



这题的关键在于如何去思考,
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:
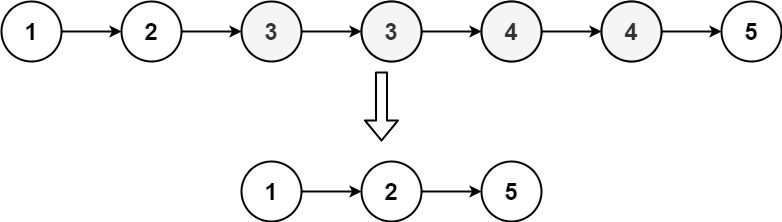
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
示例 2:
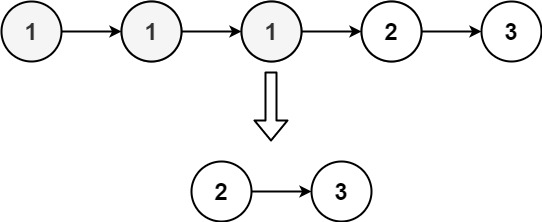
输入:head = [1,1,1,2,3]
输出:[2,3]
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/remove-duplicates-from-sorted-list-ii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
参考大佬的答案,我还是倾向于根据链表的性质来做这道题,首先有递归和迭代两种方法。
递归的话。需要判断当前的节点是否是重复的节点。
首先是退出的条件,当已经没有下一个节点可以递归以及下一个节点与本节点不是重复的值。
def f(head):
if head.val != head.next.val:
head = head.next
else:
cur = head.next
while cur.next and cur.val == head.val:
cur = cur.next
return f(cur)
return head
当然在前面还需判断节点存在以及下一个节点也存在。
if not head or not head.next:return head
接着是迭代,迭代的方法主要难度就是考虑当前节点是否重复值,然后不断后移
先创建两个节点,指向head和前一个节点。用cur判断是否重复,用pre剪切。
dummy = pre = ListNode(0,head)
cur = head
判断条件,当cur还存在的时候,先行判断当cur下一个节点存在以及当前节点与下一个节点值相等,cur寻找到下一个节点。
就有两个情况,一个pre也就是前一个节点就是cur的前一个节点,两个节点距离为1,节点向后移动。否则, 就需要剪切节点,先向pre也就是剪去重复的节点,即cur.next,这里可以将cur直接指向pre,重新开始判断。
while cur:
while cur.next and cur.val == cur.next.val:
cur = cur.next
if pre.next == cur:
pre = pre.next
else:
pre.next = cur.next
cur = pre
cur = cur.next

















 1381
1381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









