



 文章介绍了TIKC++的算子开发流程,包括快速和标准两种方式,并详细讲解了Add算子的实现步骤,涉及到算子分析、核函数定义、内存管理和并行计算策略,特别是doublebuffer机制的应用,以提高计算效率。
文章介绍了TIKC++的算子开发流程,包括快速和标准两种方式,并详细讲解了Add算子的实现步骤,涉及到算子分析、核函数定义、内存管理和并行计算策略,特别是doublebuffer机制的应用,以提高计算效率。
一、学习目标
1. 了解TIK C++算子开发流程
2. 理解TIK C++矢量算子的实现逻辑
3. 掌握Add算子的实现步骤
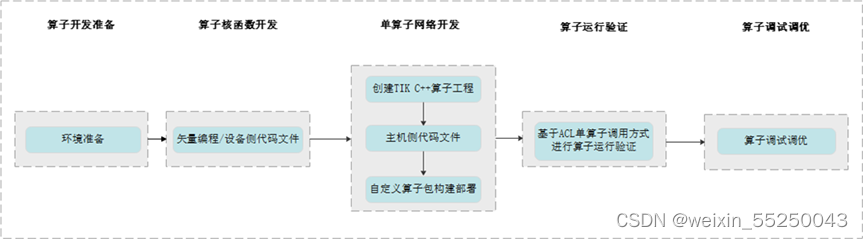
二、算子开发流程
1. 开发流程
(1)快速TIK C++算子开发流程
完成算子核函数的开发
基于内核调用符方式进行算子运行验证

(2)标准TIK C++算子开发流程
完成算子核函数的开发
完成单算子网络应用程序的开发
基于ACL单算子调用方式进行算子运行验证
(3)

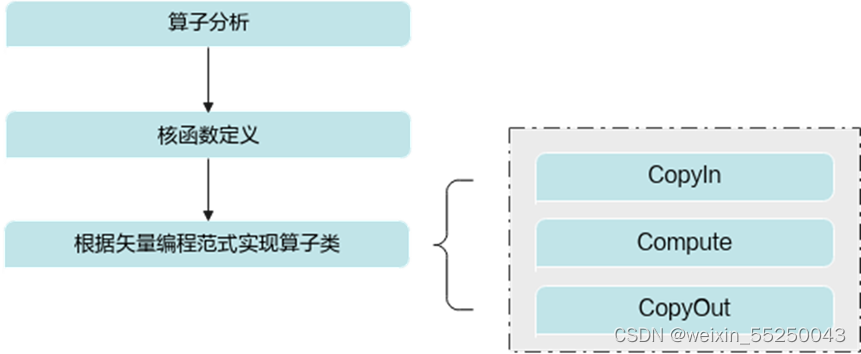
2. TIK C++矢量算子的编程
算子分析:分析算子的数学表达式、输入、输出以及计算逻辑的实现,明确需要调用的TIK C++接口。
核函数定义:定义TIK C++算子入口函数。
根据矢量编程范式实现算子类:完成核函数的内部实现。
3.
以ElemWise(Add)算子为例,数学公式:𝑧 ⃗=𝑥 ⃗+𝑦 ⃗,为简单起见,设定输入张量x, y, z为固定shape(8, 2048),数据类型dtype为half类型,数据排布类型format为ND,核函数名称为add_tik2
(1)算子分析
明确算子的数学表达式及计算逻辑
Add算子的数学表达式为: 𝑧 ⃗=𝑥 ⃗+𝑦 ⃗,计算逻辑:输入数据需要先搬入到片上存储,然后使用计算接口完成两个加法运算,得到最终结果,再搬出到外部存储
明确输入和输出
Add算子有两个输入: 𝑥 ⃗ 与 𝑦 ⃗ ,输出为𝑧 ⃗ 。输入数据类型为half,输出数据类型与输入数据类型相同。输入支持固定shape(8,2048),输出shape与输入shape相同。输入数据排布类型为ND
确定核函数名称和参数
自定义核函数名,如add_tik2。根据输入输出,确定核函数有3个入参x,y,z
x,y为输入在Global Memory上的内存地址,z为输出在Global Memory上的内存地址
确定算子实现所需接口
涉及内外部存储间的数据搬运,使用数据搬移接口:DataCopy实现
涉及矢量计算的加法操作,使用矢量双目指令:Add实现
使用到LocalTensor,使用Queue队列管理,会使用到EnQue、DeQue等接口。

(2)核函数定义
在add_tik2核函数的实现中实例化KernelAdd算子类,调用Init()函数完成内存初始化,调用Process()函数完成核心逻辑
// implementation of kernel function
extern "C" __global__ __aicore__ void add_tik2(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z)
{
KernelAdd op;
op.Init(x, y, z);
op.Process();
}
(3)对于核函数的调用
#ifndef __CCE_KT_TEST__
// call of kernel function
void add_tik2_do(uint32_t blockDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y, uint8_t* z)
{
add_tik2<<<blockDim, l2ctrl, stream>>>(x, y, z);
}
#endif
(4)算子类实现
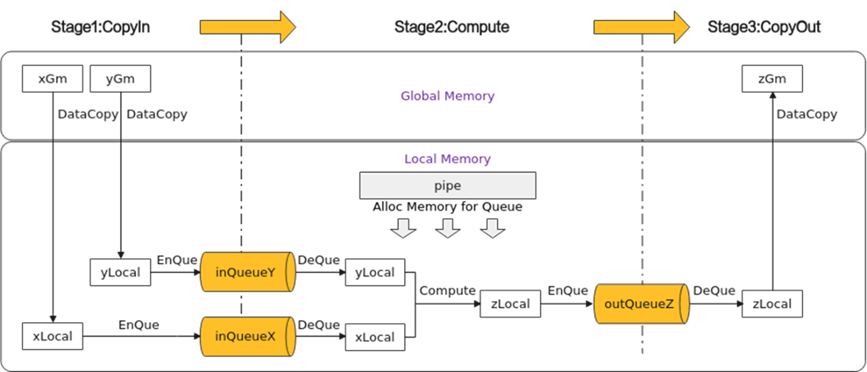
- CopyIn任务:将Global Memory上的输入Tensor xGm和yGm搬运至Local Memory,分别存储在xLocal, yLocal
- Compute任务:对xLocal, yLocal执行加法操作,计算结果存储在zLocal中
- CopyOut任务:将输出数据从zLocal搬运至Global Memory上的输出Tensor zGm中
CopyIn,Compute任务间通过VECIN队列inQueueX,inQueueY进行通信和同步
Compute,CopyOut任务间通过VECOUT队列outQueueZ进行通信和同步
pipe内存管理对象对任务间交互使用到的内存、临时变量使用到的内存统一进行管理
class KernelAdd {
public:
__aicore__ inline KernelAdd() {}
// 初始化函数,完成内存初始化相关操作
__aicore__ inline void Init(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z) {}
// 核心处理函数,实现算子逻辑,调用私有成员函数CopyIn、Compute、CopyOut完成算子逻辑
__aicore__ inline void Process() {}
private:
// 搬入函数,完成CopyIn阶段的处理,被Process函数调用
__aicore__ inline void CopyIn(int32_t progress) {}
// 计算函数,完成Compute阶段的处理,被Process函数调用
__aicore__ inline void Compute(int32_t progress) {}
// 搬出函数,完成CopyOut阶段的处理,被Process函数调用
__aicore__ inline void CopyOut(int32_t progress) {}
private:
// Pipe内存管理对象
TPipe pipe;
// 输入数据Queue队列管理对象,QuePosition为VECIN
TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY;
// 输出数据Queue队列管理对象,QuePosition为VECOUT
TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueZ;
// 管理输入输出Global Memory内存地址的对象,其中xGm, yGm为输入,zGm为输出
GlobalTensor<half> xGm, yGm, zGm;
};
(5)Init()函数实现
使用多核并行计算,需要将数据切片,获取到每个核实际需要处理的在Global Memory上的内存偏移地址
数据整体长度TOTAL_LENGTH为8* 2048,平均分配到8个核上运行,每个核上处理的数据大小BLOCK_LENGTH为2048。block_idx为核的逻辑ID,(__gm__ half*)x + block_idx * BLOCK_LENGTH即索引为block_idx的核的输入数据在Global Memory上的内存偏移地址
对于单核处理数据,可以进行数据切块(Tiling),将数据切分成8块。切分后的每个数据块再次切分成BUFFER_NUM=2块,可开启double buffer,实现流水线之间的并行
单核需要处理的2048个数被切分成16块,每块TILE_LENGTH=128个数据。Pipe为inQueueX分配了BUFFER_NUM块大小为TILE_LENGTH * sizeof(half)个字节的内存块,每个内存块能容纳TILE_LENGTH=128个half类型数据
(6)double buffer机制
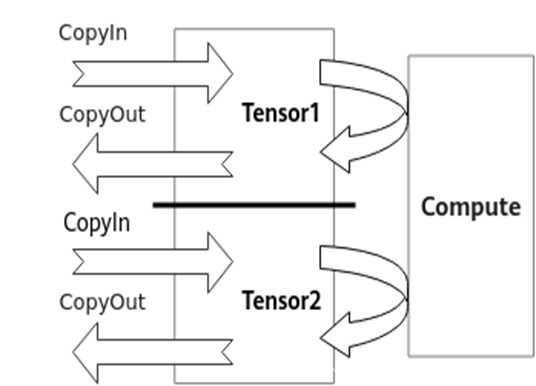
double buffer通过将数据搬运与矢量计算并行执行以隐藏数据搬运时间并降低矢量指令的等待时间,最终提高矢量计算单元的利用效率
1个Tensor同一时间只能进行搬入、计算和搬出三个流水任务中的一个,其他两个流水任务涉及的硬件单元则处于Idle状态
如果将待处理的数据一分为二,比如Tensor1、Tensor2
当矢量计算单元对Tensor1进行Compute时,Tensor2可以执行CopyIn的任务
当矢量计算单元对Tensor2进行Compute时,Tensor1可以执行CopyOut的任务
当矢量计算单元对Tensor2进行CopyOut时,Tensor1可以执行CopyIn的任务
由此,数据的进出搬运和矢量计算之间实现并行,硬件单元闲置问题得以有效缓解


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









