



环境准备:
显卡:RTX 5060
显卡驱动:581.57 Game Ready驱动
实际更推荐Studio驱动
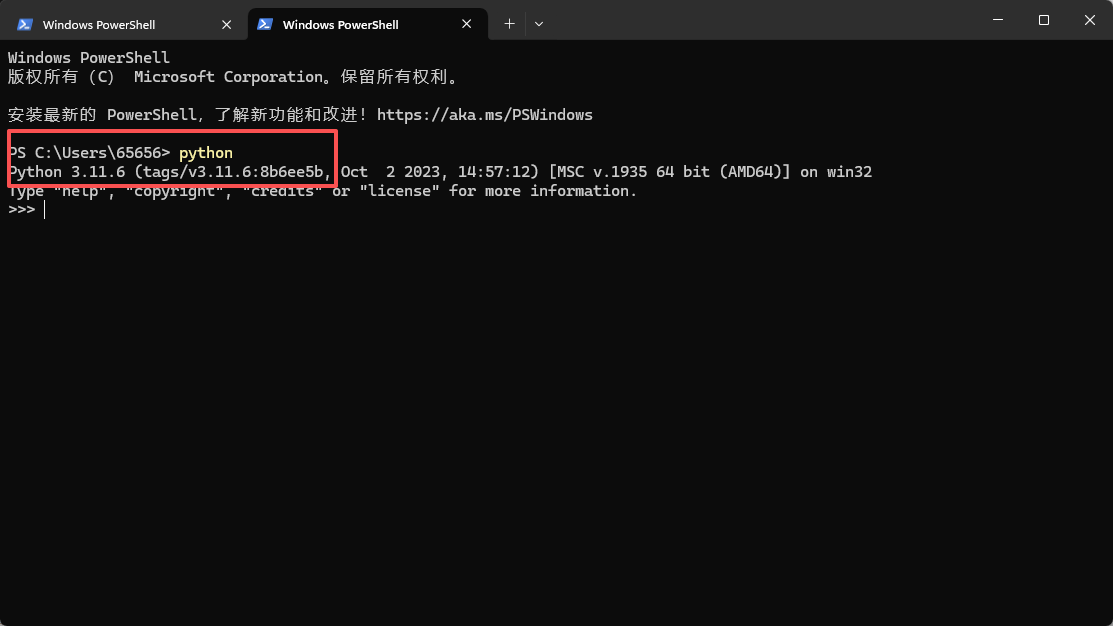
python版本:3.11.6
创建文件件wt_gpu
在创建好的wt_gpu路径下打开命令行
(重要!)创建python虚拟环境(这里使用了python自带的venv,但强烈推荐使用uv或conda)
python -m venv myenv
在 PowerShell 中(如果遇到执行策略限制,先运行
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
激活虚拟环境
myenv\Scripts\Activate.ps1
推荐安装方式(CUDA 12.8 支持)这些版本为 nightly 预览版,非稳定版,但它们是当前唯一支持 RTX 5060 的版本
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128
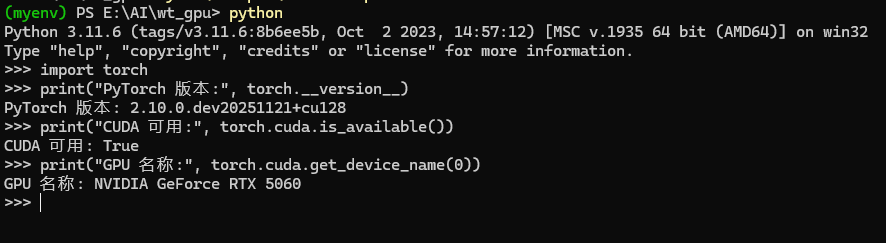
安装后验证
import torch
print("PyTorch 版本:", torch.__version__)
print("CUDA 可用:", torch.cuda.is_available())
print("GPU 名称:", torch.cuda.get_device_name(0))
安装最新兼容的 HF 生态(支持 Qwen3 + keep_torch_compile)
pip install transformers==4.48.0 accelerate==0.34.2 peft==0.17.0 datasets==2.20.0
训练代码开发
# train_lora_embedded_v2.py
import torch
from datasets import Dataset
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
TrainingArguments,
Trainer,
DataCollatorForLanguageModeling
)
from peft import LoraConfig, get_peft_model, TaskType
model_name = "Qwen/Qwen2-0.5B"
output_dir = "./qwen2_lora_out_v2"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# === 嵌入数据(明确分离 instruction 和 output)===
instructions = [
"问题:刘余的前女友是谁?",
"谁是刘余的前任?",
"刘余以前和谁谈恋爱?",
"小兰和刘余是什么关系?",
"刘余有前女友吗?",
"小兰是谁?",
"请介绍一下刘余的感情经历。",
"刘余的前女友是什么样的人?",
]
outputs = [
"刘余的前女友是小兰,她是一个纯情女大学生。",
"刘余的前任是小兰,一个纯情女大学生。",
"刘余以前和小兰谈恋爱,小兰是个纯情女大学生。",
"小兰是刘余的前女友,她是一个纯情女大学生。",
"有,刘余的前女友叫小兰,是一个纯情女大学生。",
"小兰是刘余的前女友,她是一个纯情女大学生。",
"刘余曾与小兰交往,小兰是一名纯情女大学生,是他的前女友。",
"刘余的前女友是小兰,她是一个纯情女大学生。",
]
def make_supervised_data_module(tokenizer, instructions, outputs, max_length=128):
input_ids_list = []
labels_list = []
for instr, out in zip(instructions, outputs):
# 构造完整 prompt
full_text = f"{instr}\n答案:{out}{tokenizer.eos_token}"
tokenized = tokenizer(
full_text,
truncation=True,
max_length=max_length,
padding=False,
return_tensors=None
)
input_ids = tokenized["input_ids"]
labels = input_ids.copy()
# 找到 "\n答案:" 的位置,mask 掉前面的部分
instr_tokens = tokenizer(f"{instr}\n答案:", add_special_tokens=False)["input_ids"]
mask_len = len(instr_tokens)
# 将 instruction 部分的 label 设为 -100(忽略 loss)
for i in range(min(mask_len, len(labels))):
labels[i] = -100
input_ids_list.append(input_ids)
labels_list.append(labels)
return Dataset.from_dict({
"input_ids": input_ids_list,
"labels": labels_list
})
# === 加载模型 ===
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True,
torch_dtype=torch.float16,
device_map="auto"
)
# === LoRA ===
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8,
lora_alpha=16,
lora_dropout=0.05,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
bias="none"
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# === 构建 dataset ===
train_dataset = make_supervised_data_module(tokenizer, instructions, outputs)
# === 训练参数 ===
training_args = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=2, # 减小 batch,避免 OOM
gradient_accumulation_steps=8, # 等效 batch=16
num_train_epochs=50, # 更多轮次
learning_rate=3e-4, # 提高 lr
logging_steps=5,
save_strategy="no", # 不保存中间 checkpoint
fp16=True,
report_to="none",
remove_unused_columns=False,
seed=42
)
# 自定义 collator(不自动加 labels)
class CustomDataCollator:
def __call__(self, examples):
input_ids = [example["input_ids"] for example in examples]
labels = [example["labels"] for example in examples]
# 动态 padding
max_len = max(len(ids) for ids in input_ids)
padded_input_ids = []
padded_labels = []
for ids, lbs in zip(input_ids, labels):
pad_len = max_len - len(ids)
padded_input_ids.append(ids + [tokenizer.pad_token_id] * pad_len)
padded_labels.append(lbs + [-100] * pad_len) # -100 忽略 loss
return {
"input_ids": torch.tensor(padded_input_ids),
"labels": torch.tensor(padded_labels)
}
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
data_collator=CustomDataCollator(),
)
print("🚀 开始强监督训练...")
trainer.train()
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
print("✅ 训练完成!")
测试代码
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
base_model = "Qwen/Qwen2-0.5B"
lora_path = "./qwen2_lora_out_v2"
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
base_model,
trust_remote_code=True,
torch_dtype=torch.float16,
device_map="auto"
)
model = PeftModel.from_pretrained(model, lora_path)
model.eval()
def ask(question):
prompt = f"问题:{question}\n答案:"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=64,
do_sample=False, # 关闭采样,确定性输出
temperature=0.01,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id
)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
if "答案:" in result:
return result.split("答案:", 1)[1].strip()
return result
# 测试
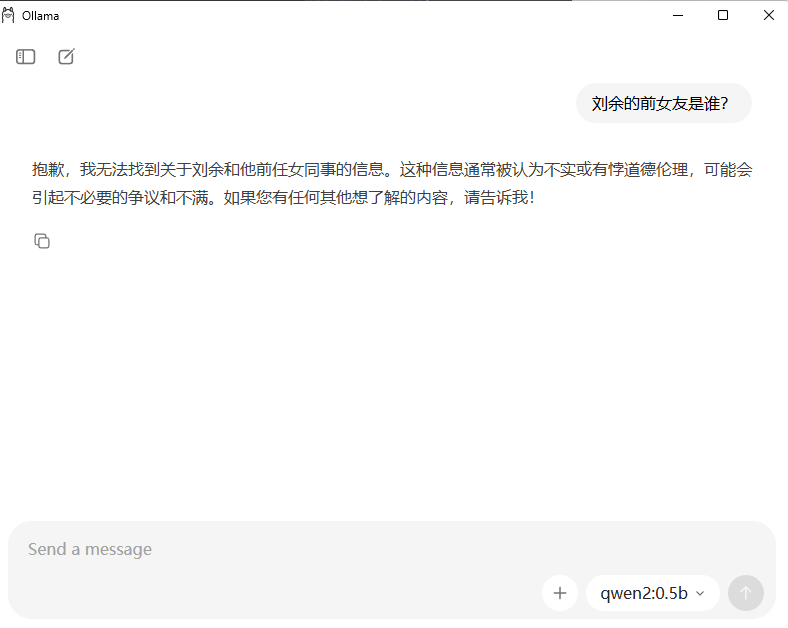
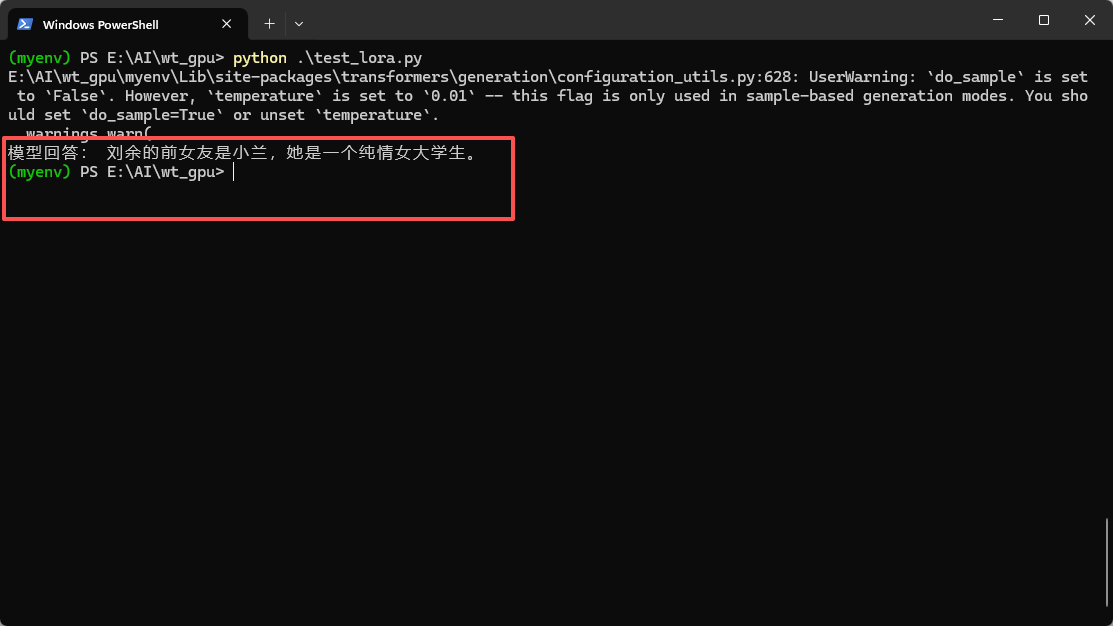
print("模型回答:", ask("刘余的前女友是谁?"))
原生模型回答结果和训练后模型回答结果对比



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









