




 该博客主要涉及编程任务,目标是改进read_densities函数,使其能处理物质名称包含多个单词的情况。创建了read_densities1和read_densities2两个新函数,分别通过字符串join方法和子串索引来提取物质名称和密度。同时,定义了test_densities函数用于比较这两个函数的输出是否一致。测试函数返回True表示两个函数结果相同。
该博客主要涉及编程任务,目标是改进read_densities函数,使其能处理物质名称包含多个单词的情况。创建了read_densities1和read_densities2两个新函数,分别通过字符串join方法和子串索引来提取物质名称和密度。同时,定义了test_densities函数用于比较这两个函数的输出是否一致。测试函数返回True表示两个函数结果相同。
编程要求
根据提示,在右侧编辑器补充代码。函数read_densities(filename)存在一个问题,即物质的名称只能包含一个或两个单词,而更复杂的表格可能包含名称是由几个单词组成的物质。本任务的目的是使用字符串操作来缩短代码,并使其更加通用和优雅。
- 创建一个函数
read_densities1(filename),让物质名称可由多个单词组成,这些单词是读取的文件每一行除了最后一个单词(表示相应密度的值)之外的所剩下单词。使用字符串对象中的join方法可将这些单词组合起来构成物质的名称。函数返回处理后的字典,以名称为键,相应密度为值。 - 文件
densities.dat中的所有密度值都是从同一列中开始。编写一个替代函数read_densities2(filename),利用子串索引将文件每一行分为两部分(物质名称和密度)。函数返回处理后的字典,以名称为键,相应密度为值。 要注意的是其中的物质名称列占12个字符,需要去掉多余的空格,例如:>>> substance = "air " # 共占12字符>>> substance.strip()>>> 'air'
- 输出两个函数返回的字典,创建一个测试函数
test_densities(filename)来调用上述两个函数,然后进行测试看它们产生的结果是否相同,相同函数返回True,不同返回False。
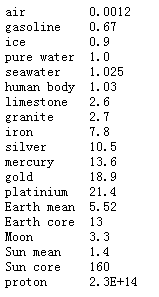
本任务中的densities.dat文件保存在src/step2/densities.dat路径下,文件内容为:
函数read_densities(filename)代码为:
def read_densities(filename):infile = open(filename, 'r')densities = {}for line in infile:words = line.split()density = float(words[-1])if len(words[:-1]) == 2:substance = words[0] + ' ' + words[1]else:substance = words[0]densities[substance] = densityinfile.close()return densities
测试说明
预期的输出为:
- 打印输出函数
read_densities1(filename)的处理结果。 - 打印输出函数
read_densities2(fileanme)的处理结果。 - 打印测试函数
test_densities(filename)的结果
开始你的任务吧,祝你成功!
#coding=utf-8
import re
def read_densities1(filename):
# 请在此处填写代码
# ********** Begin **********#
f=open(filename,'r')
dirt1={}
for i in f:
list1=re.split('\s{2,}',i.rstrip('\n'),2,re.U)
dirt1[list1[0]]=eval(list1[1])
return dirt1
# ********** End **********#
def read_densities2(filename):
# 请在此处填写代码
# ********** Begin **********#
f=open(filename,'r')
dirt1={}
for i in f:
list1=i.rstrip('\n').split()
str1=' '.join(list1[0:len(list1)-1])
dirt1[str1]=eval(list1[-1])
return dirt1
# ********** End **********#
def test_densities(filename):
# 请在此处填写代码
# ********** Begin **********#
if read_densities2(filename)==read_densities1(filename):
return True
else :
return False
# ********** End **********#


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









