



[2403.08319] Knowledge Conflicts for LLMs: A Survey 2024-03
https://github.com/pillowsofwind/Knowledge-Conflicts-Survey
https://www.zhihu.com/question/625481187/answer/3558297769

引言:

LLM受到retrieved documents,user prompt,Parametric Knowledge(Memory)三者的影响。并且这三者信息也会有错误。
根据冲突信息的来源,可以两两组合划分下面三个类别:
1. Context-Memory Conflict 即上下文和参数知识之间的冲突。例子1:模型通过Web检索获取的知识是即时的,但学到的知识已经“过气”;例子2:模型获得了错误的假信息,与参数知识发生了冲突。
2. Inter-Context Conflict 即上下文知识内部的冲突。例子:通过Web检索,获得的信息因为发布的时间不同,或是混入了恶意的有误信息而自相冲突。
3. Intra-Memory Conflict 即参数化知识内部的冲突。例子:对于事实性问答,模型在语义相同的提示一下被激发出不同结果的答案,产生出自相矛盾的效果。
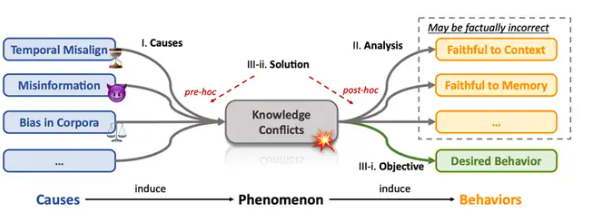

模型通过web或其他方式检索的只是是即时的,但学到的知识是过时的;模型在检索中可能会遇到错误的恶意信息,和其参数只是(记忆)冲突。
1.预防措施
○ 持续学习(Continue Learning):通过持续预训练模型以纳入新的和更新的数据,从而减少时间错位带来的影响。例如,Lazaridou等人(2021)建议通过持续预训练来更新模型的内部知识,以跟上最新的信息。
○ 知识编辑(Knowledge Editing):直接更新已训练模型的参数知识,以反映最新的信息。例如,De Cao等人(2021)提出了一种知识编辑方法,旨在直接修改模型的内部知识,以纠正错误或过时的信息。但是知识编辑的一个弊端是可能会导致模型出现内在冲突的知识,即诱发后面我们提到的intra-memory conflict。
○ 检索增强生成(RAG):利用检索模块从外部资源(例如数据库或网络)获取相关文档,以补充模型知识,而无需改变模型参数(Karpukhin 等,2020;Guu 等,2020;Lewis 等,2020;Lazaridou 等,2022;Borgeaud 等,2022;Peng 等,2023;Vu 等,2023)
2. 应对措施
○ 微调模型(Fine-Tuning):通过引入反事实和无关上下文等方法,加强模型对上下文的控制能力和鲁棒性。例如,Li等人(2022)提出的知识感知细调(KAFT)方法,通过在标准训练数据集中引入反事实和无关上下文,增强了模型在面对冲突信息时的鲁棒性。
○ 提示语技术(Prompting):通过专门设计的提示语策略,增强模型对上下文的依赖。例如,Zhou等人(2023)提出了简洁的 context-faithful prompting的技术,显著提升了模型在上下文敏感任务中的表现。
○ 知识插入(Knowledge Plug-in):通过插件模块存储更新的知识,确保原始模型不受影响。例如,Lee等人(2022)提出的持续更新QA(CuQA)方法,通过知识插件增强模型的知识更新能力,而不影响其原有参数。
○ 解码技术(Decoding):通过调整解码策略,减少模型在知识冲突情况下生成幻觉的概率。例如,Shi等人(2023)提出的上下文感知解码(CAD)方法,通过放大输出概率的差异,优先考虑上下文信息,从而减少模型在冲突信息下的误导。
通过结合这些预防和应对措施,可以从不同角度提高模型在处理Context-Memory Conflict时的准确性和鲁棒性,从而提升模型在实际应用中的表现和用户体验。
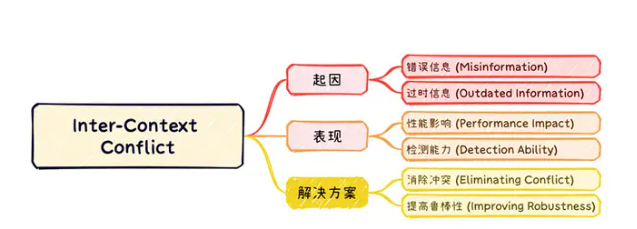
在检索外部信息可能受到外部错误信息和过时信息的影响。
1. 消除冲突(Eliminating Conflict)
○ 专用模型(Specialized Models):专门训练一个模型来更好地处理特定类型的冲突。如Pielka等(2022)建议在学习过程中加入语言学知识,通过引入语法和语义特征来增强对矛盾信息的识别,以提高模型对矛盾检测的能力。
○ 通用模型(General Models):使用通用模型来完成冲突消除。Chern等(2023)提出了一个整合了多种工具(如Google Search、Google Scholar等)的事实核查框架,用于检测文本中的事实错误。这种方法不仅依赖于模型的内部知识,还结合了外部检索到的信息,提供更为全面的事实验证。
2. 提高鲁棒性(Improving Robustness)
○ 训练方法(Training Approach):从训练算法上提升模型在面临冲突上下文时的鲁棒性。Hong等(2023)提出了一种新的微调方法,通过同时训练判别器和解码器来提高模型的鲁棒性。这种方法不仅可以提高模型在面对冲突信息时的稳定性,还能增强其处理复杂信息的能力。
○ 查询增强(Query Augmentation):在推理阶段通过进一步引入外界知识来提升模型的鲁棒性。Weller等(2022)提出了一种查询增强技术,提示GPT-3从原始查询中提取新的问题,通过生成多个与原始问题相关的查询,模型可以从多个角度验证答案的正确性,从而减少由于单一信息源导致的错误。这种方法不仅提高了模型应对冲突信息的能力,还增加了其回答的准确性和可靠性。
Inter-Context Conflict是知识冲突中的重要一环。大模型如何处理相互冲突的信息是一个关键任务。通过上述方法,可以从不同角度提高模型在处理Inter-Context Conflict时的准确性和鲁棒性。
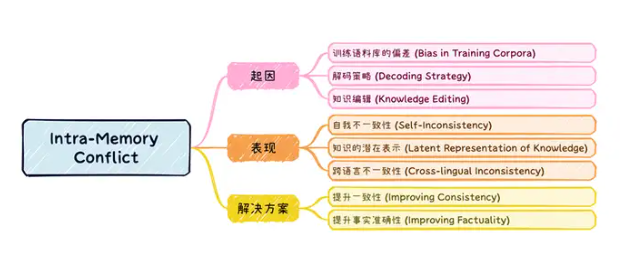
Intra-Memory Conflict是指LLM在面对意思一样但句法不同时输出不一致的问题。主要是因为预训练语料库的质量参差不齐;LLM输出解码时有不同的解码策略(贪心,top-p,top-k)会导致内容随机性,知识编辑技术旨在高效地修改模型中小范围的知识,而不需要重新训练整个模型。然而,这些编辑方法可能导致知识的一致性难以保证。
1. 提升一致性(Improving Consistency)
○ 微调(Fine-tuning):通过引入一致性损失函数,并结合标准的语言模型训练损失,进行微调,提升模型的知识一致性。例如,Li等人(2023)则利用模型生成的回答对其进行验证,筛选出一致性较高的回答对进行微调,进一步提升生成的答案的一致性。
○ 插件(Plug-in):通过模块插入的整合方法提高模型的一致性。例如,Jang和Lukasiewicz(2023)提出通过利用字典中的词义对模型进行训练,增强其对符号意义的理解。然后将这些增强的参数与现有语言模型的参数合并从而提高模型的一致性。
○ 输出集成(Output Ensemble):通过对多次输出进行综合,从而获得一个最正确的答案。Mitchell等人(2022)提出了这种双模型架构,通过评估答案间的逻辑一致性来选择最可信的最终答案,减少模型生成的不一致性。
2. 提升事实准确性(Improving Factuality)
提升模型响应的真实性,从而减少模型自身不一致的发生。例如,Li等人(2023)提出了一种知识探测方法,通过识别模型参数中包含的真实知识,并在推理阶段沿着这些真实知识相关的方向调整激活,从而减少生成过程中的事实错误。
内部记忆冲突是LLMs研究中的一个重要挑战,解决这一问题需要从训练、生成和后处理等多个阶段入手。虽然目前的解决方案已经在一定程度上缓解了这一问题,但仍有许多挑战需要克服。
context-memory conflict
Decoding - CAD
[2305.14739] Trusting Your Evidence: Hallucinate Less with Context-aware Decoding 2023-05
可通过这种方式增强LLM对 检索知识的
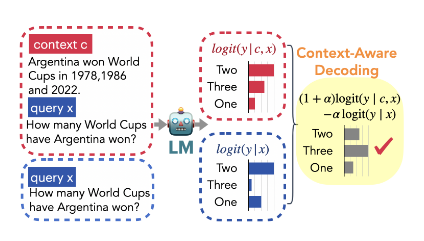
给定一个语言模型 θ、一个输入查询 x 和包含一些外部知识的上下文 c ,我们要求模型 θ 在查询和上下文的基础上生成一个响应 y。该响应可以直接从条件概率分布中进行采样(自回归方式):
![]()
为了缓解此类问题,通过对比性地将先验知识从模型原始的输出分布去除。我们将先验知识建模为

,并使用上下文c和生成

的点互信息调整模型的输出概率分布。

Pre-training - ICLM
ICLR 2024

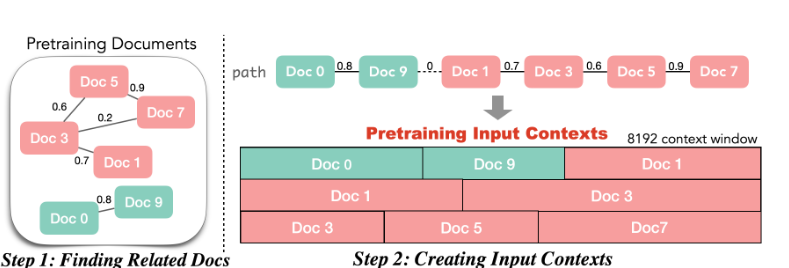
提出了两种方法来对文档进行排序以让训练过程能够通过相关文档获取更多信息。
- 检索模型与高效搜索索引:通过语义嵌入空间中的相似性,构建一个文档图,将每个文档与其在语义上最相似的文档配对。
- 旅行商问题排序算法:我们将文档排序问题形式化为旅行商问题(TSP),并开发了一种有效的算法,最大化文档与其上下文的相似性,同时确保每个文档只出现一次。


















 1644
1644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









