






 本文详细介绍了数据库中的索引类型,包括聚簇索引和非聚簇索引的特点,以及它们在CRUD操作中的差异。讨论了回表操作、覆盖索引的概念,强调了索引顺序和唯一性对性能的影响。此外,还提到了索引下推优化、索引失效的情况以及如何选择和创建合适的索引,以提高查询效率。
本文详细介绍了数据库中的索引类型,包括聚簇索引和非聚簇索引的特点,以及它们在CRUD操作中的差异。讨论了回表操作、覆盖索引的概念,强调了索引顺序和唯一性对性能的影响。此外,还提到了索引下推优化、索引失效的情况以及如何选择和创建合适的索引,以提高查询效率。
18、什么是聚簇索引?
聚簇索引数据和索引存放在一起组成一个b+树
参考前面的第5题
19、一个表中可以有多个(非)聚簇索引吗?
聚簇索引只能有一个
非聚簇索引可以有多个
20、聚簇索引与非聚集索引的特点是什么?
参考前面5题
21、CRUD时聚簇索引与非聚簇索引的区别是什么?
-
聚簇索引插入新值比采用非聚簇索引插入新值的速度要慢很多,因为插入要保证主键不能重复
-
聚簇索引范围,排序查找效率高,因为是有序的
-
非聚簇索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据
22、非聚簇索引为什么不存数据地址值而存储主键?
因为聚簇索引中有时会引发分页操作、重排操作数据有可能会移动
23、什么是回表操作?
id age name sex
age -> index
select * from user where age >20 ;
第一次 取回id,第二次(回表)根据id拿到完整数据
select * from user where age >20 ;
24、什么是覆盖索引?
id age name sex
age -> index
select * from user where age >20 ;
第一次 取回id,第二次(回表)根据id拿到完整数据
age,name -> index
select age from user where age >20 and name like"张%" ;
覆盖索引不会回表查询,查询效率也是比较高的
25、非聚集索引一定回表查询吗?
不一定,只要b+树中包含的字段(创建索引的字段),覆盖(包含)想要select 的字段,那么就不会回表查询了。
26、为什么要回表查询?直接存储数据不可以吗?
为了控制非聚簇索引的大小
27、如果把一个 InnoDB 表的主键删掉,是不是就没有主键,就没办法进行回表查询了?
不是,InnoDB会生成rowid辅助回表查询
28、什么是联合索引,组合索引,复合索引?
为c2和c3列建立联合索引,如下所示:
c2,c3 - > index
c3,c2 -> index
where c3=?
全职匹配
最左前缀
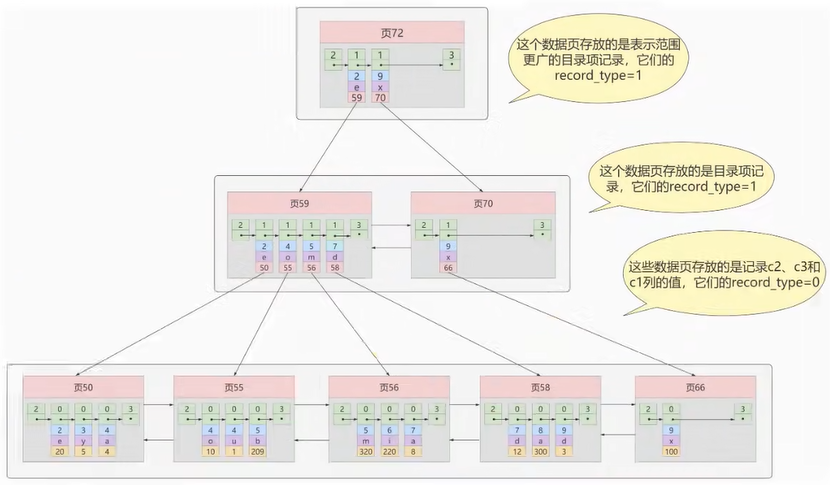
29、复合索引创建时字段顺序不一样使用效果一样吗?
我们也可以同时以多个列的大小作为排序规则,也就是同时为多个列建立索引,比方说我们想让B+树按照 c2和c3列 的大小进行排序,这个包含两层含义:
-
先把各个记录和页按照
c2列进行排序。 -
在记录的
c2列相同的情况下,采用c3列进行排序 -
B+树叶子节点处的记录由
c2列、c3列和主键c1列组成 -
本质上也是二级索引
create index idx_c2_c3 on user (c2,c3);
30、什么是唯一索引?
-
随表一起创建索引:
CREATE TABLE customer (
id INT UNSIGNED AUTO_INCREMENT,
customer_no VARCHAR(200),
customer_name VARCHAR(200),
PRIMARY KEY(id), -- 主键索引:列设定为主键后会自动建立索引,唯一且不能为空。
UNIQUE INDEX uk_no (customer_no), -- 唯一索引:索引列值必须唯一,允许有NULL值,且NULL可能会出现多次。
KEY idx_name (customer_name), -- 普通索引:既不是主键,列值也不需要唯一,单纯的为了提高查询速度而创建。
KEY idx_no_name (customer_no,customer_name) -- 复合索引:即一个索引包含多个列。
);
-
单独建创索引:
CREATE TABLE customer1 (
id INT UNSIGNED,
customer_no VARCHAR(200),
customer_name VARCHAR(200)
);
ALTER TABLE customer1 ADD PRIMARY KEY customer1(id); -- 主键索引
CREATE UNIQUE INDEX uk_no ON customer1(customer_no); -- 唯一索引
CREATE INDEX idx_name ON customer1(customer_name); -- 普通索引
CREATE INDEX idx_no_name ON customer1(customer_no,customer_name); -- 复合索引
031 唯一索引是否影响性能?
是
032 什么时候使用唯一索引?
业务需求唯一字段的时候,一般不考虑性能问题
【强制】业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引。 说明:不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明 显的;另外,即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必 然有脏数据产生。
33、什么时候适合创建索引,什么时候不适合创建索引?
适合创建索引
-
频繁作为where条件语句查询字段
-
关联字段需要建立索引
-
排序字段可以建立索引
-
分组字段可以建立索引(因为分组前提是排序)
-
统计字段可以建立索引(如.count(),max())
不适合创建索引
-
频繁更新的字段不适合建立索引
-
where,分组,排序中用不到的字段不必要建立索引
-
可以确定表数据非常少不需要建立索引
-
参与mysql函数计算的列不适合建索引
创建索引时避免有如下极端误解:
1)宁滥勿缺。认为一个查询就需要建一个索引。
2)宁缺勿滥。认为索引会消耗空间、严重拖慢更新和新增速度。
3)抵制惟一索引。认为业务的惟一性一律需要在应用层通过“先查后插”方式解决。
34、什么是索引下推?
5.6之前的版本是没有索引下推这个优化的
Using index condition:叫作 Index Condition Pushdown Optimization (索引下推优化)
-
如果没有索引下推(ICP),那么MySQL在存储引擎层找到满足content1 > 'z'条件的第一条二级索引记录。主键值进行回表,返回完整的记录给server层,server层再判断其他的搜索条件是否成立。如果成立则保留该记录,否则跳过该记录,然后向存储引擎层要下一条记录。 -
如果使用了索引下推(ICP),那么MySQL在存储引擎层找到满足content1 > 'z'条件的第一条二级索引记录。不着急执行回表,而是在这条记录上先判断一下所有关于idx_content1索引中包含的条件是否成立,也就是content1 > 'z' AND content1 LIKE '%a'是否成立。如果这些条件不成立,则直接跳过该二级索引记录,去找下一条二级索引记录;如果这些条件成立,则执行回表操作,返回完整的记录给server层。
总结:
未开启索引下推:
-
根据筛选条件在索引树中筛选第一个条件
-
获得结果集后回表操作
-
进行其他条件筛选
-
再次回表查询
开启索引下推:在条件查询时,当前索引树如果满足全部筛选条件,可以在当前树中完成全部筛选过滤,得到比较小的结果集再进行回表操作
35、有哪些情况会导致索引失效?
-
计算、函数导致索引失效
-- 显示查询分析
EXPLAIN SELECT * FROM emp WHERE emp.name LIKE 'abc%';
EXPLAIN SELECT * FROM emp WHERE LEFT(emp.name,3) = 'abc'; --索引失效
-
LIKE以%,_ 开头索引失效
拓展:Alibaba《Java开发手册》
【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
EXPLAIN SELECT * FROM emp WHERE name LIKE '%ab%'; --索引失效
-
不等于(!= 或者<>)索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.name = 'abc' ;
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.name <> 'abc' ; --索引失效
-
IS NOT NULL 失效 和 IS NULL
EXPLAIN SELECT * FROM emp WHERE emp.name IS NULL;
EXPLAIN SELECT * FROM emp WHERE emp.name IS NOT NULL; --索引失效
注意:当数据库中的数据的索引列的NULL值达到比较高的比例的时候,即使在IS NOT NULL 的情况下 MySQL的查询优化器会选择使用索引,此时type的值是range(范围查询)
-- 将 id>20000 的数据的 name 值改为 NULL
UPDATE emp SET `name` = NULL WHERE `id` > 20000;
-- 执行查询分析,可以发现 IS NOT NULL 使用了索引
-- 具体多少条记录的值为NULL可以使索引在IS NOT NULL的情况下生效,由查询优化器的算法决定
EXPLAIN SELECT * FROM emp WHERE emp.name IS NOT NULL
-
类型转换导致索引失效
EXPLAIN SELECT * FROM emp WHERE name='123';
EXPLAIN SELECT * FROM emp WHERE name= 123; --索引失效
-
复合索引未用左列字段失效
-
如果mysql觉得全表扫描更快时(数据少);
36、为什么LIKE以%开头索引会失效?
id,name,age
name 创建索引
select * from user where name like '%明'
type=all
select name,id from user where name like '%明'
type=index
张明
(name,age)
其实并不会完全失效,覆盖索引下会出现type=index,表示遍历了索引树,再回表查询,
覆盖索引没有生效的时会直接type=all
没有高效使用索引是因为字符串索引会逐个转换成accii码,生成b+树时按首个字符串顺序排序,类似复合索引未用左列字段失效一样,跳过开始部分也就无法使用生成的b+树了
37、一个表有多个索引的时候,能否手动选择使用哪个索引?
不可用手动直接干预,只能通过mysql优化器自动选择
38、如何查看一个表的索引?
show index from t_emp; // 显示表上的索引
explain select * from t_emp where id=1; // 显示可能会用到的索引及最终使用的索引
39、能否查看到索引选择的逻辑?是否使用过optimizer_trace?
set session optimizer_trace="enabled=on",end_markers_in_json=on;
SELECT * FROM information_schema.OPTIMIZER_TRACE;
set session optimizer_trace="enabled=off";
40、多个索引优先级是如何匹配的?
-
主键(唯一索引)匹配
-
全值匹配(单值匹配)
-
最左前缀匹配
-
范围匹配
-
索引扫描
-
全表扫描
一般性建议
- 对于单键索引,尽量选择过滤性更好的索引(例如:手机号,邮件,身份证)
- 在选择组合索引的时候,过滤性最好的字段在索引字段顺序中,位置越靠前越好。
- 选择组合索引时,尽量包含where中更多字段的索引
- 组合索引出现范围查询时,尽量把这个字段放在索引次序的最后面
- 尽量避免造成索引失效的情况
41、使用Order By时能否通过索引排序?
没有过滤条件不走索引
42、通过索引排序内部流程是什么?
select name,id from user where name like '%明' order by name;
select name,id,age from user where name like '%明'
关键配置:
-
sort_buffer可供排序的内存缓冲区大小
-
max_length_for_sort_data 单行所有字段总和限制,超过这个大小启动双路排序
-
通过索引检过滤筛选条件索到需要排序的字段+其他字段(如果是符合索引)
-
判断索引内容是否覆盖select的字段
-
如果覆盖索引,select的字段和排序都在索引上,那么在内存中进行排序,排序后输出结果
-
如果索引没有覆盖查询字段,接下来计算select的字段是否超过max_length_for_sort_data限制,如果超过,启动双路排序,否则使用单路
-
43、什么是双路排序和单路排序
单路排序:一次取出所有字段进行排序,内存不够用的时候会使用磁盘
双路排序:取出排序字段进行排序,排序完成后再次回表查询所需要的其他字段
如果不在索引列上,filesort有两种算法: mysql就要启动双路排序和单路排序
双路排序(慢)
Select id,age,name from stu order by name;
- MySQL 4.1之前是使用双路排序,字面意思就是两次扫描磁盘,最终得到数据, 读取行指针和order by列,对他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取对应的数据输出
- 从磁盘取排序字段,在buffer进行排序,再从磁盘取其他字段。
- 取一批数据,要对磁盘进行两次扫描,众所周知,I\O是很耗时的,所以在mysql4.1之后,出现了第二种改进的算法,就是单路排序。
单路排序(快)
从磁盘读取查询需要的所有列,按照order by列在buffer对它们进行排序,然后扫描排序后的列表进行输出, 它的效率更快一些,避免了第二次读取数据。并且把随机IO变成了顺序IO,但是它会使用更多的空间, 因为它把每一行都保存在内存中了。
结论及引申出的问题
但是用单路有问题
在sort_buffer中,单路比多路要多占用很多空间,因为单路是把所有字段都取出, 所以有可能取出的数据的总大小超出了sort_buffer的容量,导致每次只能取sort_buffer容量大小的数据,进行排序(创建tmp文件,多路合并),排完再取sort_buffer容量大小,再排……从而多次I/O。
单路本来想省一次I/O操作,反而导致了大量的I/O操作,反而得不偿失。
优化策略
- 增大sort_buffer_size参数的设置
- 增大max_length_for_sort_data参数的设置
- 减少select 后面的查询的字段。 禁止使用select *
提高Order By的速度
1、Order by时select * 是一个大忌。只Query需要的字段, 这点非常重要。在这里的影响是:
当Query的字段大小总和小于max_length_for_sort_data 而且排序字段不是 TEXT|BLOB 类型时,会用改进后的算法——单路排序, 否则用老算法——多路排序。
l 两种算法的数据都有可能超出sort_buffer的容量,超出之后,会创建tmp文件进行合并排序,导致多次I/O,但是用单路排序算法的风险会更大一些,所以要提高sort_buffer_size。
2、 尝试提高 sort_buffer_size
l 不管用哪种算法,提高这个参数都会提高效率,当然,要根据系统的能力去提高,因为这个参数是针对每个进程(connection)的 1M-8M之间调整。 MySQL5.7和8.0,InnoDB存储引擎默认值是1048576字节,1MB。
SHOW VARIABLES LIKE '%sort_buffer_size%';
3、 尝试提高 max_length_for_sort_data
l 提高这个参数, 会增加用改进算法的概率。
SHOW VARIABLES LIKE '%max_length_for_sort_data%';
5.7默认1024字节
8.0默认4096字节
l 但是如果设的太高,数据总容量超出sort_buffer_size的概率就增大,明显症状是高的磁盘I/O活动和低的处理器使用率。如果需要返回的列的总长度大于max_length_for_sort_data,使用双路算法,否则使用单路算法。1024-8192字节之间调整
44、group by 分组和order by在索引使用上有什么区别?
group by 使用索引的原则几乎跟order by一致 ,唯一区别:
-
group by 先排序再分组,遵照索引建的最佳左前缀法则
-
group by没有过滤条件,也可以用上索引。Order By 必须有过滤条件才能使用上索引。
45、如果表中有字段为null,又被经常查询该不该给这个字段创建索引?
应该创建索引,使用的时候尽量使用is null判断。
-
IS NOT NULL 失效 和 IS NULL
EXPLAIN SELECT * FROM emp WHERE emp.name IS NULL;
EXPLAIN SELECT * FROM emp WHERE emp.name IS NOT NULL; --索引失效
注意:当数据库中的数据的索引列的NULL值达到比较高的比例的时候,即使在IS NOT NULL 的情况下 MySQL的查询优化器会选择使用索引,此时type的值是range(范围查询)
-- 将 id>20000 的数据的 name 值改为 NULL
UPDATE emp SET `name` = NULL WHERE `id` > 20000;
-- 执行查询分析,可以发现 IS NOT NULL 使用了索引
-- 具体多少条记录的值为NULL可以使索引在IS NOT NULL的情况下生效,由查询优化器的算法决定
EXPLAIN SELECT * FROM emp WHERE emp.name IS NOT NULL
46、有字段为null索引是否会失效?
不一定会失效,每一条sql具体有没有使用索引 可以通过trace追踪一下
最好还是给上默认值
数字类型的给0,字符串给个空串“”,
参考上一题


















 2802
2802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











