






目录
文章目录
前言
本文章使用的是《天机学堂》开源的资料,并从创建虚拟机开始部署《天机学堂项目》,避免还要下载资料中的20GB虚拟机,只需要下载镜像以及其他基础资料即可,请大家放心食用(https://blog.youkuaiyun.com/weixin_68576312/article/details/154407558?spm=1011.2415.3001.5331)
上一篇:《天机学堂-day3(学习计划和进度)》

一、原业务逻辑与优化方案业务逻辑对比
1、原业务逻辑痛点
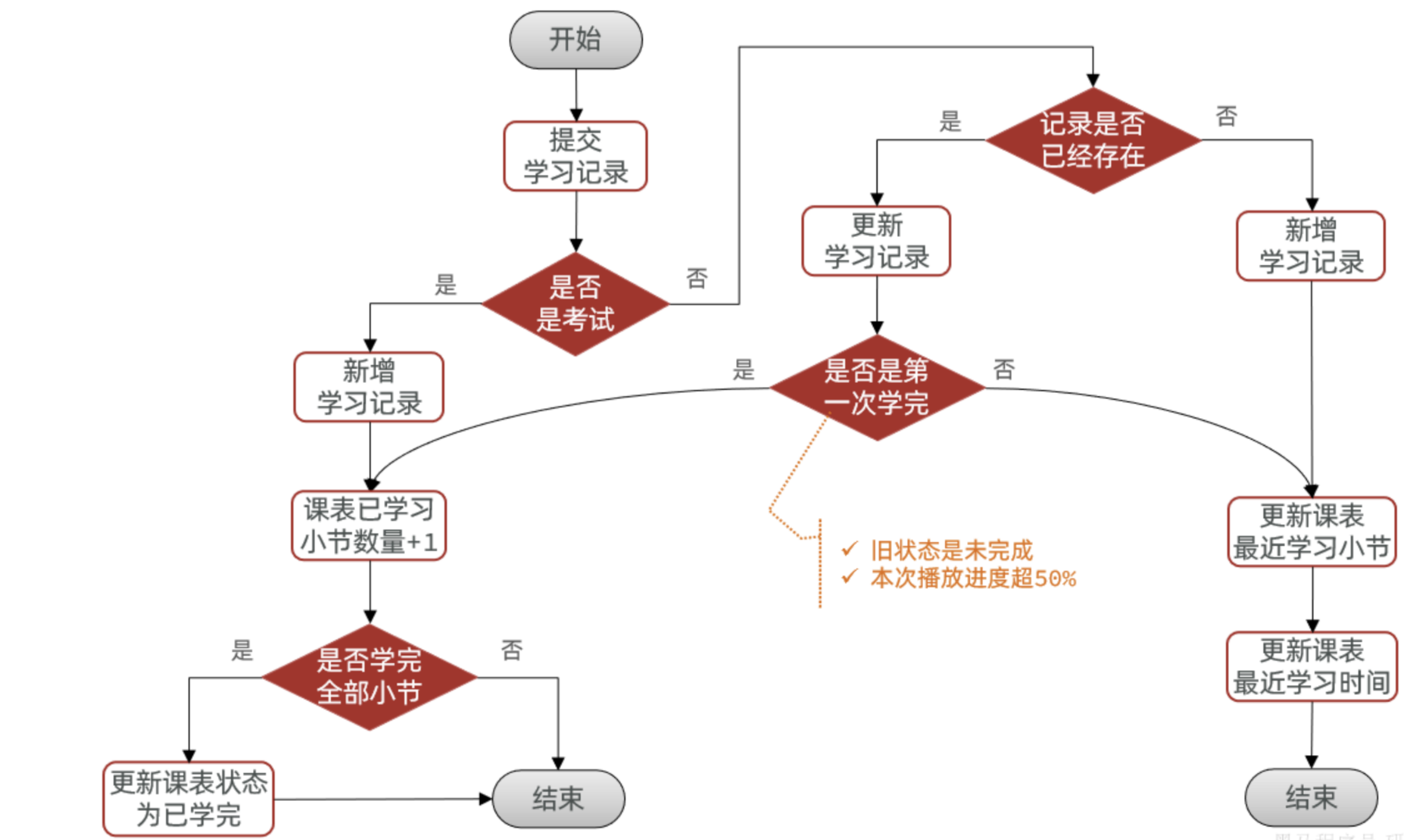
原业务逻辑图:
分析接口调用逻辑 :
我们知道的是这个接口是用来完成事实跟踪用户的学习小节进度从而提升用户的体验,但是我们知道这个接口的调用是非常的频繁的由课程视频老师所说大概是15s左右一次,但是我们简单的去看一下上面的业务逻辑图,便会想到每次调用都要执行上面的逻辑,这样带来的弊端:在并发较高的情况下,会给数据库带来非常大的压力。
2、优化方案
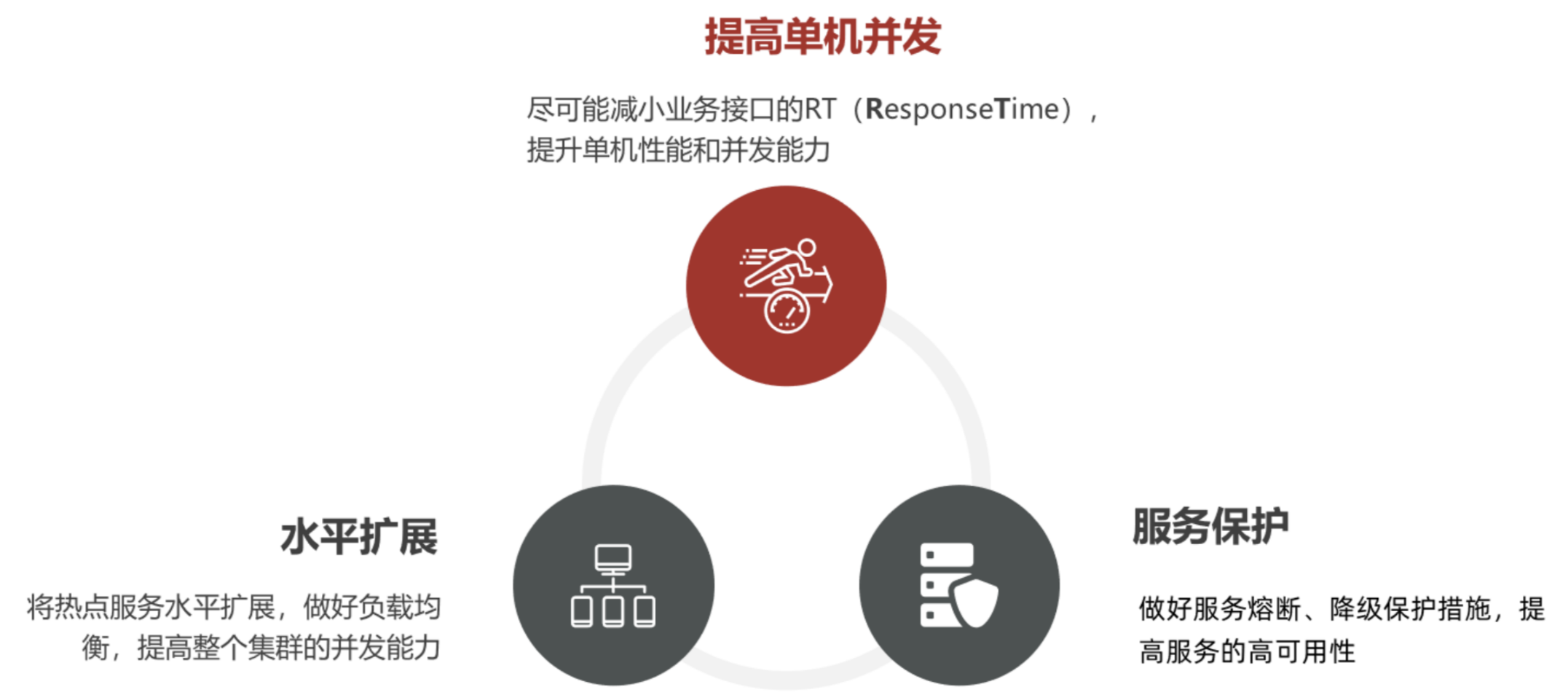
2.1 高并发优化宏观方向
- 提高单机并发:减少接口RT(Response Time),提升单个服务器的处理能力。
- 水平扩展:通过增加服务器数量,分散压力,提升集群整体并发能力。
- 服务保护:保障系统可用性,防止级联故障,提高服务韧性。
三方案协同工作示例
假设电商秒杀场景:
- 单机优化:
- Redis缓存商品库存
- 内存队列处理订单
- 本地缓存用户信息- 水平扩展:
- 秒杀服务部署10个实例
- Nginx负载均衡分发请求
- Redis集群承载高并发读- 服务保护:
- 熔断:库存服务失败时熔断
- 降级:秒杀失败返回友好提示
- 限流:入口限流10000QPS
- 排队:请求进入消息队列缓冲
实际部署架构图
客户端 → CDN → 网关层 → 负载均衡层 → 业务服务层 → 数据层 ↓ ↓ ↓ ↓ 限流熔断 流量分发 水平扩展 主从分离 降级保护 会话保持 无状态化 读写分离 健康检查 服务发现 分库分表
这三个方案通常按序实施:先优化单机 → 再水平扩展 → 最后服务保护,形成完整的高并发体系。
其中,水平扩展和服务保护侧重的是运维层面的处理。 而提高单机并发能力侧重的则是业务层面的处理,也就是我们程序员在开发时可以做到的。因此我们重点讨论如何通过编码来提供业务的单机并发能力。
2.1.1 单机并发优化
在机器性能一定的情况下,提高单机并发能力就是要尽可能缩短业务的响应时间(ResponseTime),而对响应时间影响最大的往往是对数据库的操作。而从数据库角度来说,我们的业务无非就是读或写两种类型:
- 对于读多写少的业务,其优化手段大家都比较熟悉了,主要包括两方面:
- 优化代码和SQL
- 添加缓存
- 对于写多读少的业务,大家可能较少碰到,优化的手段可能也不太熟悉,这也是我们要讲解的重点。
对于高并发写的优化方案有:
- 优化代码及SQL
- 变同步写为异步写
- 合并写请求
代码和SQL优化与读优化类似,我们就不再赘述了,接下来我们着重分析一下变同步为异步、合并写请求两种优化方案。
2.1.2 变同步为异步
假如一个业务比较复杂,需要有多次数据库的写业务,如图所示:
由于各个业务之间是同步串行执行,因此整个业务的响应时间就是每一次数据库写业务的响应时间之和,并发能力肯定不会太好。
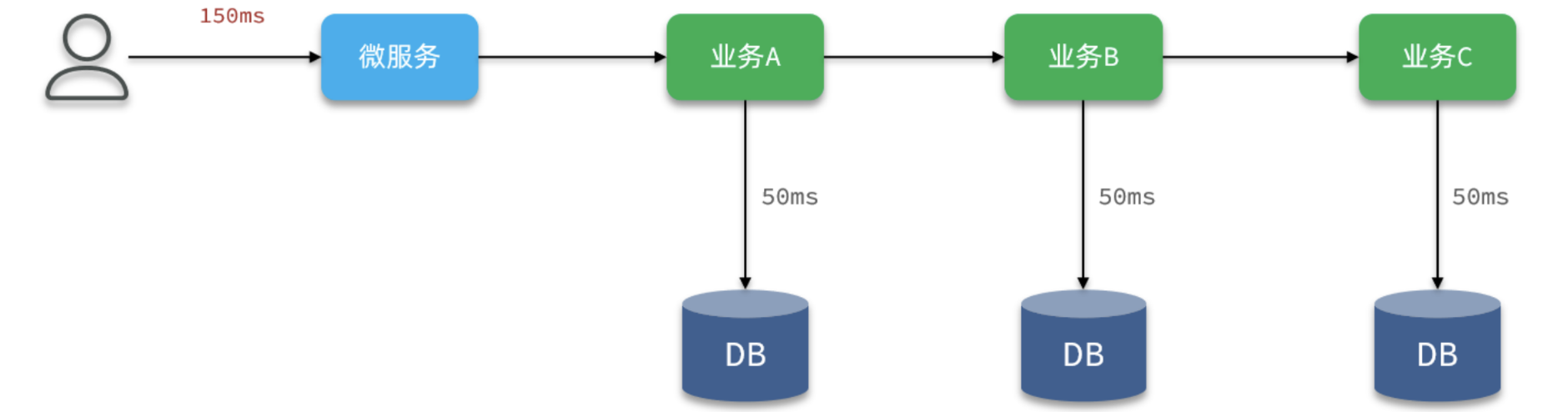
优化的思路很简单,我们之前讲解MQ的时候就说过,利用MQ可以把同步业务变成异步,从而提高效率。
- 当我们接收到用户请求后,可以先不处理业务,而是发送MQ消息并返回给用户结果。
- 而后通过消息监听器监听MQ消息,处理后续业务。
如图:
这样一来,用户请求处理和后续数据库写就从同步变为异步,用户无需等待后续的数据库写操作,响应时间自然会大大缩短。并发能力自然大大提高。
![[图片]](https://i-blog.csdnimg.cn/direct/3852ac1ea5014cdea90814d426debe1e.png)
优点:
- 无需等待复杂业务处理,大大减少响应时间
- 利用MQ暂存消息,起到流量削峰整形作用
- 降低写数据库频率,减轻数据库并发压力
缺点:
- 依赖于MQ的可靠性
- 降低了些频率,但是没有减少数据库写次数
应用场景:
- 比较适合应用于业务复杂, 业务链较长,有多次数据库写操作的业务。
2.1.3 合并写请求
合并写请求方案其实是参考高并发读的优化思路:
当读数据库并发较高时,我们可以把数据缓存到Redis,这样就无需访问数据库,大大减少数据库压力,减少响应时间。
既然读数据可以建立缓存,那么写数据可以不可以也缓存到Redis呢?
答案是肯定的,合并写请求就是指当写数据库并发较高时,不再直接写到数据库。而是先将数据缓存到Redis,然后定期将缓存中的数据批量写入数据库。
如图:
由于Redis是内存操作,写的效率也非常高,这样每次请求的处理速度大大提高,响应时间大大缩短,并发能力肯定有很大的提升。
而且由于数据都缓存到Redis了,积累一些数据后再批量写入数据库,这样数据库的写频率、写次数都大大减少,对数据库压力小了非常多!
![[图片]](https://i-blog.csdnimg.cn/direct/5e8469e1a47c439d8d1a7f67e38486b5.png)
优点:
- 写缓存速度快,响应时间大大减少
- 降低数据库的写频率和写次数,大大减轻数据库压力
缺点:
- 实现相对复杂
- 依赖Redis可靠性
- 不支持事务和复杂业务
场景:
- 写频率较高、写业务相对简单的场景
2.2 播放进度并发优化
2.2.1 优化方向选择
通过阅读上面的优化方案,我们接下啦要思考我们这个业务逻辑适合那个?
- 首先我们大致分析需要优化的部分有哪些?
首先我们先分析考试和视频两个方向是否都需要优化?
分析考试: 考试它本一般只会执行一次考试结束变更新状态即可,所以它不需要
分析视频: 前端每隔15秒就提交一次请求。在一个视频播放的过程中,可能有数十次请求,但完播(进度超50%)的请求只会有一次。因此多数情况下都是更新一下播放进度即可。**- 分析适合的优化方案:
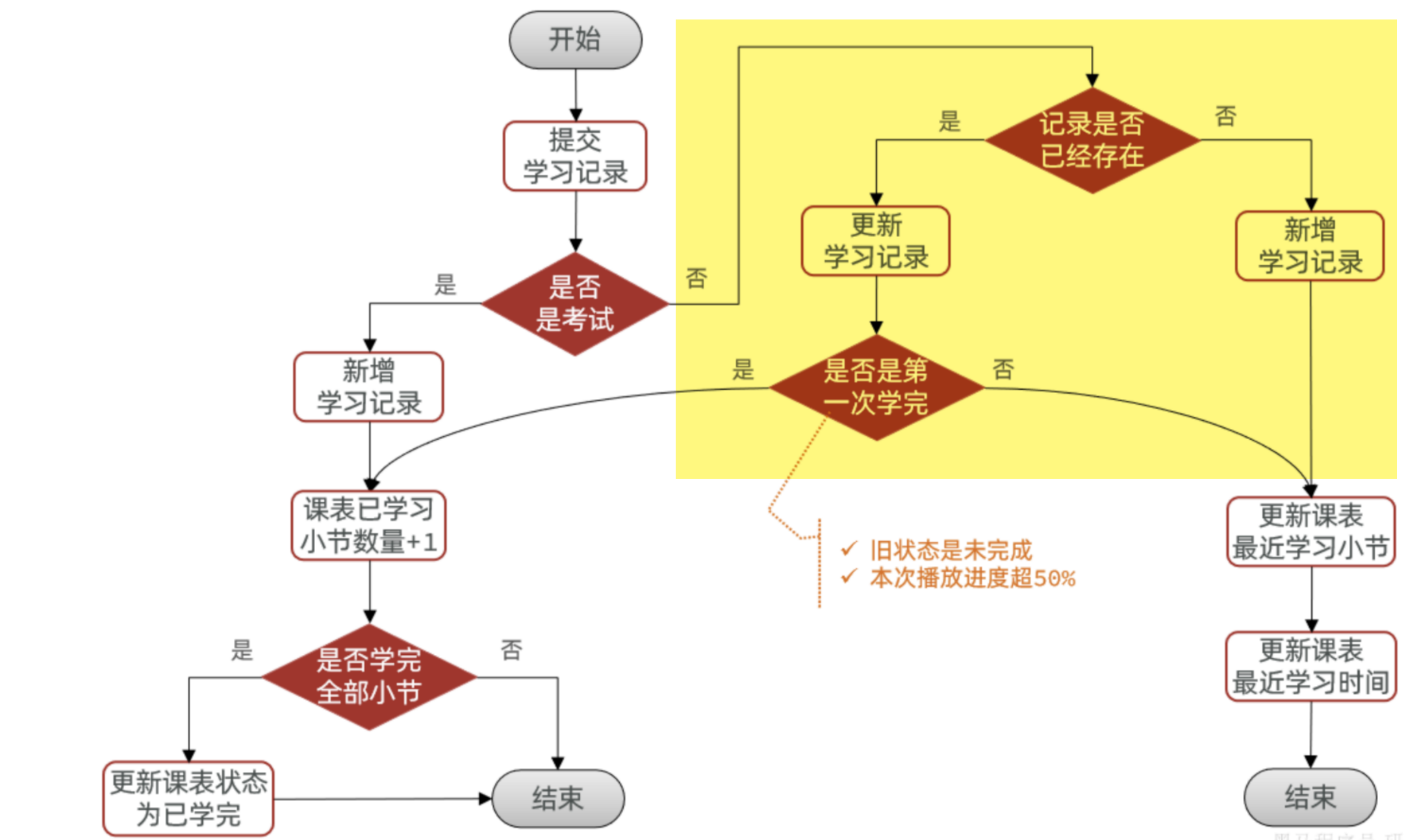
我们先将需要优化的部分标注出来:
我们先想一下这一部分是在做什么?
它其实就是在 更新学习记录:更新learning_record表中的moment字段learning_lesson表中的 小节id 和 时间
也就是说它每次请求都需要更新这几个字段,也就是大量简单的写请求。由此我们得出:提交播放进度业务虽然看起来复杂,但大多数请求的处理很简单,就是更新播放进度。并且播放进度数据是可以合并的(覆盖之前旧数据)。我们建议采用合并写请求方案:
2.2.2 redis数据结构设计
2.2.3 持久化思路
对于合并写请求方案,一定有一个步骤就是持久化缓存数据到数据库。一般采用的是定时任务持久化:
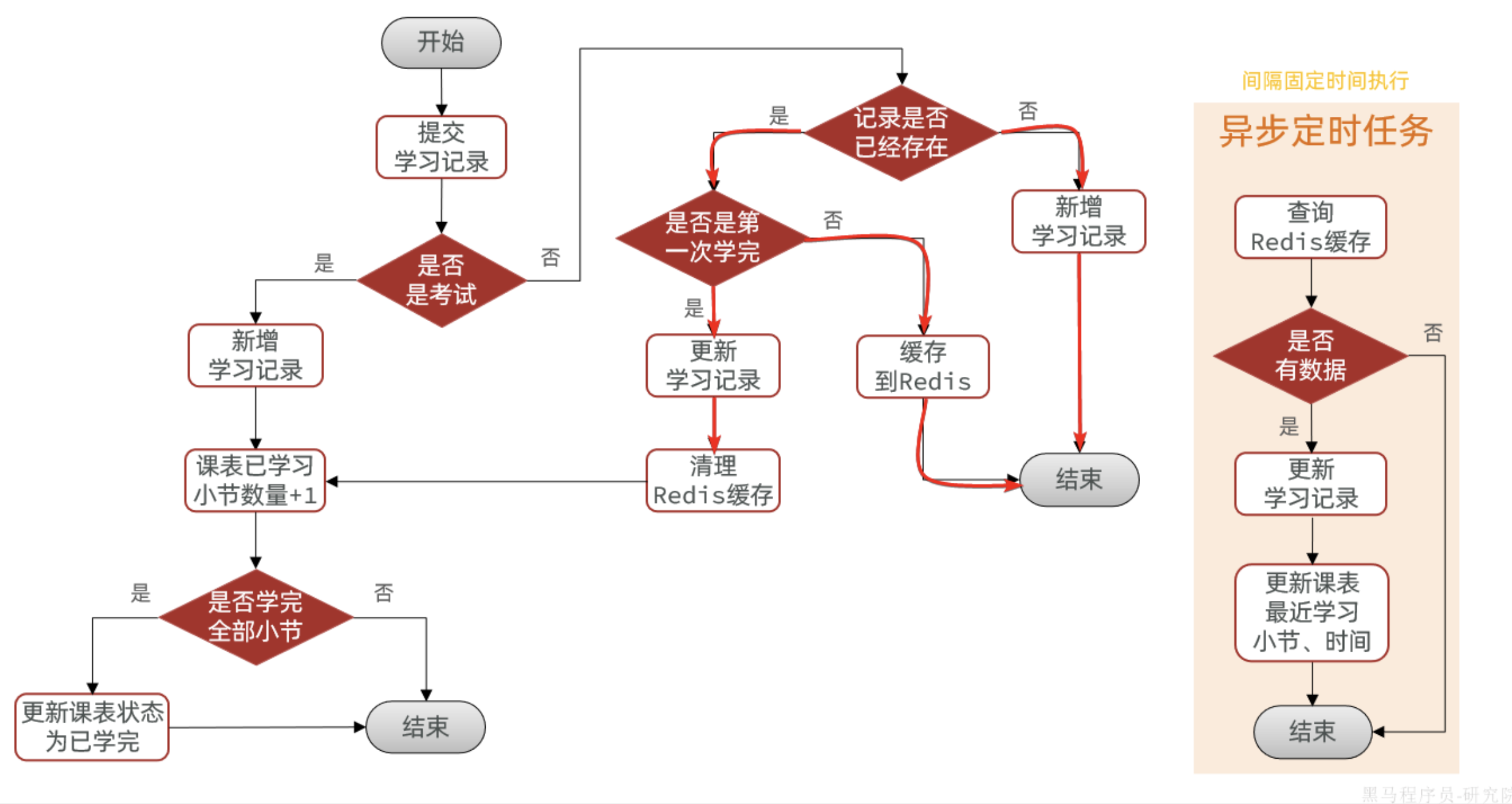
但是定时任务的持久化方式在播放进度记录业务中存在一些问题,主要就是时效性问题。我们的产品要求视频续播的时间误差不能超过30秒。
- 假如定时任务间隔较短,例如20秒一
次,对数据库的更新频率太高,压力太大- 假如定时任务间隔较长,例如2分钟一次,更新频率较低,续播误差可能超过2分钟,不满足需求
注意:
如果产品对于时间误差要求不高,定时任务处理是最简单,最可靠的一种方案,推荐大家使用。
那么问题来了,有什么办法能够在不增加数据库压力的情况下,保证时间误差较低吗?
- 假如一个视频时长为20分钟,我们从头播放至15分钟关闭,
每隔15秒提交一次播放进度,大概需要提交60次请求。但是下一次我们再次打开该视频续播的时候,
肯定是从最后一次提交的播放进度来续播。也就是说续播进度之前的N次播放进度都是没有意义的,
都会被覆盖。 既然如此,我们完全没有必要定期把这些播放进度写到数据库,
只需要将用户最后一次提交的播放进度写入数据库即可。
- 但问题来了,我们怎么知道哪一次提交是最后一次提交呢?
只要用户一直在提交记录,Redis中的播放进度就会一直变化。
如果Redis中的播放进度不变,肯定是停止了播放,是最后一次提交。
因此,我们只要能判断Redis中的播放进度是否变化即可。
- 怎么判断呢?
每当前端提交播放记录时,我们可以设置一个延迟任务并保存这次提交的进度。
等待20秒后(因为前端每15秒提交一次,20秒就是等待下一次提交),
检查Redis中的缓存的进度与任务中的进度是否一致。
- 不一致:说明持续在提交,无需处理
- 一致:说明是最后一次提交,更新学习记录、更新课表最近学习小节和时间到数据库中
流程如下:
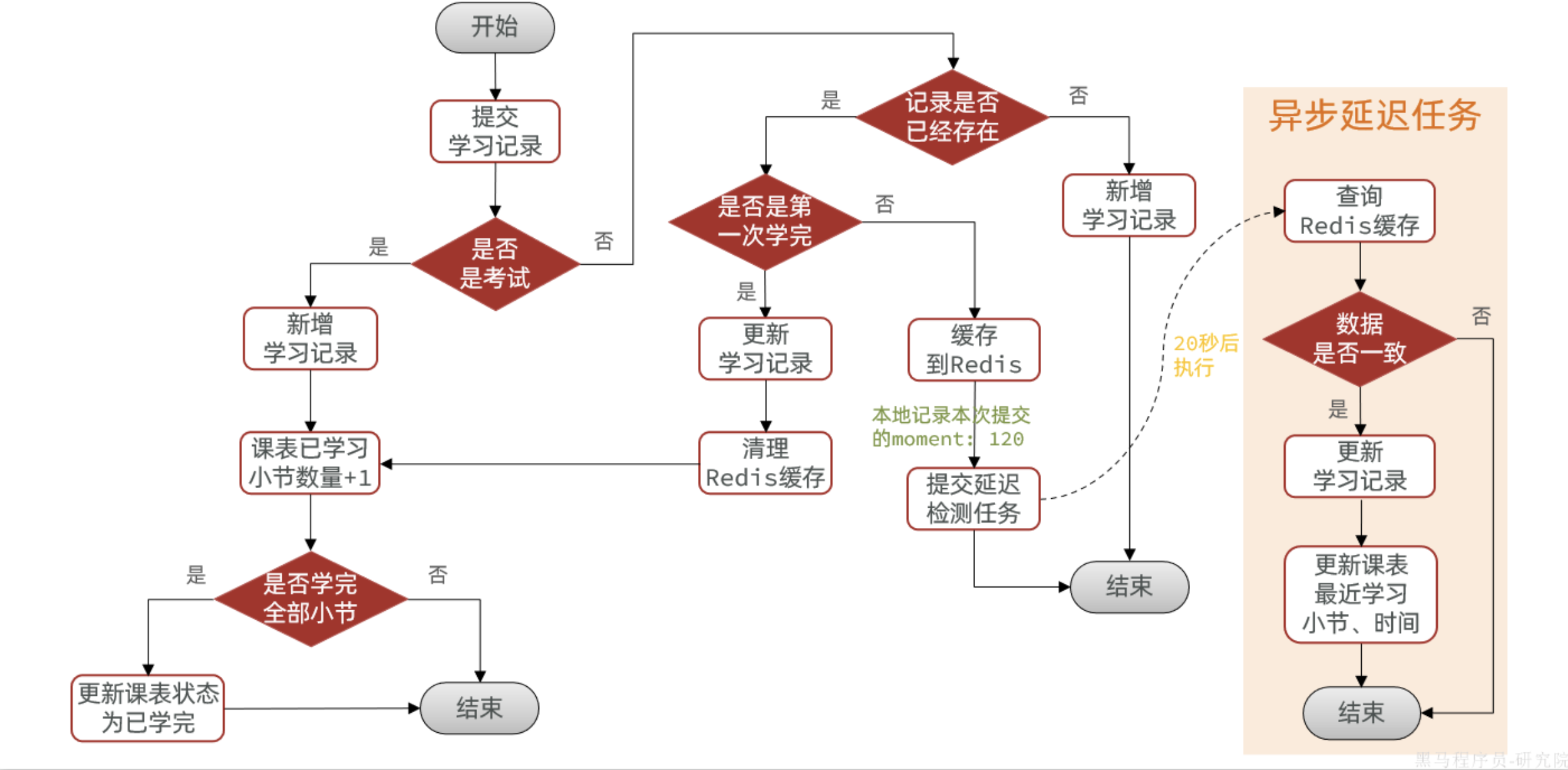
参考 《天机学堂飞书笔记》
二、优化业务逻辑工具代码编写
1、创建定时任务工具
1.1 代码编写
package com.tianji.learning.untils;
import lombok.Data;
import org.redisson.api.RDelayedQueue;
import java.time.Duration;
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;
@Data
public class DelayedTask<D> implements Delayed {
/*执行任务所需数据*/
private D data;
/*每个任务执行的时间(纳秒)*/
private long deadlineNanos;
/**
* 由延迟时间加上System.nanoTime()即可算出任务执行的时间:deadlineNanos
*
* @param data
* @param delayTime 延迟时间
*/
public DelayedTask(D data, Duration delayTime) {
this.data = data;
this.deadlineNanos = delayTime.toNanos() + System.nanoTime();
}
/**
* 获取剩余时间
*
* @param unit 时间工具
* @return 要按照它提供的 unit 时间工具进行时间转换方法返回剩余时间
*/
@Override
public long getDelay(TimeUnit unit) {
//Math.max(a,b):比较两个值的最大值的绝对值
return unit.convert(Math.max(0, deadlineNanos - System.nanoTime()), TimeUnit.NANOSECONDS);
}
@Override
public int compareTo(Delayed o) {
long l = getDelay(TimeUnit.NANOSECONDS) - o.getDelay(TimeUnit.NANOSECONDS);
if (l > 0) {
return 1;
} else if (l == 0) {
return 0;
} else {
return -1;
}
}
}
1.1.1 System.nanoTime()是什么?
System.nanoTime():从 任意时间 点开始到现在的纳秒时间,但在 一个jvm进程中 它们的 起点是相同 的,所以一般是用来做相对时间的 精确 计算与比较,因为是纳秒级所以会比较精确
Jvm进程是什么?:
- 他是一个java命令启动
- 一个main方法对应一个JVM进程入口(一个JVM可以执行多个main方法)
- 微服务架构中,每个服务是一个JVM进程
| 概念 | 是什么 | 类比 | 关键特点 |
|---|---|---|---|
| 进程 | 操作系统分配资源的基本单位 | 独立的工厂 | 有独立内存空间,进程间隔离 |
| JVM | Java 虚拟机,执行 Java 字节码 | 翻译官 + 管家 | 跨平台,自动内存管理 |
| JVM 进程 | 运行 JVM 的操作系统进程 | 安装了特定机器的工厂 | 一个进程里运行着 JVM |
| 线程 | 进程内的执行单元 | 工厂里的工人 | 共享进程内存,切换开销小 |
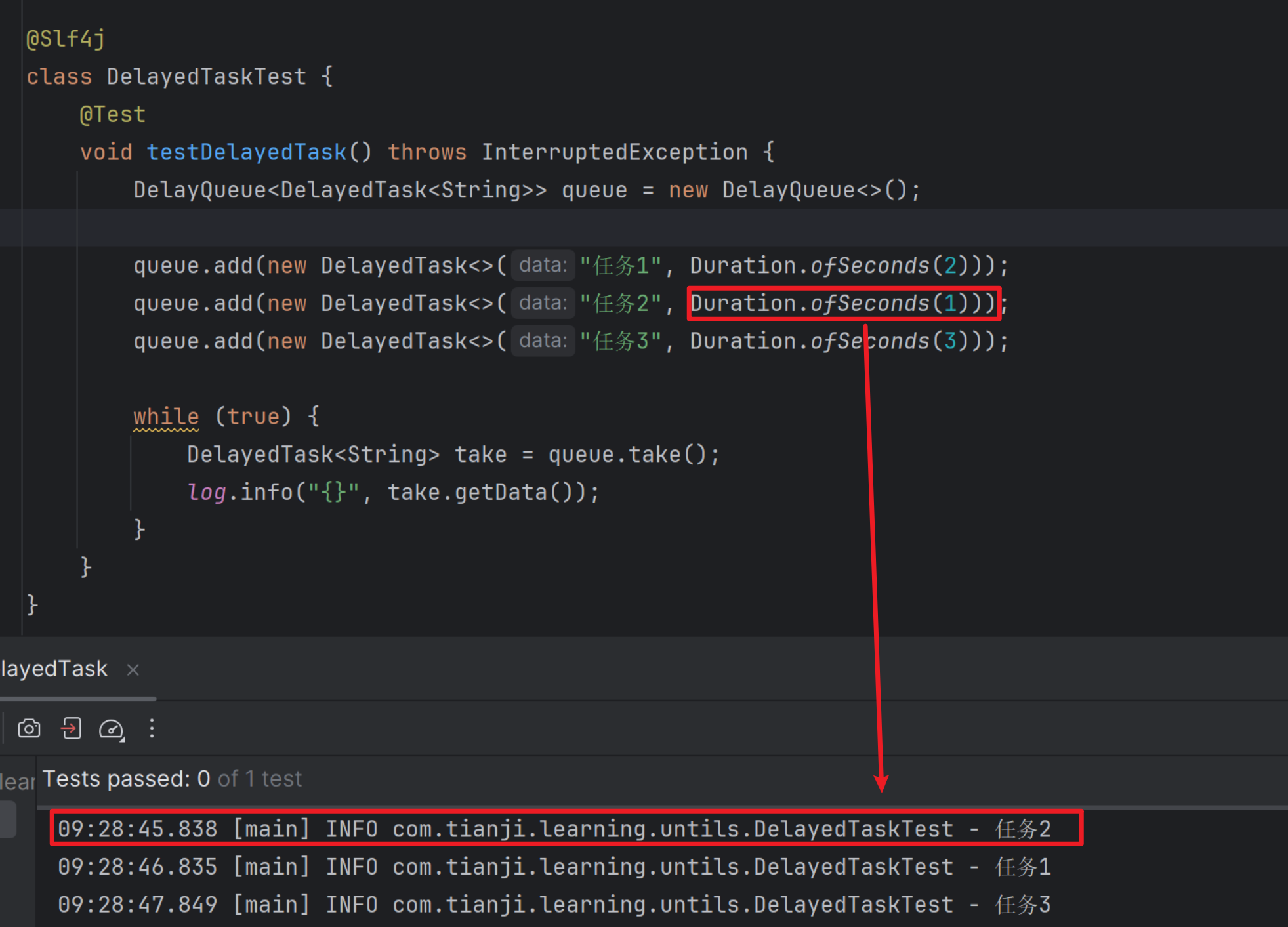
1.2 测试延时工具
这里我们可以看到执行顺序是:
任务2->任务1->任务3 ,刚好对应着延迟时间:Duration.ofSeconds(1) -> (2)-> (3)
2、创建学习记录延迟任务的工具
2.1 代码编写
package com.tianji.learning.untils;
import com.tianji.common.utils.JsonUtils;
import com.tianji.common.utils.ObjectUtils;
import com.tianji.common.utils.StringUtils;
import com.tianji.learning.domain.po.LearningLesson;
import com.tianji.learning.domain.po.LearningRecord;
import com.tianji.learning.mapper.LearningRecordMapper;
import com.tianji.learning.service.LearningLessonService;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.time.Duration;
import java.time.LocalDateTime;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.DelayQueue;
/**
* 学习记录延迟任务的工具
*/
@Slf4j
@RequiredArgsConstructor
@Component
public class LearningRecordDelayTaskHandler {
private final StringRedisTemplate redisTemplate;
/*存放到redis中的key值:这里我们使用的是opsForHash类型存放,也就是:map(key,map(key,value))*/
private final static String RECORD_KEY_TEMPLATE = "learning:record:{}";
/*创建延迟队列,存放延迟任务*/
private final DelayQueue<DelayedTask<LearningRecordData>> queue = new DelayQueue<>();
private final LearningRecordMapper recordMapper;
private final LearningLessonService lessonService;
public static volatile boolean taskStart = true;
/**
容器关闭后执行
*/
@PreDestroy
public void destroy() {
taskStart = false;
log.info("延迟任务停止执行");
}
/**
* Spring容器启动
* ↓
* 创建Bean实例(调用构造方法)
* ↓
* 注入依赖(@Autowired, @Value等)
* ↓
* 执行@PostConstruct方法 ← 初始化
* ↓
* Bean准备就绪,可以被使用
* ↓
* 应用运行...
* ↓
* 容器关闭
* ↓
* 执行@PreDestroy方法 ← 这里清理
* ↓
* Bean被销毁
*/
/*启动spring容器之后等Bean创建完,并注入完依赖之后,执行初始化*/
@PostConstruct
public void init() {
/*异步执行延迟任务*/
CompletableFuture.runAsync(this::handleDaleyTask);
}
public void handleDaleyTask() {
while (taskStart) {
try {
/*1、获取延迟任务*/
DelayedTask<LearningRecordData> take = queue.take();
LearningRecordData data = take.getData();
/*2、查询redis缓存*/
LearningRecord record = readRecordCache(data.getLessonId(), data.getSectionId());
/*没有查找到数据跳过当前延迟任务*/
if (record == null) continue;
/*3、对比moment值是否相同*/
/*不同:说明用户还在播放视频,放弃旧数据*/
if (!ObjectUtils.equal(data.getMoment(),record.getMoment())) continue;
/*相同:持久化缓存播放进度*/
/*更新学习记录*/
record.setFinished(null);
recordMapper.updateById(record);
/*更新课表最近学习小节、时间*/
LearningLesson learningLesson = new LearningLesson();
learningLesson.setId(data.getLessonId());
learningLesson.setLatestSectionId(data.getSectionId());
learningLesson.setLatestLearnTime(LocalDateTime.now());
lessonService.updateById(learningLesson);
} catch (Exception e) {
log.error("延迟任务执行异常:", e);
}
}
}
/**
* 添加延迟任务到队列
* @param record 数据
*/
public void addLearningRecordTask(LearningRecord record) {
log.info("更新学习记录的缓存数据");
try {
/*写入记录到缓存*/
writeRecordCache(record);
/*添加延迟任务到队列中*/
queue.add(new DelayedTask<>(
new LearningRecordData(record)
/*延迟20s之后执行*/
/*因为这里前端会以15s为间隙,理论上不可能在20s后还在继续播放,除非用户暂停或者退出播放了(当然也不排除网络延迟的可能)*/
,Duration.ofSeconds(20)
));
} catch (Exception e) {
log.error("更新学习记录的缓存数据异常,", e);
}
}
/**
* 写入记录到缓存
* @param record
*/
public void writeRecordCache(LearningRecord record) {
log.debug("更新学习记录的缓存数据");
try {
/*数据转换:HashValue*/
String hValue = JsonUtils.toJsonStr(new RecordCacheData(record));
/*写入redis*/
String key = StringUtils.format(RECORD_KEY_TEMPLATE,
record.getLessonId().toString());
redisTemplate.opsForHash().put(key,
record.getSectionId().toString(),
hValue);
/*添加过期时间*/
redisTemplate.expire(key, Duration.ofMinutes(1));
} catch (Exception e) {
log.error("更新学习记录缓存异常", e);
}
}
/**
* 读取学习记录缓存
* @param lessonId 课表id
* @param sectionId 小节id
* @return
*/
public LearningRecord readRecordCache(Long lessonId, Long sectionId) {
try {
/*获取数据*/
String key = StringUtils.format(RECORD_KEY_TEMPLATE, lessonId);
Object cacheData = redisTemplate.opsForHash()
.get(key,sectionId.toString());
/*缓存中没有此数据*/
if (cacheData == null) return null;
/*数据转换*/
return JsonUtils.toBean(cacheData.toString(), LearningRecord.class);
} catch (Exception e) {
log.error("缓存读取失败", e);
return null;
}
}
/**
* 删除学习记录缓存
* @param lessonId
* @param sectionId
*/
public void cleanRecordCache(Long lessonId, Long sectionId) {
redisTemplate.opsForHash().delete(
StringUtils.format(RECORD_KEY_TEMPLATE, lessonId),
sectionId.toString()
);
}
@Data
@NoArgsConstructor
/**
* 学习记录缓存数据:存放到缓存中供客户端调用提升效率
* id:学习记录id:用来充当标识作用
* moment:观看时长
* finished:是否是第一次完成
*/
public static class RecordCacheData {
private Long id;
private Integer moment;
private Boolean finished;
public RecordCacheData(LearningRecord record) {
this.id = record.getId();
this.moment = record.getMoment();
this.finished = record.getFinished();
}
}
@Data
@NoArgsConstructor
/**
* 学习记录数据:用来当延迟任务的数据,
* 可以通过这个数据找到对应的redis记录,
* 同时找到对应的小节和小节的观看时间点
* lessonId:课表id用来确定redis的记录
* sectionId:小节id用来确定当前opsForHash()记录中的那个hashKey
* moment:观看的时间点:用来去比较与原本的moment是否相同的
*/
public static class LearningRecordData {
private Long lessonId;
private Integer moment;
private Long sectionId;
public LearningRecordData(LearningRecord record) {
this.lessonId = record.getLessonId();
this.moment = record.getMoment();
this.sectionId = record.getSectionId();
}
}
}
三、改造原代码
1、代码展示
package com.tianji.learning.service.impl;
import cn.hutool.core.date.DateTime;
import cn.hutool.db.DbRuntimeException;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.tianji.api.client.course.CourseClient;
import com.tianji.api.dto.course.CourseFullInfoDTO;
import com.tianji.api.dto.leanring.LearningLessonDTO;
import com.tianji.api.dto.leanring.LearningRecordDTO;
import com.tianji.api.dto.leanring.LearningRecordFormDTO;
import com.tianji.common.exceptions.BizIllegalException;
import com.tianji.common.utils.BeanUtils;
import com.tianji.common.utils.UserContext;
import com.tianji.learning.domain.po.LearningLesson;
import com.tianji.learning.domain.po.LearningRecord;
import com.tianji.learning.enums.LessonStatus;
import com.tianji.learning.enums.SectionType;
import com.tianji.learning.service.LearningLessonService;
import com.tianji.learning.service.LearningRecordService;
import com.tianji.learning.mapper.LearningRecordMapper;
import com.tianji.learning.untils.LearningRecordDelayTaskHandler;
import lombok.RequiredArgsConstructor;
import org.bouncycastle.asn1.DERTaggedObject;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.Date;
import java.util.List;
/**
* @author Huawei
* @description 针对表【learning_record(学习记录表)】的数据库操作Service实现
* @createDate 2025-11-26 08:23:48
*/
@Service
@RequiredArgsConstructor
public class LearningRecordServiceImpl extends ServiceImpl<LearningRecordMapper, LearningRecord>
implements LearningRecordService {
private final CourseClient courseClient;
private final LearningLessonService lessonService;
private final LearningRecordDelayTaskHandler taskHandler;
@Override
@Transactional
public void addLearningRecord(LearningRecordFormDTO recordFormDTO) {
Long user = UserContext.getUser();
/*学习记录*/
//1、判断是否是考试?
boolean ifExam = recordFormDTO.getSectionType() == SectionType.EXAM.getValue();
boolean finished = false;
if (ifExam) {
//是:新增学习记录
finished = handleExamRecord(user, recordFormDTO);
} else {
//否:更新/新增学习记录
finished = handleVideoRecord(user, recordFormDTO);
}
/*课表*/
//2、判断是否是 “第一次” 学完
//否:所以执行视频的课表逻辑(更新:最近学习小节、学习时间)
/*因为上面已经处理了不是第一次完成的更新,也就是延迟任务所执行的操作,
所以这里只要不是第一次完成便直接返回即可*/
if (!finished) return;
/*那这里只可能是第一次完成了:*/
//是:执行更新课表逻辑:课表已学习+1、
//判断是否学完全部小节? 更新课表学习状态 : END
handleLearningLession(recordFormDTO);
}
/**
* 添加课表记录
*
* @param recordFormDTO
*/
private void handleLearningLession(LearningRecordFormDTO recordFormDTO) {
//1、查询课表
LearningLesson lesson = lessonService.getById(recordFormDTO.getLessonId());
if (lesson == null) {
throw new BizIllegalException("查询不到课表");
}
Boolean allLearning = false;
//3、查询课程信息
CourseFullInfoDTO cInfoById = courseClient
.getCourseInfoById(lesson.getCourseId(), false, false);
if (cInfoById == null) {
throw new BizIllegalException("查询不到课程");
}
//4、比较全部小节是否全部学完:以学习课程数+1>=课程总数
allLearning = lesson.getLearnedSections() + 1 >= cInfoById.getSectionNum();
//5、更新课表
lessonService.lambdaUpdate()
.eq(LearningLesson::getId, lesson.getId())
/*第一次学习(判断条件:moment是否等于0),将学习状态从0(未学习)->1(学习中)*/
.set(recordFormDTO.getMoment() == 0,
LearningLesson::getStatus,
LessonStatus.LEARNING.getValue())
/*若是学习完本节,更改学习状态*/
.set(allLearning, LearningLesson::getStatus, LessonStatus.FINISHED.getValue())
/*修改已学习数量*/
.setSql("learned_sections = learned_sections + 1")
.update();
}
/**
* 新增/修改视频学习小节记录
*
* @param user
* @param recordFormDTO
* @return
*/
private boolean handleVideoRecord(Long user, LearningRecordFormDTO recordFormDTO) {
boolean finished = false;
LearningRecord old = queryOldRecord(recordFormDTO.getLessonId(),
recordFormDTO.getSectionId());
/*是否是第一次提交*/
if (old == null) {
LearningRecord learningRecord = BeanUtils.copyBean(recordFormDTO, LearningRecord.class);
learningRecord.setUserId(user);
if (!save(learningRecord)) {
throw new DbRuntimeException("添加视频学习记录失败");
}
return finished;
} else {
/*判断是否是第一次完成学习*/
finished = !old.getFinished() &&
recordFormDTO.getMoment() * 2 >= recordFormDTO.getDuration();
/*若不是第一次学完,添加缓存并提交到延迟队列中*/
if (!finished) {
LearningRecord learningRecord = BeanUtils
.copyBean(recordFormDTO, LearningRecord.class);
learningRecord.setId(old.getId());
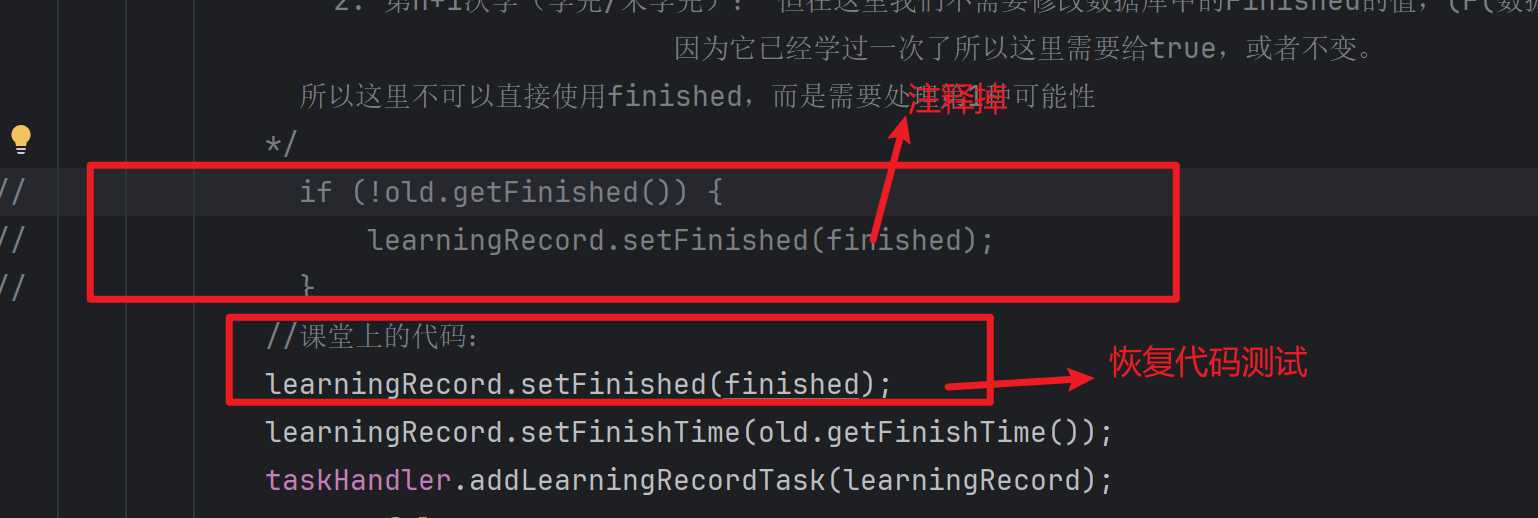
/*到这里有两种可能性:
1. 第一次学,但没有学完:这里应该为false,也与finished的值相同(F(数据库):false,f(变量):false)
2. 第n+1次学: 但在这里我们不需要修改数据库中的Finished的值,(F(数据库):t,f(变量):false/true)
因为它已经学过一次了所以这里需要给true,或者不变。
所以这里不可以直接使用finished,而是需要处理第1种可能性
*/
if (!old.getFinished()) {
learningRecord.setFinished(finished);
}
//课堂上的代码:
//learningRecord.setFinished(finished);
learningRecord.setFinishTime(old.getFinishTime());
taskHandler.addLearningRecordTask(learningRecord);
return false;
}
/*第一次学完:更新数据*/
boolean update = lambdaUpdate()
.eq(LearningRecord::getId, old.getId())
.set(LearningRecord::getMoment, recordFormDTO.getMoment())
.set(LearningRecord::getFinished, true)
.set(LearningRecord::getFinishTime, recordFormDTO.getCommitTime())
.update();
if (!update) {
throw new DbRuntimeException("更新视频学习记录失败");
}
/*清理缓存*/
taskHandler.cleanRecordCache(recordFormDTO.getLessonId(),
recordFormDTO.getSectionId());
return true;
}
}
/**
* 查询学习记录缓存,若没有命中则查询数据库,并更新缓存
* @param lessonId
* @param sectionId
* @return
*/
private LearningRecord queryOldRecord(Long lessonId, Long sectionId) {
/*1、查询缓存*/
LearningRecord learningRecord = taskHandler.readRecordCache(lessonId, sectionId);
/*2、若命中返回*/
if (learningRecord != null) {
return learningRecord;
}
/*3、若未命中查询数据库*/
LearningRecord old = lambdaQuery()
.eq(LearningRecord::getSectionId, sectionId)
.eq(LearningRecord::getLessonId, lessonId)
.one();
/*4、写入缓存*/
if (old != null) {
taskHandler.addLearningRecordTask(old);
}
return old;
}
/**
* 新增考试学习小节记录
*
* @param user
* @param recordFormDTO
* @return
*/
private boolean handleExamRecord(Long user, LearningRecordFormDTO recordFormDTO) {
LearningRecord learningRecord = BeanUtils.copyBean(recordFormDTO, LearningRecord.class);
learningRecord.setUserId(user);
learningRecord.setFinished(true);
boolean b = save(learningRecord);
if (!b) {
throw new DbRuntimeException("添加考试学习记录失败");
}
return true;
}
}
2、TIPS
1. 使用课堂上的代码时明明学过视频,但过半时还要执行更新数据?
测试课堂中的代码:
如果大家是跟着老师写的代码这里不用变,若是复制的上面的代码,那大家要想跟着测试,可以按照下面这个步骤:
启动之后我们直接可随便打开一个视频测试:
①:若是第一次学习,视频过半执行的代码
②:若是第n+1次学习,视频过半执行的代码
!!!注意!!!: 测试我们最好打断点,
在下面图片中的:第二部分(任意)、第三部分的update赋值部分打断点方便观查
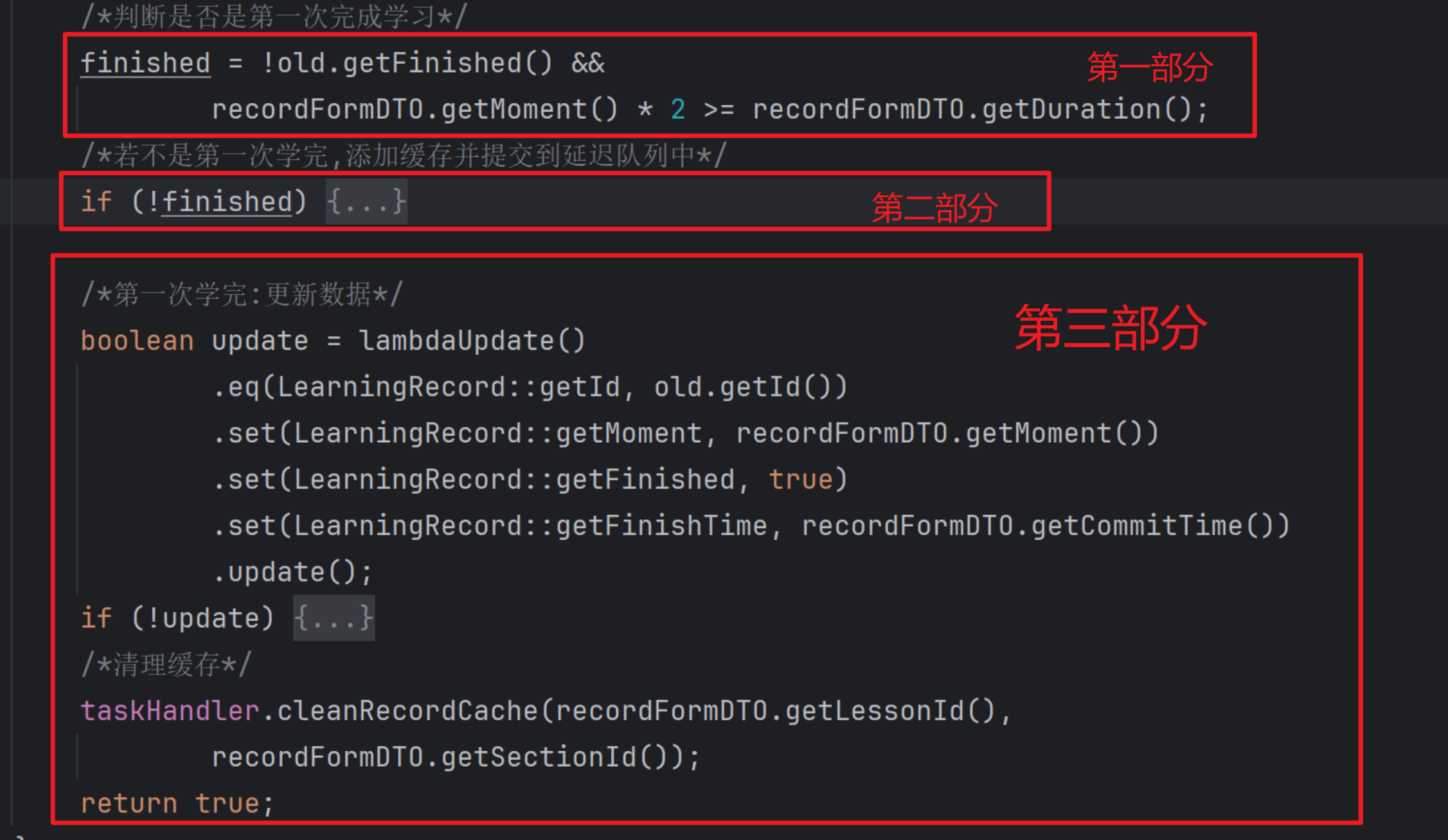
测试结果分析:
不管是
①:若是第一次学习,视频过半执行的代码还是②:若是第n+1次学习,视频过半执行的代码,可以发现都要执行第三部分。
刚刚执行完②这时我们可以看一下日志:
这里我们也可以很明显的看出它执行了第三部分
而我们仔细思考一下第三部分是做什么的?
很容易想到它是用来做第一次学完之后去更新数据的。
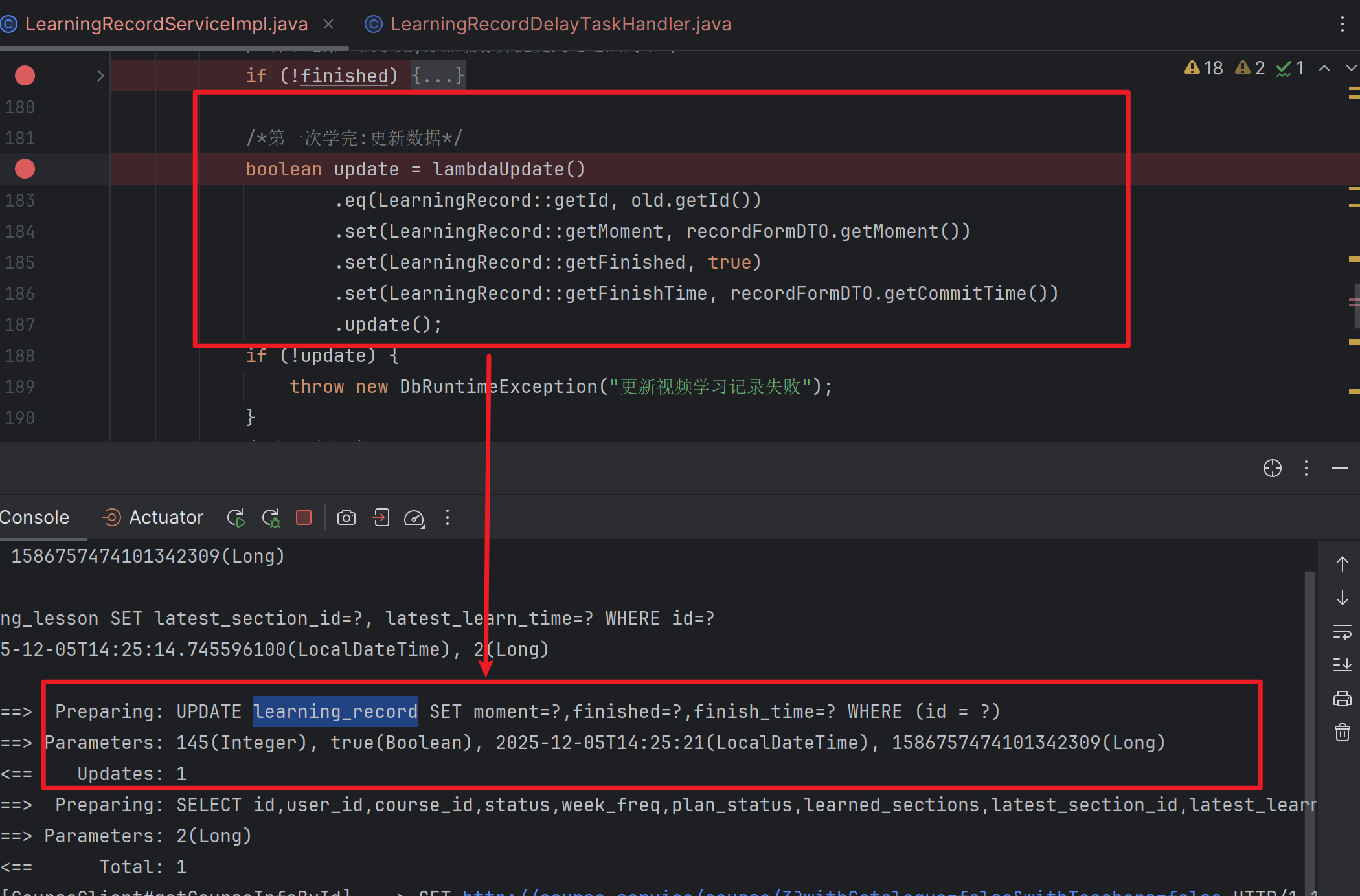
但是为什么
②为什么还会执行第三部分呢?
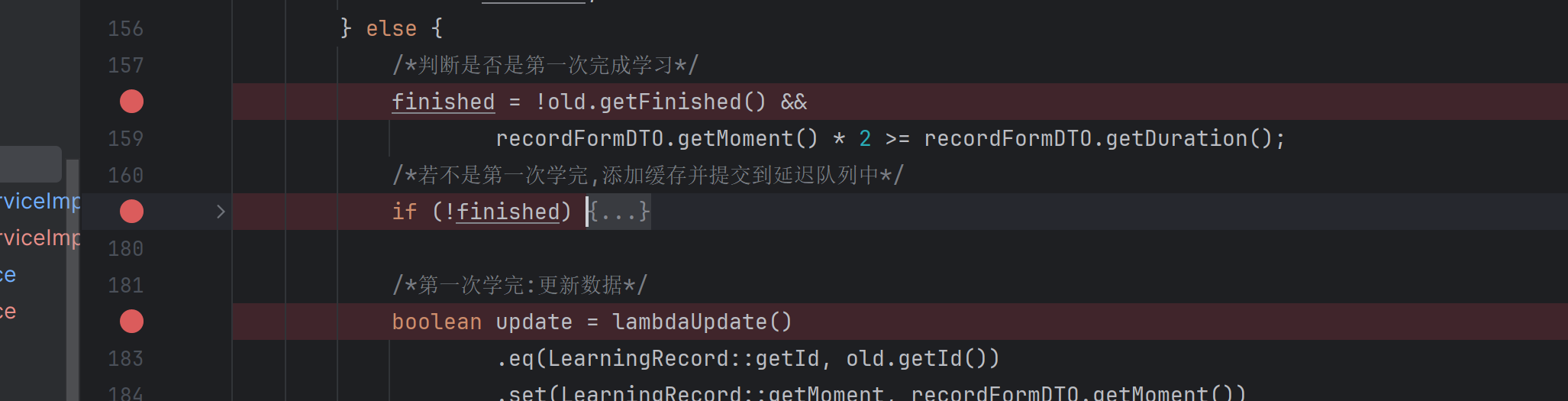
这时我们先在这三个部分打断点:
重新将视频进度拉到大于一半的位置(若是已经处于一般的位置的话,大家重新将进度拉到开始的位置,等发起一次http://api.tianji.com/ls/learning-records请求,在将进度拉到大于一半的位置),
进入断点之后可以看一下这参数的值:
得出的结论就是:我们还是第一次学习这一小节
这就很奇怪了,明明我们已经学过一次了为什么还是第一次呢?
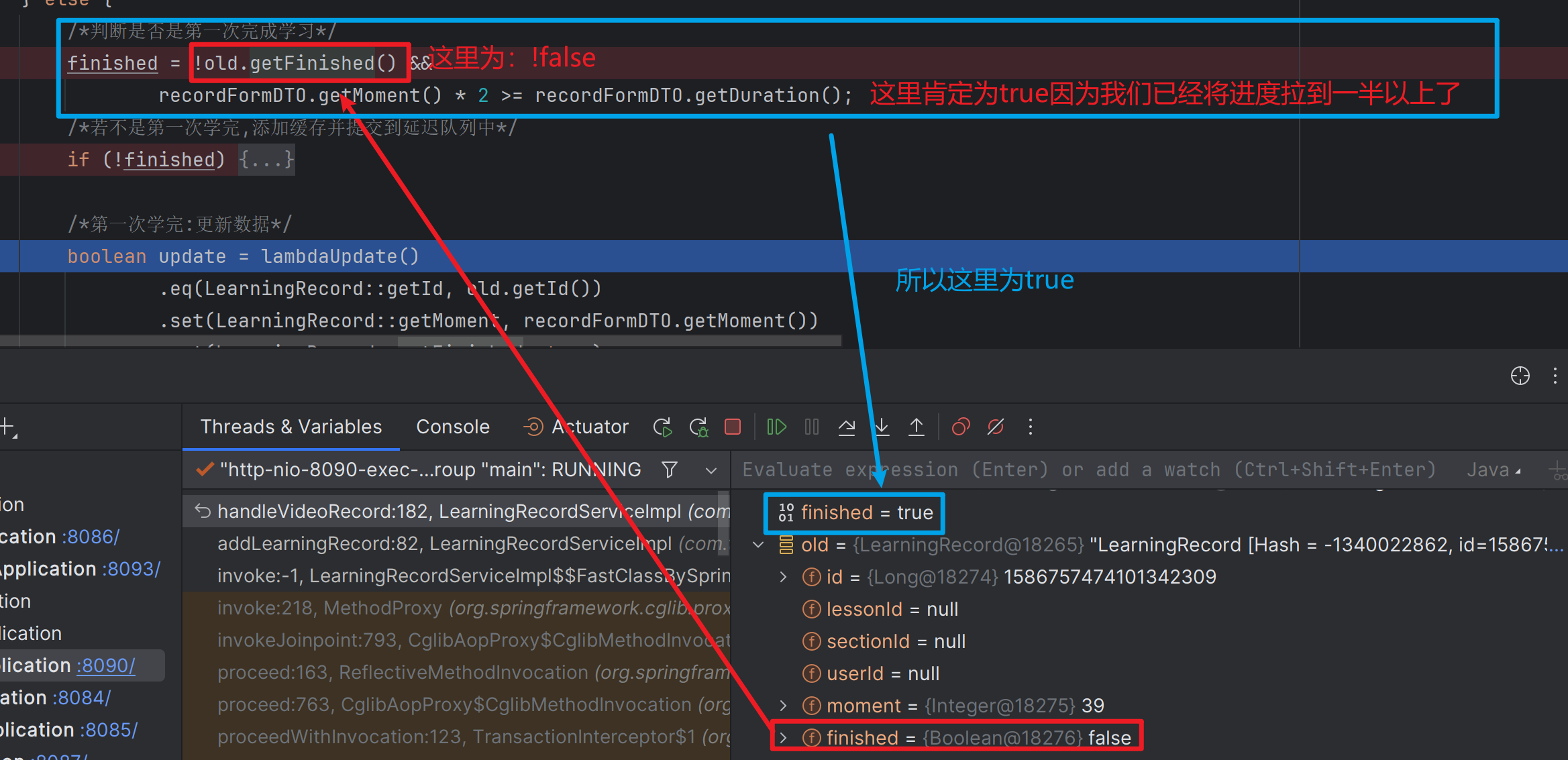
这时我们回去看一下第二部分的这段代码:
我们仔细分析一下这里有几种情况?:
- finished = ! F and T = F(视频学过,已学完本视频)
- finished = ! F and F = F(视频学过,未学完本视频)
- finished = ! F and F = F( 视频未学过,未学完本视频)
这几种情况我们都可以到
learningRecord.setFinished(finished);这段代码上,
这里我们可以将finished值代入进去分析是否合理
到这里我们分为两种可能性进行分析:
- 视频未学过,但没有学完:这里应该为false,也与finished的值相同(F(数据库):false,f(变量):false)
- 第n+1次学(学完/未学完): 但在这里我们不需要修改数据库中的Finished的值,(F(数据库):t,f(变量):false/true)
分析到这里问题就很明显了:
因为它已经学过一次了所以这里需要给true,或者不变(因为在第三部分我们已经修改状态了)。所以这里不可以直接使用finished,
而是只需要处理第1种可能性即可 或者 不处理也可以(因为默认值为false)
我这里为了突出这个错误所以进行多余的判断,大家也可以直接删掉:
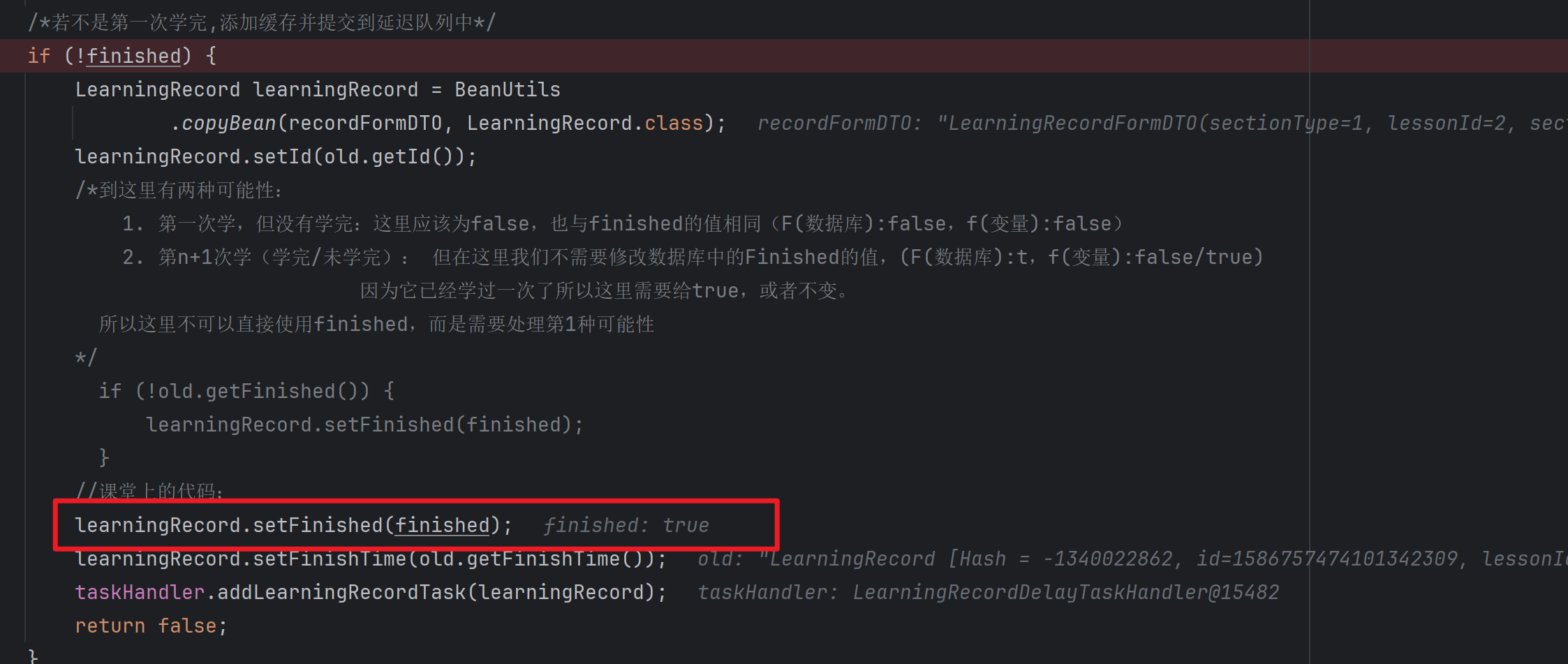
/*若不是第一次学完,添加缓存并提交到延迟队列中*/
if (!finished) {
LearningRecord learningRecord = BeanUtils
.copyBean(recordFormDTO, LearningRecord.class);
learningRecord.setId(old.getId());
/*到这里有两种可能性:
1. 第一次学,但没有学完:这里应该为false,也与finished的值相同(F(数据库):false,f(变量):false)
2. 第n+1次学(学完/未学完): 但在这里我们不需要修改数据库中的Finished的值,(F(数据库):t,f(变量):false/true)
因为它已经学过一次了所以这里需要给true,或者不变。
所以这里不可以直接使用finished,而是需要处理第1种可能性
*/
if (!old.getFinished()) {
learningRecord.setFinished(finished);
}
//课堂上的代码:
// learningRecord.setFinished(finished);
learningRecord.setFinishTime(old.getFinishTime());
taskHandler.addLearningRecordTask(learningRecord);
return false;
}
所以:需要将
learningRecord.setFinished(finished);给注释掉

















 1753
1753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









