






🥂(❁´◡`❁)您的点赞👍➕评论📝➕收藏⭐➕关注👀是作者创作的最大动力🤞
💖📕🎉🔥 支持我:点赞👍+收藏⭐️+留言📝+关注👀欢迎留言讨论
🔥🔥🔥(源码获取 + 调试运行 + 问题答疑)🔥🔥🔥 有兴趣可以联系我
🔥🔥🔥 文末有往期免费源码,直接领取获取(无删减,无套路)
我们常常在当下感到时间慢,觉得未来遥远,但一旦回头看,时间已经悄然流逝。对于未来,尽管如此,也应该保持一种从容的态度,相信未来仍有许多可能性等待着我们。
🔥🔥🔥(免费,无删减,无套路):java swing管理系统源码 程序 代码 图形界面(11套)」
链接:https://pan.quark.cn/s/784a0d377810
提取码:见文章末尾
JDK8 ConcurrentHashMap:高并发下的扩容与计数机制深度解析
引言
在并发编程的世界中,ConcurrentHashMap 一直是 Java 开发者的重要武器。JDK8 对其进行了革命性的重构,抛弃了分段锁的设计,采用了更先进的 CAS + synchronized 机制。其中最值得深入研究的两个特性是:多线程协助扩容机制和基于 CounterCell 的并发计数机制。本文将深入剖析这两大核心机制的设计原理和实现细节。
一、ConcurrentHashMap 的扩容机制
1.1 扩容触发条件
在 JDK8 的 ConcurrentHashMap 中,扩容主要发生在两种情况下:
-
元素数量超过阈值:当表中的元素数量超过容量 × 负载因子(默认 0.75)时
-
链表过长:当单个桶的链表长度超过 8,但表长度小于 64 时(此时优先扩容而不是树化)
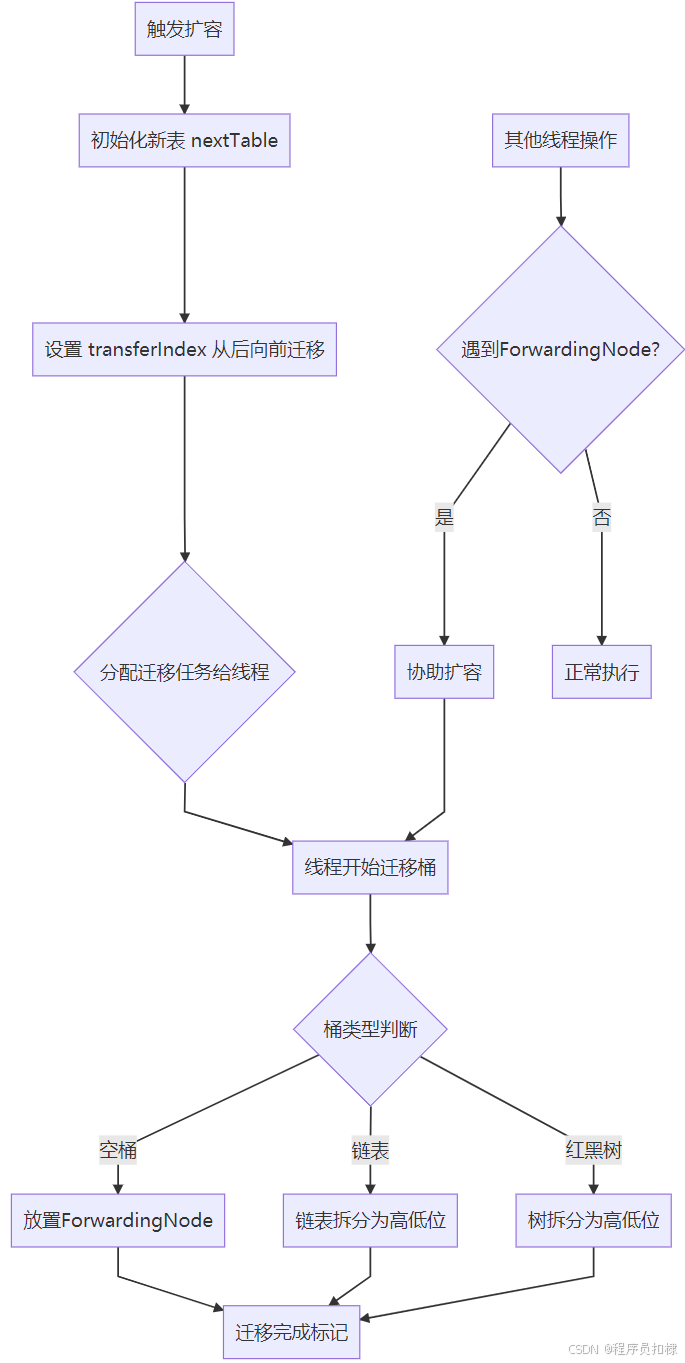
1.2 ForwardingNode:扩容的"信号灯"
ForwardingNode 是扩容机制中的关键节点,它是一个特殊的 Node 类型,哈希值为 MOVED(-1)。当一个桶完成迁移后,会在这个位置放置一个 ForwardingNode。
static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
}这个设计巧妙之处在于:
-
对于读操作:ForwardingNode 知道数据已经迁移到新表,可以直接到新表中查找
-
对于写操作:遇到 ForwardingNode 的线程会协助进行扩容
-
对于迭代器:可以正确地在扩容期间遍历数据
🔥🔥🔥(免费,无删减,无套路): Python源代码+开发文档说明(23套)」
链接:https://pan.quark.cn/s/1d351abbd11c
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):计算机专业精选源码+论文(26套)」
链接:https://pan.quark.cn/s/8682a41d0097
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):Java web项目源码整合开发ssm(30套)
链接:https://pan.quark.cn/s/1c6e0826cbfd
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):「在线考试系统源码(含搭建教程)」
链接:https://pan.quark.cn/s/96c4f00fdb43
提取码:见文章末尾
1.3 多线程协助扩容机制
transfer() 方法的核心思想
扩容的核心在 transfer() 方法中实现,其设计哲学是 "分工协作、最小冲突":
-
分而治之:将整个表分成多个"迁移段",每个线程负责一个段
-
逆序迁移:从后向前处理桶,避免并发处理时的冲突
-
CAS 控制:通过 CAS 操作分配迁移任务,确保线程安全
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
// 计算每个线程处理的桶数量,最小为16
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE;
// 初始化新表,长度为原表的2倍
if (nextTab == null) {
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) {
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n; // 从后向前迁移
}
// 具体的迁移逻辑...
}协助扩容的触发条件
当线程在 put、remove 等操作时遇到 ForwardingNode,会触发协助扩容:
final V putVal(K key, V value, boolean onlyIfAbsent) {
// ... 省略其他代码
else if ((fh = f.hash) == MOVED) // 遇到ForwardingNode
tab = helpTransfer(tab, f); // 协助扩容
// ... 后续处理
}1.4 扩容期间的读写操作
读操作如何并行
读操作在扩容期间完全无锁:
-
如果桶未迁移,直接读取
-
如果桶已迁移,通过 ForwardingNode 的 nextTable 转到新表读取
-
如果正在迁移,可能先读旧表再读新表
写操作如何处理
-
目标桶未迁移:正常进行 CAS 或 synchronized 操作
-
目标桶已迁移:通过 ForwardingNode 找到新表进行操作
-
正在迁移的桶:等待迁移完成后再操作,或者协助迁移
二、基于 CounterCell 的并发计数机制
2.1 传统计数方案的瓶颈
在高并发环境下,简单的原子变量(如 AtomicLong)会导致严重的 CAS 竞争。当数百个线程同时更新同一个计数器时,大量 CPU 时间浪费在 CAS 失败和重试上。
2.2 LongAdder 思想的引入
JDK8 的 ConcurrentHashMap 借鉴了 LongAdder 的思想,采用了 "分段累加、最终汇总" 的策略:
// 计数器的核心字段
private transient volatile long baseCount;
private transient volatile CounterCell[] counterCells;2.3 CounterCell 机制详解
结构设计
@sun.misc.Contended static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}注意 @sun.misc.Contended 注解,这是为了防止伪共享(False Sharing)。CPU 缓存以缓存行为单位(通常 64 字节),如果没有这个注解,相邻的 CounterCell 可能会在同一个缓存行,导致一个线程更新时使其他线程的缓存失效。
更新流程
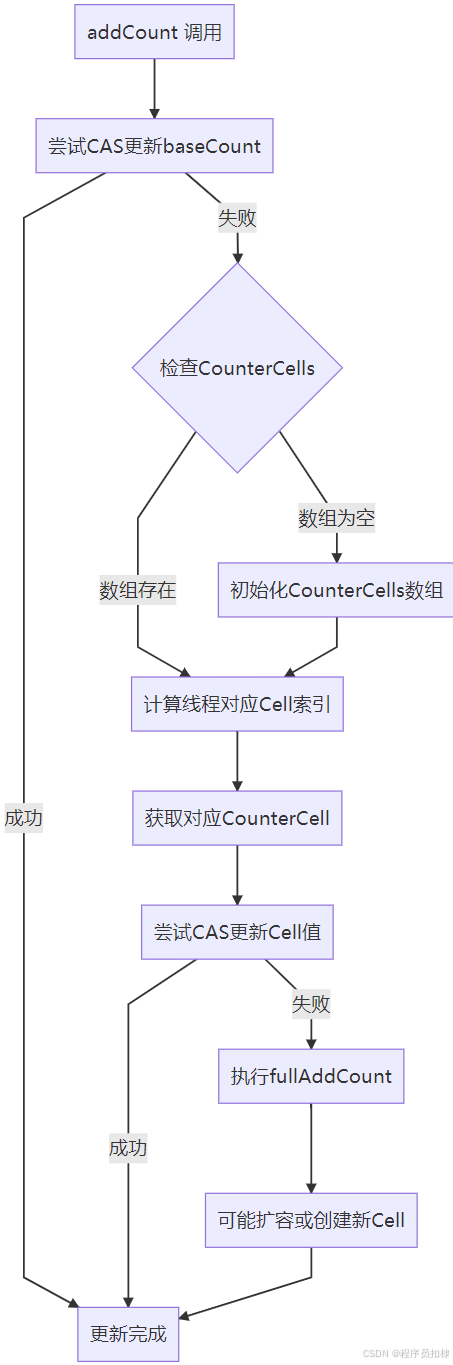
addCount() 方法是计数的核心:
-
首选更新 baseCount:通过 CAS 尝试更新 baseCount
-
失败则使用 CounterCell:如果 CAS 失败,说明存在竞争,使用 CounterCell 数组
-
初始化或扩容 CounterCell:根据需要初始化或扩容 CounterCell 数组
-
在 CounterCell 上累加:通过哈希算法选择特定的 CounterCell 进行更新
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
// 第一步:尝试更新 baseCount
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
// 第二步:使用 CounterCell
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
// 第三步:初始化或扩容 CounterCell
fullAddCount(x, uncontended);
return;
}
// ... 省略后续处理
}
// ... 省略后续处理
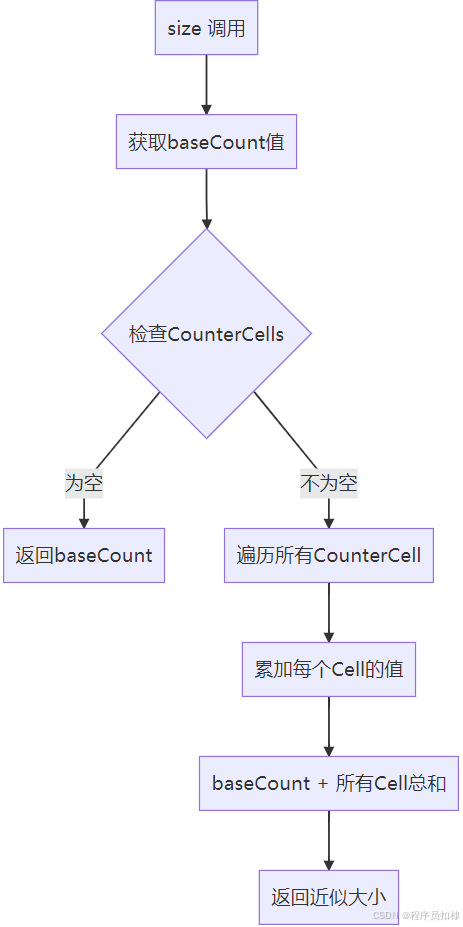
}2.4 size() 方法的实现
size() 方法并不是简单地返回一个值,而是需要汇总所有计数:
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
CounterCell[] as = counterCells;
CounterCell a;
long sum = baseCount; // 基础值
// 累加所有 CounterCell 的值
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}注意:size() 方法返回的是近似值,因为在并发环境下,统计过程中可能有其他线程在更新。如果需要精确值,应该使用 mappingCount() 方法。
三、性能分析与设计思想
3.1 扩容机制的性能优势
-
避免单点瓶颈:传统 HashMap 扩容时整个表被锁定,而 ConcurrentHashMap 允许多线程并行迁移
-
减少扩容时间:N 个线程参与可以将扩容时间近似减少到 1/N
-
平滑扩容:读写操作在扩容期间基本不受影响
3.2 计数机制的性能优势
-
降低竞争:将热点分散到多个 CounterCell,减少了 CAS 冲突
-
伪共享防护:通过
@Contended注解避免缓存行失效 -
惰性初始化:只有在确实存在竞争时才初始化 CounterCell 数组
3.3 实际应用建议
-
预估容量:如果知道大概的元素数量,创建时指定初始容量,避免频繁扩容
-
合理设置并发级别:虽然 JDK8 不再使用分段锁,但初始容量仍影响性能
-
理解 size() 的近似性:在高并发场景下,不要依赖 size() 的精确值做关键决策
-
监控 CounterCell 竞争:如果 CounterCell 数组过大,说明并发竞争激烈
结语
JDK8 的 ConcurrentHashMap 通过 ForwardingNode 实现的多线程协助扩容机制,以及基于 CounterCell 的分布式计数方案,展示了现代并发数据结构设计的精髓。这两大机制的共同特点是:
-
避免全局锁:通过细粒度的控制和 CAS 操作
-
化整为零:将大问题分解为小问题并行处理
-
自适应调整:根据并发竞争程度动态调整策略
理解这些机制不仅有助于更好地使用 ConcurrentHashMap,更能启发我们在设计高并发系统时的思考方式。在面对并发问题时,"分而治之"和"减少共享"永远是最有效的两大法宝。
size() 方法执行流程
ConcurrentHashMap 扩容和计数机制:
ForwardingNode 在扩容中的作用:
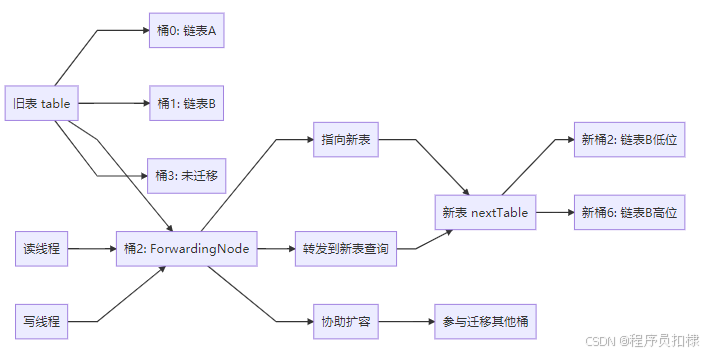
ForwardingNode 转发机制
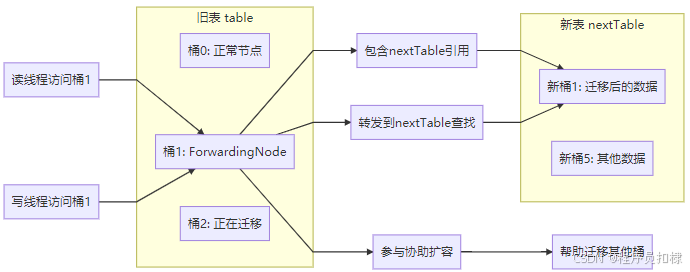
ConcurrentHashMap 的扩容流程和 CounterCell 计数机制的核心原理
往期免费源码对应视频:
免费获取--SpringBoot+Vue宠物商城网站系统
🥂(❁´◡`❁)您的点赞👍➕评论📝➕收藏⭐➕关注👀是作者创作的最大动力🤞
💖📕🎉🔥 支持我:点赞👍+收藏⭐️+留言📝+关注👀欢迎留言讨论
🔥🔥🔥(源码 + 调试运行 + 问题答疑)
🔥🔥🔥 有兴趣可以联系我
💖学习知识需费心,
📕整理归纳更费神。
🎉源码免费人人喜,
🔥码农福利等你领!💖常来我家多看看,
📕网址:扣棣编程,
🎉感谢支持常陪伴,
🔥点赞关注别忘记!💖山高路远坑又深,
📕大军纵横任驰奔,
🎉谁敢横刀立马行?
🔥唯有点赞+关注成!
⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇点击此处获取源码⬇⬇⬇⬇⬇⬇⬇⬇⬇

















 2222
2222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









