管理以及程序优化。
-
对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个特例而已。也就是说,Flink 会把所有任务当成流来处理,这也是其最大的特点。Flink 可以支持本地的快速迭代,以及一些环形的迭代任务。
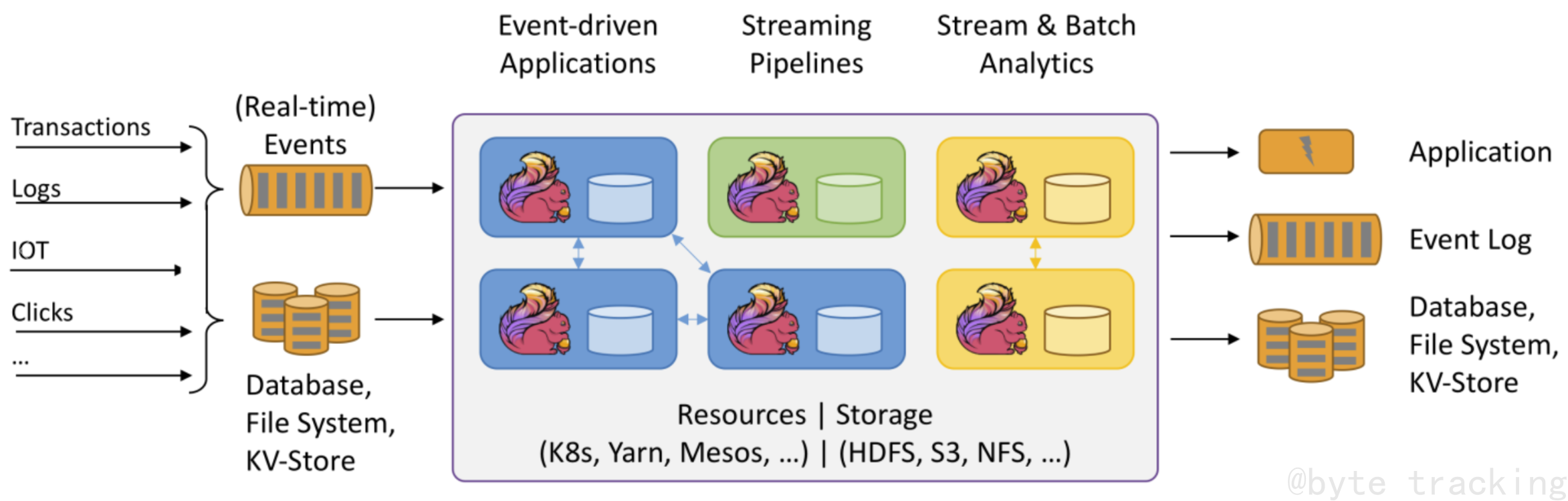
前提条件
- flink-1.14.0-bin-scala_2.12.tgz (位于 /opt/softwares/ 下)
- Hadoop 和 Zookeeper 集群已经启动
- 分布式部署
1.解压
以下内容在 master 节点上操作
进入目录内:
cd /opt/module/
解压 flink-1.14.0-bin-scala_2.12.tgz 到当前目录:
tar -zxvf /opt/softwares/flink-1.14.0-bin-scala_2.12.tgz
重命名flink:
mv flink-1.14.0/ flink
2.配置环境变量
以下内容在 master 节点上操作
编辑环境变量:
env-edit
在文件末尾添加:
#FLINK_HOME
export FLINK_HOME=/opt/module/flink
export PATH=$PATH:$FLINK_HOME/bin
export HADOOP_CLASSPATH=`hadoop classpath`
3.生效环境变量
以下内容在 master 节点上操作
env-update
4.修改配置文件
以下内容在 master 节点上操作
进入配置文件目录:
cd /opt/module/flink/conf
编辑flink-conf.yaml:
vim flink-conf.yaml
注意:
如果是1.16.0之后的版本就需要修改下面的内容
- #JobManager节点地址.
- jobmanager.rpc.address: master 主节点的地址
- jobmanager.bind-host: 0.0.0.0 远程连接,设为0.0.0.0别的机器也可以访问,设为master也可以
- rest.address: master 与主节点的地址保持一直就可以
- rest.bind-address: 0.0.0.0
- #TaskManager节点地址.需要配置为当前机器名
- taskmanager.bind-host: 0.0.0.0
- taskmanager.host: master
如果是1.16.0版本之前只需要修改jobmanager.rpc.address就可以了
输入 /jobmanager.rpc.address 进行定位搜索,修改后如下:
jobmanager.rpc.address:master
输入 /rest.port 进行定位搜索,取消注释,修改后如下:
# 修改默认端口号,避免与spark冲突
rest.port: 8083
添加以下内容到末尾,解决版本冲突问题:
classloader.check-leaked-classloader: false
5.配置workers&&masters文件
以下内容在 master 节点上操作
确保在 /opt/module/flink/conf 目录下
编辑workers文件:
vim workers
修改写入工作机器的地址:
master
slave1
slave2
编辑masters文件:
vim masters
修改为:
master:8083
8083为web访问flink的端口
下面为优化配置选项,根据需要配置,可以使用默认不对其进行更改。
另外,在flink-conf.yaml文件中还可以对集群中的JobManager和TaskManager组件进行优化配置,主要配置项如下:
jobmanager.memory.process.size:对JobManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1600M,可以根据集群规模进行适当调整。
taskmanager.memory.process.size:对TaskManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1728M,可以根据集群规模进行适当调整。
taskmanager.numberOfTaskSlots:对每个TaskManager能够分配的Slot数量进行配置,默认为1,可根据TaskManager所在的机器能够提供给Flink的CPU数量决定。所谓Slot就是TaskManager中具体运行一个任务所分配的计算资源。
parallelism.default:Flink任务执行的并行度,默认为1。优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量。
注意:如果您是1.16.0以下的版本可以忽略以下步骤,本文部署的版本为1.14.0。
如果您是1.16.0以上的版本还需要将配置文件flink-conf.yaml中的taskmanager.host 改为与本机的地址或主机名。
修改slave1节点的taskmanager.host
确保你在 /opt/module/flink/conf 目录中,编辑配置文件
vim flink-conf.yaml
修改taskmanager.host,修改后为:
taskmanager.host: slave1
修改slave2节点的taskmanager.host,修改后为:
vim flink-conf.yaml
修改taskmanager.host,修改后为:
taskmanager.host: slave2
6.分发文件
以下内容在 master 节点上操作
将flink分发到slave1和slave2:
scp -r /opt/module/flink slave1:/opt/module
scp -r /opt/module/flink slave2:/opt/module
下发环境变量文件到 slave1 和 slave2 节点:
scp -r /etc/profile.d/myenv.sh slave1:/etc/profile.d/
scp -r /etc/profile.d/myenv.sh slave2:/etc/profile.d/
7.生效环境变量
以下内容在 slave1 和 slave2 上操作
env-update
8.启动集群
# 在 master 节点上运行
start-cluster.sh
查看进程情况:
jps
master节点:
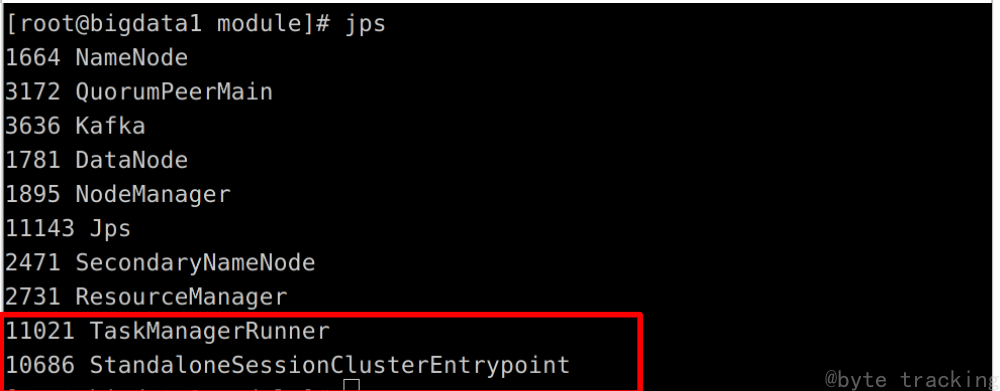
两个从节点 slave1 和 slave2:
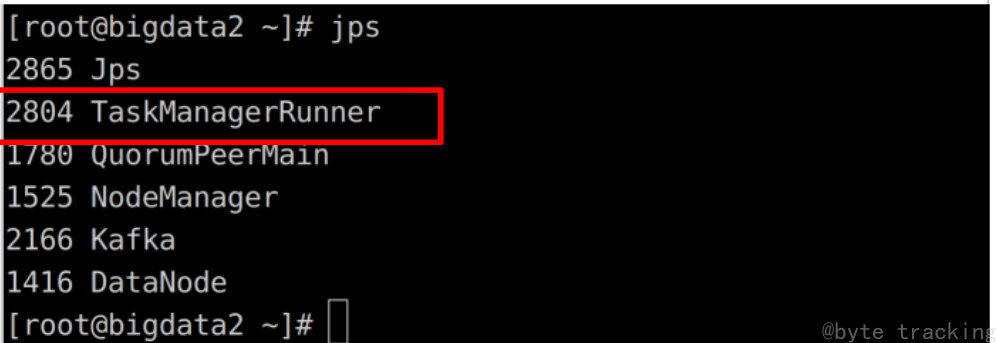
9.访问Web UI
启动成功后,同样可以访问 http://192.168.122.100:8083/ 对flink集群和任务进行监控管理。
这里可以明显看到,当前集群的TaskManager数量为3;由于默认每个TaskManager的Slot数量为1,所以总Slot数和可用Slot数都为3。
十五、Maxwell 组件部署
以下内容全部在 master 节点上操作
介绍
- 它可以读取MySQL binlogs并将行更新作为JSON写入Kafka、Kinesis或其他流媒体平台。Maxwell的操作开销很低,只需要mysql和一个写入位置。它的常见用例包括ETL、缓存构建/过期、度量收集、搜索索引和服务间通信。Maxwell为您提供了活动资源的一些好处,而无需重新构建整个平台。
前提条件
- maxwell-1.29.0.tar.gz (位于 /opt/softwares/ 下)
- Mysql 部署完成
- 非分布式部署
1.解压
进入目录:
cd /opt/module/
解压 maxwell-1.29.0.tar.gz 到当前目录内:
tar -zxvf /opt/softwares/maxwell-1.29.0.tar.gz
重命名 maxwell:
mv maxwell-1.29.0/ maxwell
2.配置环境变量
编辑环境变量:
env-edit
在文件末尾添加:
#MAXWELL_HOME
export MAXWELL_HOME=/opt/module/maxwell
export PATH=$PATH:$MAXWELL_HOME/bin
3.生效环境变量
env-update
4.配置mysql文件
编辑 my.cnf 文件:
vim /etc/my.cnf
在[mysqld]下添加如下:
server_id=1
log-bin=mysql-bin
binlog_format=row
binlog-do-db=maxwell_test
命令参数解释:
- server_id=1 集群id如果配置了多个集群的mysql开启服务需要对每个mysql配置id
- log-bin=mysql-bin 生成的日志文件就是mysql-bin开头
- binlog_format=row 二进制的日志文件级别 row行级
- binlog-do-db=test 对哪些库进行监控可以配置多行 如果没有配置则监控所有的数据库
重启MySQL服务:
systemctl restart mysqld
5.初始化Maxwell元数据库
在mysql中建立一个maxwell库用于存储Maxwell的元数据
进入mysql:
mysql -uroot -p123456
创建数据库:
CREATE DATABASE maxwell;
设置 mysql 用户密码和安全级别:
SET global validate_password_length=4;
SET global validate_password_policy=0;
创建一个用户并指定密码:
GRANT ALL ON maxwell.* TO 'maxwell'@'%' IDENTIFIED BY '123456';
增加可以监控其他数据库的权限 (仅有监控权限,无增删改查权限):
GRANT SELECT ,REPLICATION SLAVE , REPLICATION CLIENT ON *.* TO maxwell@'%';
刷新权限:
flush privileges;
ctrl + d 退出 Mysql 命令行
6.Maxwell进程启动
使用命令行参数启动 Maxwell 进程:
maxwell --user='maxwell' --password='123456' --host='master' --producer=stdout
参数:
- –user 连接 mysql 的用户
- –password 连接 mysql 的用户的密码
- –host 安装的主机名
- –producer 生产者模式(stdout:控制台 kafka:kafka 集群)
7.测试
确保Maxwell进程已经启动 :运行 maxwell 来监控 mysql 数据更新
再新开一个 master 节点,登录mysql:
mysql -uroot -p123456
新建一个测试数据库,跟上文 my.cnf 中要监控的数据库名字保持一致:
CREATE DATABASE maxwell_test;
使用此数据库:
USE maxwell_test;
向数据库中创建 test 表:
CREATE TABLE test (
id int,
name varchar(10)
);
向表中插入数据:
INSERT INTO test VALUES(1,'aaa');
查看 maxwell 的控制台输出,如图所示:

参数:
- “database” --库名
- “table” --表名
- “type” --数据更新类型
- “ts” --操作时间
- “xid” --操作 id
- “commit” --提交成功
- “data” --数据
测试完成 ctrl + z 强制结束即可
十六、Redis 数据库部署
以下内容全部在 master 节点上操作
介绍
- Redis全称为Remote Dictionary Server(远程数据服务),是一款开源的基于内存的键值对存储系统,其主要被用作高性能缓存服务器使用,当然也可以作为消息中间件和Session共享等。Redis独特的键值对模型使之支持丰富的数据结构类型,即它的值可以是字符串、哈希、列表、集合、有序集合,而不像Memcached要求的键和值都是字符串。同时由于Redis是基于内存的方式,免去了磁盘I/O速度的影响,因此其读写性能极高。
前提条件
- Linux环境安装Redis必须先具备gcc编译环境,需要具备C++库环境 (下面第一步会安装)
- 建议Redis安装6.0.8以上的版本
- redis-6.2.6.tar.gz(位于 /opt/softwares/ 下)
- 非分布式部署
gcc是linux下的一个编译程序,是C程序的编译环境
1.安装gcc
需要具备c++库环境,安装gcc:
yum -y install gcc-c++
查看是否安装成功:
gcc -v
如图所示:

注意:此版本不能低于4.8.5
2.解压
进入目录:
cd /opt/module/
解压 redis-6.2.6.tar.gz 到当前目录:
tar -zxvf /opt/softwares/redis-6.2.6.tar.gz
重命名 redis:
mv redis-6.2.6/ redis
3.安装make & make install
进入目录:
cd /opt/module/redis
在redis下执行make命令:
make
如果看到 Hint: It’s a good idea to run ‘make test’ 😉 这样一句话说明安装成功
如图所示:
在redis下执行make insatll命令:
make install
如图所示:
当然,您也可以同时执行make与make install进行安装:
make && make install
这就成功安装了redis,诶!不要着急安装下一个软件,还有东西没搞完呢
进入 redis 的默认安装路径:
cd /usr/local/bin
这几个文件分别是:
- redis-benchmark: 性能测试工具,服务器启动后运行该命令,看看自己的本子性能如何
- redis-check-aof: 修复有问题的AOF文件
- redis-check-dump: 修复有问题的dump.rdb文件
- redis-cli: 客户端,操作入口
- redis-sentinel: redis集群使用
- redis-server: redis服务器启动命令
4.修改配置文件
进入目录:
cd /opt/module/redis
使用预置模板:
cp redis.conf redis.my.conf
redis.conf配置文件,改完后确保生效,及的重启redis
-
默认daemonize no 改为 daemonize yes 能够让redis在后台启动,作为后台服务器
-
默认protected-mode yes 改为 protected-mode no 关闭保护模式
-
默认bind 127.0.0.1 改为 直接注释掉(默认bind 127.0.0.1只能本机访问)或改成本机IP地址,否则影响远程IP连接
-
添加redis密码 改为 requirepass 您自己设置的密码 如果不用密码就不用管这一项,但建议还是设置密码
编辑配置文件:
vim redis.my.conf
输入 /daemonize 进行定位搜索,修改 daemonize no 为 daemonize yes:

输入 /protected-mode 进行定位搜索,修改protected-mode yes 为protected-mode no:

输入 /bind 127.0.0.1 - 进行定位搜索,注释掉:

输入 /requirepass foobared 进行定位搜索,取消注释并设置密码为123456:

5.启动redis
指定您修改的配置文件启动redis:
redis-server /opt/module/redis/redis.my.conf
查看端口占用情况,redis默认使用6379端口:
ps -ef | grep redis | grep -v grep
如图所示:

连接redis服务:
redis-cli -a 123456 -p 6379
- -a 指定密码
- -p 指定端口(默认为6379,如果不加-p,默认就使用6379端口)
如果不加 -a 进入redis-cli后输入ping就会报错 “NOAUTH Authentication required.”
这时只要您设置了密码,输入 “auth 000000(自己设置的密码)” 返回ok就可以正常使用了

在redis-cli服务中输入ping,输出PONG说明可以正常使用了:
您可能会发现连接后最上面会有一个警告,Warning: Using a password with ‘-a’ or ‘-u’ option on the command line interface may not be safe. 虽然不影响使用,但看着心里挺难受的,现在就把它去掉
- shell的标准输出包含两种:
- (标准输出)
- (标准错误)我们的命令,即包含1也包含2,2即是我们想去除的提示。
ctrl + c 退出 redis-cli
输入以下命令启动时关闭错误警告:
redis-cli -a 123456 -p 6379 2>/dev/null
当然,您如果嫌看着麻烦可以忽略,这个警告并不影响正常使用
6.测试
以下内容在redis-cli命令行运行
查看全部key:
keys *
如图所示,代表没有key:

可以使用"set key value"的形式设置键值:
set k1 HelloWord
以get key的形式获取key的值:
get k1
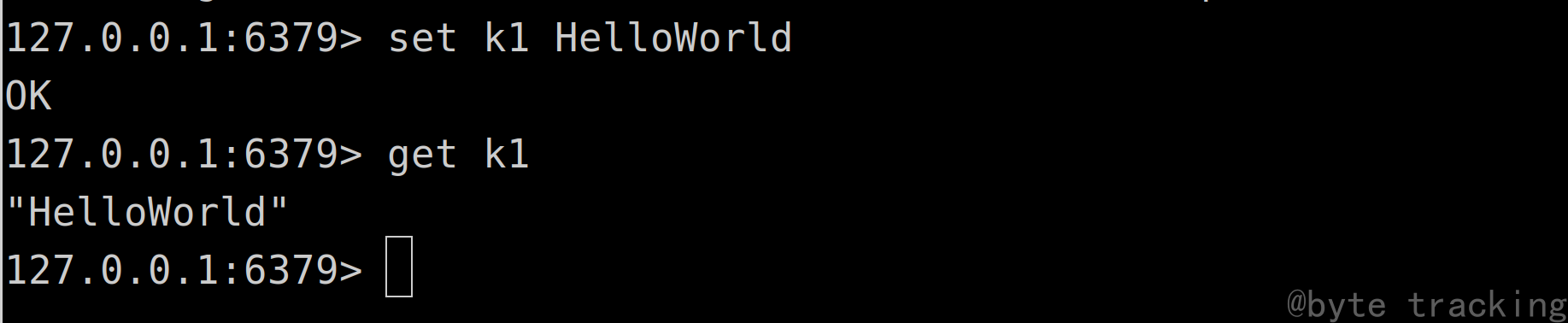
7.关闭 redis 服务
关闭 redis 服务有两种方法:
- 1.在 redis-cli 命令行中输入以下命令:
shutdown
-
- Ctrl + c 退出 redis-cli,执行以下命令:
redis-cli -a 123456 shutdown
查看6379端口:
ps -ef | grep redis | grep -v grep
可见无任何输出
恭喜您已经把主流的大数据组件部署完成🎉
致谢
此文由实验室伙伴在学习大数据的路上,观看千峰教育/尚硅谷/黑马 等网络课程以及查阅网上资料进行整理所得。若有不足之处还请指出以便及时更改,同时也希望这篇文章能够在你学习大数据的路上贡献出一点微薄之力!🙇


















 1980
1980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









