




一、文献基本信息
题目:Large Language Models Know What is Key Visual Entity: An LLM-assisted Multimodal Retrieval for VQA
会议:EMNLP 2024 (CCF-B会)
作者:Pu Jian(中科大),Donglei Yu(中科大),Jiajun Zhang(中科大)
二、研究背景和意义
视觉问答(VQA)任务通常由视觉语言模型(VLM)完成,面临着长尾知识的挑战。最近的检索增强VQA (RA-VQA)系统通过检索和集成外部知识来源来解决这个问题。然而,这些系统在检索过程中仍然存在与问题无关的冗余视觉信息。
为了解决这些问题,本文提出了一种利用大语言模型(LLM)的推理能力来识别关键视觉实体的新方法LLM-RA,从而最大限度地减少了检索器查询中不相关信息的影响。此外,针对多模态联合检索,关键视觉实体被独立编码,避免了跨实体干扰。
实验结果表明,该方法优于其他RA-VQA增强系统。在两个知识密集型VQA基准测试中,我们的方法在参数规模相似的模型中达到了新的最先进的性能,甚至可以与参数大1-2阶的模型相媲美。
三、研究方法
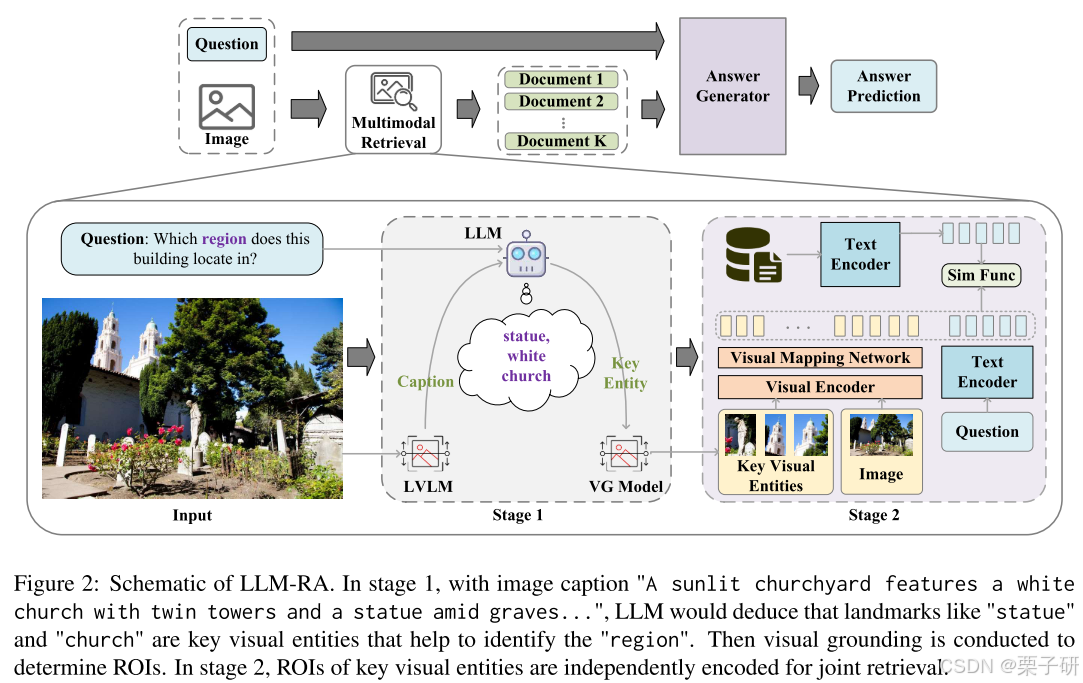
1.关键视觉实体的提取
1)General Information from Image Captions
利用LVLM,将图像转换成文字描述。
输入:问题:Which region does thisbuilding locate in?
输出:图片描述:"A sunlit churchyard features a white church with twin towers and a statue amid graves..."
2)LLM-assisted Key Entity Extraction
LLM利用文字描述和问题,结合上下文示例进行推理,以结构化的形式给出关键视觉实体及其属性。
输入:问题,图片描述
输出:关键实体的结构表达式:{"statue": "amid graves"}
3)Visual Grounding
利用现有的引用表达式理解模型(referring expression comprehension model),确定与这些实体对应的兴趣区域(ROI,region of interest)
输入:关键实体的结构表达式
输出:关键实体的引用表达式:"The statue that amid graves",关键实体的ROI
2.多模态联合检索
1)Independent visual representation
使用CLIP编码器对图片
和关键视觉实体
编码;
使用基于Transformer的编码器对问题
编码;
预训练一个大型的图像-文字配对的映射网络,将视觉特征映射到文本特征域上。
将所有嵌入和
嵌入连接,得到最终查询
,其中
代表第
个关键实体的
,总共有
个
;
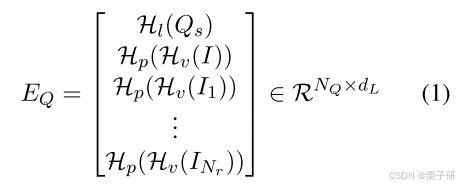
使用基于Transformer的编码器对外部知识
编码,得到token级别的知识表示
。
![]()
2)Joint retrieval
计算(,
)和外部知识
的相似度
![]()
与DPR (Karpukhin et al., 2020)将和
压缩为一维嵌入不同,式(3)在词、短语和视觉实体级别上建模它们的相关性。它防止了不同关键视觉实体和文本信息之间的干扰。
3.答案生成
将文本嵌入(问题和检索文档)与视觉嵌入连接,输入给答案生成器。它将针对每个检索文档生成一个答案,并基于联合检索的相似度选择最佳答案。
四、实验方法
1.实现
图像描述生成:MiniGPTv2
关键实体提取:frozen LLM of MiniGPTv2
视觉接地:Grounding-Dino
文本编码器:ColBERTv2
图像编码器:CLIP ViT-base
外部知识文档:FAISS
联合检索:采用对比损失作为损失函数,引入批内负样本采样(In-batch negative sampling)
答案生成器:BLIP2-Flan-T5-XL,使用LoRA微调
数据集:OK-VQA,Infoseek
评估方法:Recall@K,VQA指标
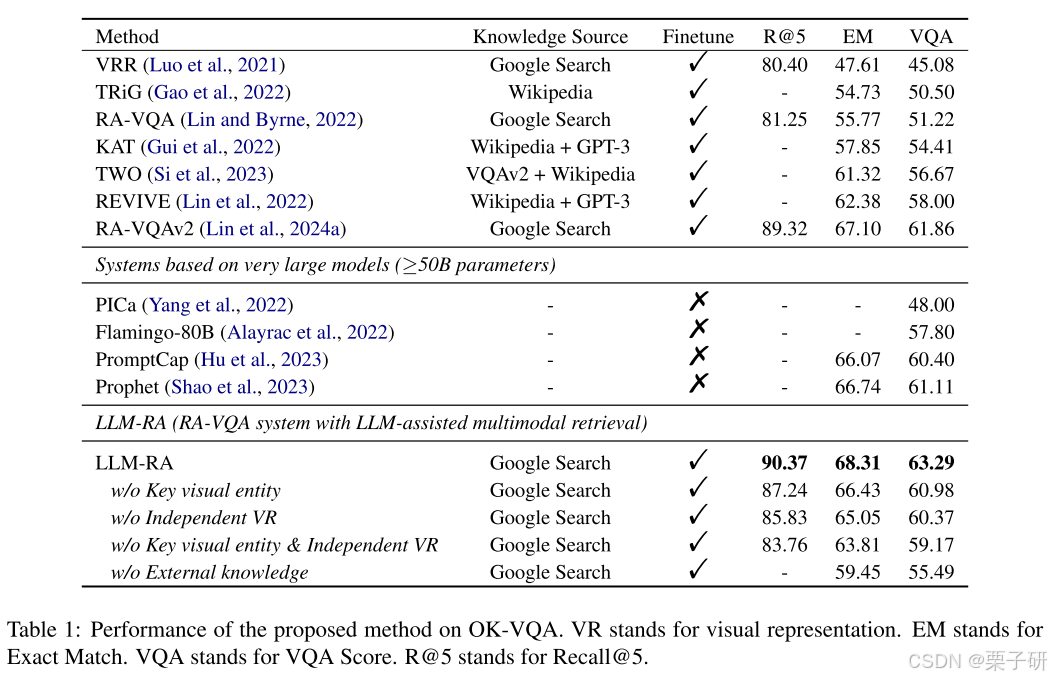
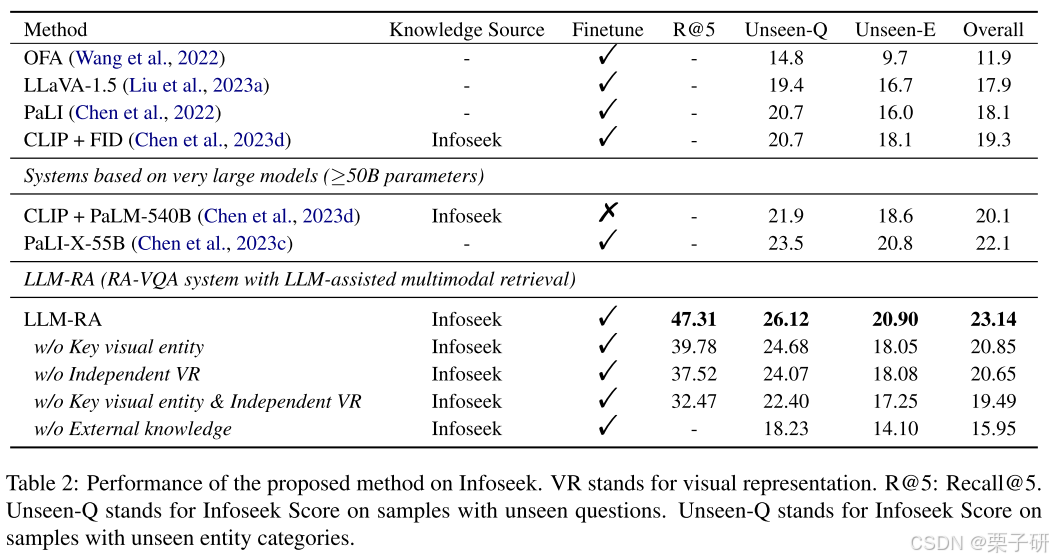
2.对比实验&消融实验
OK-VQA - 63.29;Infoseek - 23.14
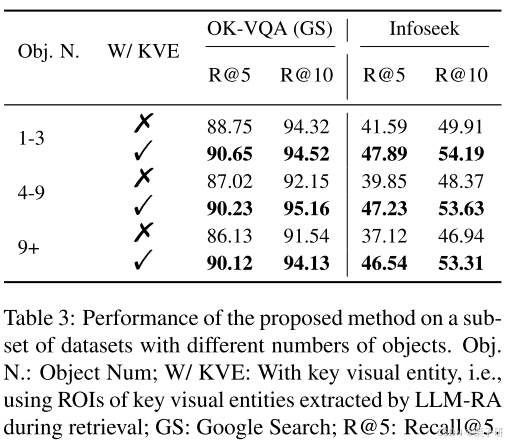
3.不同对象数量下的性能
除了关键的视觉实体外,包含更多对象的图像通常还会呈现更多冗余信息。因此,我们根据图像中物体的数量将测试数据集划分为多个子集,以评估LLM-RA在不同信息冗余级别上检索性能的改进。
如表3所示,实验结果表明,LLM-RA在对象数量较多的子集中获得的收益更大。这一发现与预期一致,即从图像中删除冗余的视觉信息,并在查询中的视觉嵌入中强调相关的视觉细节,能够提高检索性能。
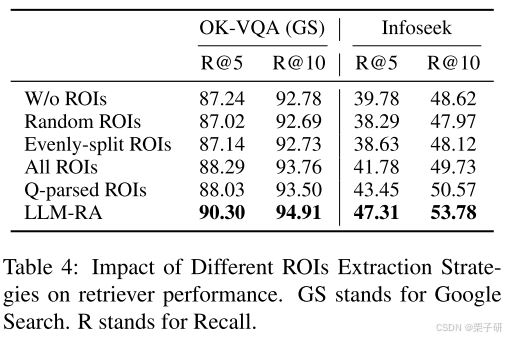
4.关键视觉细节提取方法的影响
为了证明关键视觉实体的性能提高来自于在检索过程中包含与问题相关的细粒度视觉细节,而不仅仅是增加特征的数量,我们将我们的方法与其他ROI提取方法对检索性能的影响进行了比较。比较的方法包括:
1)随机裁剪图像中大于100 × 100像素的小块作为ROI(随机ROI);
2)将图像均匀划分为ROI (even-split ROI);
3)基于性能良好的目标检测器获得ROI(所有ROI);
4)仅根据问题解析的实体进行视觉接地,获得ROI (基于Q解析的ROI);
5) LLM-RA中的方法(关键roi)。
如表4所示,使用我们的关键视觉细节提取方法提取的ROI优于其他方法。这表明LLM辅助的视觉细节提取在保留与问题相关的细粒度视觉细节的同时,有效地去除了查询中的冗余视觉信息,从而提高了RA-VQA系统的性能。
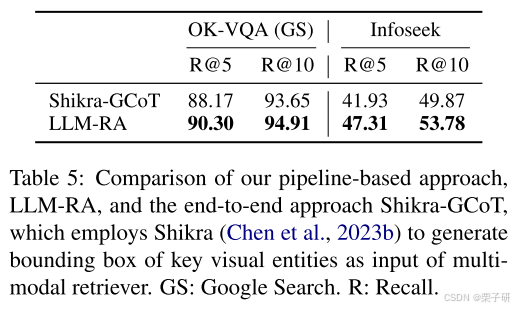
5.基于管道和端到端方法的比较
LLM-RA是一种基于管道的方法,现在探索该方法是否优于端到端方法。端到端方法使用VLM直接提取与问题相关的关键视觉实体的边界框。我们将管道方法与使用Shikra(Chen等人,2023b)的端到端方法进行了比较,Shikra可以生成关键视觉实体的边界框作为输入(接地CoT),称为Shikra-gcot。表5中的结果显示,与基于Shikra的端到端方法相比,管道方法执行得更好。
为了调查原因,我们从OK-VQA和Infoseek中抽取例子来分析Shikra的输出。我们发现,对于一些问题,Shikra未能执行接地CoT,这可能是由于Shikra在这些数据集中普遍存在细粒度的知识问题,这些问题不在分布范围内(OOD)。然而,目前在多模态领域解决接地CoT的OOD问题的研究有限。相比之下,管道方法的优势在于它能够通过利用已经成熟的组件来实现良好的性能。
6.在人类判定的复杂KI-VQA样本上的性能
我们进一步研究了LLM-RA在复杂KI-VQA样品上的性能。
复杂KI-VQA样本的定义是:
1)如果没有知识检索,人类无法轻易回答问题;
2)回答问题所需的关键视觉实体被大量冗余的视觉信息所掩盖;
3)问题没有指明他们关注的实体,需要跨模态推理。
我们从两个KI-VQA数据集中随机抽取400个VQA样本,要求人类受试者回答附录B中的问卷,以识别复杂的KI-VQA样本。两个数据集中判定为复杂的样本数量和比例如表6所示。LLM-RA对人类判断的复杂KI-VQA样品的性能如表7所示。

在OK-VQA上,Recall@5从64.81%增加到81.48%,而在Infoseek上,从21.43%增加到44.90%。这些结果表明,对于涉及关键实体推理和大量冗余视觉信息的复杂视觉问题,LLM-RA显著优于不使用关键视觉实体的基线系统。这表明LLM-RA在现实场景中有更广泛的应用。
五、个人理解
1.相似度的计算

2.个人理解
该研究提出了一种基于关键实体的研究方法,符合人类直觉。通过LLM提取到问题的关键实体,并根据关键实体划定关键区域,用于后续与外部知识库的检索比对,从而去除冗余信息,避免干扰。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









