



 本文探讨了SQL Server中的分组查询,包括GROUP BY、HAVING、GROUPING SETS、CUBE和ROLLUP等操作,以及如何结合聚合函数进行数据统计。同时,介绍了子查询的概念和用法,如嵌套查询、相关子查询的处理方式,并举例说明其在实际查询中的应用。
本文探讨了SQL Server中的分组查询,包括GROUP BY、HAVING、GROUPING SETS、CUBE和ROLLUP等操作,以及如何结合聚合函数进行数据统计。同时,介绍了子查询的概念和用法,如嵌套查询、相关子查询的处理方式,并举例说明其在实际查询中的应用。
SQL Server中分组查询常用于配合聚合函数,实现分类汇总统计的信息。而其分类汇总的本质实际上就是先将信息排列成组,排序后相同类别的信息会聚在一起,然后通过需求进行统计计算。
常用的数据分组:
GROUP BY - 根据“By”指定的规则对对查询结果进行分组
HAVING - 通常与GROUP BY子句一起使用,用来指定组或聚合的搜索条件。
GROUPING SETS - 生成多个分组集。
CUBE - 生成包含维列的所有组合的分组集。
ROLLUP - 生成分组集,假设输入列之间存在层次结构。
聚合函数:
COUNT() 函数返回每个组中的行数
MIN() 函数返回每个组中的最小值
MAX() 函数返回每个组中的最大值
SUM() 函数返回每个组的总价值
AVG() 函数返回每个组的平均值
例:

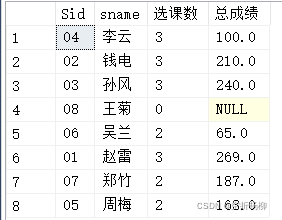
嵌入另一个SELECT语句中的SELECT语句被称为子查询,任何允许使用表达式的地方都可以使用子查询。
语法规则:
子查询的select查询总使用圆括号括起来
不能包括compute或for browse子句
如果同时指定top子句,则可能只包括order by子句
子查询最多嵌套32层,个别查询可能会不支持32层嵌套
任何可以使用表达式的地方都可以使用子查询,主要它返回的是单个值
如果某个表只出现在子查询中而不出现在外部查询中,那么该表中的列就无法包含在输出中
例:


嵌套查询是指将一个查询块嵌套在另一个查询块的where子句或having短语的条件中的查询。
嵌套查询的处理方法:先处理最内侧的子查询,然后一层一层地向上处理,直到最外层。

相关子查询是使用外部查询的值的子查询。由于这种依赖性,相关子查询不能作为简单子查询独立执行。 此外,对外部查询评估的每一行重复执行一次相关子查询。 相关子查询也称为重复子查询。
例:


















 2503
2503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









