



 本文深入探讨了Transformer模型的结构和工作原理,包括自我注意力机制、编码器-解码器架构、预训练任务以及残差连接。Transformer在NLP领域的广泛应用和流行,主要得益于其在语言理解和生成任务中的高效迁移学习能力。文章还介绍了Transformer的不同变体和预训练策略,如Encoder-only、Decoder-only和Encoder-Decoder模型。
本文深入探讨了Transformer模型的结构和工作原理,包括自我注意力机制、编码器-解码器架构、预训练任务以及残差连接。Transformer在NLP领域的广泛应用和流行,主要得益于其在语言理解和生成任务中的高效迁移学习能力。文章还介绍了Transformer的不同变体和预训练策略,如Encoder-only、Decoder-only和Encoder-Decoder模型。
前言
This week, I read the paper “Transformer Models: An Introduction and Catalog”, which is an article about NLP. The paper provides a brief analysis of the relevant technology of transformer and summarizes other models based on transformer architecture in terms of Pretraining Architecture, Pretraining Task, Compression, Application, Year, and Number of Parameters.
Simultaneously, a detailed examination was conducted on the specifics of the transformer model (basic) to better understand how it operates.
一、论文阅读《TRANSFORMER MODELS: AN INTRODUCTION AND CATALOG》
这是一篇介绍Transformer和Transformer变形的论文集合的文章。链接:TRANSFORMER MODELS: AN INTRODUCTION AND CATALOG
摘要
在过去的几年里,我们已经看到了几十个Transformer family的模型的迅速出现,所有这些都有有趣的,但不是不言自明的名字。本文的目标是为最流行的Transformer模型提供一个比较全面但简单的目录和分类。本文还介绍了Transformer模型中最重要的方面和创新。
Introduction
Transformer架构是编码器-解码器模型的一个特定实例,该模型在2 - 3年前开始流行起来。然而,在此之前,注意力只是这些模型使用的机制之一,这些模型主要基于LSTM(长短期记忆)和其他RNN(循环神经网络)变体。《Transformers 》论文的关键见解是,注意力可以被用作推导输入和输出之间依赖关系的唯一机制。
Attention
下面会详细学习Attention
attention函数是查询和一组键值对到输出之间的映射。输出是按值的加权和计算的,其中分配给每个值的权重是通过查询与相应键的兼容性函数计算的。变形金刚使用多头注意力,这是一个被称为缩放点积注意力的特定注意力函数的并行计算。
Encoder/Decoder architecture
通用编码器/解码器体系结构由两个模型组成。编码器接受输入并将其编码为固定长度的向量。解码器获取该向量并将其解码为输出序列。编码器和解码器联合训练以最小化条件对数似然。一旦训练,编码器/解码器可以生成给定输入序列的输出,或者可以对输入/输出序列进行评分。
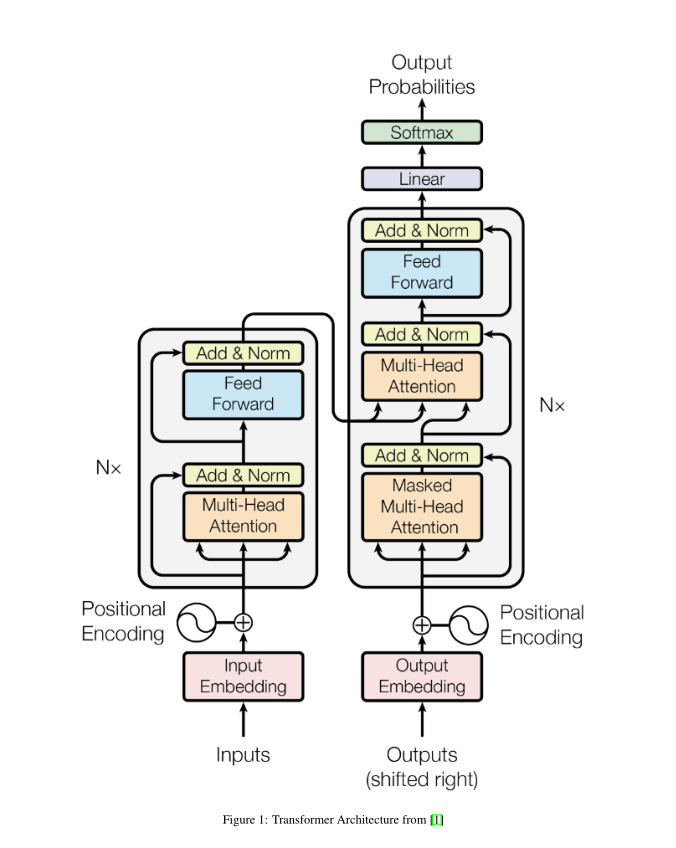
在最初的Transformer架构中,编码器和解码器都有6个相同的层。在这6层中的每一层编码器都有两个子层:一个多头注意层和一个简单的前馈网络。每个子层都有一个残差连接和一个层归一化。编码器的输出大小是512。解码器添加了第三个子层,这是编码器输出上的另一个多头注意层。此外,解码器中的另一个多头层被屏蔽,以防止对后续位置的注意。
What are Transformers used for and why are they so popular
最初的转换器是为语言翻译而设计的,特别是从英语到德语。但是,原始论文已经表明,该架构可以很好地推广到其他语言任务。这一特别的趋势很快就引起了研究界的注意。在接下来的几个月里,大多数与语言相关的ML任务的排行榜完全被某个版本的transformer架构所主导,Transformer能够如此迅速地占据大多数NLP排行榜的关键原因之一是它们能够快速适应其他任务,也就是迁移学习。预训练的Transformer模型可以非常容易和快速地适应它们没有经过训练的任务,这具有巨大的优势。作为ML从业者,您不再需要在庞大的数据集上训练大型模型,用更小的数据集进行调整。一种用于使预训练模型适应不同任务的特定技术被称为微调。
The Transformers catalog
论文将根据以下属性对每个模型进行分类:Pretraining Architecture,Pretraining Task,Compression,Application,Year和 Number of Parameters。
Pretraining Architecture
Transformer架构描述为:由Encoder和Decoder组成,对于最初的Transformer也是如此。然而,从那时起,已经取得了不同的进展,揭示了在某些情况下,只使用编码器,只使用解码器,或两者都是有益的。
Encoder Pretraining
这些模型也被称为双向或自动编码,在预训练过程中只使用编码器,这通常是通过在输入句子中屏蔽单词并训练模型进行重建来完成的。在预训练的每个阶段,注意层都可以访问所有输入的单词。这个系列的模型对于需要理解完整句子的任务最有用,比如句子分类或提取性问题回答。
Decoder Pretraining
解码器预训练解码器模型,通常称为自回归,在预训练期间只使用解码器,通常设计为迫使模型预测下一个单词。注意层只能访问句子中给定单词之前的单词。它们最适合用于涉及文本生成的任务。
Transformer (Encoder-Decoder) Pretraining
预训练编码器-解码器模型,也称为序列到序列,使用Transformer架构的两个部分。编码器的注意层可以访问输入中的所有单词,而解码器的注意层只能访问输入中给定单词之前的单词。预训练可以使用编码器或解码器模型的目标来完成,但通常涉及一些更复杂的东西。这些模型最适合于根据给定输入生成新句子的任务,例如总结、翻译或生成式问答。
Pretraining Task
当训练一个模型时,我们需要为模型定义一个学习任务。上面已经提到了一些典型的任务,比如预测下一个单词或学习重构掩码单词。“Pre-trained Models for Natural Language Processing: A Survey”这篇综述中包含了一个相当全面的预训练任务分类,所有这些任务都可以被认为是自监督的:
- 语言建模(LM):预测下一个 token(在单向LM的情况下)或上一个和下一个 token(在双向LM的情况下)
- 蒙面语言建模(masking Language Modeling, MLM):从输入句子中屏蔽掉一些标记,然后训练模型通过剩余的标记来预测被屏蔽的标记(这个在bert上使用过)
- 排列语言建模(PLM):与LM相同,但基于输入序列的随机排列。一个排列是从所有可能的排列中随机抽取的。然后选择一些令牌作为目标,训练模型来预测这些目标。
- 去噪自动编码器(DAE):取部分损坏的输入(例如,从输入中随机采样令牌并用“[MASK]”元素替换它们。从输入中随机删除标记,或以随机顺序打乱句子),目的是恢复原始的未扭曲的输入。
- 对比学习(CTL):通过假设一些观察到的文本对比随机采样的文本在语义上更相似来学习文本对的评分函数。
Catalog List
以家族分类主要有以下几个家族:CLIP (Also using Resnet, ViT, and vanilla transformer for text)、HTML、GPT、BERT、Chinchilla、Transformer、 T5等等。但主要的是GPT和BERT,运用到了大量的模型中。
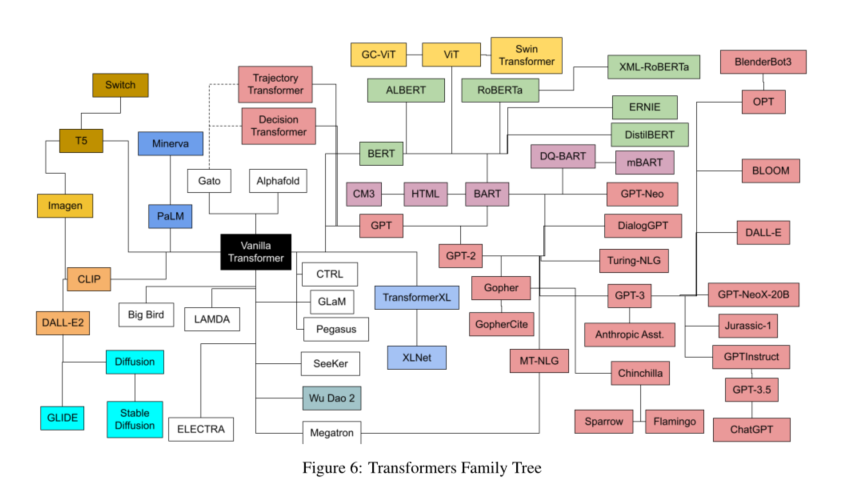
后面就对各个模型进行简答的描述,和提供论文呢链接。
二、Transformer和Attention
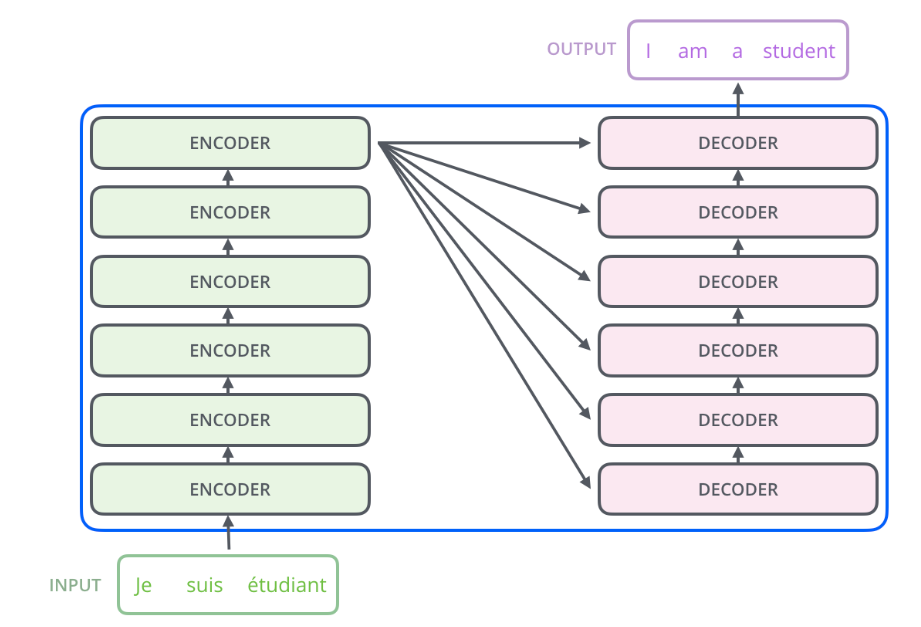
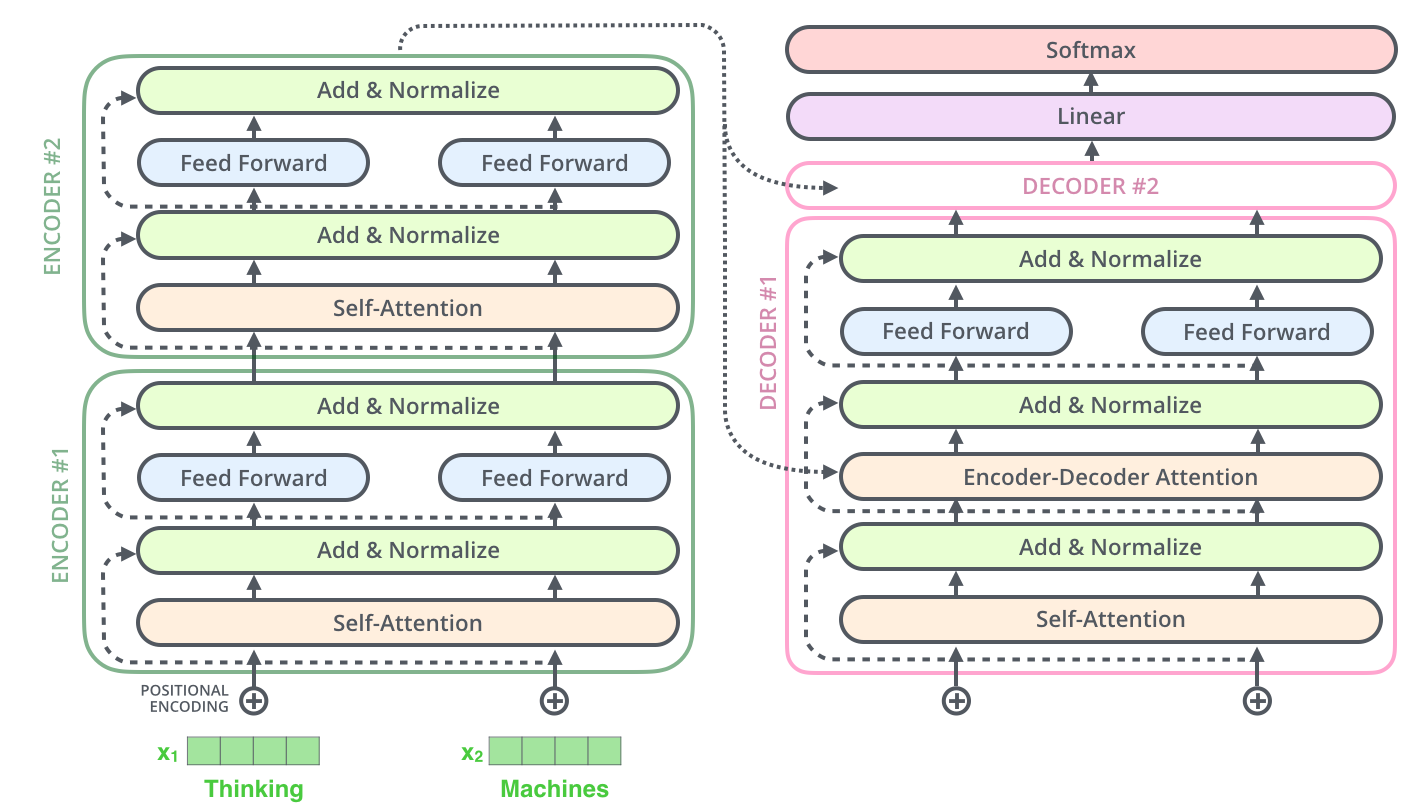
首先将transformer模型看作一个简单的黑盒。在机器翻译应用里面,模型将一种语言的句子作为输入,然后输出另一种语言的表示。深入到组件内部,由编码组件、解码组件和它们之间的连接层组成。编码组件是六层编码器首位相连堆砌而成,解码组件也是六层解码器堆成的。
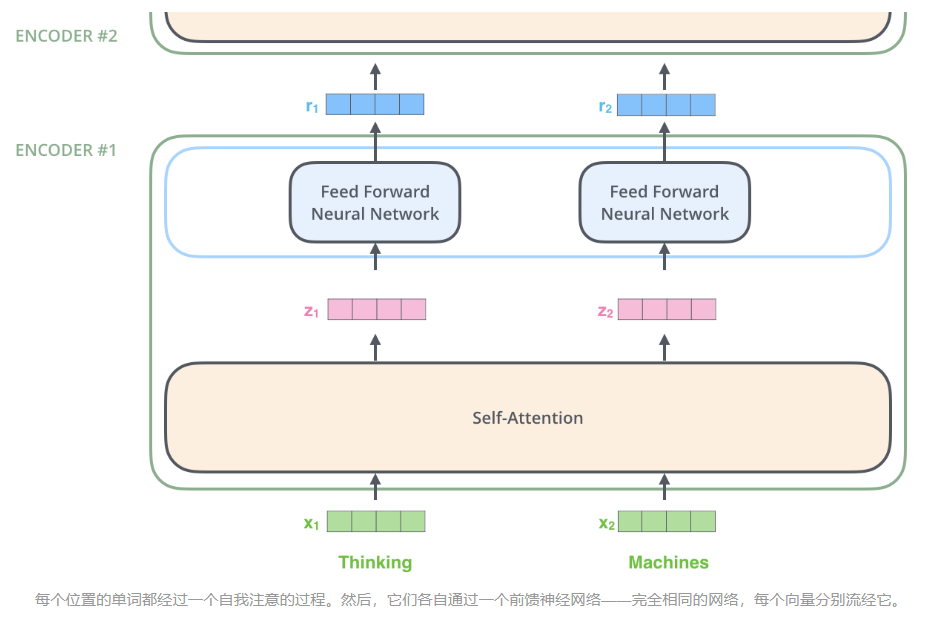
每一层的编码器结构完全相同(但不共享参数),每一个编码器都可以拆解成以下两个部分。
encoder中的结构:
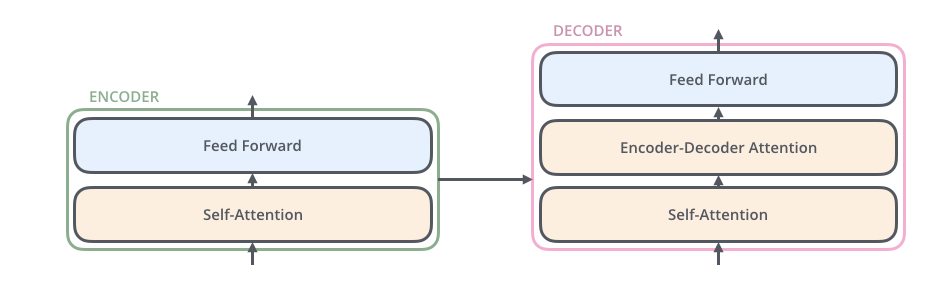
编码器的输入首先流经自我注意层 - 该层可帮助编码器在编码特定单词时查看输入句子中的其他单词。
自我注意层的输出被馈送到前馈神经网络。完全相同的前馈网络独立应用于每个位置。
解码器具有这两个层,但在它们之间是一个注意力层,可帮助解码器专注于输入句子的相关部分(类似于 seq2seq 模型中的注意力)
将张量带入图片
与一般的NLP应用程序一样,我们首先使用嵌入算法(embedding algorithm)将每个输入词转换为向量。
嵌入仅发生在最底部的编码器中。所有编码器的共同抽象是它们接收一个大小为 512 的向量列表 – 在底部编码器中,这将是单词嵌入,但在其他编码器中,它将是编码器的输出正下方。
将单词嵌入到我们的输入序列中后,每个单词都流经编码器的两层中的每一层。
这里能看到Transformer的一个关键特性,每个位置的词仅仅流过它自己的编码器路径。在self-attention层中,这些路径之间是相互依赖的。而feed-forward层则没有这些依赖性,这些路径在流经feed-forward层时可以并行执行。
编码器接收一个向量列表作为输入。它通过将这些向量传递到“自我注意”层来处理此列表,然后传递到前馈神经网络,然后将输出向上发送到下一个编码器。
Self-Attention的含义
假设以下句子是我们想要翻译的输入句子:
"The animal didn’t cross the street because it was too tired“
当模型处理单词“it”时,自我注意允许它将“it”与“animal”相关联。
当模型处理每个单词(输入序列中的每个位置)时,自我注意允许它查看输入序列中的其他位置,以寻找有助于更好地编码该单词的线索。

Self-Attention细节
第一步,根据编码器的输入向量,生成三个向量。
对每个词向量,生成Query vector, Key vector, Value vector,生成方法为分别乘以三个矩阵,这些矩阵是训练过程中需要学习的参数。
【注意:不是每个词向量独享3个matrix,而是所有输入共享3个转换矩阵;权重矩阵是基于输入位置的转换矩阵】
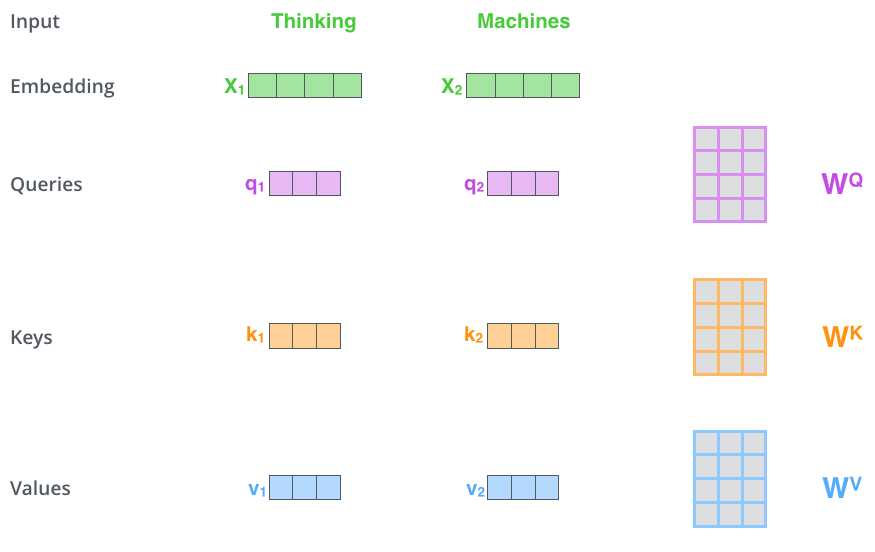
(将 x1 乘以 WQ 权重矩阵得到 q1,即与该单词关联的“查询”向量。我们最终为输入句子中的每个单词创建一个“查询”、“键”和“值”投影。)
第二步是计算分数。
假设我们正在计算此示例中第一个单词“思考”的自我注意。我们需要根据该单词对输入句子的每个单词进行评分。分数决定了当我们在某个位置对单词进行编码时,对输入句子的其他部分的关注程度。
分数的计算方法是将查询向量的点积与我们评分的相应单词的关键向量相提并论。因此,如果我们处理位置 中单词的自我注意,第一个分数将是 q1 和 k1 的点积。第二个分数将是 q1 的点积和K2.
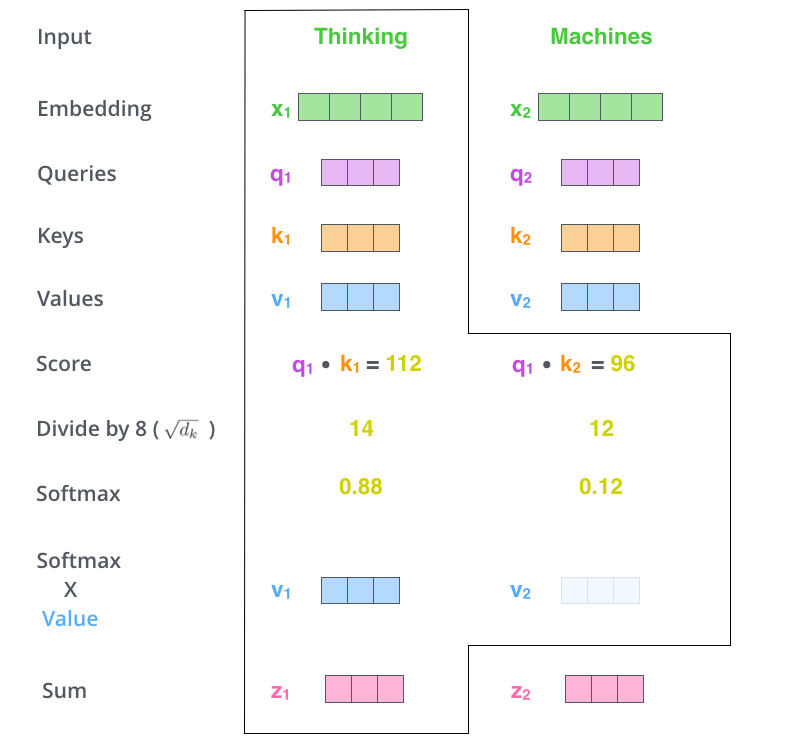
第三步和第四步是将分数除以 8。
(论文中使用的关键向量维度的平方根 – 64。这导致具有更稳定的梯度。这里可能还有其他可能的值,但这是默认值),然后通过 softmax 操作传递结果。Softmax 对分数进行归一化,因此它们都是正数,加起来为 1。
这个softmax分数决定了每个单词在这个位置的表达量。显然,这个位置的单词将具有最高的softmax分数,但有时关注与当前单词相关的另一个单词很有用。
第五步是将每个值向量乘以softmax分数(准备将它们相加)。
这里的直觉是保持我们想要关注的单词的值不变,并淹没不相关的单词(例如,将它们乘以像 0.001 这样的小数字)。
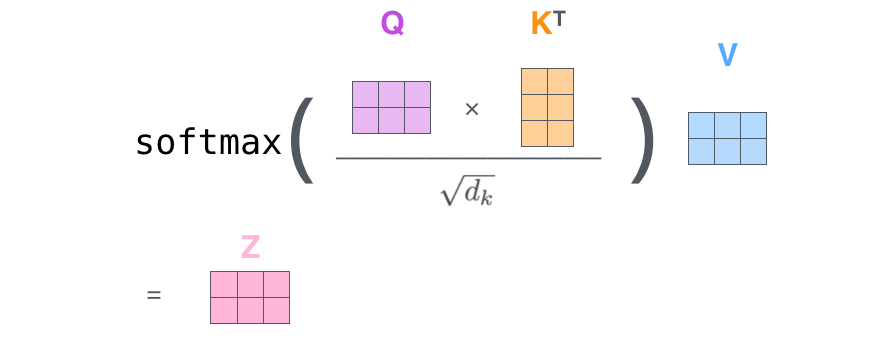
第六步是总结加权值向量。
这会在此位置(对于第一个单词)产生自我注意层的输出。
生成的向量是我们可以发送到前馈神经网络的向量。然而,在实际实现中,这种计算是以矩阵形式完成的,以便更快地处理。因此,现在让我们看看,我们已经看到了单词级别的计算直觉。
Multi-Headed Attention
该论文通过添加一种称为“多头”注意的机制进一步完善了自我注意层。这通过两种方式提高了注意力层的性能:
- 多头机制扩展了模型集中于不同位置的能力。在上面的例子中,z1只包含了其他词的很少信息,仅由实际自己词决定。在其他情况下,比如翻译 “The animal didn’t cross the street because it was too tired”时,我们想知道单词"it"指的是什么。
- 它为注意力层提供了多个“表示子空间”。正如我们接下来将看到的,对于多头注意力,我们不仅有一组,而是多组query/key/value-matrix(转换器使用8-heads,所以我们最终为每个编码器/解码器有八组)。这些集合中的每一个都是随机初始化的。然后,在训练后,每个集合用于将输入嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。
我们计算multi-headed self-attention的,分别有八组不同的Q/K/V matrix,我们得到八个不同的矩阵。
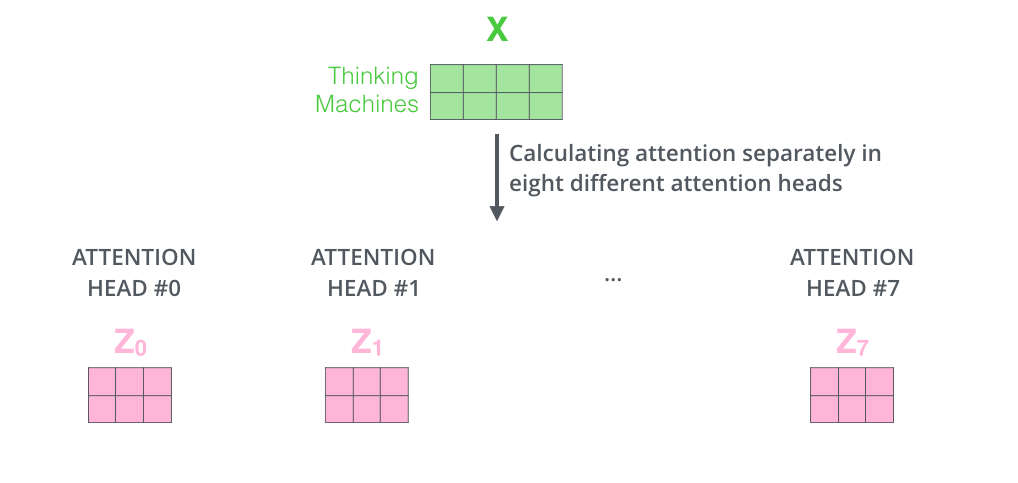
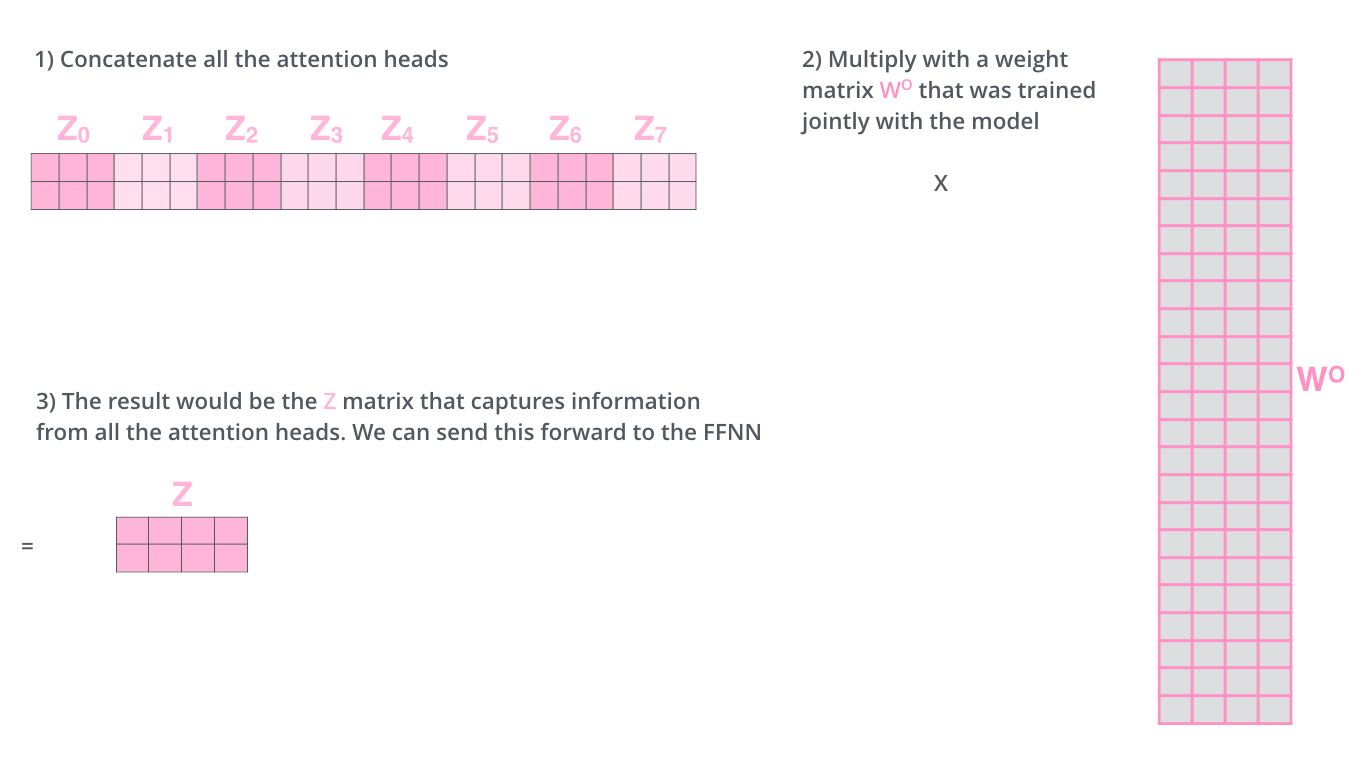
前馈层不需要八个矩阵 - 它期望单个矩阵(每个单词的向量)。因此,我们需要一种方法将这八个压缩成一个矩阵。我们将矩阵连接起来,然后将它们乘以一个额外的权重矩阵 WO。
现在加入attention heads之后,重新看下当编码“it”时,哪些attention head会被集中。

当我们对“它”这个词进行编码时,一个注意力头最关注“动物”,而另一个注意力集中在“疲惫”上——从某种意义上说,模型对“它”这个词的表示融入了“动物”和“疲惫”的一些表示。
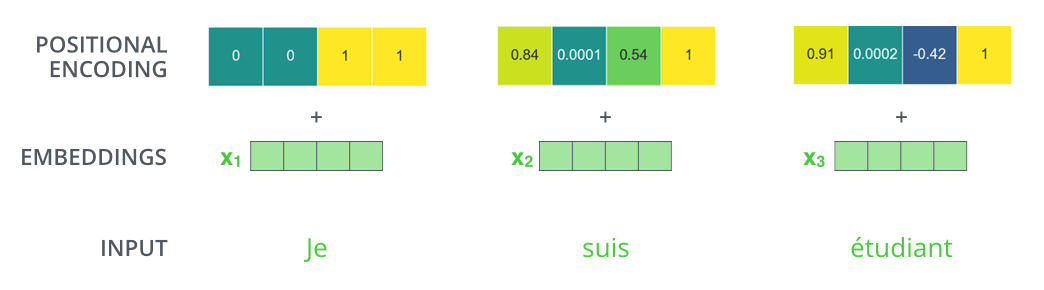
位置编码
为了解决输入序列中单词顺序的问题,转换器向每个输入嵌入添加一个向量。这些向量遵循模型学习的特定模式,这有助于它确定每个单词的位置或序列中不同单词之间的距离。这里的直觉是,将这些值添加到嵌入中,一旦嵌入向量投影到 Q/K/V 向量中,并且在点积注意期间,嵌入向量之间就会提供有意义的距离。
如果我们假设嵌入的维数为 4,则实际的位置编码如下所示:
The Residuals 残差
在继续之前,我们需要提及编码器架构中的一个细节是,每个编码器中的每个子层(自我注意,ffnn)周围都有一个残差连接,然后是层规范化步骤。
可视化与自我注意相关的向量和层范数运算,它看起来像这样:
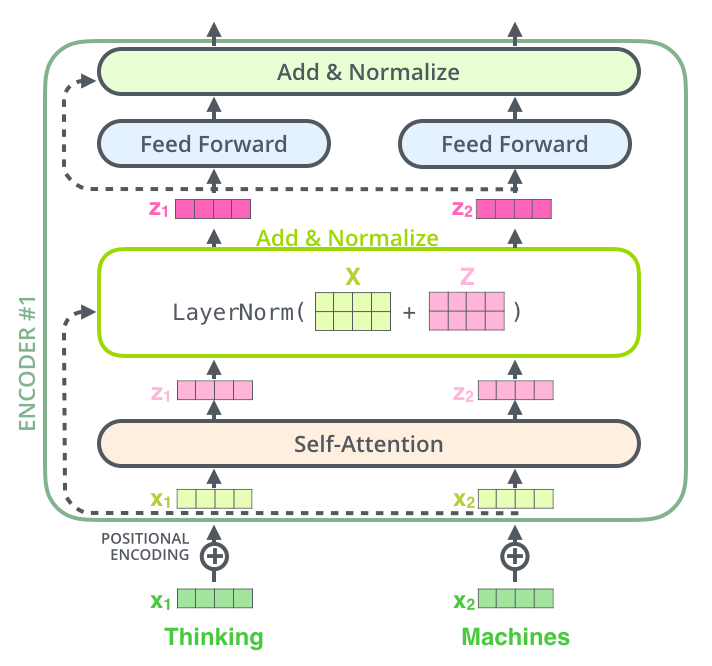
这也适用于解码器的子层。如果我们要考虑一个由 2 个堆叠编码器和解码器的 Transformer 组成,它看起来像这样:
总结
帮我把这段话用计算机学术英语翻译出来 :本周阅读了论文《TRANSFORMER MODELS: AN INTRODUCTION AND CATALOG》,这就一篇关于NLP的文章,其内容简要分析了transformer的相关技术,还把用transformer模型为基础的其他模型做了一个总结,分别按照Pretraining Architecture,Pretraining Task,Compression,Application,Year和 Number of Parameters进行了分类。同时,详细学习了transformer模型(基础)的的细节然后看下它到底是如何工作的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









