




http://arxiv.org/abs/2106.08657
要了解本论文,最好先看一下ATLOP论文和E2GRE论文,本文提出的EIDER模型是在这两个模型上进行改进的模型。
目录
3 Joint Relation and Evidence Extraction
4 Evidence-centered Relation Extraction
5 Fusion of Extraction Results
1 摘要

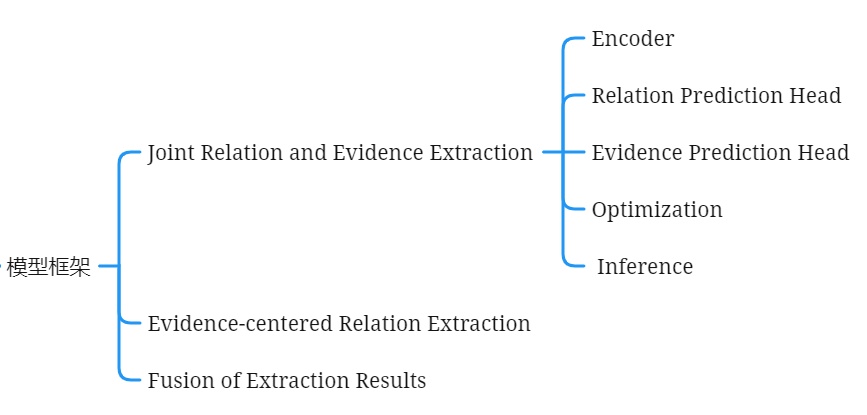
在文档关系抽取任务中,文档中某一部分句子可以称为证据句,它们可以充分地预测实体对之间地关系,而不需要其他的非证据句。因此,为了更好地使用证据句,我们提出了一个三阶段的证据增强模型-EIDER。三个阶段分别是:joint relation and evidence extraction,evidence-center relation extraction,and fusion of extraction results.我们首先联合训练一个RE模型和一个简单且内存高效的证据提取模型。然后,我们根据提取的证据语句构造伪文档,并再次运行RE模型。
一方面,如果提取的证据完全准确,直接使用提取的证据进行预测可以简化原始文档的结构,从而使模型更容易做出正确的预测。另一方面,提取证据的质量并不完美。此外,原始文件中的非证据句也可能提供实体的背景信息,并可能有助于预测。因此,仅仅依靠这些预测出的证据句子可能会导致信息丢失,并导致次优性能。因此,我们将原始文档和提取的证据上的预测结果结合起来。
2 动机
为了充分地利用证据句,使模型更容易做出正确的预测。但同时避免信息的丢失,仍然可以访问整个文档。因此既从原文档中提取关系,也从伪文档中中提取关系。
模型设计
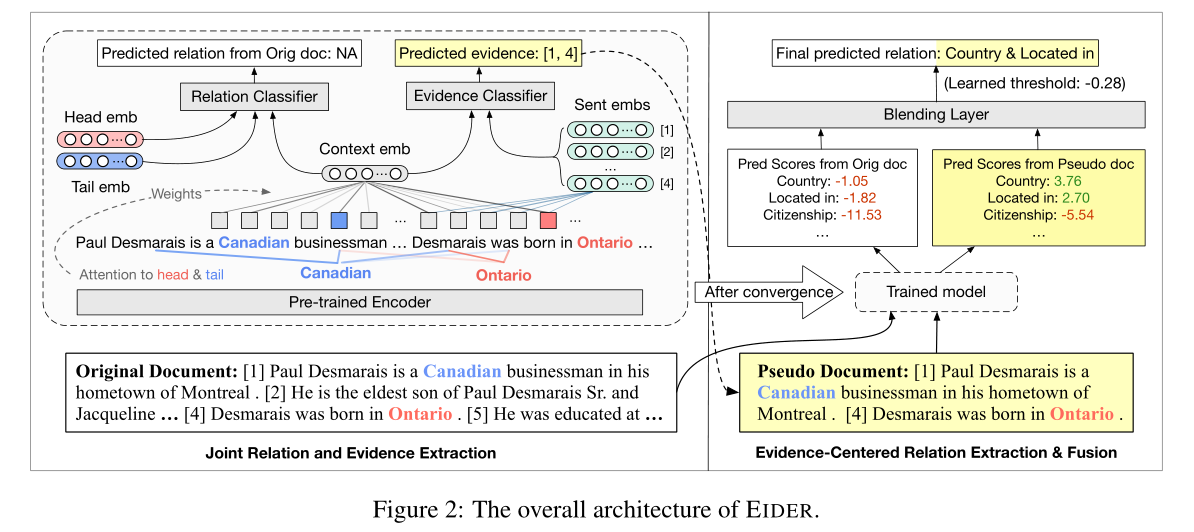
三个阶段:
阶段一:
训练关系提取模型和证据提取模型
在两个模型中都采用了局部上下文池化,得到实体对的上下文表示
阶段二:
把真正的证据句按照原文档中出现的顺序连接起来,然后用阶段一中提取到的证据句替换真正的证据句,把该文档视为伪文档,阶段一的关系提取模型上进行关系的预测,得到关系预测的分数即概率值(无需再训练关系提取模型,因为阶段一已经训练过了)
阶段三:
将阶段一得到的关系预测分数和阶段二得到的关系预测分数进行融合,得到最终的关系预测分数。
3 Joint Relation and Evidence Extraction
3.1 Encoder
3.1.1 目的
得到文档的上下文表示,实体的embedding,实体对的上下文信息(局部上下文池化)
3.1.2 步骤
- 在提及前后插入"*"
- 将文档序列送入Encoder中,得到文档的上下文表示embedding
- 将提及前的一个“*”的embedding作为该提及的embedding
- 我们对一个实体的所有提及采用logsumexp池化得到该实体的embedding
- 从预训练模型中得多头的attention,将每个提及的token的attention求平均,得到提及的attention,再将提及的attention求平均,得到实体的attention
- 然后,将头实体和尾实体的attention的注意力相乘,并累加多头的结果,放入softmax函数中,得到最终的实体对entity pair的attention
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 994
994




 到【灌水乐园】发言
到【灌水乐园】发言







