




一、使用search()和match()方法匹配字符串
re模块中的search()方法用于在整个字符串中搜索第一个匹配的值,如果匹配成功则返回Match对象,否则返回None。
1、 获取第一个指定字符开头的字符串
import re
pattern = 'mr_\w+' # 模式字符串 w+ 用于匹配字母,数字或下划线字符
string = 'MR_SHOP mr_shop'
match = re.search(pattern,string,re.I)# 搜索字符串,不区分大小写
print(match)
运行结果:因为不区分大小写,那么匹配到的是MR_SHOP
<re.Match object; span=(0, 7), match='MR_SHOP'>
2、可选匹配
在匹配字符串时,有时会遇到部分内容可有可无的情况,对于这样的情况可以使用"?"来解决,”?“可以理解为可选符号。
# .* 表示任意匹配除换行符(\n、\r)之外的任何单个或多个字符
# (.*?) 表示"非贪婪"模式,只保存第一个匹配到的子串
print(re.search('a.*?','aaaaaaaaaaa')) # a
print(re.search('a.*','aaaaaaaaaaa')) # aaaaaaaaaaa
import re # 导入re模块
#1、表达式,(\d?)+表示多个数字可有可无,\s空格可有可无,([\u4e00-\u9fa5]?)+多个汉字可有可无
pattern = '(\d?)+mrsoft\s?([\u4e00-\u9fa5]?)+'
# [\s\S]* 是完全通配的意思,\s 是指空白,包括空格、换行、Tab 缩进等所有的空白,而 \S 刚好相反
# [\u4e00-\u9fa5] 匹配中文
# \d 数字
match = re.search(pattern,'01mrsoft 中国')
2、match = re.search(pattern,'mrsoft') # 匹配字符串,mrsoft匹配成功
match = re.search(pattern,'mrsoft ') # 匹配字符串,mrsoft后面有一个空格,匹配成功
match = re.search(pattern,'mrsoft 第一') # 匹配字符串,mrsoft后面有空格和汉字,匹配成功
match = re.search(pattern,'rsoft 第一') # 匹配字符串,rsoft后面有空格和汉字,匹配失败
3、匹配字符串边界
使用”\b“匹配字符串的边界。如果字符串在开始处、结尾处,或者是字符串的分界符为空格、标点符号以及换行,可以使用"\b"匹配字符串的边界
import re # 导入re模块
pattern = r'\bmr\b' # 表达式,mr两侧均有边界
match = re.search(pattern,'mrsoft') # 匹配字符串,mr右侧不是边界是soft,匹配失败
print(match) # 打印匹配结果
match = re.search(pattern,'mr soft') # 匹配字符串,mr左侧为边界右侧为空格,匹配成功
print(match) # 打印匹配结果
match = re.search(pattern,' mrsoft ') # 匹配字符串,mr左侧为空格右侧为soft空格,匹配失败
print(match) # 打印匹配结果
match = re.search(pattern,'mr.soft') # 匹配字符串,mr左侧为边界右侧为“.”,匹配成功
print(match) # 打印匹配结果
4、group
group(num) 或 groups() 匹配对象函数来获取匹配表达式。
group(num=0):匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
2、groups():返回一个包含所有小组字符串的元组,从 1 到 所含的小组号
案例:
line = 'Cates are smarter than dogs'
searchObj = re.search(r'(.*) are (.*?) .*',line,re.M|re.I)
if searchObj:
print(searchObj.group()) # Cates are smarter than dogs
print(searchObj.group(1)) # Cates
print(searchObj.group(2)) # smarter
print(searchObj.groups()) # ('Cates', 'smarter')
5、元字符
|
表达式 |
匹配 |
|
. |
小数点可以匹配除换行符\n以外的任意一个字符 |
|
| |
逻辑或操作符 |
|
[ ] |
匹配字符集中的任意一个字符 |
|
[^ ] |
对字符集求反, |
|
- |
定义[]里的一个字符区间,例如[a-z] |
|
\ |
对紧跟其后的一个字符进行转义。如\r,\n,\\,\.,\$ |
|
() |
对表达式进行分组,将圆括号内的内容体作为一个整体,并获得匹配的值。 |
案例:
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print "matchObj.group() : ",matchObj.group()
print "matchObj.group(1) : ", matchObj.group(1)
print "matchObj.group(2) : ", matchObj.group(2)
else:
print "No match!!"
结果:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
一些无法书写或者具有特殊功能的字符,采用在前面加斜杠""进行转义的方法。
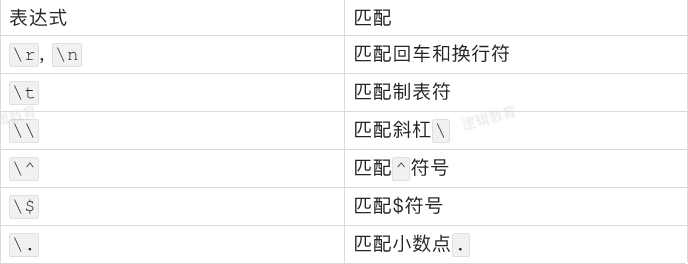
6、预定义匹配字符集
涉及到的正则规则:
\s:用于匹配单个空格符,包括tab键和换行符,等价于 [ \t\n\r\f]。
\S:用于匹配除单个空格符之外的所有字符;
\d:用于匹配从0到9的数字;
\w:用于匹配字母,数字或下划线字符;
\W:用于匹配所有与\w不匹配的字符;
. :用于匹配除换行符之外的所有字符。
可以把\s和\S以及\w和\W看作互为逆运算
7、正则表达式实例
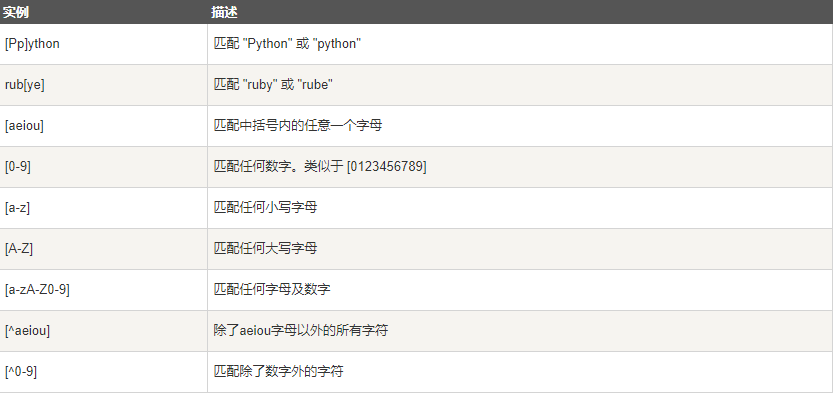
8、match()函数
格式:match(pattern,string,flags=0)
参数说明:
pattern:正则表达式,匹配成功返回match对象,否则返回None
string:要匹配的字符串
flags:标志位于控制正则表达式表达式的匹配方式,如是否区分大小写,多行匹配等。
案例:
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print "matchObj.group() : ",matchObj.group()
print "matchObj.group(1) : ", matchObj.group(1)
print "matchObj.group(2) : ", matchObj.group(2)
else:
print "No match!!"
结果:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
9、re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
pattern = r'\bmr\b'
match = re.search(pattern,'vss mr soft')
print("match:",match)
结果:match: <re.Match object; span=(4, 6), match='mr'>
match2 = re.match(pattern,'vss mr soft')
print('match2:',match2)
结果: match2: None
二、使用findall()方法匹配字符串
使用".* ?"实现非贪婪匹配字符串
import re
pattern = 'https://.*(\d+).com'
match = re.findall(parttern,'https://www.hao123.com')
print(match)
运行结果:['3']
分析:
在贪婪匹配下,"x*"会尽量匹配更多的字符,而"\d+"表示至少匹配一个数字并没有指定数字的多少,所以,".*"将"www.hao12"全部匹配到了,只把数字3留给了"(\d+)" 进行匹配,所以也就有了数字3的结果。
所以,可以使用非贪婪匹配".*?",这样的匹配方式可以尽量匹配更少的字符
修改如下:
import re
pattern = 'https://.*?(\d+).com'
match = re.findall(pattern,'https://www.hao123.com')
print(match) # ['123']
注意:
非贪婪匹配虽然有一定优势,但是如果需要匹配的结果在字符串的尾部时,'.*?'就很有可能匹配不到任何内容,因为它会尽量匹配更少的字符。
import re
pattern = 'https://(.*?)'
match = re.findall(pattern,'https://www.hao123.com/')
print(match)
pattern = 'https://(.*)'
match = re.findall(pattern,'https://www.hao123.com/')
print(match)
运行结果:
['']
['www.hao123.com/']
三、字符串处理
1、替换字符串
sub()方法用于实现将某个字符串中所有匹配正则表达式的部分替换成其他字符串。
格式:
re.sub(pattern,repl,string,count,flags)
参数:
pattern:表示模式字符串,由要匹配的正则表达式转换而来
repl:表示替换的字符串
string: 表示要被查找替换的原始字符串
count: 可选参数,表示模式匹配后替换的最大此时,默认为0,表示替换所有的匹配
flags:可选参数,表示修饰符,用于控制匹配方式,例如是否区分字母大小写。
import re
pattern = r'1[3478]\d{9}'
string = '中奖号码为:84978981 联系电话为: 13635654785'
result = re.sub(pattern,'1XXXXXXXXXX',string)
print(result)
运行结果:中奖号码为:84978981 联系电话为: 1XXXXXXXXXX
sub()方法除了有替换字符串的功能外,还可以使用该方法实现删除字符串中我们所不需要的数据。
import re
string = 'hk400 jhkj6h7k5 jhkjhk1j0k66'
pattern = '[a-z]'
match = re.sub(pattern,'',string,flags=re.I)
print(match)
运行结果:
400 675 1066
在re模块中还提供了一个subn()方法,该方法也能实现替换字符串的功能,此外,还可以返回替换的数量。
import re
string = 'John,I like you to meet Mr.Wang,Mr Wang,this is our Sales Manager John.Hohn,this is Mr .Wang.'
pattern = 'Wang'
match = re.subn(pattern,'Li',string)
print(match)
运行结果:
('John,I like you to meet Mr.Li,Mr Li,this is our Sales Manager John.Hohn,this is Mr .Li.', 3)
替换后返回的数据为一个元组
2、分割字符串
split()方法用于实现根据正则表达式分割字符串,并以列表的形式返回。
格式:
re.split(pattern,string,[maxsplit],[flags])
参数格式:
pattern: 表示模式字符串,由要匹配的正则表达式转换而来。
string:表示要匹配的字符串。
maxsplit:可选参数。表示最大的拆分次数
flags: 可选参数,表示修饰符,用于控制匹配方式。如是否区分字母大小写。
import re
pattern = r'[?|&]' # 定义分割符
url = 'http://www.mingrisoft.com/login.jsp?username="mr"&pwd="mrsoft"'
result = re.split(pattern,url) # 分割字符串
print(result)
运行结果:
['http://www.mingrisoft.com/login.jsp', 'username="mr"', 'pwd="mrsoft"']
如果需要分割的字符串非常大,并且不希望使用模式字符串一直分割下去,此时可以指定split()方法中的maxsplit参数指定最大的分割次数。
import re # 导入re模块
# 需要匹配的字符串
string = '预定|K7577|CCT|THL|CCT|LYL|14:47|16:51|02:04|Y|'
pattern = '\|' # 表达式
match = re.split(pattern,string,maxsplit=1) # 匹配字符串,通过第一次出现的|进行分割
print(match)
运行结果:['预定', 'K7577|CCT|THL|CCT|LYL|14:47|16:51|02:04|Y|']
四、compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
格式:re.compile(pattern[,flags])
参数说明:
pattern:正则表达式
flags:匹配模式,如忽略大小写导尿管
re.I:忽略大小写
re.L:表示特殊字符集:\w,\W,\b,\B,\s,\S依赖于当前环境
re.M:多行模式
re.S:为"."并且包含换行符在内的任意字符('.'不包含换行符)
re.U:表示特殊字符集\w,\W,\b,\B,\s,\S依赖于Unicode字符属性数据库
re.X:为了增添加可读性,忽略空格和'#'的注释
import re
rel = re.compile('python')
str1 = 'python and python'
matchalls = re.match(rel,str1).group()
print("matchalls:",matchalls) # matchalls: python
searchalls = re.search(rel,str1).group() # searchalls: python
print('searchalls:',searchalls)
findAlls = re.findall(rel,str1)
print("findAlls:",findAlls) # findAlls: ['python', 'python']
五、案例:爬取编程e学网视频的几种方法
1、使用requests和re模块
import requests
import re
url = 'http://site2.rjkflm.com:666/index/index/view/id/1.html'
# 定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
response = requests.get(url=url,headers=header)
if response.status_code == 200:
# 通过正则表达式匹配视频地址
# .*? 表示匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复
result = re.findall('<source src="(.*?)" type="video/mp4"',response.text)
video_url = "http://site2.rjkflm.com:666/" + result[0]
video_response = requests.get(url=video_url,headers=header)
if video_response.status_code == 200:
data = video_response.content
with open('下载视频.mp4','wb') as file:
file.write(data)
2、使用requests_html与re模块
from requests_html import HTMLSession,UserAgent
import re
url = 'http://site2.rjkflm.com:666/index/index/view/id/1.html'
session = HTMLSession()
user_agent = UserAgent().random
response = session.get(url,headers={'user-agent':user_agent})
if response.status_code == 200:
# 通过正则匹配视频地址
result = re.findall('<source src="(.*?)" type="video/mp4"',response.text)
video_url = "http://site2.rjkflm.com:666/" + result[0]
video_response = session.get(url,headers={'user-agent':user_agent})
if video_response.status_code == 200:
data = video_response.content
with open('下载视频2.mp4','wb') as file:
file.write(data)
3、使用urllib3 与re
import urllib3
import re
url = 'http://site2.rjkflm.com:666/index/index/view/id/1.html'
http = urllib3.PoolManager()
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
response = http.request('GET',url=url,headers=header)
if response.status == 200:
content = response.data.decode('utf-8')
result = re.findall('<source src="(.*?)" type="video/mp4"',content)
video_url = "http://site2.rjkflm.com:666/" + result[0]
video_response = http.request('GET',url,headers=header)
if video_response.status == 200:
data = video_response.data
with open('下载视频3.mp4','wb') as file:
file.write(data)
4、使用urllib.request与re
import urllib.request
import re
from fake_useragent import UserAgent
url = 'http://site2.rjkflm.com:666/index/index/view/id/1.html'
【
response = urllib.request.urlopen(url)
或者
headers = {
'User-Agent':UserAgent().random
}
request = urllib.request.Request(url=url,headers=header)
# Request 构建一个多种功能的请求对象
response = urllib.request.urlopen(request)
】
if response.status == 200:
content = response.read().decode('utf-8')
result = re.findall('<source src="(.*?)" type="video/mp4"',content)
video_url = "http://site2.rjkflm.com:666/" + result[0]
video_response = urllib.request.urlopen(video_url)
if video_response.status == 200:
data = video_response.read()
with open('下载视频4.mp4','wb') as file:
file.write(data)
六、re.finditer
和findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回
re.finditer(pattern, string, flags=0)
import re
it = re.finditer(r"\d+","12a32bc43jf3")
for match in it:
print (match.group())
七、正则表达式修饰符 - 可选标志




















 2906
2906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











