




基于PaddleOCR的DBNet多分类文本检测网络
基于PaddleOCR的DBNet多分类文本检测网络
目的
之前一直思考如果DBnet文本检测网络能够加入多分类的话,就可以实现模型很小又能够区分类别的功能,在端侧部署的话就能达到非常高的精度和效率。在参考了大佬的pytorch版的DBnet多分类功能,在此实现Paddle版的DBnet多分类文本检测网络,注意此方式不适合多个分类有重叠的情况。
模型网络结构对比
修改前 vs 修改后:从图明显发现多出来一个分支用来判定分类的
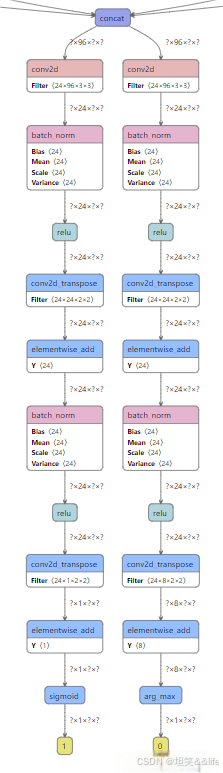
代码实现
经过测试以下方式在官方release/2.6分支中同样好使,本github(文章最后有源码下载地址)中代码版本较低可做参考。
1、数据集格式
新增label_list.txt文件
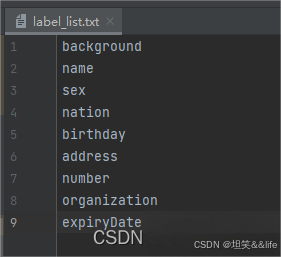
调整数据集中的 “transcription”对应的值,为上图中的label_name
2、配置文件调整
Global:
...
label_list: "../../2.4/train_data/sfz/label_list.txt" #新增一个分类文件
num_classes: 9 # 新增一个分类数量
...
Train:
dataset:
...
transforms:
...
- KeepKeys:
keep_keys: [ 'image', 'threshold_map', 'threshold_mask', 'shrink_map', 'shrink_mask', 'class_mask' ] # 新增一个class_mask
...
...
3、数据预处理
将不同分类按照[1,2,3,4…]的样子进行填充,有三个地方需要调整
label_ops.py
class DetLabelEncode(object):
# def __init__(self, **kwargs):
# pass
def __init__(self, label_list, num_classes=1, **kwargs):
self.num_classes = num_classes
self.label_list = []
if label_list is not None:
if isinstance(label_list, str):
with open(label_list, "r+", encoding="utf-8") as f:
for line in f.readlines():
self.label_list.append(line.replace("\n", ""))
else:
self.label_list = label_list
if num_classes != len(self.label_list):
assert "label_list长度与num_classes长度不符合"
def __call__(self, data):
label = data['label']
label = json.loads(label)
nBox = len(label)
boxes, txts, txt_tags = [], [], []
classes = []
for bno in range(0, nBox):
box = label[bno]['points']
txt = label[bno]['transcription']
boxes.append(box)
txts.append(txt)
if txt in ['*', '###']:
txt_tags.append(True)
if self.num_classes > 1:
classes.append(-2)
else:
txt_tags.append(False)
if self.num_classes > 1:
classes.append(int(self.label_list.index(txt)))
if len(boxes) == 0:
return None
boxes = self.expand_points_num(boxes)
boxes = np.array(boxes, dtype=np.float32)
txt_tags = np.array(txt_tags, dtype=np.bool)
# classes = np.array(classes, dtype=np.int)
classes = classes
data['polys'] = boxes
data['texts'] = txts
data['ignore_tags'] = txt_tags
if self.num_classes > 1:
data['classes'] = classes
return data
make_shrink_map.py

random_crop_data.py
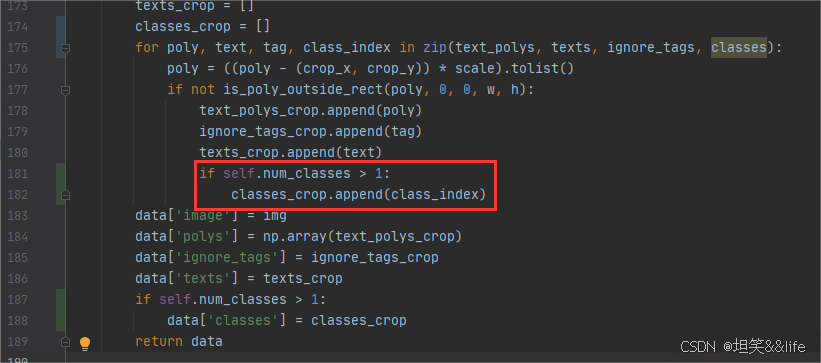
4、模型代码调整
添加新分支,只需要调整head模块就可以了,det_db_head.py代码如下
class Head(nn.Layer):
def __init__(self, in_channels, name_list, num_classes=1):
super(Head, self).__init__()
self.num_classes = num_classes
...
self.conv3 = nn.Conv2DTranspose(
in_channels=in_channels // 4,
out_channels=num_classes,
kernel_size=2,
stride=2,
weight_attr=ParamAttr(
initializer=paddle.nn.initializer.KaimingUniform()),
bias_attr=get_bias_attr(in_channels // 4), )
def forward(self, x):
x = self.conv1(x)
x = self.conv_bn1(x)
x = self.conv2(x)
x = self.conv_bn2(x)
x = self.conv3(x)
if self.num_classes == 1:
x = F.sigmoid(x)
return x
class DBHead(nn.Layer):
def __init__(self, in_channels, num_classes=1, k=50, **kwargs):
super(DBHead, self).__init__()
self.k = k
self.num_classes = num_classes
...
if num_classes != 1:
self.classes = Head(in_channels, binarize_name_list, num_classes=num_classes)
else:
self.classes = None
def step_function(self, x, y):
return paddle.reciprocal(1 + paddle.exp(-self.k * (x - y)))
def forward(self, x, targets=None):
shrink_maps = self.binarize(x)
if not self.training:
if self.num_classes == 1:
return {'maps': shrink_maps}
else:
classes = paddle.argmax(self.classes(x), axis=1, keepdim=True, dtype='int32')
return {'maps': shrink_maps, "classes": classes}
threshold_maps = self.thresh(x)
binary_maps = self.step_function(shrink_maps, threshold_maps)
y = paddle.concat([shrink_maps, threshold_maps, binary_maps], axis=1)
if self.num_classes == 1:
return {'maps': y}
else:
return {'maps': y, "classes": self.classes(x)}
5、添加多分类loss
参考PaddleSeg代码,新增了一个CrossEntropyLoss方法
class CrossEntropyLoss(nn.Layer):
def __init__(self,
weight=None,
ignore_index=255,
top_k_percent_pixels=1.0,
data_format='NCHW'):
super(CrossEntropyLoss, self).__init__()
self.ignore_index = ignore_index
self.top_k_percent_pixels = top_k_percent_pixels
self.EPS = 1e-8
self.data_format = data_format
if weight is not None:
self.weight = paddle.to_tensor(weight, dtype='float32')
else:
self.weight = None
def forward(self, logit, label, semantic_weights=None):
channel_axis = 1 if self.data_format == 'NCHW' else -1
if self.weight is not None and logit.shape[channel_axis] != len(
self.weight):
raise ValueError(
'The number of weights = {} must be the same as the number of classes = {}.'
.format(len(self.weight), logit.shape[channel_axis]))
if channel_axis == 1:
logit = paddle.transpose(logit, [0, 2, 3, 1])
label = label.astype('int64')
# In F.cross_entropy, the ignore_index is invalid, which needs to be fixed.
# When there is 255 in the label and paddle version <= 2.1.3, the cross_entropy OP will report an error, which is fixed in paddle develop version.
loss = F.cross_entropy(
logit,
label,
ignore_index=self.ignore_index,
reduction='none',
weight=self.weight)
return self._post_process_loss(logit, label, semantic_weights, loss)
def _post_process_loss(self, logit, label, semantic_weights, loss):
mask = label != self.ignore_index
mask = paddle.cast(mask, 'float32')
label.stop_gradient = True
mask.stop_gradient = True
if loss.ndim > mask.ndim:
loss = paddle.squeeze(loss, axis=-1)
loss = loss * mask
if semantic_weights is not None:
loss = loss * semantic_weights
if self.weight is not None:
_one_hot = F.one_hot(label, logit.shape[-1])
coef = paddle.sum(_one_hot * self.weight, axis=-1)
else:
coef = paddle.ones_like(label)
if self.top_k_percent_pixels == 1.0:
avg_loss = paddle.mean(loss) / (paddle.mean(mask * coef) + self.EPS)
else:
loss = loss.reshape((-1,))
top_k_pixels = int(self.top_k_percent_pixels * loss.numel())
loss, indices = paddle.topk(loss, top_k_pixels)
coef = coef.reshape((-1,))
coef = paddle.gather(coef, indices)
coef.stop_gradient = True
coef = coef.astype('float32')
avg_loss = loss.mean() / (paddle.mean(coef) + self.EPS)
return avg_loss
class DBLoss(nn.Layer):
"""
Differentiable Binarization (DB) Loss Function
args:
param (dict): the super paramter for DB Loss
"""
def __init__(self,
balance_loss=True,
main_loss_type='DiceLoss',
alpha=5,
beta=10,
ohem_ratio=3,
eps=1e-6,
num_classes=1,
**kwargs):
super(DBLoss, self).__init__()
self.alpha = alpha
self.beta = beta
self.num_classes = num_classes
self.dice_loss = DiceLoss(eps=eps)
self.l1_loss = MaskL1Loss(eps=eps)
self.bce_loss = BalanceLoss(
balance_loss=balance_loss,
main_loss_type=main_loss_type,
negative_ratio=ohem_ratio)
self.loss_func = CrossEntropyLoss()
def forward(self, predicts, labels):
predict_maps = predicts['maps']
if self.num_classes > 1:
predict_classes = predicts['classes']
label_threshold_map, label_threshold_mask, label_shrink_map, label_shrink_mask, class_mask = labels[1:]
else:
label_threshold_map, label_threshold_mask, label_shrink_map, label_shrink_mask = labels[1:]
shrink_maps = predict_maps[:, 0, :, :]
threshold_maps = predict_maps[:, 1, :, :]
binary_maps = predict_maps[:, 2, :, :]
loss_shrink_maps = self.bce_loss(shrink_maps, label_shrink_map,
label_shrink_mask)
loss_threshold_maps = self.l1_loss(threshold_maps, label_threshold_map,
label_threshold_mask)
loss_binary_maps = self.dice_loss(binary_maps, label_shrink_map,
label_shrink_mask)
loss_shrink_maps = self.alpha * loss_shrink_maps
loss_threshold_maps = self.beta * loss_threshold_maps
# 处理
if self.num_classes > 1:
loss_classes = self.loss_func(predict_classes, class_mask)
loss_all = loss_shrink_maps + loss_threshold_maps + loss_binary_maps + loss_classes
losses = {'loss': loss_all,
"loss_shrink_maps": loss_shrink_maps,
"loss_threshold_maps": loss_threshold_maps,
"loss_binary_maps": loss_binary_maps,
"loss_classes": loss_classes}
else:
loss_all = loss_shrink_maps + loss_threshold_maps + loss_binary_maps
losses = {'loss': loss_all,
"loss_shrink_maps": loss_shrink_maps,
"loss_threshold_maps": loss_threshold_maps,
"loss_binary_maps": loss_binary_maps}
return losses
6、修改db_postprocess.py
class DBPostProcess(object):
"""
The post process for Differentiable Binarization (DB).
"""
def __init__(self,
thresh=0.3,
box_thresh=0.7,
max_candidates=1000,
unclip_ratio=2.0,
use_dilation=False,
score_mode="fast",
**kwargs):
self.thresh = thresh
self.box_thresh = box_thresh
self.max_candidates = max_candidates
self.unclip_ratio = unclip_ratio
self.min_size = 3
self.score_mode = score_mode
assert score_mode in [
"slow", "fast"
], "Score mode must be in [slow, fast] but got: {}".format(score_mode)
self.dilation_kernel = None if not use_dilation else np.array(
[[1, 1], [1, 1]])
def boxes_from_bitmap(self, pred, _bitmap, classes, dest_width, dest_height):
'''
_bitmap: single map with shape (1, H, W),
whose values are binarized as {0, 1}
'''
bitmap = _bitmap
height, width = bitmap.shape
outs = cv2.findContours((bitmap * 255).astype(np.uint8), cv2.RETR_LIST,
cv2.CHAIN_APPROX_SIMPLE)
if len(outs) == 3:
img, contours, _ = outs[0], outs[1], outs[2]
elif len(outs) == 2:
contours, _ = outs[0], outs[1]
num_contours = min(len(contours), self.max_candidates)
boxes = []
scores = []
class_indexes = []
class_scores = []
for index in range(num_contours):
contour = contours[index]
points, sside = self.get_mini_boxes(contour)
if sside < self.min_size:
continue
points = np.array(points)
if self.score_mode == "fast":
score, class_index, class_score = self.box_score_fast(pred, points.reshape(-1, 2), classes)
else:
score, class_index, class_score = self.box_score_slow(pred, contour, classes)
if self.box_thresh > score:
continue
box = self.unclip(points).reshape(-1, 1, 2)
box, sside = self.get_mini_boxes(box)
if sside < self.min_size + 2:
continue
box = np.array(box)
box[:, 0] = np.clip(
np.round(box[:, 0] / width * dest_width), 0, dest_width)
box[:, 1] = np.clip(
np.round(box[:, 1] / height * dest_height), 0, dest_height)
boxes.append(box.astype(np.int16))
scores.append(score)
class_indexes.append(class_index)
class_scores.append(class_score)
if classes is None:
return np.array(boxes, dtype=np.int16), scores
else:
return np.array(boxes, dtype=np.int16), scores, class_indexes, class_scores
def unclip(self, box):
unclip_ratio = self.unclip_ratio
poly = Polygon(box)
distance = poly.area * unclip_ratio / poly.length
offset = pyclipper.PyclipperOffset()
offset.AddPath(box, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
expanded = np.array(offset.Execute(distance))
return expanded
def get_mini_boxes(self, contour):
bounding_box = cv2.minAreaRect(contour)
points = sorted(list(cv2.boxPoints(bounding_box)), key=lambda x: x[0])
index_1, index_2, index_3, index_4 = 0, 1, 2, 3
if points[1][1] > points[0][1]:
index_1 = 0
index_4 = 1
else:
index_1 = 1
index_4 = 0
if points[3][1] > points[2][1]:
index_2 = 2
index_3 = 3
else:
index_2 = 3
index_3 = 2
box = [
points[index_1], points[index_2], points[index_3], points[index_4]
]
return box, min(bounding_box[1])
def box_score_fast(self, bitmap, _box, classes):
'''
box_score_fast: use bbox mean score as the mean score
'''
h, w = bitmap.shape[:2]
box = _box.copy()
xmin = np.clip(np.floor(box[:, 0].min()).astype(np.int), 0, w - 1)
xmax = np.clip(np.ceil(box[:, 0].max()).astype(np.int), 0, w - 1)
ymin = np.clip(np.floor(box[:, 1].min()).astype(np.int), 0, h - 1)
ymax = np.clip(np.ceil(box[:, 1].max()).astype(np.int), 0, h - 1)
mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
box[:, 0] = box[:, 0] - xmin
box[:, 1] = box[:, 1] - ymin
cv2.fillPoly(mask, box.reshape(1, -1, 2).astype(np.int32), 1)
if classes is None:
return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0], None, None
else:
k = 999
class_mask = np.full((ymax - ymin + 1, xmax - xmin + 1), k, dtype=np.int32)
cv2.fillPoly(class_mask, box.reshape(1, -1, 2).astype(np.int32), 0)
classes = classes[ymin:ymax + 1, xmin:xmax + 1]
new_classes = classes + class_mask
# 拉平
a = new_classes.reshape(-1)
b = np.where(a >= k)
classes = np.delete(a, b[0].tolist())
class_index = np.argmax(np.bincount(classes))
class_score = np.sum(classes == class_index) / len(classes)
return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0], class_index, class_score
def box_score_slow(self, bitmap, contour, classes):
'''
box_score_slow: use polyon mean score as the mean score
'''
h, w = bitmap.shape[:2]
contour = contour.copy()
contour = np.reshape(contour, (-1, 2))
xmin = np.clip(np.min(contour[:, 0]), 0, w - 1)
xmax = np.clip(np.max(contour[:, 0]), 0, w - 1)
ymin = np.clip(np.min(contour[:, 1]), 0, h - 1)
ymax = np.clip(np.max(contour[:, 1]), 0, h - 1)
mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
contour[:, 0] = contour[:, 0] - xmin
contour[:, 1] = contour[:, 1] - ymin
cv2.fillPoly(mask, contour.reshape(1, -1, 2).astype(np.int32), 1)
if classes is None:
return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0], None, None
else:
k = 999
class_mask = np.full((ymax - ymin + 1, xmax - xmin + 1), k, dtype=np.int32)
cv2.fillPoly(class_mask, contour.reshape(1, -1, 2).astype(np.int32), 0)
classes = classes[ymin:ymax + 1, xmin:xmax + 1]
new_classes = classes + class_mask
# 拉平
a = new_classes.reshape(-1)
b = np.where(a >= k)
classes = np.delete(a, b[0].tolist())
class_index = np.argmax(np.bincount(classes))
class_score = np.sum(classes == class_index) / len(classes)
return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0], class_index, class_score
def __call__(self, outs_dict, shape_list):
pred = outs_dict['maps']
if isinstance(pred, paddle.Tensor):
pred = pred.numpy()
pred = pred[:, 0, :, :]
segmentation = pred > self.thresh
if "classes" in outs_dict:
classes = outs_dict['classes']
if isinstance(classes, paddle.Tensor):
classes = classes.numpy()
else:
classes = None
boxes_batch = []
for batch_index in range(pred.shape[0]):
src_h, src_w, ratio_h, ratio_w = shape_list[batch_index]
if self.dilation_kernel is not None:
mask = cv2.dilate(
np.array(segmentation[batch_index]).astype(np.uint8),
self.dilation_kernel)
else:
mask = segmentation[batch_index]
if classes is None:
boxes, scores = self.boxes_from_bitmap(pred[batch_index], mask, None,
src_w, src_h)
boxes_batch.append({'points': boxes})
else:
boxes, scores, class_indexes, class_scores = self.boxes_from_bitmap(pred[batch_index], mask,
classes[batch_index],
src_w, src_h)
boxes_batch.append({'points': boxes, "classes": class_indexes, "class_scores": class_scores})
return boxes_batch
7、修改train.py、eval.py、infer_det.py和export_model.py
添加这两行代码
if "num_classes" in global_config:
config['Architecture']["Head"]['num_classes'] = global_config["num_classes"]
config['Loss']['num_classes'] = global_config["num_classes"]
完毕!!!
到此,整个网络结构及核心代码就完成了!本文只讲解了在python端相关实现和部署代码,如果需要c++、端侧等部署代码可以加QQ【2952855968】获取,接下来我们看看实际效果如何。

后面将写几篇文章来讲解DBNet多分类的应用,敬请关注!
github代码地址:GitHub - yangy996/PaddleOCR
无法访问以上链接,请访问 https://download.youkuaiyun.com/download/weixin_54626591/92423933
工程应用:
底下评论
问题一:
请问博主,export_model.py里并没有定义global_config的操作,需要加那段代码么?
作者回答:
需要加的,具体代码已经放到了github上了
问题二:
你好,我想问下代码中提到的数据集是不是没放到github呀,还是说我没找到表情包?
作者回答:
这个身份证数据集没法公开表情包,你可以自己标注,我下篇文章有这个身份证多分类检测的模型,你可以下载试试。
提问者提问:
你好,我对一些相似度高的文本进行分类时,效果不是特别好,请问有什么方法能优化一下呢?
提问者提问:
还有就是像身份证这种文本位置基本固定的情况,DBNet能够学习到相应的位置特征吗表情包。我是小白,问题比较多,还是希望博主能解答一下,谢谢。
提问者提问:
另外就是DBNet针对这种文字基本都是位置的情况,也能够学习到对应的位置信息吗?我是小白,问题比较多,希望博主能解答一下表情包,谢谢~
作者回答:
可以的,对应这种相似度高情况,最好使用比较大的深度网络,比如ResNet50,可以提取到更多的特征,效果会比较好
作者回答:
位置特征用DBNet不合适,这只能检测文字,位置特征可以参考下人脸识别的关键点检测
提问者提问:
谢谢,我试试
问题三:
博主请问数据集标注的格式使用ppocrLabel kie模式标注的数据集可以训练吗?
作者回答:
正常标注就可以了,只是需要把识别结果改成分类label
提问者提问:
{“transcription”: “******”, “points”: [[305, 168], [329, 167], [338, 471], [308, 471]], “difficult”: false, “key_cls”: “address”}
现在官方的标注工具支持kie,我把transcription改到了key_cls也能正常训练
提问者提问:
博主,我现在在拿飞桨OCR训练银行卡识别,大概训练了6000-8000张图片,但是效果一直不是很明显,有什么好的建议吗?ch_PP-OCRv3_det_distill_train基于这个模型进行finetune的,ch_PP-OCRv2_rec_train 文字识别使用的这个
作者回答:
这么多图片效果还不好吗?你可以看看我的另外的一个博客,训练的银行卡识别效果很不错
作者回答:
改成这样的{“transcription”: “address”, “points”: [[305, 168], [329, 167], [338, 471], [308, 471]], “difficult”: false}
提问者提问:
对的,我感觉文字识别准确率还是比较低,而且很多识别结果会多出几个数字的情况,我用了你那个博客里的数据集和我们自己标注的一部分
问题四:
博主,有个问题,上面你的覆盖了单行多行文本,如果同时还要检测比如二维码这样的是不是不能用dbnet网络
作者回答:
可以用,dbnet本质上就是个分割网络,检测别的也是可以的,只是对文本检测多做了一些后处理
提问者提问:
多谢博主,这几天正在做这方面的工作,感谢你的分享表情包
问题五:
hi,训练数据的标注结果是什么样的格式呢
作者回答:
标注就是把之前识别出来的文字换成分类label
问题五:
博主你好!我按照你的教程成功训练出了模型,在训练模型上效果很好,但转成推理模型后,正确率下降很多,请问你是怎么转换的呢?十分感谢
作者回答:
看看这篇文章, 网页链接
提问者提问:
感谢博主回复,我修改yml重新训练后 预测模型和推理模型正确率相同的结果,但出现新的问题,推理模型的检测框比预测结果的检测框大很多,但predict_det.py中的unclip_ratio都是1.5 我无论怎么修改这个值,都无法改变检测框的大小
作者回答:
那就不清楚了,你看一下代码是哪里改的没生效
提问者提问:
博主 好的,我这边还有一个疑问,我参考了你GitHub上的代码,使用inter_det.py 有label输出,但使用predict_det.py却没有label输出,请问我需要改哪儿呢表情包
作者回答:
predict_det.py中def call(self, img, cls=False):,cls改成True就会输出label
其他人提问:
您好,我和您遇到相同的问题,推理模型检测结果很差,请问你是怎么解决的?博主的链接失效了表情包
其他人提问:
请问yml文件你这边做了哪些修改呀,我这也出现了预测模型和推理模型正确率差太多了情况
作者回答:
修改的地方在文章中有详细标注呀
其他人提问:
请问您是怎么解决 , 预测模型 在推理的时候 差异很大的问题?
其他人提问:
你好. 您是直接 重新训练就解决了 预测模型和推理模型 差异过大的问题吗? 还是修改了什么参数? 求解.
其他人提问:
你好,解决了吗,我也遇到了同样的问题
其他人提问:
改成True能输出label,但predict_det输出的label全是错的,infer_det输出的是正确的,是怎么回事呀
作者回答:
不会呀,你传入的label不对吗?
其他人提问:
请问您有解决这个问题吗?
问题六:
PP-OCRv3_det_student.yml训练出的模型 网络结构和官方给出的一模一样是什么情况
作者回答:
什么意思呢?官方的代码肯定跟官方的模型一样呀
提问者提问:
我是按照你的方式,修改了P-OCRv3_det_student.yml,然后训练出来的模型和官方模型的网络结构一样
作者回答:
配置文件改了吗?会根据配置文件自动识别是不是多分类的
其他人提问:
老哥 后来这个问题有解决吗?
问题七:
想问一下,训练数据中background这一类,怎么标注,这一类数据量要很多吗?
作者回答:
background这一类不需要处理,也不需要标注图片
问题八:
博主请问Paddle里的DBnet++也能增加分类效果吗?
作者回答:
可以
问题九:
我按照文章设置后,一直报错,assert loss<=1
作者回答:
没遇到过这种错误,应该是没配置正确
提问者提问:
已解决,x=F.sigmoid(x)这里不修改就不会报错
问题十:
你好,基于ch_det_res18_db_v2.0.yml 这个模型配置文件能多分类加标签训练不
作者回答:
可以的
问题十一:
你好,能用官方的预训练检测模型吗
作者回答:
可以
提问者提问:
你好, 标注用什么工具方便
作者回答:
官网的标注工具就行
问题十二:
你好,我训练出的检测结果还可以,但是分类会出现类别标签不对的情况。请问这种情况下应该怎么优化呢?我尝试修改det_db_loss.py中的逻辑,在CrossEntropyLoss中的_post_process_loss返回avg_loss时,给他加了一个权重,
作者回答:
我研究过,如果只在这个网络上加分类,适合检测区域与整图比值较大的场景,比值较小的场景效果就差很多,这种情况需要更复杂的网络去获取特征。
提问者提问:
嗯,感谢作者,我试着用DB++,骨干网络换成了Resnet, 用了这个配置det_r50_db++_td_tr.yml,效果确实好一些。 但是推理速度变得非常慢,我在想是不是Resnet层数不设置成50层,更少一点会更好,还是我量化一下用slim来精度设置成int8效果会更好,作者有什么建议吗?
其他人提问:
你好,我也遇到了分类标签效果不好的问题,所以我参考您的评论做了修改,现在我训练好的模型对所有图片做预测,文字框标签都是background,您知道是什么原因吗?
问题十三:
DetLabelEncode第26行为什么取的是标注的内容,是不是应该取分类的具体值
作者回答:
最开始的标注软件里没有分类的标注,就直接拿内容当做分类
问题十四:
大佬,好像2.6.1版本训练的时候,会出现评估的时候,计算不出来数据,一直都是0,这个问题你有遇到过吗?
问题十五:
请问一下,你一共标注了多少张呢
作者回答:
5千多张
问题十六:
身份证住址有多行时,文字识别为什么只识别出来一行.



















 2052
2052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











