





原文:提取PDF文本
步骤 1:获取并访问 PHP PDF API 的许可证
对于 ComPDFKit API 用户,我们提供 1000 个免费 PDF API 请求。请按照以下步骤访问许可证并开始您的 API 请求。
-
注册ComPDFKit API 以转到仪表板。您将在仪表板上看到 API 密钥、API 计划的进度以及 API 请求的状态。
-
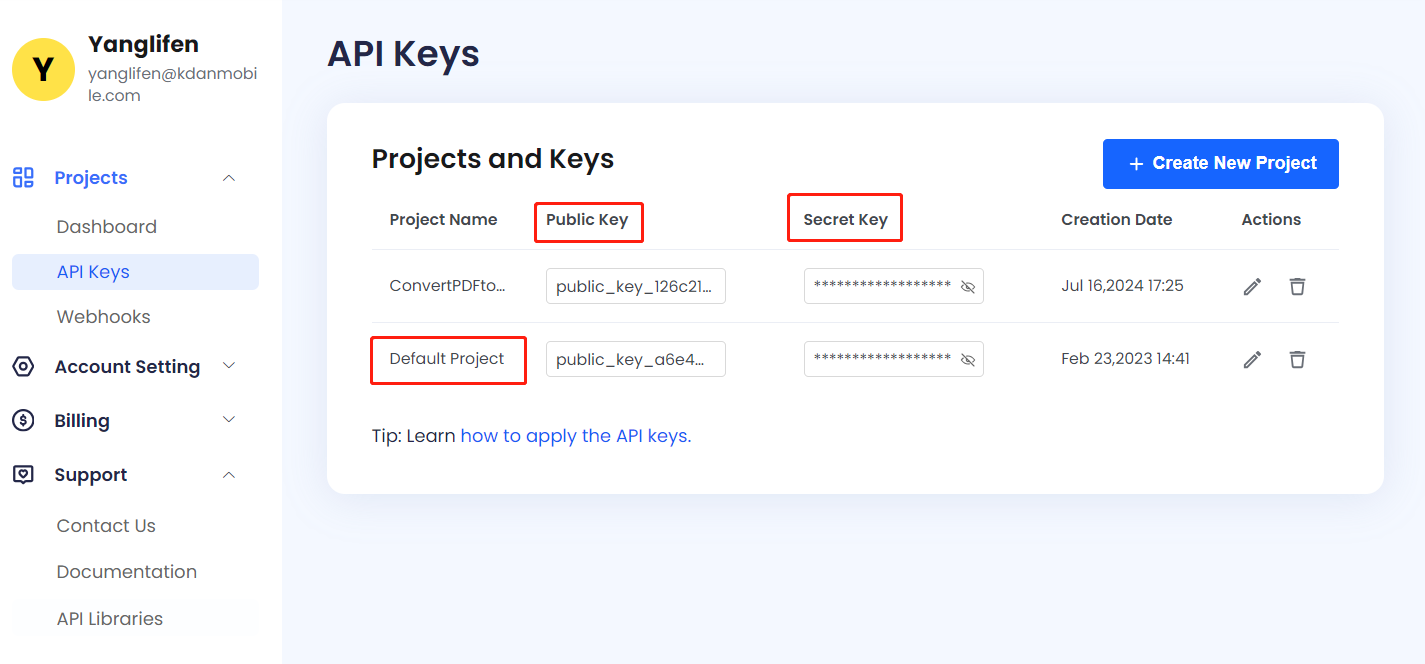
创建一个项目并获取公钥和密钥。
创建帐户后,将创建一个默认项目。您可以创建更多项目来调用 ComPDFKit API。每个项目都有唯一的公钥和密钥。请记住为相应的项目应用正确的密钥。
步骤2:用于 PDF 文本提取的身份验证 PDF API
需要替换真实的publicKey和secretKey,获取accessToken,然后使用accessToken创建任务,上传文件,提取PDF文字,获取提取出来的PDF文本JSON文件。
用于验证 ComPDFKit PDF 文本提取 API 的 PHP 代码示例:
<span style="background-color:#272e3b"><span style="color:white"><code>$params = [
'publicKey' => $publicKey,
'secretKey' => $secretKey
];
$headers = ['Content-Type: application/json'];
$curl = curl_init();
curl_setopt_array($curl, array(
CURLOPT_URL => 'https://api-server.compdf.com/server/v1/oauth/token',
CURLOPT_RETURNTRANSFER => true,
CURLOPT_ENCODING => '',
CURLOPT_MAXREDIRS => 10,
CURLOPT_TIMEOUT => 0,
CURLOPT_FOLLOWLOCATION => true,
CURLOPT_HTTP_VERSION => CURL_HTTP_VERSION_1_1,
CURLOPT_CUSTOMREQUEST => 'POST',
CURLOPT_HTTPHEADER => $headers,
CURLOPT_POSTFIELDS => json_encode($params)
));
$response = curl_exec($curl);
curl_close($curl);
$result = json_decode($response, true);
$accessToken = $result['data']['accessToken'];
$bearerToken = "Bearer $accessToken";</code></span></span>
步骤3:创建任务 - 提取PDF文本
您需要替换上一步获取到的accessToken 。设置显示错误信息的语言类型(1,英文,2,中文)。ComPDFKit PDF API参数可以在快速入门-->请求说明页面找到。
替换它们之后,您将在响应数据中获得taskId。创建PDF文本提取任务的PHP代码示例:
<span style="background-color:#272e3b"><span style="color:white"><code>$headers = [
'Content-Type: application/json',
'Authorization: ' . $bearerToken
];
$curl = curl_init();
curl_setopt_array($curl, array(
CURLOPT_URL => 'https://api-server.compdf.com/server/v1/task/pdf/json?language=' . $language,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_ENCODING => '',
CURLOPT_MAXREDIRS => 10,
CURLOPT_TIMEOUT => 0,
CURLOPT_FOLLOWLOCATION => true,
CURLOPT_HTTP_VERSION => CURL_HTTP_VERSION_1_1,
CURLOPT_CUSTOMREQUEST => 'GET',
CURLOPT_HTTPHEADER => $headers,
));
$response = curl_exec($curl);
curl_close($curl);
$result = json_decode($response, true);
$taskId = $result['data']['taskId'];</code></span></span>
步骤4:上传文件至PDF解析器
替换PHP代码中的信息:
-
PDF 文件:您想要从中提取文本的 PDF。
-
taskId:在任务创建步骤中获取。
-
语言:您想要显示错误信息的语言。
-
accessToken:在身份验证步骤中获取。
ComPDFKit API 提供 AI、OCR 等。您也可以在此步骤输入参数:
-
type:提取内容的选项(0:文本,1:表格)默认0。
-
isAllowOcr:是否允许打开OCR(1:是,0:否),默认0。
-
isOnlyAiTable:是否启用AI识别表格(1:是,0:否)默认0。
上传 PDF 进行解析的 PHP 代码示例:
<span style="background-color:#272e3b"><span style="color:white"><code>$params = [
'taskId' => $taskId, // ID of your task
'file' => new CURLFile($pdfPath), // Files you need to process
'language' => $language,
'password' => '',
'parameter' => json_encode(['type' => 1, 'isAllowOcr' => 1, 'isContainOcrBg' => 0])
];
$headers = [
'Authorization: ' . $bearerToken
];
$curl = curl_init();
curl_setopt_array($curl, array(
CURLOPT_URL => 'https://api-server.compdf.com/server/v1/file/upload',
CURLOPT_RETURNTRANSFER => true,
CURLOPT_ENCODING => '',
CURLOPT_MAXREDIRS => 10,
CURLOPT_TIMEOUT => 0,
CURLOPT_FOLLOWLOCATION => true,
CURLOPT_HTTP_VERSION => CURL_HTTP_VERSION_1_1,
CURLOPT_CUSTOMREQUEST => 'POST',
CURLOPT_HTTPHEADER => $headers,
CURLOPT_POSTFIELDS => $params
));
$response = curl_exec($curl);
curl_close($curl);
$result = json_decode($response, true);
$fileKey = $result['data']['fileKey'];</code></span></span>
步骤5:处理并提取上传的PDF文件中的文本
执行任务,从您上传的 PDF 中提取单词。以下是 PHP 代码示例:
<span style="background-color:#272e3b"><span style="color:white"><code>$headers = [
'Content-Type: application/json',
'Authorization: ' . $bearerToken
];
$curl = curl_init();
curl_setopt_array($curl, array(
CURLOPT_URL => 'https://api-server.compdf.com/server/v1/execute/start?language=' . $language . '&taskId=' . $taskId,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_ENCODING => '',
CURLOPT_MAXREDIRS => 10,
CURLOPT_TIMEOUT => 0,
CURLOPT_FOLLOWLOCATION => true,
CURLOPT_HTTP_VERSION => CURL_HTTP_VERSION_1_1,
CURLOPT_CUSTOMREQUEST => 'GET',
CURLOPT_HTTPHEADER => $headers,
));
$response = curl_exec($curl);
curl_close($curl);</code></span></span>
步骤6:获取PDF文本提取任务信息
按照下面的 PHP 代码示例获取任务信息。替换所需的信息,如taskId和access_token。PDF PDF 解析器和提取的结果文件以 JSON 文件的形式呈现,这是一种结构化的数据格式,有利于重复使用 PDF 文本提取。
<span style="background-color:#272e3b"><span style="color:white"><code>$headers = [
'Content-Type: application/json',
'Authorization: ' . $bearerToken
];
$curl = curl_init();
curl_setopt_array($curl, array(
CURLOPT_URL => 'https://api-server.compdf.com/server/v1/task/taskInfo' . '?taskId=' . $taskId,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_ENCODING => '',
CURLOPT_MAXREDIRS => 10,
CURLOPT_TIMEOUT => 0,
CURLOPT_FOLLOWLOCATION => true,
CURLOPT_HTTP_VERSION => CURL_HTTP_VERSION_1_1,
CURLOPT_CUSTOMREQUEST => 'GET',
CURLOPT_HTTPHEADER => $headers,
));
$response = curl_exec($curl);
curl_close($curl);
$result = json_decode($response, true);</code></span></span>
















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









