一.准备工作
1.加载数据
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms,datasets
import os,PIL,pathlib,warnings
warnings.filterwarnings('ignore')
device =torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device

import pandas as pd
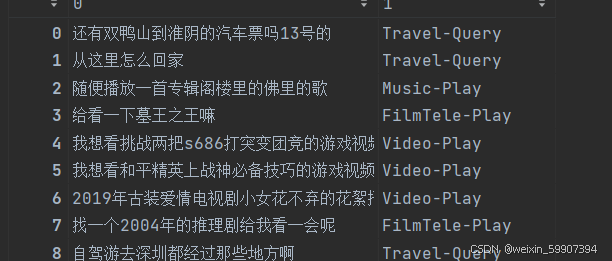
train_data =pd.read_csv('./train.csv',sep='\t',header=None)
train_data
def coustom_data_iter(texts,labels):
for x,y in zip(texts,labels):
yield x,y
train_iter=coustom_data_iter(train_data[0].values[:],train_data[1].values[:])
二.数据预处理
1.构建词典
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
import jieba
tokenizer=jieba.lcut
def yield_tokens(data_iter):
for text,_ in data_iter:
yield tokenizer(text)
vocab=build_vocab_from_iterator(yield_tokens(train_iter),specials=['<unk>'])
vocab.set_default_index(vocab['<unk>'])





 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









