







卷积操作
卷积是一种在许多应用中使用的热门数组操作。它被用于图像处理、信号处理和机器学习。本文介绍1D卷积的CUDA实现,2D卷积请参考【CUDA】 2D卷积 2DConvolution
图1展示了一个卷积操作的示例:
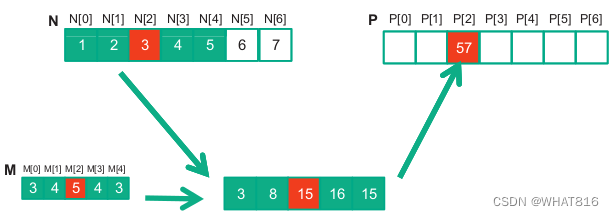
图1
基本方法、常数存储器、共享存储器和Caching
基本方法
在基本方法中,卷积是通过逐次访问数组并为每个元素计算卷积来计算的。这种方法很简单,但效率不高。原因在于卷积操作需要多次访问输入数组和mask (掩膜,卷积核,掩码)。
常量存储器
为了避免多次访问mask ,我们可以将mask 的元素存储到常量内存中。这将使硬件能够将mask 元素缓存到L2缓存内存中。这将大大减少全局内存访问,并提高kernel的性能。
共享存储器
共享存储器方法利用共享内存缓存输入数组。由于卷积操作多次访问相同的输入元素,我们可以将输入元素的块缓存到共享内存中,这样相邻的线程就不会从全局内存中加载相同的元素。
Caching
Caching处理方式是共享存储器处理方式的一个变种。唯一的区别是将halo(边角)元素如图2从全局内存中访问。我们之所以这样做是因为halo单元来自相邻块的内部单元。这意味着这些元素可能已经在L2缓存中找到,这将使我们再次避免全局内存访问的同时简化代码。
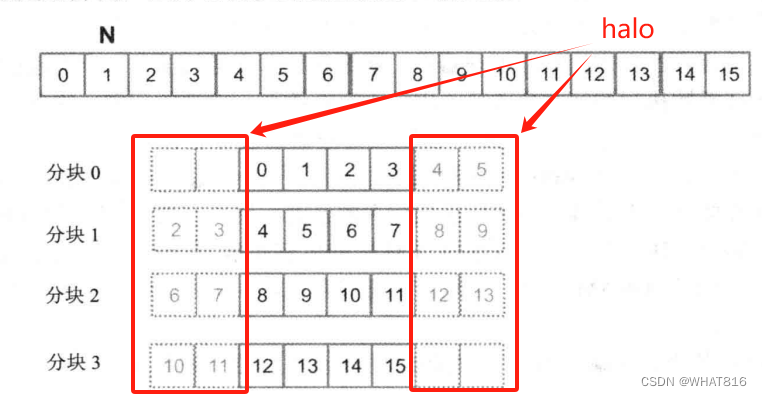
图2
以上四种方法再介绍完Code后分析访存差异。
Code
Host代码用随机值初始化输入向量和mask,并调用kernel执行1D卷积。
#include <iostream>
#include <cstdio>
#include <ctime>
#include <cmath>
#include <cuda_runtime.h>
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include "Convolution1D.cuh"
#include "helper_cuda.h"
#include "error.cuh"
const double EPSILON = 1.0e-10;
const int FORTIME = 50;
void check_res(float* h_out, float* d_out, int img_w, std::string kernel_name) {
bool success = true;
for (int i = 0; i < img_w; ++i) {
if (fabs(h_out[i] - d_out[i]) > 0.001) {
std::cout << "Error at " << i << ": " << h_out[i] << " != " << d_out[i] << std::endl;
success = false;
}
}
std::cout << "Test (" << kernel_name << "): " << (success ? "PASSED" : "FAILED") << std::endl;
}
int main(void)
{
int img_w, mask_w, tile_w, mask_w_radius;
img_w = 4194304;
//img_w = 1024;
mask_w = 25;
tile_w = 1024;
mask_w_radius = mask_w / 2;
thrust::host_vector<float> h_img(img_w);
thrust::host_vector<float> h_mask(mask_w);
thrust::host_vector<float> h_out(img_w);
thrust::host_vector<float> h_dout(img_w);
srand(time(NULL));
for (int i = 0; i < img_w; ++i)
h_img[i] = (rand() % 256) / 255.0;
for (int i = 0; i < mask_w; ++i)
h_mask[i] = (rand() % 256) / 255.0 / (mask_w / 4.);
for (int i = 0; i < img_w; ++i) {
for (int m = 0; m < mask_w; ++m)
if (i + m - mask_w_radius >= 0 && i + m - mask_w_radius < img_w)
h_out[i] += h_img[i + m - mask_w_radius] * h_mask[m];
h_out[i] = clamp(h_out[i]);
}
thrust::device_vector<float> d_img = h_img;
thrust::device_vector<float> d_mask = h_mask;
thrust::device_vector<float> d_out(img_w);
int block_dim = tile_w;
int grid_dim = (img_w + block_dim - 1) / block_dim;
cudaEvent_t start, stop;
checkCudaErrors(cudaEventCreate(&start));
checkCudaErrors(cudaEventCreate(&stop));
checkCudaErrors(cudaEventRecord(start));
for (int i = 0; i < FORTIME; i++) {
convolution_1D_bas 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









