



本文通过高考数据分析案例,详细介绍了AI Agent的开发实践。展示了基于手写代码的AI Agent实现流程,包括语义混合检索、大模型调用和数据分析等核心组件,为开发者提供了完整的AI Agent开发参考。
在大模型与智能体应用场景层出不穷的今天,作为一名不断学习的信息化数字化从业者,我们可以实践一下AI Agent基本开发流程,理论联系实践,以加深我们对AI Agent的了解。
本文是Chaiys同学基于一个简单业务场景详细描述的AI Agent开发实践案例,可以用于熟悉RAG、工具调用、ReAct等概念,可以体验LangChain和QwenAgent等AI Agent主流开发框架。

一、案例描述
1.1. 业务场景
这里我们设计一个简单的场景:2025年,一位高三的同学在高考结束之后,借助AI Agent简单的查询了解一下2016年到2024的考生人数、录取人数、复读人数、普通高校数量、本科录取人数、专科录取人数这些基本信息,对历年高考考生规模做一个基本了解,借助小助手做一个简单分析预测。
基于这个场景,我们梳理一下我们的Agent需要实现的功能:用户输入自然语言查询高考录取相关信息,Agent自动生成查询SQL,查询完毕后附带简要分析输出,具体如下:
- 结构化的数据需要后台运维,进行持久化存储,采用Mysql存储,涉及多张表的数据;
- 元数据结构采用ElasticSearch8存储,可向量化KNN匹配;
- 自然语言解析出查询SQL需要借助大模型匹配元数据结构,然后编写提示词生成SQL;
- 生成的SQL需要到Mysql查询数据;
- 查询完毕的数据还需要借助大模型分析一下返回。
1.2. 数据准备
对于高考信息,我们需要存储到Mysql的结构化的表中,以便搜索查询数据,表结构如下:
drop table college_entrance_examination;droptable college_entrance_admission;createtable college_entrance_examination ( examination_year integerNOTNULL COMMENT '高考年份', candidates_count decimal(10,2) NOTNULL COMMENT '考生人数(万人)', retake_count decimal(10,2) COMMENT '复读人数(万人)', primary key (examination_year)) comment '考生人数与复读人数信息表,包含字段:高考年份(主键)、考生人数(万人)、复读人数(万人)';createtable college_entrance_admission ( admission_year integerNOTNULL COMMENT '录取年份', admission_count decimal(10,2) NOTNULL COMMENT '录取人数(万人)', university_count integer COMMENT '普通高中招生高校数', undergraduate_admission_count decimal(10,2) COMMENT '本科录取人数(万人)', specialty_admission_count decimal(10,2) COMMENT '专科录取人数(万人)', primary key (admission_year)) comment '录取人数与普通高校数信息表,包含字段:录取年份(主键)、录取人数(万人)、普通高中招生高校数、本科录取人数(万人)、专科录取人数(万人)';
数据如下:
insert into college_entrance_examination( examination_year,candidates_count,retake_count) values(2016,940,117),(2017,940,143.39),(2018,975,172.1),(2019,1031,230.95),(2020,1071,242.2),(2021,1078,187),(2022,1193,316.56),(2023,1291,210),(2024,1342,413);insertinto college_entrance_admission( admission_year,admission_count,university_count, undergraduate_admission_count,specialty_admission_count) values(2016,772,2595,405,367),(2017,761.49,2631,410,351),(2018,790.99,2663,422,369),(2019,820,2688,431,389),(2020,967.45,2740,443,524.45),(2021,1001.32,2759,448.74,552.58),(2022,1014.54,2760,467.18,547.36),(2023,1058.21,2820,482.89,575.32),(2024,1068.9,2868,478.16, 590.74);
注:上述高考考生基本数据来源于互联网、教育局网站。
注:具体业务上可能远远不止一个数据源、两张表,需要根据用户问题使用RAG检索匹配具体使用哪个数据源的哪个表,本次实践仅仅使用两张表模拟多数据源的业务场景,为语义匹配流程开发做一个学习与了解!
接下来我们分别用手写代码、基于LangChain框架、基于QwenAgent框架等三种不同的模式进行AI Agent的实践探索。
二、开发实践(手写代码)
2.1. 总体架构
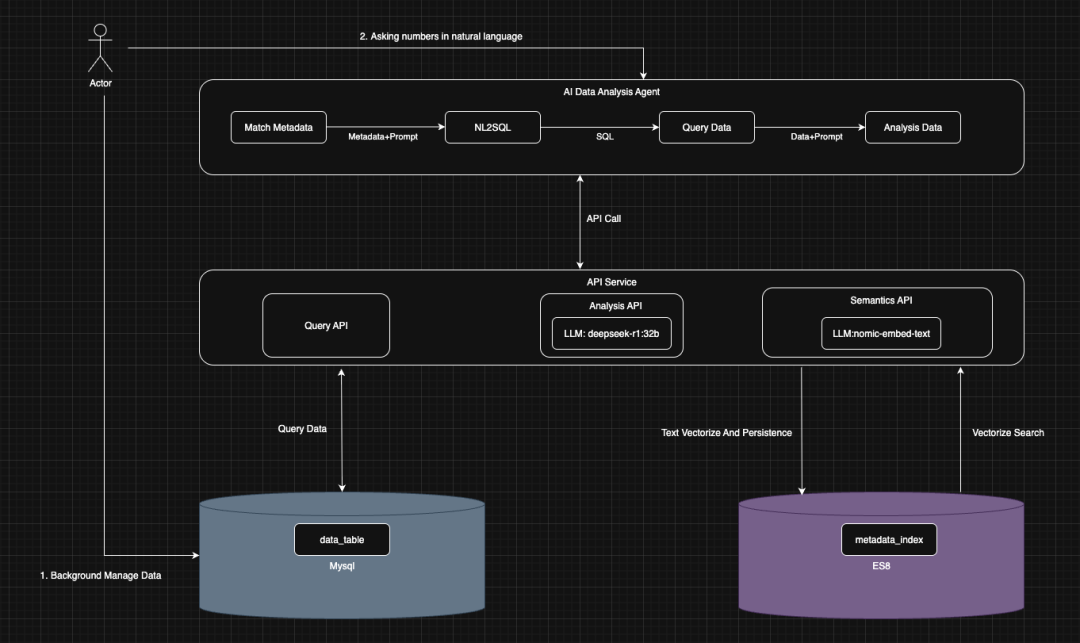
1、API服务(API Service)对智能体提供类似MCP的工具服务;
2、智能体(AI Data Analysis Agent)对用户输入的自然语言查数进行回答,执行过程中调用相应的API服务;
3、同时智能体具有简单的容错流程:未匹配到元数据时结束流程并进行提示、生成的SQL未查询到数据时结束流程并进行提示;
2.2. 实现流程
按照我们上面的核心业务梳理实现流程,手写一个Workflow,主要是根据用户问题,先匹配数据源的表结构,再生成SQL、查数和分析。
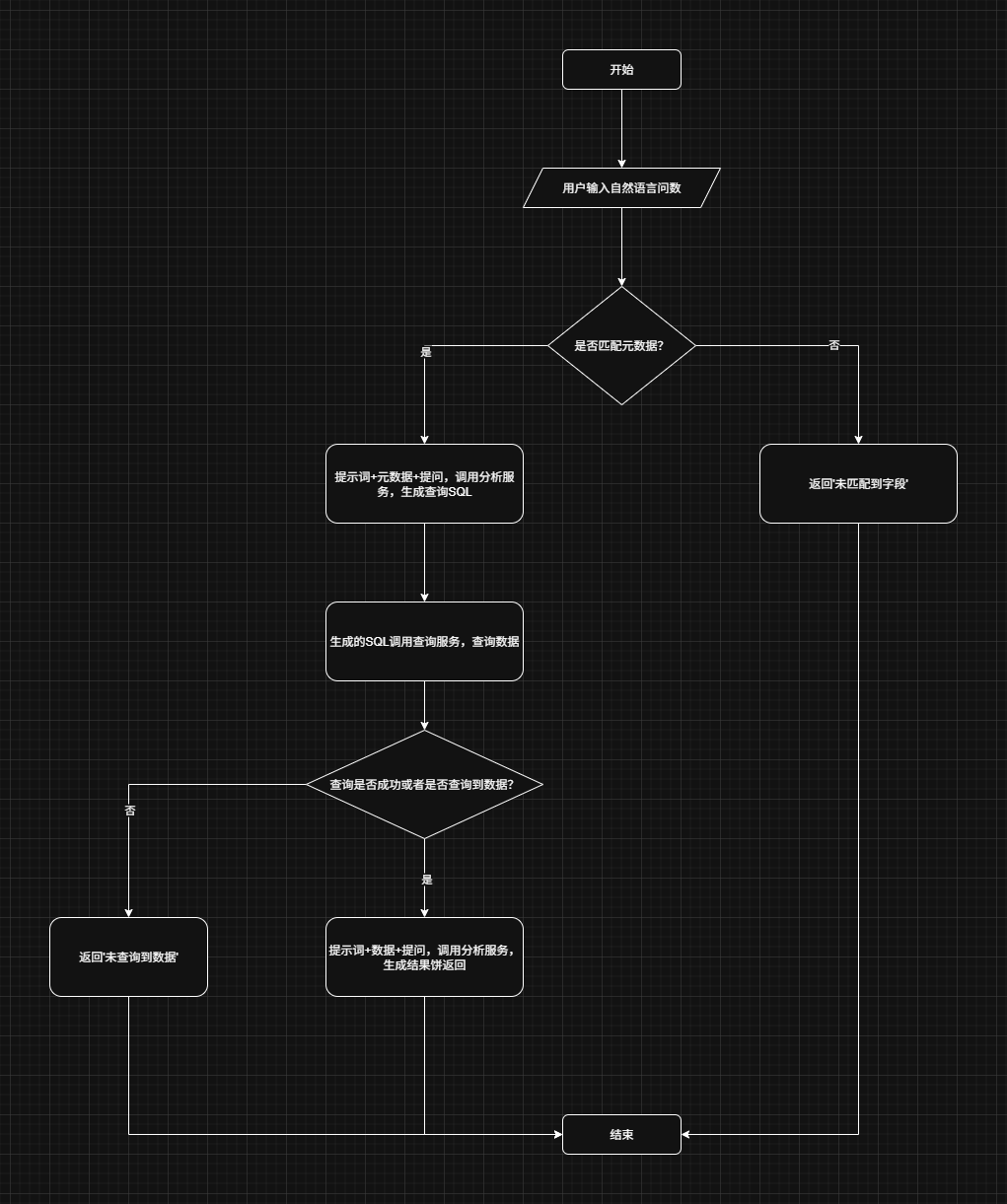
2.3. 智能体代码实践
具体开发实现如下(agent_service.py):
import sysimport reimport jsonfrom api_service import QueryService,SemanticServce,AnalysisService# metadata init 元数据初始向量化过程definit(): print("开始执行方法init") queryService = QueryService() semanticService = SemanticServce() # 1. 从mysql中获取表结构元数据信息 results = queryService.query( """ SELECT t.TABLE_NAME AS '表名', t.TABLE_COMMENT AS '表备注', c.COLUMN_NAME AS '字段名', c.COLUMN_TYPE AS '字段类型', c.COLUMN_COMMENT AS '字段备注' FROM INFORMATION_SCHEMA.TABLES t INNER JOIN INFORMATION_SCHEMA.COLUMNS c ON t.TABLE_NAME = c.TABLE_NAME AND t.TABLE_SCHEMA = c.TABLE_SCHEMA WHERE t.TABLE_SCHEMA = 'chaiys' and t.table_name in ('college_entrance_admission','college_entrance_examination') ORDER BY t.TABLE_NAME, c.ORDINAL_POSITION """ ) table_data = {} for row in results: table_name = row[0] if table_name notin table_data: table_data[table_name] = { '表名': table_name, '表备注': row[1], '字段列表': [] } # 添加字段信息 table_data[table_name]['字段列表'].append({ '字段名': row[2], '字段类型': row[3], '字段备注': row[4] }) print(table_data) semanticService.create_index() # 转换为列表形式 for table_name inlist(table_data.keys()): table = table_data[table_name] # 2. 向量化表结构元数据信息并插入ES索引 semanticService.vectorize_and_index(table_name, json.dumps(table, ensure_ascii=False))# agent flow 智能体核心流程defchat(user_query): print("执行方法chat") queryService = QueryService() semanticService = SemanticServce() analysisService = AnalysisService() # 1. 语义匹配 table = semanticService.hybrid_search(user_query, 1) ifnot table: print(f"未匹配到字段") return table_list = [t["table_info"] for t in table] prompt = f""" 你是一个MySQL专家。根据以下表结构信息: {table_list} 用户查询:"{user_query}" 生成标准MYSQL查询语句。 要求: 1. 只输出MYSQL语句,不要额外解释 2. 根据语义和字段类型,使用COUNT/SUM/AVG等聚合函数进行计算,非必须 3. 给生成的字段取一个简短的中文名称 输出格式:使用[]包含sql文本即可,不需要其他输出,便于解析,例如:[select 1 from dual] """ print(f"PROMPT={prompt}") # 2. 大模型生成SQL str1 = analysisService.analysis(prompt) sql = re.search(r'\[(.*?)\]', str1, re.DOTALL).group(1).strip() # 3. 执行查询 if sql: resultSet = queryService.query_with_column(sql) print(f"resultSet={resultSet}") # 基础分析 prompt2 = f""" 根据以下表结构信息: {table_list} 查询SQL: {sql} 和以下数据信息: {resultSet} 用户查询:"{user_query}" 生成一段简要分析,加上一些预测总结的内容 """ print(f"PROMPT={prompt2}") analysisService.analysis(prompt2)if __name__ == "__main__": # 获取命令行参数 args = sys.argv[1:] # 第一个参数是脚本名,跳过 ifnot args: print("请提供参数:init或者chat+user_query") elif args[0] == "init": init() elif args[0] == "chat": print(f"user_query={args[1]}") chat(args[1]) else: print(f"未知参数: {args[0]}")
2.4. API服务代码实践
这里的API服务,指的是为智能体的实现提供服务调用,文件名称api_service.py。
2.4.1. 语义检索服务(Semantics API)
语义服务有两个功能:
1、将元数据向量化到ES8,调用文本嵌入向量模型llama2向量化自然语言,生成4096高维向量;
2、自然语言匹配元数据返回,调用文本嵌入向量模型llama2向量化后,调用ES8使用KNN检索topK数据+分词检索topK数据,混合计算得分后返回最终topK,即简化版的外置检索增强生成(RAG);
具体开发实现如下:
import requestsimport jsonfrom elasticsearch import Elasticsearch# Semantics APIclassSemanticServce: def__init__(self): self.es_client = Elasticsearch( hosts=["https://localhost:9200"], basic_auth=("elastic", "FxCZQXMLEoZLAIvsghQy"), ca_certs="./es_http_ca.crt", verify_certs=True ) # 向量化模型 self.ollama_host = "http://localhost:11434/api/embeddings" self.metadata_index = "metadata_index" self.modal_name = "llama2" self.mapping = { "mappings": { "properties": { "table_info": { "type": "text", "analyzer": "ik_max_word", # 中文分词 "search_analyzer": "ik_smart" }, "nomic_embedding": { "type": "dense_vector", "dims": 4096, "index": True, "similarity": "cosine", } } } } defget_embedding(self, text): """使用 Ollama 生成文本嵌入向量""" try: print(f"调用大模型llama2向量化:{text}") response = requests.post(self.ollama_host, json={"model": self.modal_name, "prompt": text}) response.raise_for_status() embedding = response.json()["embedding"] return embedding except Exception as e: raise RuntimeError(f"嵌入生成失败: {str(e)}") defdelete_index(self): """安全删除索引""" try: ifself.es_client.indices.exists(index=self.metadata_index): self.es_client.indices.delete(index=self.metadata_index) print(f"索引 {self.metadata_index} 删除成功") returnTrue returnNone except Exception as e: print(f"删除索引失败: {type(e).__name__}: {str(e)}") returnFalse defcreate_index(self): self.delete_index() """创建支持nomic向量的索引""" self.es_client.indices.create(index=self.metadata_index, body=self.mapping) print(f"索引 {self.metadata_index} 创建成功") defvectorize_and_index(self, prompt, content): """生成文本嵌入向量并插入索引""" doc = { "table_info": content, "nomic_embedding": self.get_embedding(prompt) } self.es_client.index(index=self.metadata_index, document=doc) self.es_client.indices.refresh(index=self.metadata_index) print(f"表信息 {prompt}:{content} 向量化成功") defsemantic_search(self, user_query, k): """执行语义相似度搜索""" query_embedding = self.get_embedding(user_query) knn_query = { "knn": { "field": "nomic_embedding", "query_vector": query_embedding, "k": k, "num_candidates": 100# 这就是ef_search参数 }, "_source": ["table_info"] # 返回原始问题 } response = self.es_client.search(index=self.metadata_index, body=knn_query) table_info = [ { "score": hit["_score"], "table_info": hit["_source"]["table_info"], "id": hit["_id"] } for hit in response["hits"]["hits"] ] print(f"自然语言语义检索字段成功,匹配到的元数据信息:{table_info}") return table_info defkeyword_search(self, user_query: str, k) -> list: """基于分词的关键词匹配搜索""" search_query = { "query": { "bool": { "should": [ { "match": { "table_info": { "query": user_query, "analyzer": "ik_smart", # 使用IK中文分词器 "boost": 1.0 } } }, { "match_phrase": { "table_info": { "query": user_query, "slop": 2, # 允许短语间隔 "boost": 0.5 } } } ] } }, "size": k, "_source": ["table_info"], "highlight": { "fields": { "table_info": {} # 返回高亮片段 } } } response = self.es_client.search(index=self.metadata_index, body=search_query) table_info = [ { "score": hit["_score"], "table_info": hit["_source"]["table_info"], "id": hit["_id"], "highlight": hit.get("highlight", {}).get("table_info", []) } for hit in response["hits"]["hits"] ] print(f"自然语言分词搜索字段成功,匹配到的元数据信息:{table_info}") return table_info defhybrid_search(self, user_query: str, k, alpha: float = 0.7) -> list: """混合搜索(语义+关键词)""" # 语义搜索 semantic_results = self.semantic_search(user_query, k * 2) semantic_map = {hit["id"]: hit for hit in semantic_results} # 关键词搜索 keyword_results = self.keyword_search(user_query, k * 2) keyword_map = {hit["id"]: hit for hit in keyword_results} # 合并结果 all_ids = set(semantic_map.keys()) | set(keyword_map.keys()) combined = [] for doc_id in all_ids: semantic_score = semantic_map.get(doc_id, {}).get("score", 0) keyword_score = keyword_map.get(doc_id, {}).get("score", 0) combined.append({ "id": doc_id, "table_info": semantic_map.get(doc_id, keyword_map.get(doc_id))["table_info"], "semantic_score": semantic_score, "keyword_score": keyword_score, "combined_score": alpha * semantic_score + (1 - alpha) * keyword_score, "highlight": keyword_map.get(doc_id, {}).get("highlight", []) }) # 按综合分数排序 combined.sort(key=lambda x: x["combined_score"], reverse=True) table_info = combined[:k] print(f"自然语言混合检索字段成功,匹配到的元数据信息:{table_info}") return table_info
2.4.2. 大模型调用服务(Analysis API)
大模型调用服务中,我们直接调用本地部署的deepseek-r1:32b大模型,根据传入的提示词进行处理,可以用于根据自然语言生成SQL即NL2SQL,也可以用于对查询结果数据进行简单总结和分析,具体开发实现如下:
import requestsimport json# Analysis APIclassAnalysisService: def__init__(self): self.ollama_host = "http://localhost:11434/api/chat" defanalysis(self, prompt): # 发送POST请求 str = "" # 请求数据 data = { "model": "deepseek-r1:32b", "messages": [ {"role": "user", "content": prompt} ], "stream": True } with requests.post(self.ollama_host, json=data, stream=True) as response: # 处理流式响应 for line in response.iter_lines(): if line: decoded_line = line.decode('utf-8') try: # 解析JSON数据 chunk = json.loads(decoded_line) str += chunk['message']['content'] # 打印消息内容 print(chunk['message']['content'], end='', flush=True) except json.JSONDecodeError: print(f"无法解析JSON: {decoded_line}") return str
2.4.3. 数据查询服务(Query API)
本服务主要是根据输入SQL连接数据库进行实际查询,智能体利用大模型服务生成SQL后,还需要调用此服务查询数据,具体开发实现如下:
import pymysqlimport requestsimport jsonimport decimalfrom elasticsearch import Elasticsearch# Query APIclassQueryService: def__init__(self): self.host = "127.0.0.1" self.username = "root" self.password = "XXXXX" self.database = "chaiys" defquery(self, sql): global conn try: # 连接MySQL获取表结构 conn = pymysql.connect(host=self.host, port=3306, user=self.username, password=self.password, database=self.database) cursor = conn.cursor() cursor.execute(sql) # 返回字段列表 return cursor.fetchall() finally: conn.close() defquery_with_column(self, sql): global conn try: # 连接MySQL获取表结构 conn = pymysql.connect( host=self.host, user=self.username, password=self.password, database=self.database ) cursor = conn.cursor() cursor.execute(sql) # 获取字段名称 columns = [col[0] for col in cursor.description] # 获取数据 data = cursor.fetchall() # 将数据转换为字典列表格式 # 将数据转换为字典列表格式 result = [] for row in data: # 处理每个字段的值 processed_row = [] for value in row: ifisinstance(value, decimal.Decimal): # 转换为 float 或 str processed_row.append(float(value)) # 或 str(value) else: processed_row.append(value) result.append(dict(zip(columns, processed_row))) return result finally: conn.close()
2.5. 测试结果
我们设计一些简单的相关问题,进行提问测试:
问题1:2016年的考生人数有多少?
运行python agent_service.py chat ‘2016年的考生人数有多少?’,主要输出结果如下:
########## 第一步:元数据RAG检索结果 ##########[{'table_info': '{"表名": "college_entrance_examination", "表备注": "考生人数与复读人数信息表,包含字段:高考年份(主键)、考生人数(万人)、复读人数(万人),考生人数是指参加高考的学生的数量,复读人数是指参加高考的复读学生的数量", "字段列表": [{"字段名": ...省略若干字段信息...}]}']}]########## 第二步:大模型调用NL2SQL #################### 提示词 ########## 你是一个MySQL专家。根据以下表结构信息: ['{"表名": "college_entrance_examination", "表备注": "考生人数与复读人数信息表,包含字段:...省略...}]}'] 用户查询:"'2016年的考生人数有多少?'" 生成标准MYSQL查询语句。 要求: 1. 只输出MYSQL语句,不要额外解释 2. 根据语义和字段类型,使用COUNT/SUM/AVG等聚合函数进行计算,非必须 3. 给生成的字段取一个简短的中文名称 输出格式:使用[]包含sql文本即可,不需要其他输出,便于解析,例如:[select 1from dual]########## 结果 ##########<think>好,我来想想怎么解决这个问题。用户的问题是:“2016年的考生人数有多少?”首先,我需要理解问题中的关键词和要求。表名是college_entrance_examination,里面有关于高考的数据。字段有三个:examination_year(高考年份),candidates_count(考生人数,单位是万人),retake_count(复读人数,也是万人)。主键是examination_year,所以每个年份只有一条记录。用户问的是2016年的考生人数,也就是要查询candidates_count这一字段。因为这是一个具体的数值,并不需要聚合函数计算,直接查就可以了。所以,我需要写一个SELECT语句,从这个表中选取candidates_count,条件是examination_year等于2016年。同时,给结果的字段取个简短的名字,比如“考生人数”。检查一下数据类型,candidates_count是decimal(10,2),所以不需要处理,直接显示就可以了。最后,拼装SQL语句就是:SELECT candidates_count AS 考生人数 FROM college_entrance_examination WHERE examination_year = 2016;这样就能准确地返回用户需要的信息了。</think>[select candidates_count as 考生人数 from college_entrance_examination where examination_year=2016]执行SQL:select candidates_count as 考生人数 from college_entrance_examination where examination_year=2016########## 第三步:查询数据结果 ##########[{'考生人数': 940.0}]########## 第四步:数据分析 #################### 提示词 ########## 根据以下表结构信息: ['{"表名": "college_entrance_examination", "表备注": "考生人数与复读人数信息表,包含字段:高考... 省略若干字段信息... "}]}'] 查询SQL: select candidates_count as 考生人数 from college_entrance_examination where examination_year=2016 和以下数据信息: [{'考生人数': 940.0}] 用户查询:"'2016年的考生人数有多少?'" 生成一段简要分析,加上一些预测总结的内容########## 结果 ##########<think>好的,我现在需要帮用户生成一个关于2016年高考考生人数的分析和预测。首先,我得仔细理解用户提供的信息。用户给出了表结构,里面包括了高考年份、考生人数和复读人数。查询语句是选中2016年的考生人数,结果得到940.0万人。那用户的问题就是问“2016年的考生人数有多少?”接下来,我需要分析这个数据。首先,...省略...然后,思考为什么用户会问这个问题...省略...政策影响等。接下来是预测部分。我需要基于2016年的数据进行合理的...省略...趋势。还要考虑可能的因素,比如...省略...最后,要总结一下。2016年的数据是...省略...</think>### 数据分析与预测总结1. **数据分析**: - 2016 年高考考生人数为 940 万人,这一数据反映了当年参加高考的学生总数。 - 高考考生人数的变化受多种因素影响,例如人口结构、教育政策调整以及复读人数的变化等。2. **预测总结**: - 根据近年来高考报名人数的趋势,预计未来几年高考考生人数可能会继续保持增长趋势。这主要是由于适龄人口数量的增加以及教育资源普及率的提高。 - 复读人数也可能对总考生人数产生一定影响。如果复读人数逐年减少,可能会影响高考考生人数的增长速度。综上所述,2016 年高考考生人数为 940 万人,这一数据为我们了解当年高考的基本情况提供了重要参考。未来,高考考生人数可能会继续增长,但增速可能会趋于平稳。
可以看到,语义混合检索返回的一个表结构命中元数据考生人数信息表,正常生成SQL,并查询到考生人数,最后调用大模型简单分析返回。
问题2:2016年的录取人数有多少?
运行python agent_service.py chat ‘2016年的录取人数有多少?’,主要输出结果如下:
########## 第一步:元数据RAG检索结果 ##########[{'table_info': '{"表名":"college_entrance_admission","表备注":"录取人数与普通高校数信息表,包含字段:录取年份(主键)、录取人数(万人)、普通高中招生高校数、本科录取人数(万人)、专科录取人数(万人),录取人数是指录取或者招收、招录的学生的数量"...省略若干字
``````plaintext
为了减少文字,表结构信息这里省略了,用户这个问题通过语义检索到的表(college_entrance_admission),和前面一个问题检索到的表(college_entrance_examination)不同,
``````plaintext
########## 第二步:大模型调用NL2SQL #################### 提示词 ########## 你是一个MySQL专家。根据以下表结构信息:...省略若干字prompt和think过程 [select admission_count as 录取人数 from college_entrance_admission where admission_year=2016]执行SQL:select admission_count as 录取人数 from college_entrance_admission where admission_year=2016########## 第三步:查询数据结果 ##########[{'录取人数': 772.0}]########## 第四步:数据分析 #################### 提示词 ########## 根据以下表结构信息:...省略若干字Prompt和think过程2016年高考的录取人数为772.0万人。这一数据反映了当年全国范围内普通高校招生的整体情况。**分析:**- 从历史趋势来看,...省略若干字- 录取人数的变化还可能...省略若干字**预测总结:**- 预计未来几年高考录取人数可能...省略若干字
可以看到,语义混合检索返回的一个表结构命中元数据录取人数信息表,正常生成SQL,并查询到录取人数的信息,最后调用大模型简单分析数据返回。
大模型未来如何发展?普通人如何抓住AI大模型的风口?
※领取方式在文末
为什么要学习大模型?——时代浪潮已至
随着AI技术飞速发展,大模型的应用已从理论走向大规模落地,渗透到社会经济的方方面面。
- 技术能力上:其强大的数据处理与模式识别能力,正在重塑自然语言处理、计算机视觉等领域。
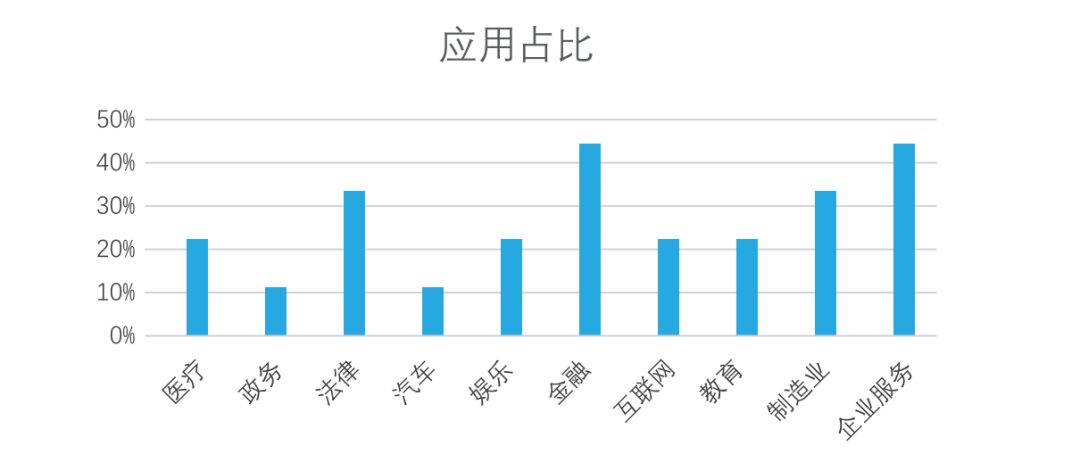
- 行业应用上:开源人工智能大模型已走出实验室,广泛落地于医疗、金融、制造等众多行业。尤其在金融、企业服务、制造和法律领域,应用占比已超过30%,正在创造实实在在的价值。
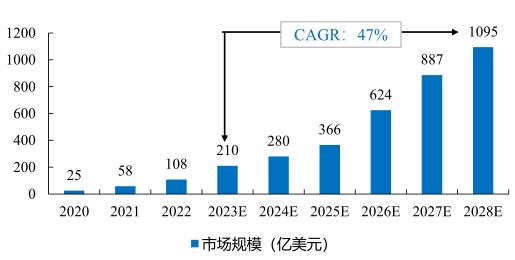
未来大模型行业竞争格局以及市场规模分析预测:
同时,AI大模型技术的爆发,直接催生了产业链上一批高薪新职业,相关岗位需求井喷:

AI浪潮已至,对技术人而言,学习大模型不再是选择,而是避免被淘汰的必然。这关乎你的未来,刻不容缓!
那么,我们如何学习AI大模型呢?
这份精心整理的AI大模型学习资料,我整理好了,免费分享!只希望它能用在正道上,帮助真正想提升自己的朋友。让我们一起用技术做点酷事!
ps:微信扫描即可获取
加上后我将逐一发送资料
与志同道合者共勉
真诚无偿分享!!!

适学人群
我们的课程体系专为以下三类人群精心设计:
-
AI领域起航的应届毕业生:提供系统化的学习路径与丰富的实战项目,助你从零开始,牢牢掌握大模型核心技术,为职业生涯奠定坚实基础。
-
跨界转型的零基础人群:聚焦于AI应用场景,通过低代码工具让你轻松实现“AI+行业”的融合创新,无需深奥的编程基础也能拥抱AI时代。
-
寻求突破瓶颈的传统开发者(如Java/前端等):将带你深入Transformer架构与LangChain框架,助你成功转型为备受市场青睐的AI全栈工程师,实现职业价值的跃升。

※大模型全套学习资料展示
通过与MoPaaS魔泊云的强强联合,我们的课程实现了质的飞跃。我们持续优化课程架构,并新增了多项贴合产业需求的前沿技术实践,确保你能获得更系统、更实战、更落地的大模型工程化能力,从容应对真实业务挑战。
 资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
01 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。希望这份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
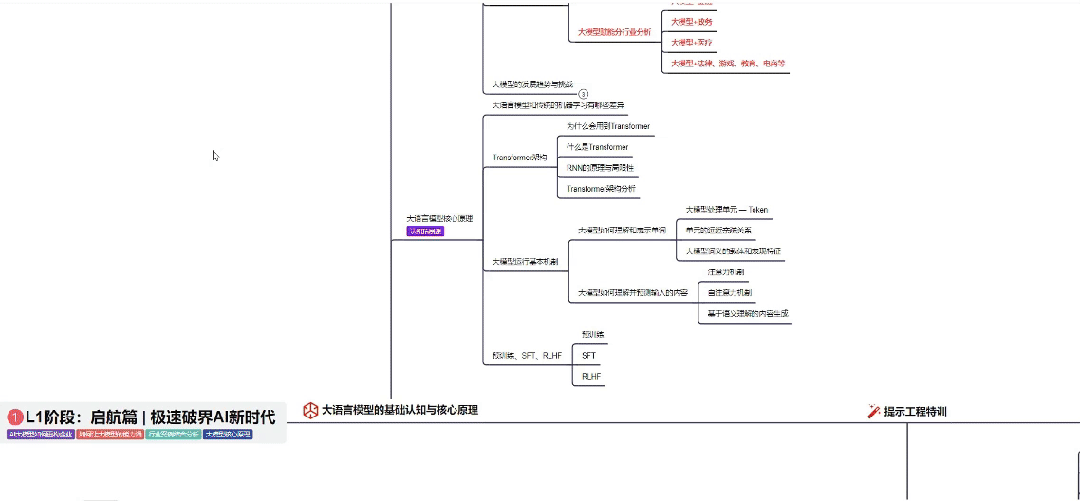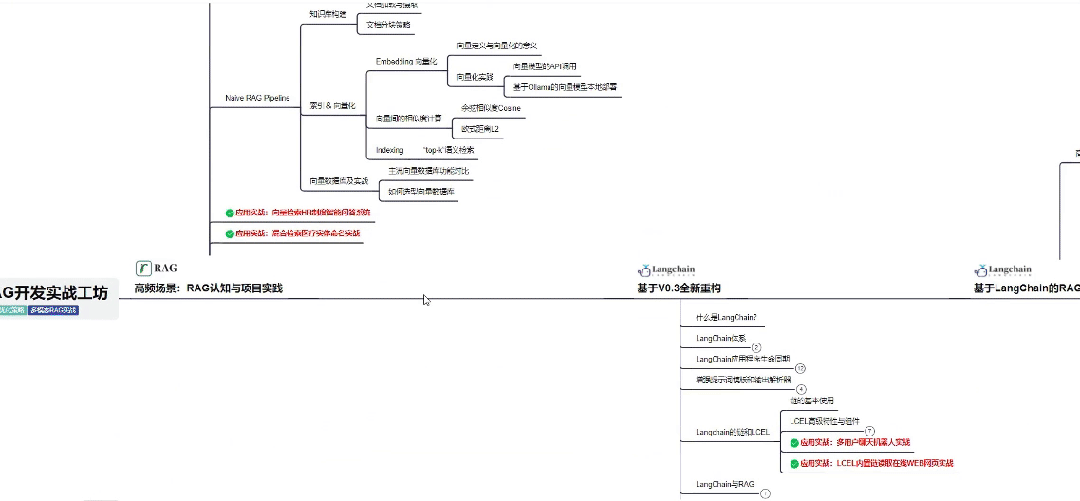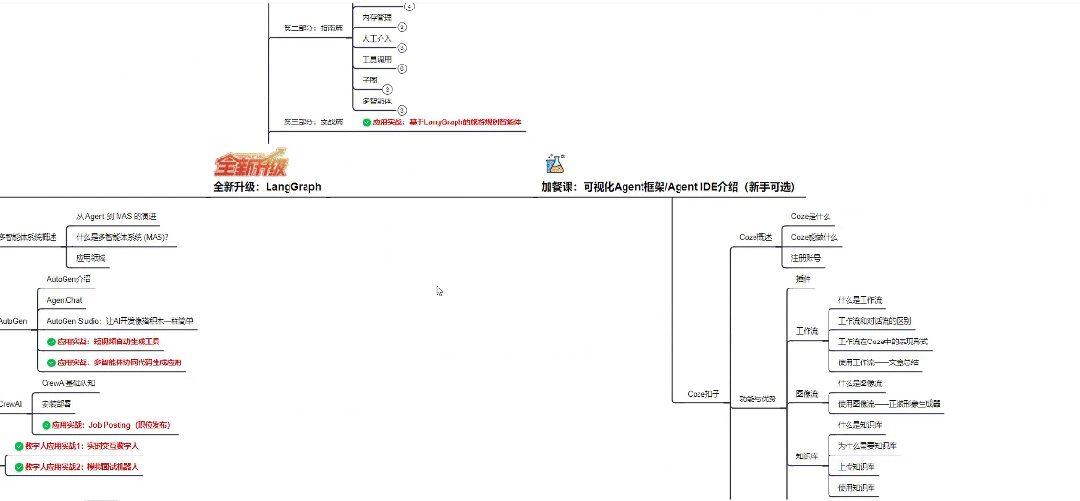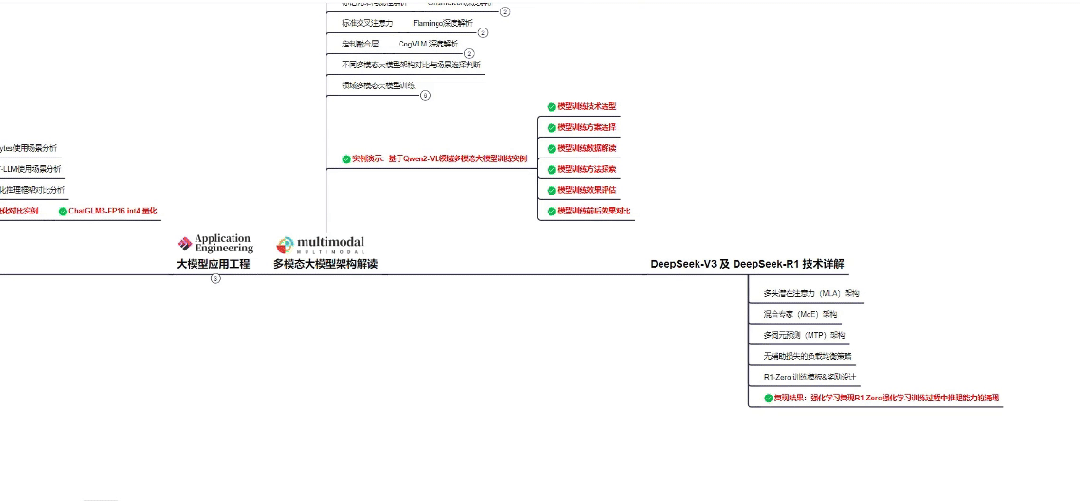
👇微信扫描下方二维码即可~

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
02 大模型学习书籍&文档
新手必备的权威大模型学习PDF书单来了!全是一系列由领域内的顶尖专家撰写的大模型技术的书籍和学习文档(电子版),从基础理论到实战应用,硬核到不行!
※(真免费,真有用,错过这次拍大腿!)

03 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
04 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
05 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

06 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
由于篇幅有限
只展示部分资料
并且还在持续更新中…
ps:微信扫描即可获取
加上后我将逐一发送资料
与志同道合者共勉
真诚无偿分享!!!
最后,祝大家学习顺利,抓住机遇,共创美好未来!


















 1783
1783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









