




 本文档介绍了基于SSM的Java文档搜索引擎项目,采用ansj分词库,无爬虫程序,直接处理已下载的Java文档。项目包含前端搜索与展示页面,后端包括索引、搜索和Web模块。索引部分由ScanAnalysis和Index类处理,搜索模块由Searcher类实现,Web模块负责前后端交互。
本文档介绍了基于SSM的Java文档搜索引擎项目,采用ansj分词库,无爬虫程序,直接处理已下载的Java文档。项目包含前端搜索与展示页面,后端包括索引、搜索和Web模块。索引部分由ScanAnalysis和Index类处理,搜索模块由Searcher类实现,Web模块负责前后端交互。
项目介绍
Java文档搜索引擎项目是一个SSM项目,该项目的前端界面部分是由搜索页面和展示页面组成,后端部分索引模块(ScanAnalysis、index)、搜索模块(Searcher)、Web模块(SearcherController)。该项使用ansj第三方分词库进行分词,该项目并没有使用爬虫程序来获取Java文档,而是直接将Java文档下载下来,将Java文档里面的内容进行分词保存到正排索引文件和倒排索引文件中。
项目使用的技术栈
HTML、CSS、JS、Ajax、SpringBoot、SpringMVC
前端页面展示
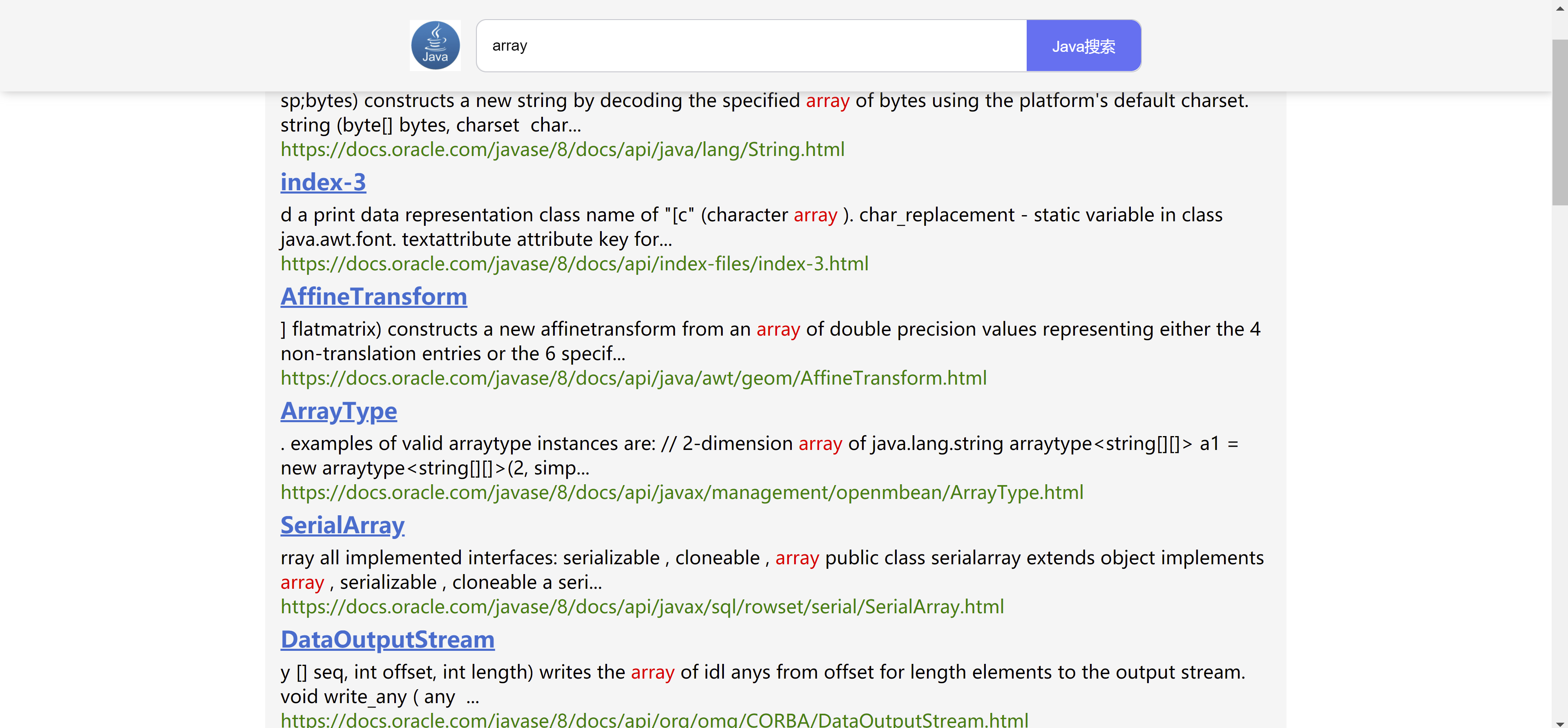
搜索页面:

显示页面:
后端逻辑部分
索引部分
索引部分底层实现了两个类:ScanAnalysis类、Index类
***ScanAnalysis类:***用来扫描Java文档中的所有HTML文件,将HTML文件的标题、url路径、正文保存到正排索引文件和倒排索引文件中。
***Index类:***底层实现了正排索引结构和倒排索引结构,Index类是配合ScanAnalysis类一起使用的,Index将HTML文件内容保存到正排索引和倒排索引结构中,最终保存到正排索引文件和倒排索引文件中。
ScanAnalysis类的底层代码:
public class ScanAnalysis {
//要扫描的根路径
private static final String PATH_ROOT = "D:\\知识复习思维导图(Java)和Java笔记\\project-warehouse\\jdk-8u351-docs-all\\docs\\api";
//Java文档的网络地址 不同部分
private static final String JAVA_PATN = "https://docs.oracle.com/javase/8/docs/api/";
//索引对象
private static Index index = new Index();
/**
* 启动方法
* 我们在进行扫描的时候,我们会发现在进行扫描的时候效率是比较低的。
* 该方法使用的是单线程的方式
* 我们可以使用多线程的方式来提高效率
*/
public void run() {
long ben1 = System.currentTimeMillis();
//保存每一个文档的路径
ArrayList<String> arrayList = new ArrayList<>();
//1.获取每一个文档的路径
scanPath(PATH_ROOT,arrayList);
long ben = System.currentTimeMillis();
//2.对每一个html文件进行解析
for (String pathChild:arrayList) {
analysis(pathChild);
}
long end = System.currentTimeMillis();
System.out.println("解析所花费的时间:"+(end - ben)+"ms");
//3.将索引保存的索引文档中
index.saveFile();
long end1 = System.currentTimeMillis();
System.out.println("整个程序的时间:"+(end1 - ben1) +"ms");
}
/**
* 启动方法2:我们对解析这个步骤使用多线程的方式来提高效率
*
*/
public void run2() {
long ben1 = System.currentTimeMillis();
//保存每一个文档的路径
ArrayList<String> arrayList = new ArrayList<>();
//1.获取每一个文档的路径
scanPath(PATH_ROOT,arrayList);
long ben = System.currentTimeMillis();
//2.对每一个html文件进行解析
//我们创建一个有时光线程的线程池
ExecutorService executorService = Executors.newFixedThreadPool(15);
//这个CountDownLatch对象,是用来表明需要等待多少个任务才结束
//因为我们要等到解析这个过程完成了在执行下一步
CountDownLatch countDownLatch = new CountDownLatch(arrayList.size());
for (String pathChild:arrayList) {
//将解析的工作提交倒线程池中
executorService.submit(new Runnable() {
@Override
public void run() {
analysis(pathChild);
//完成一次解析任务就减一
countDownLatch.countDown();
}
});
}
try {
//等待任务结束,如果没结束,就阻塞等待
countDownLatch.await();
//关闭线程池
executorService.shutdown();
} catch (InterruptedException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("解析所花费的时间:"+(end - ben)+"ms");
//3.将索引保存的索引文档中
index.saveFile();
long end1 = System.currentTimeMillis();
System.out.println("整个程序的时间:"+(end1 - ben1) +"ms");
}
/**
* 对 HTML文件进行解析
* 获取到题目、正文、url
* @param pathChild
*/
private void analysis(String pathChild) {
File file = new File(pathChild);
//1.获取标题
String title = getTitle(file);
// System.out.println(title);
//2.获取正文
String content = getContents(file);
//3.获取url
String url = getUrl(file);
System.out.println(url);
//4.将标题、正文、url保存到索引中
index.saveIndex(title,content,url);
}
/**
* 获取url
* @param file
* @return
*/
private String getUrl(File file) {
StringBuilder stringBuilder = new StringBuilder();
String str = file.getAbsolutePath().substring(PATH_ROOT.length()+1);
for (int i = 0; i < str.length(); i++) {
char ch = str.charAt(i);
if (ch != '\\') {
stringBuilder.append(ch);
} else {
stringBuilder.append('/');
}
}
return JAVA_PATN+stringBuilder.toString();
}
/**
* 获取正文,这个比较麻烦,我们需要去除标签,和<script></script>里面的内容
* 这里我们需要使用正则表达式
* @param file
* @return
*/
public String getContents(File file) {
//获取到HTML里面的内容
String content = getcontentHtml(file);
//使用正则表达式,将<script></script>标签和里面的内容都替换掉
//字符串中的replaceAll方法是支持正则表达式的
content = content.replaceAll("<script.*?>(.*?)</script>"," ");
//使用正则表达式,去除其他标签
content = content.replaceAll("<.*?>"," ");
//使用正则表达式,去除连续的空格
content = content.replaceAll("\\s+"," ");
return content ;
}
/**
* 获取到HTML文件的内容,这人进行文件读取操作,
* 使用字符流,进行读取
* @param f
* @return
*/
private String getcontentHtml(F 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1352
1352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









