



RabbitMQ:[像风1]
就是一个消息中间件,流程就是将生产者发送的消息放到自身的容器中,再发送给消费者的, 优点在于应用解耦,提升容错性和可维护性,异步提速,提升用户体验和系统吞吐量,削峰填谷,提高系统稳定性。缺点在于系统可用性降低 系统引入的外部依赖越多,系统稳定性越差。一旦MQ 宕机,就会对业务造成影响;系统复杂度提高,MQ 的加入大大增加了系统的复杂度,以前系统间是同步的远程调用,现在是通过MQ 进行异步调用。需要保证消息没有被重复消费,处理消息丢失,保证消息传递的顺序性;一致性问题,一个系统处理完业务,通过MQ 给其他三个系统发消息数据,如果有一个系统处理失败,需要保证消息数据处理的一致性.
为什么选择RabbitMq
ZeroMQ : 扩展性好,开发比较灵活,采用C语言实现,不能数据持久化
ActiveMQ: 历史悠久的开源项目,已经在很多产品中得到应用,对队列数较多的情 况支持不好,容易出现丢消息. 4000并发
Redis 做为一个基于内存的K-V数据库,其提供了消息订阅的服务,可以当作MQ来使用,目前应用案例较少,且不方便扩展
RocketMQ: 阿里巴巴的MQ中间件,在其多个产品下使用,可查询的资料相当少,不全面
RabbitMQ :结合erlang语言本身的并发优势,性能较好,管理端页面功能丰富,消息延迟微秒级,支持多种语言且支持AMQP客户端.
我记得当时官方有6种模式: 简单模式、work queues、Publish/Subscribe 发布与订阅模式、Routing 路由模式、Topics 主题模式、RPC 远程调用模式(远程调用,不太算MQ)
简单模式 HelloWorld
一个生产者、一个消费者,不需要设置交换机(使用默认的交换机).
工作队列模式Work Queue
一个生产者、多个消费者(竞争关系,轮询策略),不需要设置交换机(使用默认的交换机).
发布订阅模式 Publish/subscribe
需要设置类型为 fanout 的交换机,并且交换机和队列进行绑定,当发送消息到交换机后,交换机会将消息发送到绑定的队列.
路由模式 Routing
需要设置类型为 direct 的交换机,交换机和队列进行绑定,并且指定 routing key,当发送消息到交换机 后,交换机会根据 routing key 将消息发送到对应的队列.
通配符模式 Topic
需要设置类型为 topic 的交换机,交换机和队列进行绑定,并且指定通配符(* 匹配多个字符, # 匹配一个字符)方式的routing key,当发送消息到交换机后,交换机会根据 routing key 将消息发送到对应的队列.
远程调用模式RPC
客户端发送消息到消费队列, 服务端进行消费消息执行程序将结果再发送到回调队列, 供客户端使用. 是一种双向生产消费模式.既是生产者又是消费者, 如果只有一个queue 则会出现死循环,需要有一个回调队列
我采用的是Routing模式, 交换机类型为Direct,特点是会将不同的message根据路由规则“分门别类”,即只有消息的 Routing key 与Binding key 相同时,交换机才会把消息发给该队列,所以选择了Routing模式
在使用RabbitMQ时候就会遇到相应的痛点,消息丢失,防爆刷,幂等性(消息重复)因素
消息丢失:
消息丢失分为三个阶段
生产者消息丢失
消息队列消息丢失
消费者消息丢失
生产者消息丢失:
包含两种地方丢失: 生产者到交换机消息丢失和交换机到消息队列消息丢失
生产者到交换机消息丢失
RabbitMQ提供transaction和confirm模式来确保生产者到交换机消息不丢失
transaction机制
发送消息前,开启事务(channel.txSelect()),然后发送消息,如果发送过程中出现什么异常,事务就会回滚(channel.txRollback()),如果发送成功则提交事务(channel.txCommit()),这种方式有个缺点:吞吐量下降,也就是性能下降250倍
confirm模式
一旦channel进入confirm模式,所有在该信道上发布的消息都将会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列之后,rabbitMQ就会发送一个ACK给生产者(包含消息的唯一ID),生产者就会知道消息已经正确到达目的队列了;如果rabbitMQ没能处理该消息,则会发送一个Nack消息,进行重试操作.
生产者开启publisher-confirms: true消息成功确认后,通过setConfirmCallback设置回调函数,进行Confirm回调,实现的Confirm方法形参中包含一个Boolean类型的值ack,可以通过它来确定生产者发送消息到交换机是否失败,ture成功,false失败,如果失败了,进行日志记录,通过定时器重新触发这些失败的消息.
因为transaction吞吐量下降的缺点,所以我选择的Confirm模式
交换机到消息队列消息丢失
RabbitMQ提供return退回模式来确保交换机到消息队列消息失败,主要负责的是交换机到队列之间是否发送成功
生产者开启publisher-returns: true消息失败确认后,通过setReturnCallback设置退回函数,进行Return回滚, 实现的returnedMessage方法, 形参中包含一个String类型的错误原因,通过判空进行记录, 设置rabbitTemplate.setMandatory(true)参数,会将消息退回给producer。并执行回调函数returnedMessage。
消息队列消息丢失
主要采用消息持久化来解决RabbitMQ消息队列的消息丢失,处理消息队列丢数据的情况,一般是开启持久化磁盘的配置,这个持久化配置和confirm机制配合使用,在消息持久化磁盘后,再给生产者发送一个Ack信号
持久化需要设置三方面
交换机持久化,消息队列持久化以及消息持久化
交换机持久化: 将exchange的持久化标识durable设置为true,则代表是一个持久的交换机
消息队列持久化: 将queue的持久化标识durable设置为true,则代表是一个持久的队列
消息持久化: 发送消息的时候将deliveryMode=2
这样设置以后,即使rabbitMQ挂了,重启后也能恢复数据
消费者消息丢失:
默认情况下 RabbitMQ 是自动ACK机制,就意味着 MQ 会在消息发送完毕后,自动帮我们去ACK,然后删除消息的信息,这样依赖就存在这样一个问题:如果消费者处理消息需要较长时间,最好的做法是消费者处理完之后手动去确认,消费者丢数据一般是因为采用了自动ACK,改为手动ACK即可
为了保证数据不被丢失,RabbitMQ支持消息确认机制,即ack.发送者为了保证消息肯定消费成功,只有使用方明确表示消费成功,RocketMQ才会认为消息消费成功.中途断电,抛出异常等都不会认为成功——即都会重新投递.保证数据能被正确处理而不仅仅是被Consumer收到,我们就不能采用no-ack或者auto-ack,我们需要手动ack(manual-ack).在数据处理完成后手动发送ack,这个时候Server才将Message删除.
自动ACK: 消费者在收到消息之后,处理消息之前,会自动回复RabbitMQ已收到消息;
如果这时处理消息失败,就会丢失该消息.
手动ACK:
生产者通过template: mandatory: true 开启手动签收机制,消费者通过acknowledge-mode: manual开启手动ACK,在监听队列的方法中,通过channel.basicAck(tag,false) 进行消息签收,使用try catch进行包裹要执行的方法,如果报错在catch中进行日志记录, 调用channel.basicNack()方法,让其自动重新发送消息.
消费端限流
指的就是每秒从MQ中拉取多少个请求,保证服务器不会因为处理过多请求而宕机.
通过prefetch限制消费端一次拉取多少个请求,并且消费端必须是手动ack.
幂等性(消息重复)
幂等性指一次和多次请求某一个资源,对于资源本身应该具有同样的结果。也就是说,其任 意多次执行对资源本身所产生的影响均与一次执行的影响相同。
在MQ中指,消费多条相同的消息,得到与消费该消息一次相同的结果。
目前了解两种解决消息重复方式
1. 根据代码的业务逻辑,通过改变SQL语句达到目的
2. 监听器接收MQ队列中的数据: 利用redis的setnx命令(在 redisTemplate中对应 的方法是Setifabsent()),仅为 key 不存在时,将 key 的值设为 value,并返回true,若给定的 key 已经存在,则 SETNX 不做任何动作,并返回false,以消息唯一id为key,消息内容为value,过期时间设置为10秒,存入redis中,如果能够成功存入,说明没有重复消费,则处理业务,处理完业务后返回ack或者nack确认,如果存不进去,则说明重复消费,直接返回ack确认的回调信息.
消息追踪
使用Firehose和rabbitmq_tracing插件功能来实现消息追踪
Firehose
将生产者投递给rabbitmq的消息,rabbitmq投递给消费者的消息按照指定的格式发送到默认的exchange上。这个默认的exchange的名称为amq.rabbitmq.trace,它是一个topic类型的exchange。发送到这个exchange上的消息的routing key为 publish.exchangename 和 deliver.queuename。其中exchangename和queuename为实际exchange和queue的名称,分别对应生产者投递到exchange的消息,和消费者从queue上获取的消息,打开 trace 会影响消息写入功能,适当打开后关闭。 rabbitmqctl trace_on:开启Firehose命令
rabbitmqctl trace_off:关闭Firehose命令
Rabbitmq_tracing
和Firehose在实现上如出一辙,只不过rabbitmq_tracing的方式比Firehose多了一 层GUI的包装,更容易使用和管理。
启用插件:rabbitmq-plugins enable rabbitmq_tracing
TTL以及DLX
TTL
存活时间/过期时间
当消息到达存活时间后,还没有被消费,会被自动清除,RabbitMQ可以对消息设置过期时间,也可以对整个队列(Queue)设置过期时间
DLX
死信队列
当消息成为死信后,可以被重新发送到另一个交换机
消息成为死信的三种情况
队列消息长度到达限制
消费者拒接消费消息,basicNack/basicReject,并且不把消息重新放入原目标队列,requeue=false;
原队列存在消息过期设置,消息到达超时时间未被消费;
队列绑定死信交换机给队列设置参数: x-dead-letter-exchange 和 x-dead-letter-routing-key, 当消息成为死信后,如果该队列绑定了死信交换机,则消息会被死信交换机重新路由到死信队列.
延迟队列
延迟队列,即消息进入队列后不会立即被消费,只有到达指定时间后,才会被消费.
当时项目中有一个定时发布的需求,当时有两种选择延迟队列和分布式定时任务
因为在RabbitMQ中并未提供延迟队列功能,但是TTL+死信队列组合实现延迟队列的效果,所以引入了延迟插件进行处理
RabbitMQ日志
默认日志存放路径: /var/log/rabbitmq/rabbit@xxx.log,包含了RabbitMQ版本号、Erlang版本号、RabbitMQ服务节点名称、cookie的hash值、RabbitMQ配置文件地址、内存限制、磁盘限制、默认账户guest的创建以及权限配置等等
RabbitMQ集群
原理
RabbitMQ基于Erlang,Erlang语言天生具备分布式特性(通过同步Erlang集群各节点的magic cookie来实现).所以RabbitMQ支持Clustering. ActiveMQ、Kafka还需要通过ZooKeeper分别来实现HA方案和保存集群的元数据,集群是保证可靠性的一种方式,同时可以通过水平扩展以达到增加消息吞吐量能力的目的.
负载均衡-HAProxy
HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案,实现了一种事件驱动、单一进程模型,此模型支持非常大的并发连接数.
脑裂问题的解决
当然,我们不能要求集群的可用性或网络的健康达到 100%,即使在局域网中,发生故障的可能性也是存在的
RabbitMQ 3.1 以上版本提供了配置(修改/etc/rabbitmq/rabbitmq.config配置文件)来解决这个问题:

RabbitMQ 提供了三种配置:
ignore:默认配置,发生网络分区时不作处理,当认为网络是可靠时选用该配置.
autoheal:
各分区协商后重启客户端连接最少的分区节点,恢复集群(CAP 中保证 AP,有状态丢失);
胜出的分区是获得最多客户端连接的那个分区(平局情况,选择拥有最多node分区,依旧平局的话,随机选择一个分区)
网络可能不可靠,更关心服务可用性而非数据完整性,可以是2节点的集群
pause_minority:
停掉了少数派集群
选择了CAP中的分区容错性P放弃了可用性A
确保network partition发生时最多只有一个分区继续工作
少数派分区节点在分区发生时停止,分区恢复后重新启动
在由两个node构建的集群上使用这个模式是不明智的,只要出现网络分区,或者任意node失效,都会导致两个node同时被关停;
被动关停服务的node上的ErlangVM将持续运行,但该node将不再监听任何port,也不会再进行任何工作.这种node会每秒检查一次集群中的其余node是否已重新出现,并在检查成功后重新激活自身的服务;
分区发生后判断自己所在分区内节点是否超过集群总节点数一半,如果没有超过则暂停这些节点(保证 CP,总节点数为奇数个),网络不太可靠,集群奇数个节点构成.
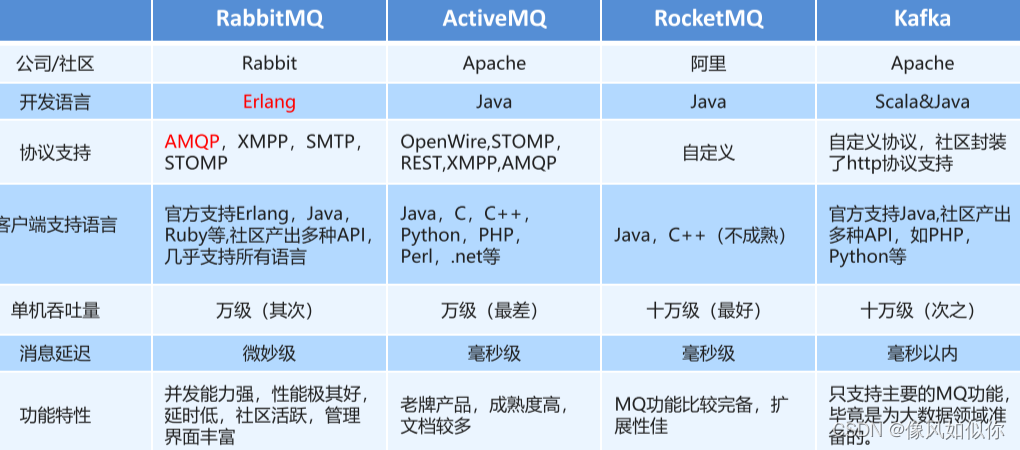

[像风1]RabbitMQ是基于 AMQP 协议使用 Erlang 语言开发的一款消息队列产品, AMQP 是协议,类比HTTP,JMS 是 API 规范接口,类比 JDBC。

















 4999
4999




 到【灌水乐园】发言
到【灌水乐园】发言







