




旨在利用多种机器学习算法实现对鸢尾花(Python自带的数据集)的分类。并使用加权准确率、加权精确率、加权召回率、加权F1—score和加权ROC-AUC等指标进行评价。并使用雷达图、柱状图等进行展示。
废话不多说先上结果图:
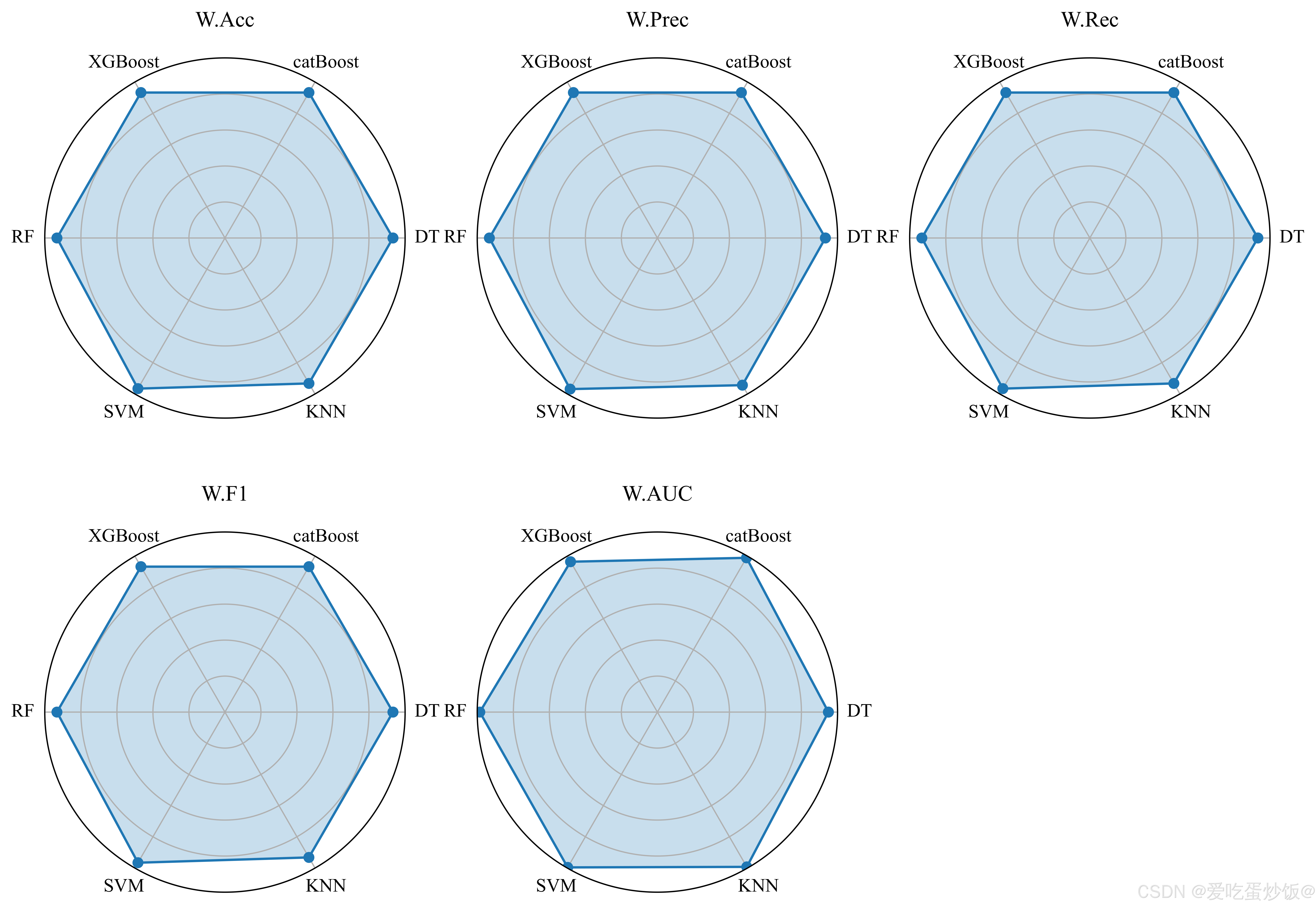
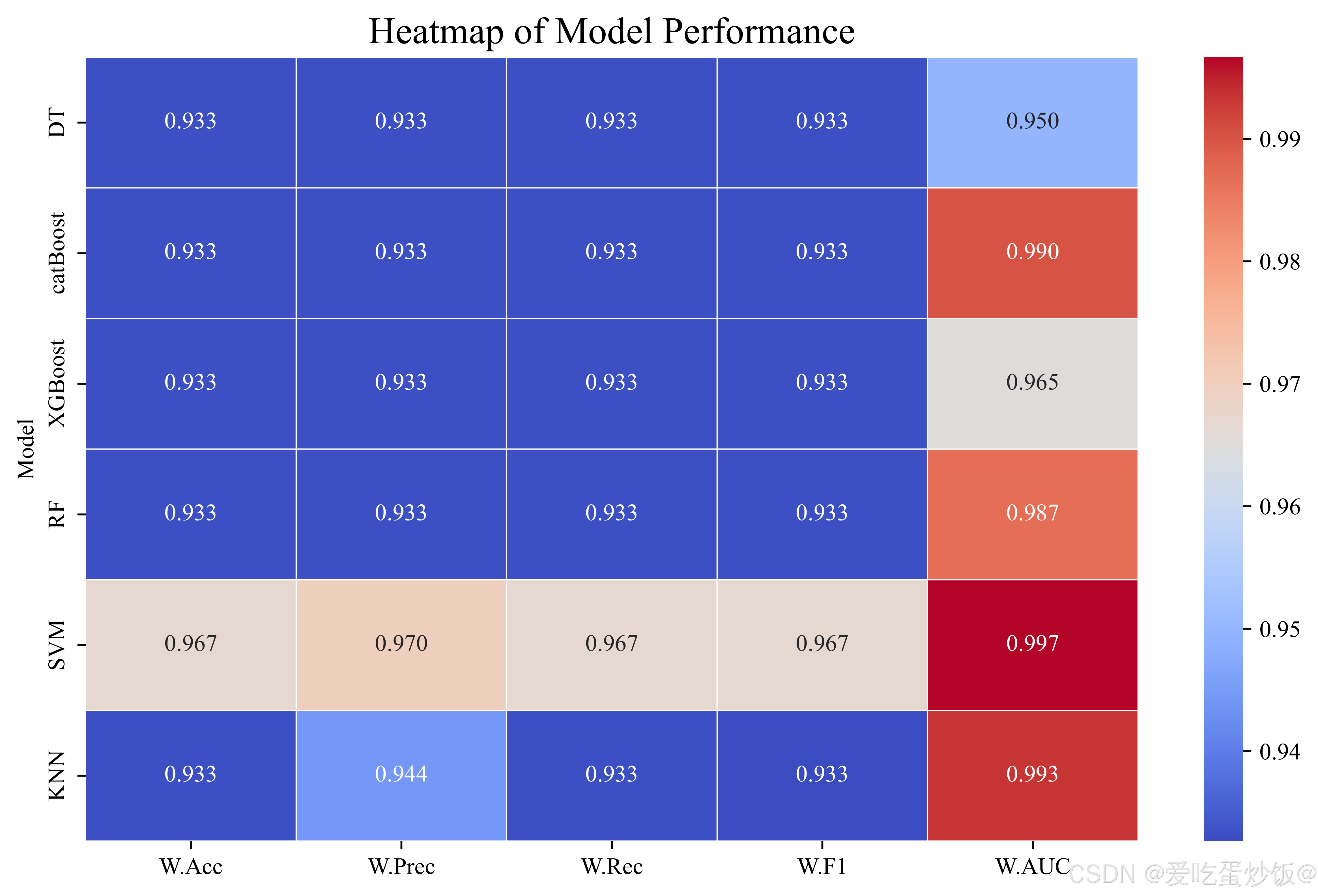
本人代码是使用notebook编写的,这里直接放上总代码!!!
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score,confusion_matrix
from adjustText import adjust_text
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from catboost import CatBoostClassifier
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
plt.rcParams['font.family'] = 'Times New Roman'
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_excel(r'C:\Users\lenovo\Desktop\blog\iris.xlsx')
# 划分特征和目标变量
X = df.drop(['target'], axis=1)
y = df['target']
# 类别映射字典
class_names = {0: 'Setosa', 1: 'Versicolor', 2: 'Virginica'} #输入数据中0、1、2分别代表了什么
# 初始化标准化器
scaler = StandardScaler()
# 对特征数据进行标准化
X = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=42, stratify=df['target'])
# 初始化结果存储
results = []
# 定义函数计算并保存多分类指标,同时绘制混淆矩阵
def evaluate_model(model_name, model, X_test, y_test):
y_pred = model.predict(X_test)
y_prob = model.predict_proba(X_test) if hasattr(model, "predict_proba") else None
# 计算指标
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')
# 计算ROC-AUC,只对概率输出的模型有效
roc_auc = roc_auc_score(y_test, y_prob, multi_class='ovr') if y_prob is not None else np.nan
# 存储结果
results.append({
"W.Acc": accuracy,
"W.Prec": precision,
"W.Rec": recall,
"W.F1": f1,
"W.AUC": roc_auc,
"Model": model_name
})
# 绘制混淆矩阵
cm = confusion_matrix(y_test, y_pred)
# 计算百分比矩阵
cm_percentage = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis] * 100
# 使用类别映射
labels = [class_names[i] for i in range(len(class_names))]
# 格式化显示的文本,显示数值和百分比
annotations = []
for i in range(len(cm)):
for j in range(len(cm[i])):
annotations.append(f'{cm[i, j]}\n({cm_percentage[i, j]:.2f}%)')
annotations = np.array(annotations).reshape(cm.shape)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=annotations, fmt='', cmap='Blues', xticklabels=labels, yticklabels=labels, cbar=False)
plt.title(f'Confusion Matrix - {model_name}')
plt.xlabel('Predicted')
plt.ylabel('True')
# 保存为PDF格式
plt.savefig(f'confusion_matrix_{model_name}.pdf', format='pdf', dpi=1200)
plt.show() # 关闭当前的绘图
# Decision Tree
dt = DecisionTreeClassifier(random_state=42)
dt.fit(X_train, y_train)
evaluate_model("DT", dt, X_test, y_test)
# CatBoost
cat = CatBoostClassifier(verbose=0, random_state=42)
cat.fit(X_train, y_train)
evaluate_model("catBoost", cat, X_test, y_test)
# XGBoost
xgb = XGBClassifier(use_label_encoder=False, eval_metric='logloss', random_state=42)
xgb.fit(X_train, y_train)
evaluate_model("XGBoost", xgb, X_test, y_test)
# Random Forest
rf = RandomForestClassifier(random_state=42)
rf.fit(X_train, y_train)
evaluate_model("RF", rf, X_test, y_test)
# SVM
svm = SVC(probability=True, random_state=42)
svm.fit(X_train, y_train)
evaluate_model("SVM", svm, X_test, y_test)
# KNN
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
evaluate_model("KNN", knn, X_test, y_test)
# 转为 DataFrame 并显示
results_df = pd.DataFrame(results)
# 将DataFrame保存为Excel文件
results_df.to_excel('results.xlsx', index=False)
results_df
#-----雷达图----
metrics = ["W.Acc", "W.Prec", "W.Rec", "W.F1", "W.AUC"]
categories = results_df["Model"].tolist()
angles = np.linspace(0, 2 * np.pi, len(categories), endpoint=False).tolist()
angles += angles[:1]
# 调整figsize以减小雷达图的大小
fig, axs = plt.subplots(2, 3, figsize=(14, 10), subplot_kw=dict(polar=True))
axs = axs.flatten()
for i, metric in enumerate(metrics):
values = results_df[metric].tolist()
values += values[:1] # Close the radar
axs[i].fill(angles, values, alpha=0.25, label=metric)
axs[i].plot(angles, values, marker='o')
axs[i].set_ylim(0, 1.001)
axs[i].set_xticks(angles[:-1])
# 增加字体大小
axs[i].set_xticklabels(categories, fontsize=12) # 原来是10,现在改为12
axs[i].set_title(metric, pad=20)
# 增加标题的字体大小
axs[i].title.set_fontsize(14) # 增加标题字体大小
axs[i].set_yticklabels([])
# 删除最后一个子图
fig.delaxes(axs[-1])
plt.savefig("rader_plt.pdf", format='pdf', bbox_inches='tight', dpi=1200)
# 调整子图间距,确保字体变大后不会重叠
plt.subplots_adjust(hspace=1.4, wspace=1.4)
plt.tight_layout()
plt.show()
#-----柱状图------
# 模型名称和评价指标
models = results_df['Model']
metrics = results_df.iloc[:, :-1].columns
# 绘图
fig, ax = plt.subplots(figsize=(16, 7))
width = 0.14 # 每个柱子的宽度
x = np.arange(len(metrics)) # 评价指标的位置
# 绘制每个模型的柱状图(竖直排列)
for i, model in enumerate(models):
bars = ax.bar(x + (i - 2.5) * width, results_df.iloc[i, :-1], width=width, label=model)
# 标注每个柱子的数值
for bar in bars:
yval = bar.get_height() # 获取柱子的高度
ax.text(bar.get_x() + bar.get_width() / 2, yval + 0.02, # 设置文本位置(在柱子上方)
f'{yval:.3f}', # 显示数值,保留两位小数
ha='center', va='bottom', fontsize=8, color='black') # 文本位置和格式
# 设置X轴标签和Y轴标签
ax.set_xticks(x)
ax.set_xticklabels(metrics)
ax.set_ylabel('Performance Metric Values')
ax.set_title('Performance Metrics for Each Model')
# 图例位置
ax.legend(title='Models', loc='center right', bbox_to_anchor=(1.1, 0.5)) # 前面的1.1为偏移量(向右),0.5为上下居中
# 保存图像为PDF
plt.tight_layout()
plt.savefig("stylolitic.pdf", format='pdf', bbox_inches='tight', dpi=300)
plt.show()
#-----热图------
import seaborn as sns
# 创建一个包含所有指标数据的 DataFrame
heatmap_data = results_df[metrics].set_index(results_df["Model"])
# 设置绘图样式
plt.figure(figsize=(10, 6))
# 绘制热力图
sns.heatmap(heatmap_data, annot=True, cmap='coolwarm', fmt='.3f', linewidths=0.5)
# 添加标题
plt.title('Heatmap of Model Performance', fontsize=16)
plt.savefig("heatmap.pdf", format='pdf', bbox_inches='tight', dpi=1200)
# 显示图形
plt.tight_layout()
plt.show()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









