




 LinkedHashSet是HashSet的子类,它在添加元素时维护了一个双向链表,保证了元素的插入顺序。底层实现基于LinkedHashMap,结合数组和双向链表,提供高效的遍历性能。元素的添加会根据hashCode计算位置,并通过before和after属性形成链表,不允许添加重复元素。通过示例代码和源码分析,展示了LinkedHashSet如何确保插入和遍历顺序的一致性。
LinkedHashSet是HashSet的子类,它在添加元素时维护了一个双向链表,保证了元素的插入顺序。底层实现基于LinkedHashMap,结合数组和双向链表,提供高效的遍历性能。元素的添加会根据hashCode计算位置,并通过before和after属性形成链表,不允许添加重复元素。通过示例代码和源码分析,展示了LinkedHashSet如何确保插入和遍历顺序的一致性。
LinkedHashSet的全面说明:
(1)LinkedHashSet是HashSet的子类,在添加数据的同时,每个数据还维护了两个引用,记录此数据前一个数据和后一个数据。对于频繁的遍历操作,LinkedHashSet效率要高于HashSet.
(2)LinkedHashSet底层是一个LinkedHashMap,底层维护了一个数组+双向链表
HashSet为数组+单向链表
(3)LinkedHashSet根据元素的hashCode值来决定元素的存储位置,同时使用链表维护元素的次序,这使得元素看起来是以插入顺序保存的。
(4)LinkedHashSet不允许添重复元素。
我们进入源码进行查看:
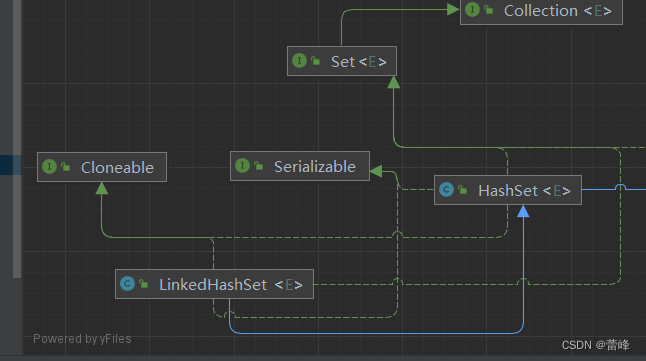
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
LinkedHashSet底层机制说明:
(1)在LinkedHashSet中维护了一个hash表和双向链表(LinkedHashSet有head(头)和tail(尾))
(2)每一个结点有before和after属性,这样可以形成双向链表
(3)在添加一个元素时,先求hash值,在求索引,确定该元素在table的位置,然后将添加的元素加入到双向链表(如果已经存在,不添加【原则和hashset一样】)
tail.next=newElement //示意代码
newElement=tail
tail=newElement;
(4)这样的话,我们遍历LinkedHashSet也能确保插入顺序和遍历顺序一致。
我们设计的代码如下所示:
package com.rgf.set;
import java.util.LinkedHashSet;
import java.util.Set;
@SuppressWarnings({"all"})
public class LinkedHashSetSource {
public static void main(String[] args) {
//分析一下LinkedHashSet的底层机制
Set set = new LinkedHashSet();
set.add(new String("AA"));
set.add(456);
set.add(456);
set.add(new Customer("刘",1001));
set.add(123);
set.add("HSP");
System.out.println("set="+set);
}
}
class Customer{
private String name;
private int no;
public Customer(String name, int no) {
this.name = name;
this.no = no;
}
}
我们运行之后如下所示: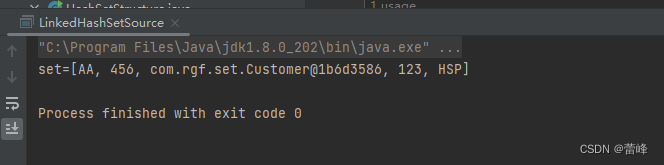
我们根据运行结果,我们发现:LinkedHashSet加入顺序和取出元素/数据的顺序一致
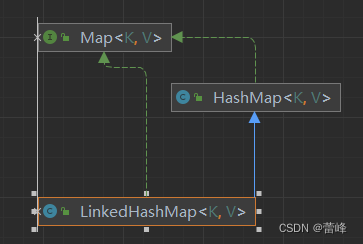
之后我们根据Debug来进行查看:
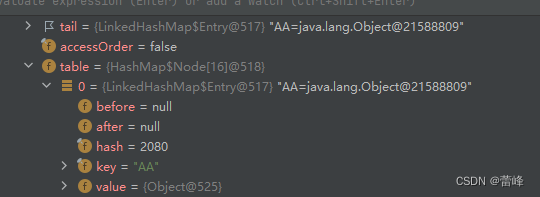
我们发现创建了table表初始化仍然为16个,同时底层发生了变化,table表的元素不再是原先的Node类型了,而是Entry这样子一个对象。添加第一次时,直接将数组table扩容到16,存放的结点类型是LinkedHashMap$Entry,table是HashMap$Node内部类数组的这样子一个类型,但是他里面存放的真实的元素是LinkedHashMap$Entry这种类型,他们之间有继承或者实现关系,Entry继承或者实现了Node。数组是HashMap$Node[],存放的元素/数据是LinkedHashMap$Entry
多态就是父类引用指向子类对象,多态数组就是存放的数据类型是数组类型的子类
我们来进行查看LinkedHashMap的源码来进行了解:
我们进入源码界面后,找到Structure,发现了entey方法: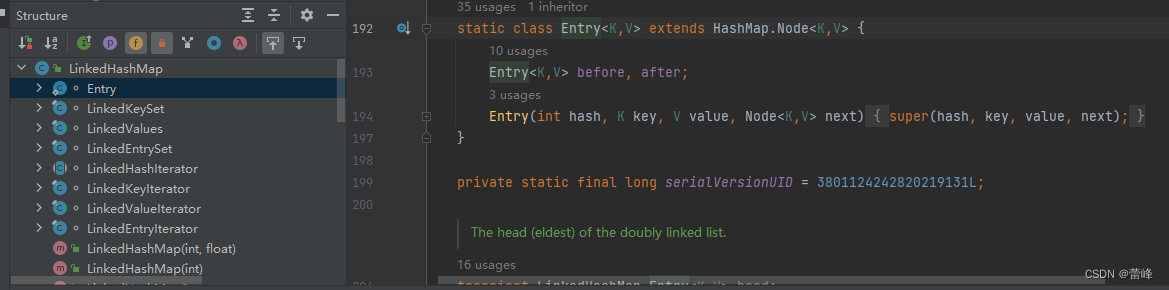
//Entry是LinkedHashMap里面的静态内部类,继承了HashMap.Node
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
我们查看完源码后,继续进行查看:
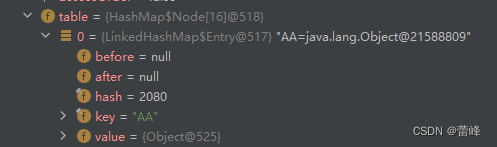
我们进入HashMap源码:
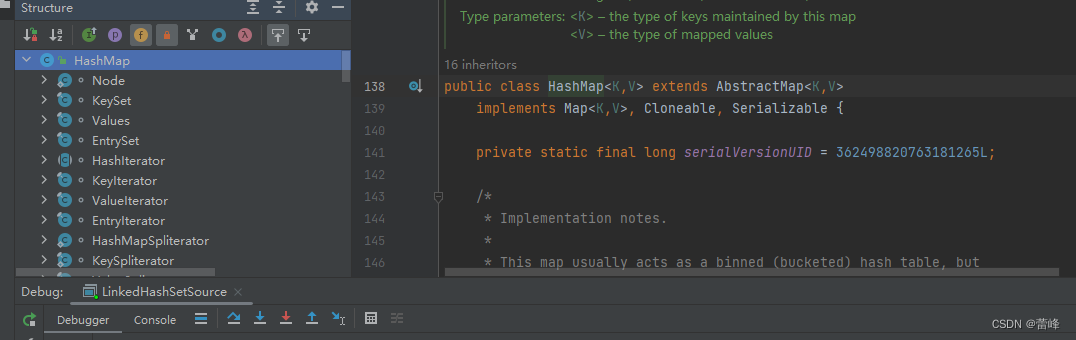
我们找到Node类:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
为静态内部类,底层源码才可以用HashMap.Node
我们添加元素的过程如下所示:
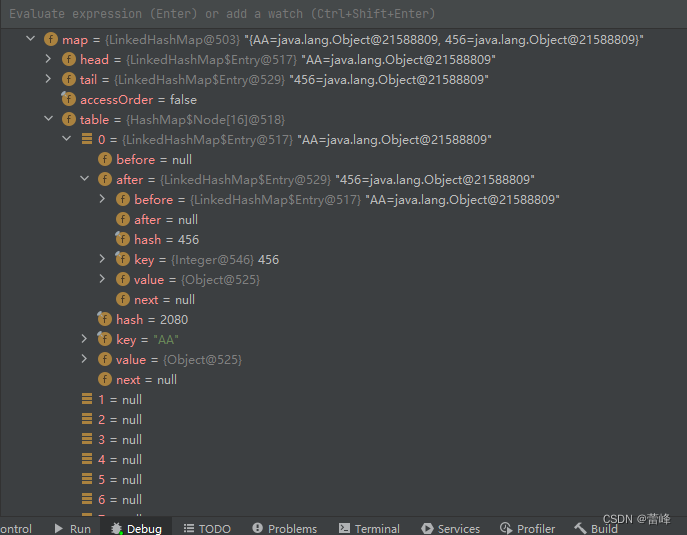
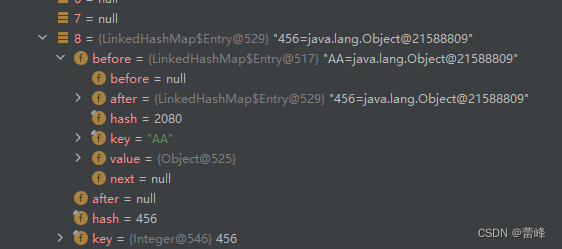
这样子即形成了一个双向链表。
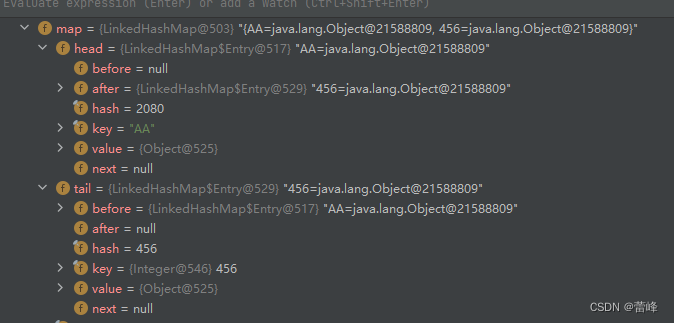
我们还可以进行查看head和tail。
我们的代码如下所示:
package com.rgf.set;
import java.util.LinkedHashSet;
import java.util.Map;
import java.util.Set;
@SuppressWarnings({"all"})
public class LinkedHashSetSource {
public static void main(String[] args) {
//分析一下LinkedHashSet的底层机制
Set set = new LinkedHashSet();
set.add(new String("AA"));
set.add(456);
set.add(456);
set.add(new Customer("刘",1001));
set.add(new Customer("任",1002));
set.add(123);
set.add(new Customer("杨",1003));
set.add("HSP");
System.out.println("set="+set);
//1.LinkedHashSet加入顺序和取出元素/数据的顺序一致
//2.LinkedHashSet底层维护的是一个LinkedHashMap
//3.LinkedHashSet 底层结构(数组+双向链表)
//4.添加第一次时,直接将数组table扩容到16,存放的结点类型是LinkedHashMap$Entry
//table是HashMap$Node内部类数组的这样子一个类型,但是他里面存放的真实的元素是LinkedHashMap$Entry这种类型
//他们之间有继承或者实现关系,Entry继承或者实现了Node.
//5.数组是HashMap$Node[],存放的元素/数据是LinkedHashMap$Entry,
//继承关系是在内部类完成的
}
}
class Customer{
private String name;
private int no;
public Customer(String name, int no) {
this.name = name;
this.no = no;
}
}
实例练习:
Car类(属性:name,price),如果name和price一样,则认为是相同元素,就不能添加。
我们设计的代码如下所示:
package com.rgf.set;
import java.util.LinkedHashSet;
import java.util.Objects;
import java.util.Set;
@SuppressWarnings({"all"})
public class LinkedHashSetExercise {
public static void main(String[] args) {
Set set = new LinkedHashSet();
set.add(new Car("奥拓",1000));
set.add(new Car("奥迪",30000));
set.add(new Car("法拉利",10000000));
set.add(new Car("奥迪",30000));
set.add(new Car("保时捷",70000000));
set.add(new Car("奥迪",30000));
System.out.println("set="+set);
}
}
class Car{
private String name;
private double price;
public Car(String name, double price) {
this.name = name;
this.price = price;
}
//重写equals方法和hashCode
//当name和price相同时,就返回相同的hashCode值,equals返回t
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Car car = (Car) o;
return Double.compare(car.price, price) == 0 && Objects.equals(name, car.name);
}
@Override
public int hashCode() {
return Objects.hash(name, price);
}
@Override
public String toString() {
return "\nCar{" +
"name='" + name + '\'' +
", price=" + price +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
}
运行界面如下所示: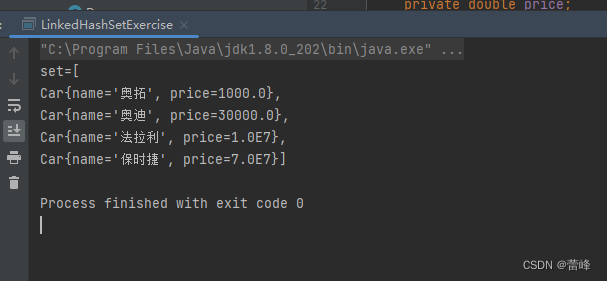


















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











