






🥂(❁´◡`❁)您的点赞👍➕评论📝➕收藏⭐➕关注👀是作者创作的最大动力🤞
💖📕🎉🔥 支持我:点赞👍+收藏⭐️+留言📝+关注👀欢迎留言讨论
🔥🔥🔥(源码获取 + 调试运行 + 问题答疑)🔥🔥🔥 有兴趣可以联系我
🔥🔥🔥 文末有往期免费源码,直接领取获取(无删减,无套路)
我们常常在当下感到时间慢,觉得未来遥远,但一旦回头看,时间已经悄然流逝。对于未来,尽管如此,也应该保持一种从容的态度,相信未来仍有许多可能性等待着我们。
JDK8 ConcurrentHashMap深度解析:从分段锁到synchronized+红黑树的进化之路
引言:并发容器的演进
在多线程并发编程中,ConcurrentHashMap无疑是最重要、最常用的并发容器之一。从JDK5引入之初,它就以其高效的并发性能赢得了开发者的青睐。然而,随着Java版本的演进,ConcurrentHashMap的实现经历了深刻的变革。特别是JDK8对其进行的重大重构,不仅改变了底层的数据结构,更彻底革新了同步机制。本文将深入剖析JDK8中ConcurrentHashMap的实现原理,揭示其为何摒弃了原有的分段锁设计,转而采用更细粒度的同步策略。
🔥🔥🔥(免费,无删减,无套路):java swing管理系统源码 程序 代码 图形界面(11套)」
链接:https://pan.quark.cn/s/784a0d377810
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路): Python源代码+开发文档说明(23套)」
链接:https://pan.quark.cn/s/1d351abbd11c
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):计算机专业精选源码+论文(26套)」
链接:https://pan.quark.cn/s/8682a41d0097
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):Java web项目源码整合开发ssm(30套)
链接:https://pan.quark.cn/s/1c6e0826cbfd
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):「在线考试系统源码(含搭建教程)」
链接:https://pan.quark.cn/s/96c4f00fdb43
提取码:见文章末尾
一、JDK7 ConcurrentHashMap的局限:分段锁的痛点
1.1 分段锁的设计思想
在JDK7及之前,ConcurrentHashMap采用了分段锁(Segment)的设计。整个Map被划分为多个Segment(默认为16个),每个Segment本质上是一个独立的HashMap,拥有自己的锁。这种设计允许多个线程同时访问不同的Segment,从而提高了并发度。
// JDK7中的Segment结构
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry<K,V>[] table;
// 其他字段和方法...
}1.2 分段锁的局限性
虽然分段锁在当时是一种创新的设计,但随着硬件的发展和并发场景的变化,其局限性逐渐显现:
-
锁粒度仍然较粗:虽然比Hashtable的全局锁细,但每个Segment锁仍然保护着多个桶(bucket)
-
内存开销较大:每个Segment都继承自ReentrantLock,包含了复杂的锁状态管理机制
-
并发度受限于Segment数量:默认16个Segment意味着最多支持16个线程完全并发
-
查询性能不够优化:链表过长时,查询时间复杂度退化为O(n)
二、JDK8 ConcurrentHashMap的革命性重构
2.1 全新的数据结构设计
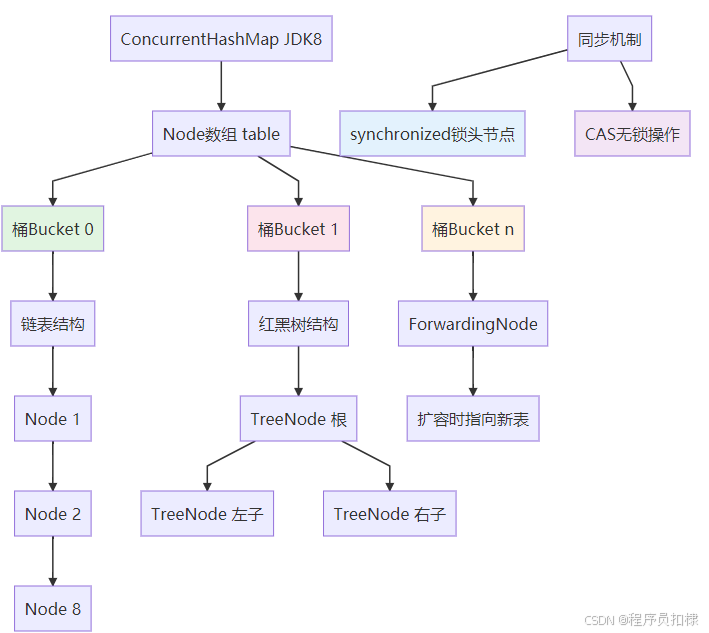
JDK8彻底摒弃了Segment分段锁的设计,回归到与HashMap类似的结构,但进行了并发优化:
Node数组(table)
↓
每个桶(bucket)独立
↓
链表 → 红黑树(条件触发)核心数据结构:
-
Node<K,V>[] table:核心的哈希表数组 -
Node节点:基本的存储单元,包含key、value、hash和next指针 -
TreeNode节点:红黑树的节点,继承自Node -
ForwardingNode:扩容时的特殊节点
2.2 细粒度的同步机制
2.2.1 从ReentrantLock到synchronized
JDK8最显著的改变之一是使用synchronized替代了ReentrantLock来同步每个桶的头节点。
为什么选择synchronized?
-
性能优化:经过多年的JVM优化,synchronized的性能已经与ReentrantLock相当甚至更好
-
内存开销小:synchronized是JVM内置的锁机制,不需要额外的内存存储锁状态
-
优化潜力大:JVM可以对synchronized进行深度优化(如锁消除、锁粗化、偏向锁、轻量级锁等)
-
代码简洁:减少了显式锁管理的复杂性
// JDK8中的putVal方法片段(简化版)
final V putVal(K key, V value, boolean onlyIfAbsent) {
// ... 前置检查
synchronized (f) { // f是桶的头节点
// 插入或更新逻辑
}
// ... 后置处理
}2.2.2 CAS操作的广泛应用
除了synchronized,JDK8大量使用了CAS(Compare-And-Swap)操作来处理无竞争的并发更新:
-
初始化table
-
扩容时的协助迁移
-
计数器更新(sizeCtl)
-
节点插入前的空桶检查
CAS操作通过sun.misc.Unsafe类实现,提供了硬件级别的原子性保证。
2.3 红黑树的引入:解决哈希冲突的终极武器
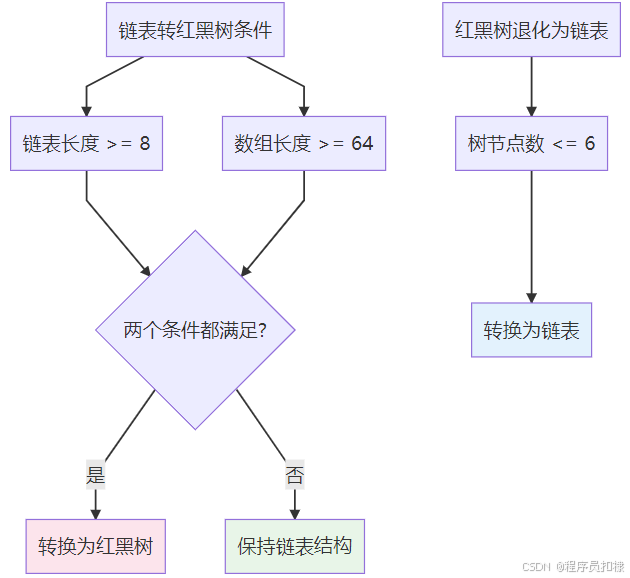
2.3.1 链表到红黑树的转换条件
JDK8引入了重要的优化:当链表长度过长时,会将其转换为红黑树:
static final int TREEIFY_THRESHOLD = 8; // 链表转树的阈值
static final int UNTREEIFY_THRESHOLD = 6; // 树转链表的阈值
static final int MIN_TREEIFY_CAPACITY = 64; // 可树化的最小表容量转换逻辑:
-
当链表长度 ≥ 8 且 数组长度 ≥ 64时,链表转换为红黑树
-
当树节点数 ≤ 6时,红黑树退化为链表
2.3.2 红黑树的优势
红黑树是一种自平衡的二叉查找树,具有以下特性:
-
最长路径不超过最短路径的两倍,保证基本平衡
-
查找、插入、删除的时间复杂度都是O(log n)
-
避免了极端情况下链表过长导致的性能退化
实际场景: 当大量元素哈希到同一个桶时(可能是哈希函数问题或恶意攻击),红黑树能保证O(log n)的查询效率,而链表会退化为O(n)。
三、核心操作原理深度剖析
3.1 put操作的并发安全实现
put操作是ConcurrentHashMap最复杂的操作之一,它需要处理多种并发场景:
// put操作的主要步骤
1. 计算key的hash值(spread方法进行再哈希)
2. 如果table为空,则初始化(initTable)
3. 定位到具体的桶
4. 如果桶为空,CAS插入新节点
5. 如果桶不为空,synchronized锁住头节点
6. 遍历链表或树,查找key是否存在
7. 存在则更新,不存在则插入
8. 检查是否需要树化
9. 更新size(通过addCount)关键优化点:
-
CAS失败重试:初始化、空桶插入等操作通过CAS+循环实现无锁化
-
锁细化:只锁住单个桶的头节点,不影响其他桶的操作
-
扩容协作:多个线程可以协作完成扩容操作
3.2 get操作的无锁优化
get操作在JDK8中是完全无锁的,这得益于以下设计:
// get操作的关键特性
1. 不需要加锁,直接读取
2. 使用volatile保证内存可见性
3. 遇到ForwardingNode时,转发到新表查询
4. 红黑树查找同样无锁为什么get可以不加锁?
-
Node的val和next都声明为volatile
-
红黑树的查找是只读操作
-
扩容时使用ForwardingNode保证正确性
3.3 扩容机制:多线程协作的典范
JDK8的扩容机制是其并发设计的精华所在:
// 扩容的主要步骤
1. 创建新表(2倍大小)
2. 分配扩容任务(stride)
3. 线程协作迁移节点
4. 设置ForwardingNode标记已迁移的桶
5. 迁移完成,使用新表迁移策略:
-
每个线程负责一个区间(stride)的迁移
-
迁移时对原桶加锁,保证迁移的原子性
-
使用ForwardingNode标记已迁移的桶
四、性能对比与实战建议
4.1 JDK7 vs JDK8性能对比
| 特性 | JDK7 ConcurrentHashMap | JDK8 ConcurrentHashMap |
|---|---|---|
| 锁粒度 | Segment级别(较粗) | 桶级别(更细) |
| 锁类型 | ReentrantLock | synchronized |
| 数据结构 | 数组+链表 | 数组+链表+红黑树 |
| 最大并发度 | Segment数量(默认16) | 桶数量(理论上无限制) |
| 内存开销 | 较大(每个Segment一个锁) | 较小 |
| 极端情况性能 | 链表可能很长,查询O(n) | 转换为红黑树,查询O(log n) |
4.2 实战使用建议
-
选择合适的初始容量
// 预估并发线程数和数据量,设置合理的初始容量 int initialCapacity = 64; // 根据实际情况调整 ConcurrentHashMap<String, Object> map = new ConcurrentHashMap<>(initialCapacity); -
合理设置并发级别
// JDK8中concurrencyLevel参数仅用于兼容性,实际作用有限 // 推荐使用初始容量和负载因子来控制 -
避免热点桶
-
确保key的hashCode分布均匀
-
自定义对象实现良好的hashCode方法
-
-
正确使用原子操作
// 使用computeIfAbsent等原子方法 map.computeIfAbsent(key, k -> createValue(k));
五、总结与展望
JDK8对ConcurrentHashMap的重构是一次深刻的进化,它体现了Java并发编程理念的变迁:
-
从粗粒度到细粒度:锁粒度细化到每个桶,提高了并发性能
-
从复杂到简洁:synchronized替代ReentrantLock,简化了实现
-
从单一到混合:链表+红黑树的混合结构,兼顾了普通情况和极端情况
-
从独占到协作:多线程协作扩容,提高了系统整体吞吐量
这些改进使得ConcurrentHashMap在高并发场景下表现更加出色,能够更好地适应现代多核处理器的架构特点。作为Java开发者,深入理解这些原理不仅有助于我们更好地使用这个工具,更能提升我们对并发编程本质的理解。
随着Java版本的不断演进,ConcurrentHashMap仍在持续优化。在未来的JDK版本中,我们可能会看到更多基于硬件特性的优化,如更细粒度的内存访问控制、更好的缓存友好性设计等。但无论如何变化,对并发安全、性能、可扩展性的追求将始终是ConcurrentHashMap设计的核心目标。

往期免费源码对应视频:
免费获取--SpringBoot+Vue宠物商城网站系统
🥂(❁´◡`❁)您的点赞👍➕评论📝➕收藏⭐➕关注👀是作者创作的最大动力🤞
💖📕🎉🔥 支持我:点赞👍+收藏⭐️+留言📝+关注👀欢迎留言讨论
🔥🔥🔥(源码 + 调试运行 + 问题答疑)
🔥🔥🔥 有兴趣可以联系我
💖学习知识需费心,
📕整理归纳更费神。
🎉源码免费人人喜,
🔥码农福利等你领!💖常来我家多看看,
📕网址:扣棣编程,
🎉感谢支持常陪伴,
🔥点赞关注别忘记!💖山高路远坑又深,
📕大军纵横任驰奔,
🎉谁敢横刀立马行?
🔥唯有点赞+关注成!
⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇点击此处获取源码⬇⬇⬇⬇⬇⬇⬇⬇⬇

















 163
163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









