



本文将聚焦于蒸馏、量化、MoE(混合专家模型)、MHA(多头注意力机制)这四大核心技术,深入剖析它们的原理、优势以及在实际应用中的成功案例,带你领略 AI 大模型落地实战的关键技术奥秘。
一、知识蒸馏:让笨重的模型学会 “教徒弟”
-
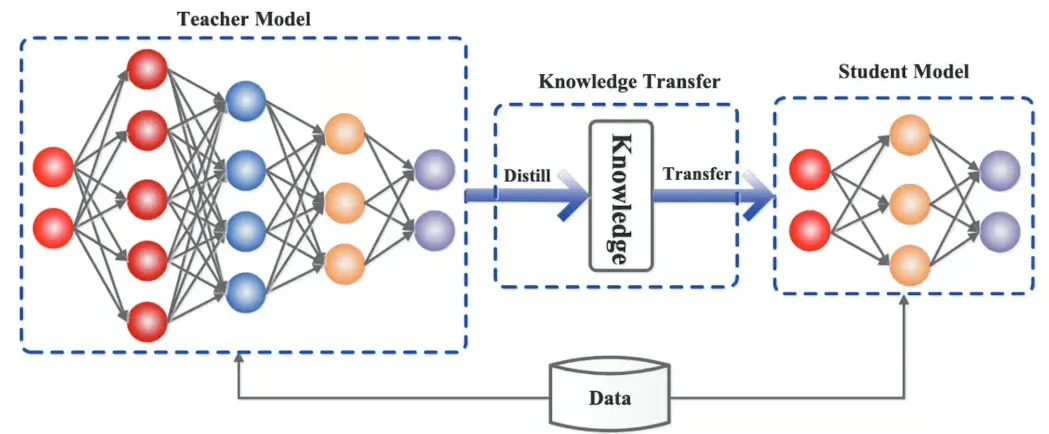
核心概念:一种机器学习模型压缩方法,将大型模型知识迁移到小型模型,提升性能与泛化能力。2014 年由 Hinton 团队提出,类比 “师徒传承系统”,教师模型复杂强大(如 12 层 Transformer,准确率 98.3%),学生模型结构简单、参数量少(如 4 层轻量网络)。
-
实现过程:教师与学生模型接收相同输入,教师模型输出软标签(含类别信息与相似度),学生模型结合软标签与真实硬标签调整参数,学习教师知识经验。
-
应用案例:电网负荷预测模型移动端部署,教师模型(12 层 Transformer)知识传递给学生模型(4 层轻量网络),模型体积从 3.2GB 缩至 780MB(缩小 76%),推理速度从 230ms 缩至 25ms(提升 9 倍),实现移动端高效部署。
二、 模型量化
- 定义:以低推理精度损失,将连续或大量离散的浮点型权重近似为有限离散值(如 int8),为 AI 模型做 “瘦身手术”,降低参数精度,减少存储与计算开销,提升推理效率。
优势
-
减小模型大小:int8 量化可减少 75% 模型大小,为 32 位浮点模型的 1/4,利于端侧部署。
-
减少内存占用:降低硬件成本,提升内存受限环境下运行稳定性。
-
减少设备功耗:内存耗用少、推理快,延长移动与边缘设备续航。
-
加快推理速度:int8 整型访问与运算更快,适配部分硬件加速器。
实操原则
-
优先量化非敏感层(如全连接层),减少计算存储量且不显著降精度。
-
保留 1 - 2 层 FP16 确保关键特征精度,平衡精度与效率。
-
采用动态范围校准,自适应调整量化参数提精度。
应用案例:寒潮预警场景,模型量化后预测速度从 3 秒 / 次提至 0.8 秒 / 次,单次推理功耗从 17W 降至 2.9W,实现快速响应。
三、 MoE 架构(Mixture of Experts,混合专家模型)
-
核心思想:通过动态选择子模型(专家)处理输入数据,“术业有专攻”,门控网络调度资源,降本提效。
-
应用案例:受 GPT - 4 启发,电网多模态数据处理中构建专家网络,如时序专家预测负荷曲线。16 专家 MoE 模型比同参数稠密模型预测准确率提升 5.8%,故障误报率降低 31%。
优势
-
性能提升:发挥专家网络优势,精准处理复杂数据。
-
计算高效:动态分配任务减少冗余,如 DeepSeek - MoE 16B 推理仅激活 2.8B 参数,计算量降 60%。
-
灵活性高:专家多样可承担广泛任务,分解复杂问题。
-
可扩展性强:支持数百上千专家,提升模型容量(如谷歌 Switch Transformer 达 1.6 万亿参数),保持分布式并行计算可行性。
四、 MHA 机制(Multi - Head Attention,多头注意力机制)
-
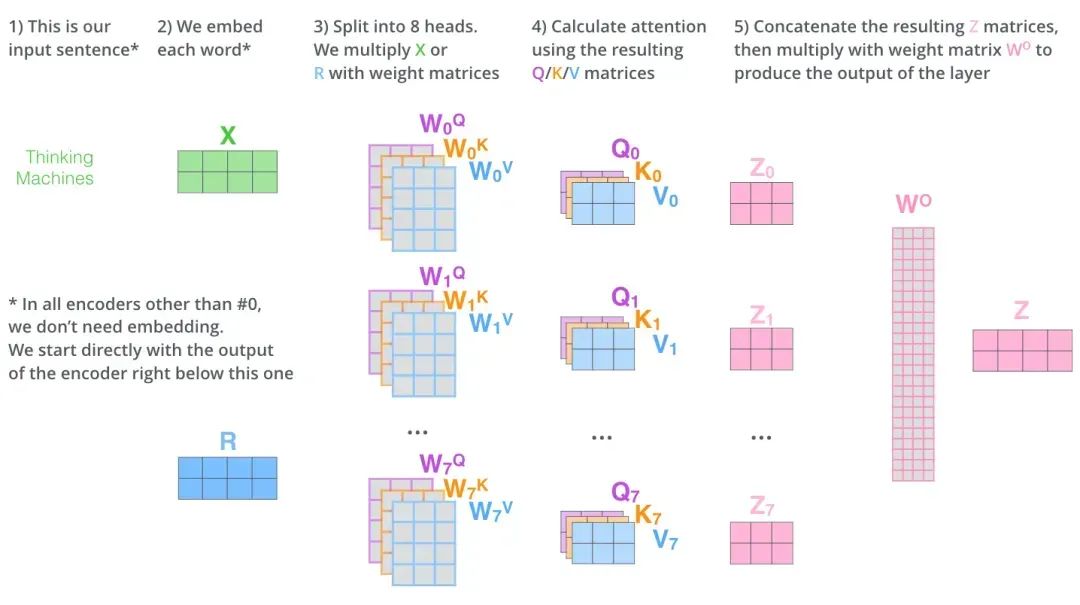
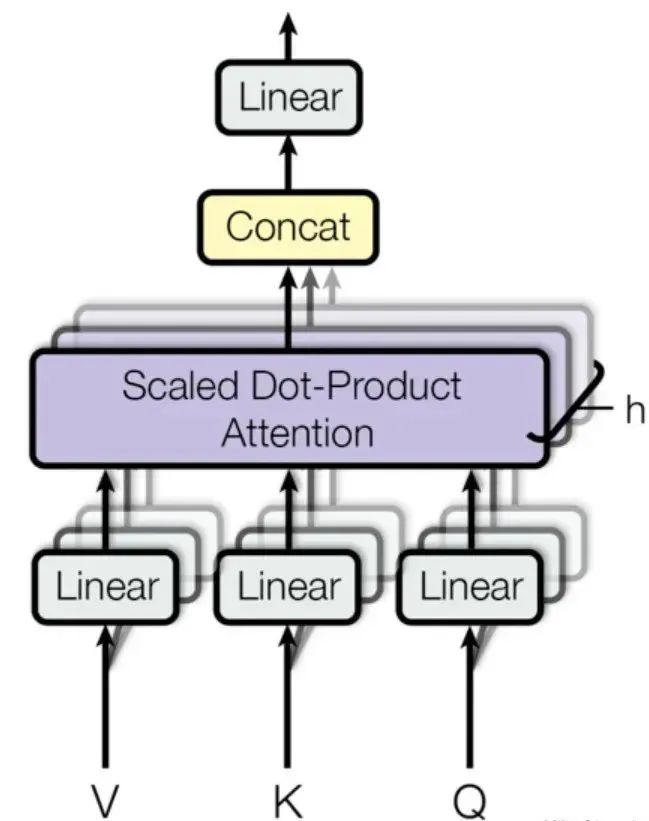
提出与原理:2017 年 Vaswani 等人提出,并行运行多个独立注意力机制,获取输入序列不同子空间注意力分布,全面捕获语义关联,类似 “多线程思考”。
-
应用案例:电力设备缺陷报告分析中,8 头注意力机制各有侧重(如头 1 关注设备型号,头 2 识别故障时间模式,头 3 关联环境温湿度),协同分析提取信息。
-
效果提升:设备故障根因分析中,MHA 的 F1 值提高 12.7%;日志根因定位场景,平均定位时间从 30 分钟缩至 10 分钟,提升问题排查效率。
综上所述,蒸馏、量化、MoE、MHA 这四大核心技术在 AI 大模型落地实战中发挥着至关重要的作用…
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









