 Python数据类型详解
Python数据类型详解





Python数据类型详解(整数、浮点数、复数)
整数类型
与数学中整数的概念一致,可正可负,没有取值范围限制。
四种进制表示形式:
十进制:正常数
二进制:以0B或0b开头
八进制:以0o或0O开头
十六进制:以0x或0X开头
**进制转换:计算机可以识别二进制,当输入为十进制为时,先将十进制转换为二进制,然后进行二进制的运算,再进行反向转换(即二进制的运算结果转换为十进制),然后输出即可。**
pow函数:pow(x,y),计算即为x的y次方,想算多大算多大。
实例一:代码界面:

运行界面:

浮点数类型
1.与数学中实数的概念一致
带有小数点及小数的数字
浮点数取值范围和小数精度都存在限制,但常规计算可忽略(及取值范围和精度基本不限制)
取值范围数量级约-10的308次方至10的308次方,精度数量级10的-16次方。
2.浮点数间运算存在不确定尾数,不是bug。
53位二进制表示小数部分,约10的-16次方。
例如:0.1在计算机中表示
二进制是0.000011100111001101(二进制表示)无限的小数,计算机只能截取其中的53位。无限的接近0.1。
十进制的话是0.1000000000055(十进制表示)很长的一个数,只是在计算机中将浮点数在输出的时候只输出了其中的16位小数。
二进制表示小数可以无限接近十进制的小数,但不完全相同。
进制转换:计算机可以识别二进制,当输入为十进制为时,先将十进制转换为二进制,然后进行二进制的运算,再进行反向转换(即二进制的运算结果转换为十进制),然后输出即可。
实例二:例如:
代码界面:

运行界面:
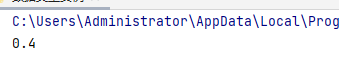
上面运行过程中0.1+0.3=0.4,但也有部分浮点数在运算时有不确定尾数。
例如:
代码界面:
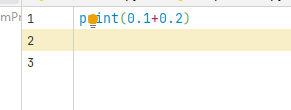
运行界面:
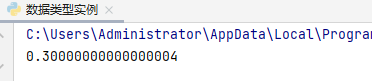
该实例中,代码运行结果并不等于0.3,而是0.3000000000004,出现了不确定尾数,这些情况存在但不是很频繁。计算机可以识别二进制,当输入为十进制为时,先将十进制转换为二进制,然后进行二进制的运算,再进行反向转换(即二进制的运算结果转换为十进制),然后输出即可。将浮点数在输出的时候只输出了其中的16位小数。二进制表示小数可以无限接近十进制的小数,但不完全相同。
可以进行如下证明过程:0.1+0.2==0.3(==为比较运算符,比较两个操作数的值是否相等,如果相等输出true,否则输出false.)
代码界面:
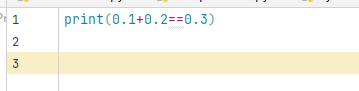
运行界面:

根据结果为False,了解到这两者不相同。
可以采用round函数
round(0.1+0.2,1)==0.3
代码界面:
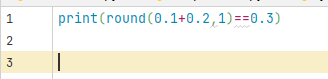
运行界面:

根据运行结果,使用round函数,可以让0.1+0.2=0.3,
round函数
round(x,d):对x四舍五入,d是小数截取位数
浮点数间运算及比较用round()函数辅助。
不确定尾数一般发生在10的-16次方左右,round()十分有效
浮点类型可以采用科学计数法表示:
使用字母e或E作为幂的符号,以10为基数,格式如下:
<a>e<b>
代码界面:
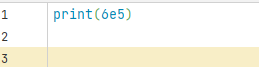
运行界面:

即6e5即为6的10的5次方。
9.6E5=9.6*10的5次方
4.3e-3=4.3*10的-3次方
复数类型(众多编程语言只有python有)
与数学中复数的概念一致(进行空间变换,尤其是跟复变函数相关的科学体系中最常用的一种内型)
a+bj 复数 a为实部,b为虚部
z=1.23e-4+5.6e+89j
z.read 实部
z.imag 虚部
实例三:
代码界面:
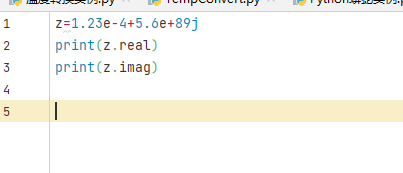
运行界面:



















 709
709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











