






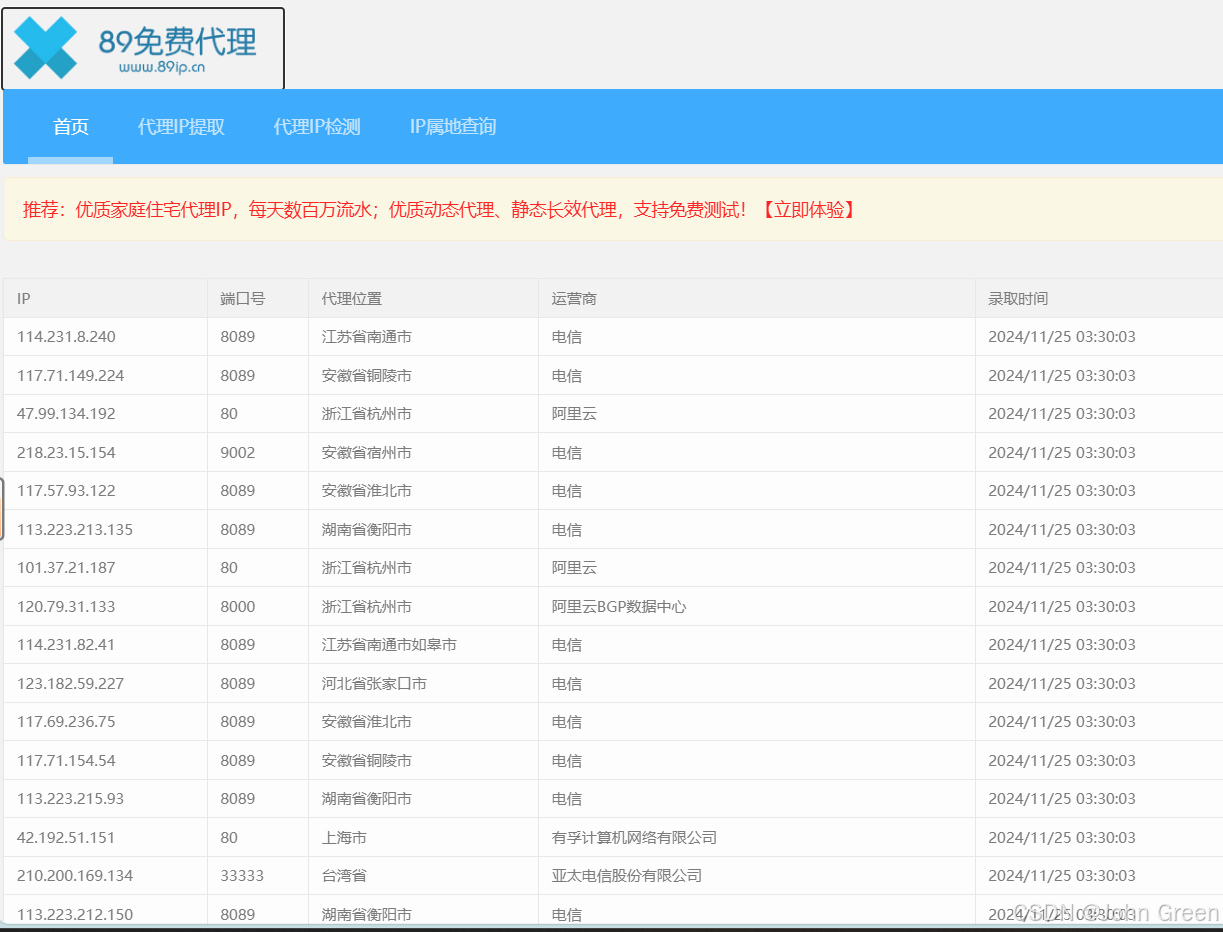
爬取的是89免费代理的IP地址
# 请求发送用的模块
import requests
from lxml import etree
with open("IP代理多页.txt", "w") as f:
for i in range(1, 100):
#发送给谁结果
url = f"https://www.89ip.cn/{i}.html"
print(f'正在获取{url}')
#伪装成浏览器
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
# 发送请求
response = requests.get(url, headers=headers)
#设置编码
# utf-8 是一种字符编码标准,广泛用于互联网和各种系统中,支持全球几乎所有的字符和符号。在 Python 中,utf-8 编码常用于处理文本文件和网络数据。
# gbk 是一种字符编码标准,主要用于中文字符的编码和解码。在 Python 中,gbk 编码常用于处理包含中文字符的文本文件或网络数据。
response.encoding = "utf-8"
#接收响应
# print(response.text)
# 处理结果
#创建可以提取数据的对象。
e = etree.HTML(response.text)
# 提取ip
ips = e.xpath('//div//div[1]//table//tr//td[1]/text()')# //div//div[1]//table//tr//td[1]/text()最后得有/text()
# 提取port
ports = e.xpath('//div//div[1]//table//tr//td[2]/text()')
# 提取地址
addrs = e.xpath('//div//div[1]//table//tr//td[3]/text()')
# 打开名为"IP代理.txt"的文件以写入模式操作
# 这里的with语句确保文件操作后能够正确关闭文件,无需显式调用f.close()
# zip函数将ips, ports, addrs三个列表组合成一个元组的迭代器
# 每次循环中,从迭代器取出一个元组,分别赋值给i, p, a
for i, p, a in zip(ips, ports, addrs):
# 保存到txt文件
# with open("ip.txt", "w") as f:
f.write(f'IP地址: {i.strip()}--port端口号: {p.strip()}--地址:{a.strip()}\n')# .strip()方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列

















 5775
5775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









