



UltraRAG 的开源项目是首个基于 MCP 的检索增强生成(RAG)框架,不写代码也能玩转。
用 YAML 文件轻松构建复杂 RAG 系统。
RAG 系统:简单来说,就是让 AI 模型能先检索相关信息,再生成答案,从而提高准确性。
一、核心亮点
🚀 低代码构建复杂 Pipeline
- 原生支持 串行、循环、条件分支 等推理控制结构。开发者只需编写 YAML 文件,即可实现几十行代码构建的 迭代式 RAG 流程。
- 🖼️ 原生多模态支持:检索、生成、评估一体化
- 统一检索、生成与评估,构建真正意义上的 多模态 RAG 全链路;
- 实现从 本地 PDF 建库 → 多模态检索 → 多模态生成 的闭环流程,显著提升复杂文档场景下的理解与问答能力。
- ⚡ 快速复现与功能扩展
基于 MCP 架构,所有模块均封装为独立、可复用的 Server。
- 用户可按需自定义 Server 或直接复用现有模块;
- 每个 Server 的功能以函数级 Tool 注册,新增功能仅需添加一个函数即可接入完整流程;
- 同时支持调用 外部 MCP Server,轻松扩展 Pipeline 能力与应用场景。
- 📚 知识接入与语料构建自动化
- 支持 PDF、Markdown、HTML、TXT 等多格式文档解析与分块建库;
- 与 MinerU 无缝集成,自动完成结构化抽取、多模态切块(文本/表格/图片);
- 一键构建个人化与企业级知识库,适用于科研、企业文档、私有知识管理等场景。
- 🔗 统一构建与评估的 RAG 工作流
- 同时适配多种检索引擎与多种生成推理后端;
- 内置标准化评估体系,支持全链路可视化调试与结果分析;
- 📊 统一评测与对比
内置 标准化评测流程与指标管理,开箱即用支持多个主流科研 Benchmark。
- 持续集成最新基线;
- 方便科研人员进行系统性对比与优化实验。
二、安装
使用 Conda 创建虚拟环境:
conda create -n ultrarag python=3.11 conda activate ultrarag
通过 git 克隆项目到本地或服务器:
git clone https://github.com/OpenBMB/UltraRAG.git --depth 1
cd
UltraRAG
我们推荐使用 uv 来进行包管理,提供更快、更可靠的 Python 依赖管理体验:
pip install uv uv pip install -e
.
如果您更习惯 pip,也可以直接运行:
pip install -e
.
#如果安装失败可以这样执行
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
运行以下命令验证安装是否成功:
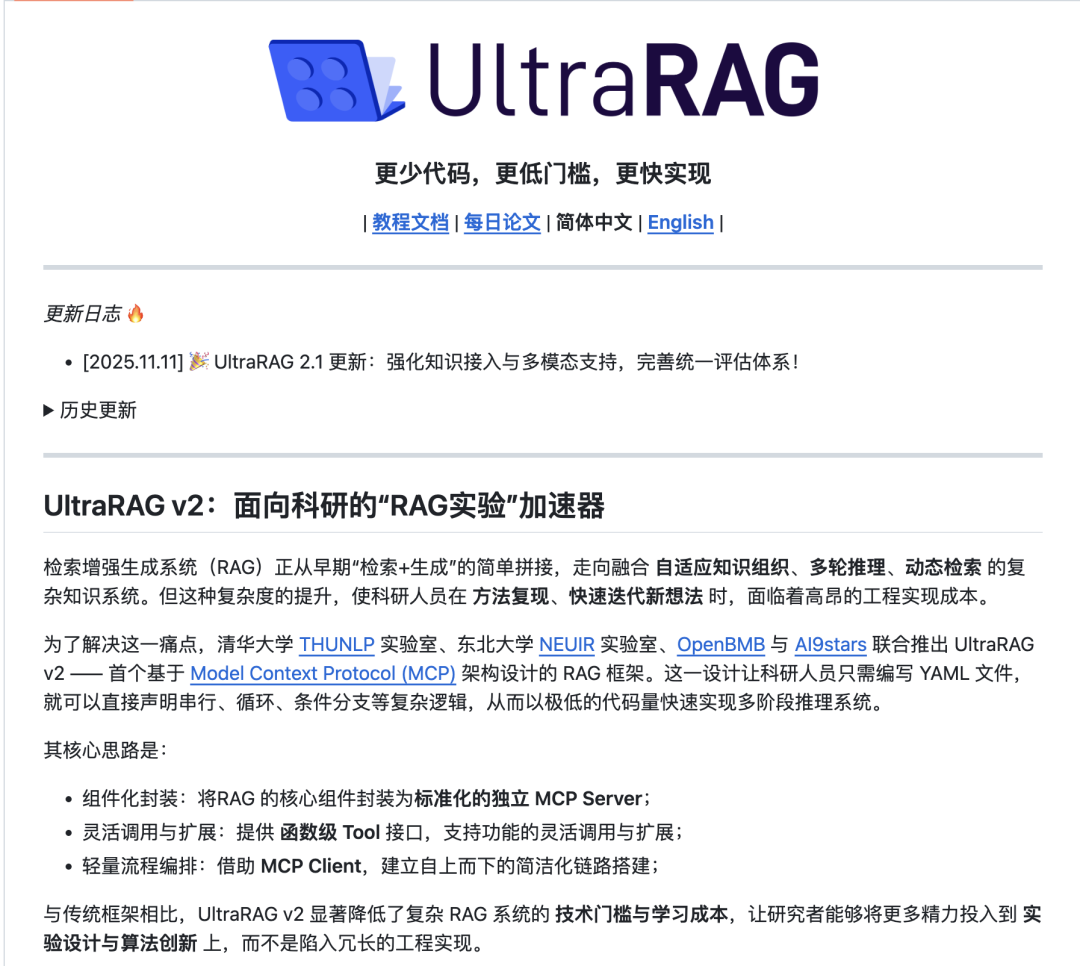
# 成功运行显示'Hello, UltraRAG 2.0!' 欢迎语
ultrarag run examples/sayhello.yaml
【可选】UltraRAG v2 支持丰富的Server组件,开发者可根据实际任务灵活安装所需依赖:
# Retriever/Reranker Server依赖:
# infinity
uv pip install infinity_emb
# sentence_transformers
uv pip install sentence_transformers
# openai
uv pip install openai
# bm25
uv pip install bm25s
# faiss(需要根据自己的硬件环境,手动编译安装 CPU 或 GPU 版本的 FAISS)
# CPU版本:
uv pip install faiss-cpu
# GPU 版本(示例:CUDA 12.x)
uv pip install faiss-gpu-cu12
# 其他 CUDA 版本请安装对应的包(例如:CUDA 11.x 使用 faiss-gpu-cu11)
# websearch
# exa
uv pip install exa_py
# tavily
uv pip install tavily-python
# 一键安装:
uv pip install -e ".[retriever]"
# Generation Server依赖:
# vllm
uv pip install vllm
# openai
uv pip install openai
# hf
uv pip install transformers
# 一键安装:
uv pip install -e ".[generation]"
# Corpus Server依赖:
# chonkie
uv pip install chonkie
# pymupdf
uv pip install pymupdf
# mineru
uv pip install "mineru[core]"
# 一键安装:
uv pip install -e ".[corpus]"
# 安装所有依赖:
uv pip install -e ".[all]"
# 或使用conda导入环境:
conda env create -f environment.yml
使用 Docker 构建运行环境
(方式一)本地构建镜像
通过 git 克隆项目到本地或服务器:
git clone https://github.com/OpenBMB/UltraRAG.git --depth 1
cd
UltraRAG
构建镜像:
docker build -t ultrarag:v0.2.1
.
运行交互环境:
docker run -it --gpus all ultrarag:v0.2.1 /bin/bash
(方式二)使用预构建好的镜像
拉取构建好的镜像:
docker pull hdxin2002/ultrarag:v0.2.1
运行交互环境:
docker run -it --gpus all hdxin2002/ultrarag:v0.2.1 /bin/bash
运行以下命令验证安装是否成功:
# 成功运行显示'Hello, UltraRAG 2.0!' 欢迎语
ultrarag run examples/sayhello.yaml
三、快速开始
UR-v2 的使用流程主要包括以下三个阶段:
- 编写 Pipeline 配置文件
- 编译 Pipeline 并调整参数
- 运行 Pipeline
此外,你还可以通过可视化工具对运行结果进行分析与评估。
Step 1:编写 Pipeline 配置文件
在examples文件夹中创建并编写你的 Pipeline 配置文件,例如:
servers:
benchmark: servers/benchmark
retriever: servers/retriever
prompt: servers/prompt
generation: servers/generation
evaluation: servers/evaluation
custom: servers/custom
pipeline:
- benchmark.get_data
- retriever.retriever_init
- retriever.retriever_embed
- retriever.retriever_index
- retriever.retriever_search
- generation.generation_init
- prompt.qa_rag_boxed
- generation.generate
- custom.output_extract_from_boxed
- evaluation.evaluate
UR-v2 的 Pipeline 配置文件需要包含以下两个部分:
-
servers声明当前流程所依赖的各个模块(Server)。例如,检索阶段需要使用
retrieverServer。 -
pipeline定义各 Server 中功能函数(Tool)的调用顺序。本示例展示了从数据加载、检索编码与索引构建,到生成与评测的完整流程。
Step 2:编译 Pipeline 并调整参数
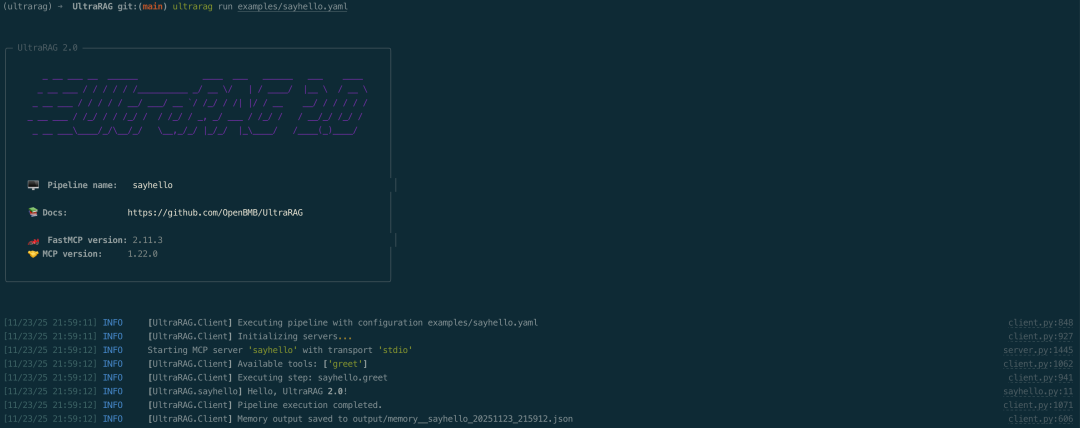
在运行代码前,首先需要配置运行所需的参数。UR-v2 提供了快捷的 build 指令,可自动生成当前 Pipeline 所依赖的完整参数文件。 系统会读取各个 Server 的 parameter.yaml 文件,解析本次流程中涉及的全部参数项,并统一汇总生成到一个独立的配置文件中。执行以下命令:
ultrarag build examples/rag_full.yaml
执行后,终端将输出如下内容:
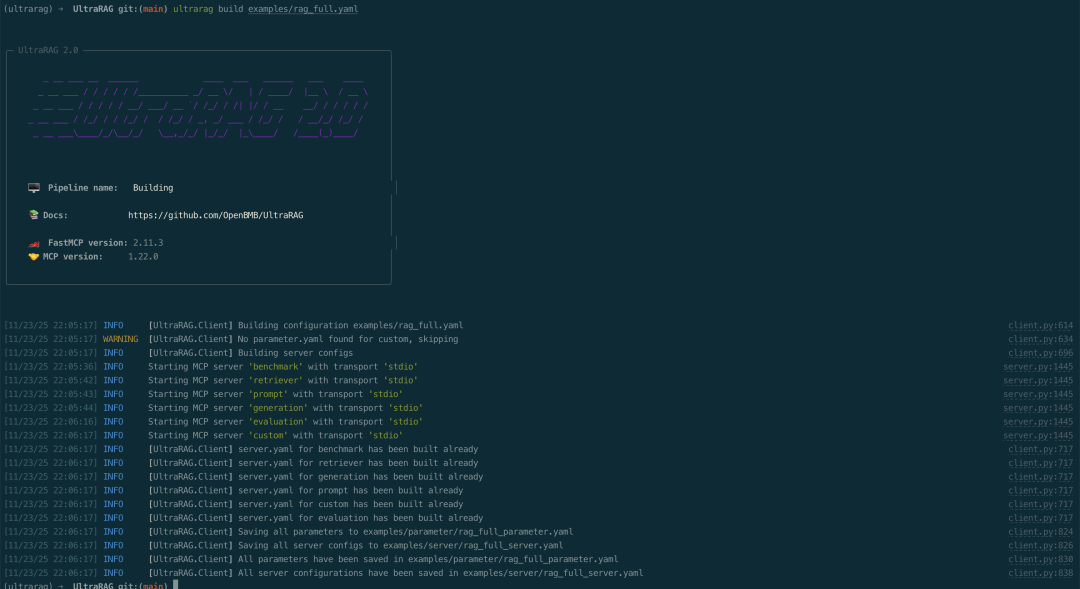
系统会在examples/parameters/文件夹下生成对应的参数配置文件。打开文件后,可根据实际情况修改相关参数,例如:
你可以根据实际情况修改参数,例如:
- 将 template 调整为RAG模版 prompt/qa_rag_boxed.jinja;
- 替换检索器与生成器的 model_name_or_path 为本地下载的模型路径;
- 若在多 GPU 环境下运行,可修改 gpu_ids 以匹配可用设备。
Step 3:运行 Pipeline
当参数配置完成后,即可一键运行完整流程。执行以下命令:
ultrarag run examples/rag_full.yaml
系统将依次执行配置文件中定义的各个 Server 与 Tool,并在终端中实时输出运行日志与进度信息:
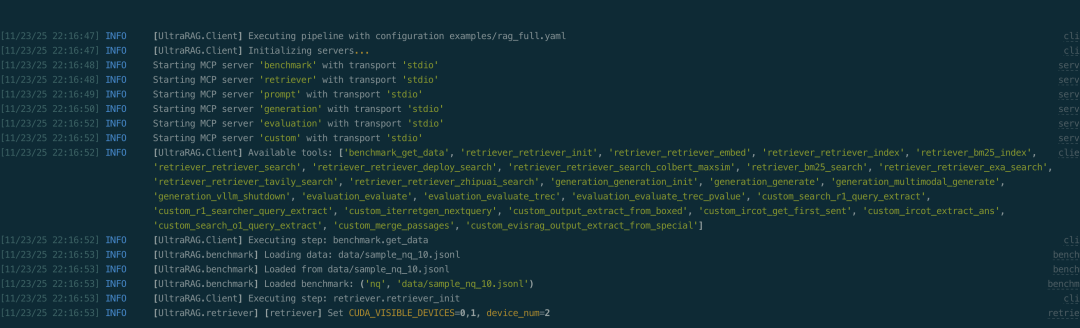
运行结束后,结果(如生成内容、评测报告等)将自动保存在对应的输出路径中,如本例中output/memory_nq_rag_full_20251123_145420.json可直接用于后续分析与可视化展示。
Step 4:可视化分析 Case Study
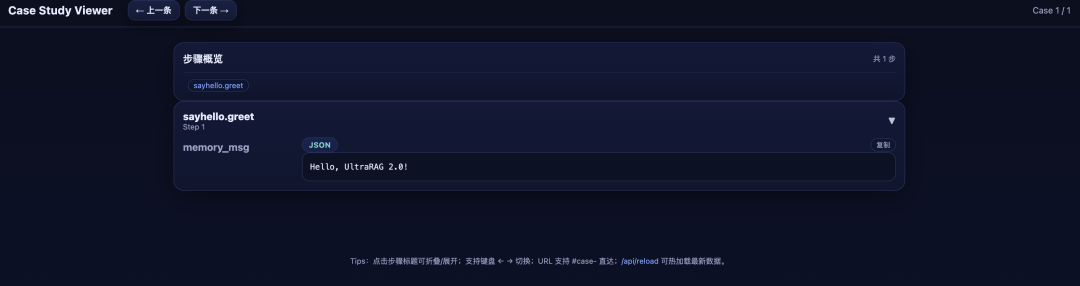
完成流程运行后,可通过内置的可视化工具快速分析生成结果。执行以下命令启动 Case Study Viewer:
python ./script/case_study.py \
--data output/memory_nq_rag_full_20251123_145420.json \
--host 127.0.0.1 \
--port 8080 \
--title "Case Study Viewer"
运行成功后,终端会显示访问地址。打开浏览器并输入该地址,即可进入 Case Study Viewer 界面,对结果进行交互式浏览与分析。 界面示例如下所示:
如何高效转型Al大模型领域?
作为一名在一线互联网行业奋斗多年的老兵,我深知持续学习和进步的重要性,尤其是在复杂且深入的Al大模型开发领域。为什么精准学习如此关键?
- 系统的技术路线图:帮助你从入门到精通,明确所需掌握的知识点。
- 高效有序的学习路径:避免无效学习,节省时间,提升效率。
- 完整的知识体系:建立系统的知识框架,为职业发展打下坚实基础。
AI大模型从业者的核心竞争力
- 持续学习能力:Al技术日新月异,保持学习是关键。
- 跨领域思维:Al大模型需要结合业务场景,具备跨领域思考能力的从业者更受欢迎。
- 解决问题的能力:AI大模型的应用需要解决实际问题,你的编程经验将大放异彩。
以前总有人问我说:老师能不能帮我预测预测将来的风口在哪里?
现在没什么可说了,一定是Al;我们国家已经提出来:算力即国力!
未来已来,大模型在未来必然走向人类的生活中,无论你是前端,后端还是数据分析,都可以在这个领域上来,我还是那句话,在大语言AI模型时代,只要你有想法,你就有结果!只要你愿意去学习,你就能卷动的过别人!
现在,你需要的只是一份清晰的转型计划和一群志同道合的伙伴。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】



















 3237
3237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









