






 本文探讨了如何通过子域名查询、黑暗引擎搜索、国外地址访问和邮件地址分析来避开CDN,包括使用遗留文件哈希比对、工具如FUCKCDN以及利用DNS记录和手机站点。了解这些技巧有助于识别真实IP并理解网站架构。
本文探讨了如何通过子域名查询、黑暗引擎搜索、国外地址访问和邮件地址分析来避开CDN,包括使用遗留文件哈希比对、工具如FUCKCDN以及利用DNS记录和手机站点。了解这些技巧有助于识别真实IP并理解网站架构。
CDN绕过
查询有无cdn
通过超级ping或站长之家查询域名所对应的IP是否存在多个如果是基本上可判断有CDN
查询www.baidu.com
存在CDN
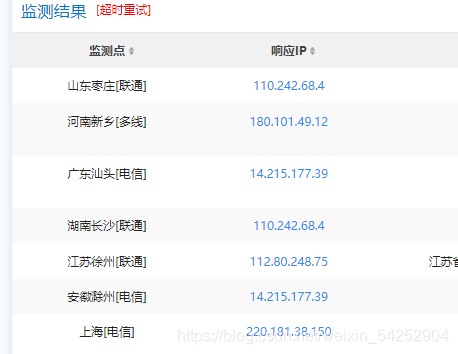
常见绕过cdn
- 子域名查询
- 黑暗引擎搜素
- 国外地址请求
- 邮件服务查询
- 遗留文件扫描全网
- dns记录
- 手机站点
获取IP后通过修改Host文件来进行判断是否为真实网站
子域名查询
www.baidu.com
bbs.baidu.com
mail.baidu.com
可能网站由于经济原因没有在分站进行cdn,那就可以从分站IP来推算主站的真实IP可能一样可能在同一网段
小技巧:可以通过查询baidu,.com和www.baidu.com的IP来进行判断主站IP
黑暗引擎搜素
查询该网站以前的DNS记录
https://get-site-ip.com/ 直接查真实IP(有时可能不能信)
https://fofa.so/ 通过搜素网站源码的一些特有信息
shadon shadon不解释
手机站点
如果存在手机站点如m.baidu.com
有时手机站点就是真正的站点
国外地址访问
国外IP请求
通过比较偏僻的国外地址访问由于地理位置原因没有设置cdn所有可能直接就是访问主站
邮件地址查询
通过分析该网站发送的注册邮件的源码
然后通过邮件的源码文件查看是从哪个地址发来的来确定真实IP
可以拿本地host文件来进行判定或通过网站的一些地理信息来进行对比最终确定真实IP
修改host文件时先拿错误的地址来进行刷新缓存然后拿获得的IP来进行判断如果能访问成功就是真实IP
遗留文件扫描全网
因为每个网站的图标hash都是不同的,所有可以可用这一点来进行判断
python代码获取图标hash
import mmh3
import requests
response = request.get("http://.....") #网站图标地址获取源码
favicon = response.content.encode("base64") #进行base64进行加密
hash = mmh3.hash(favicon) #生成hash
print("http.favicon.hash"+str(hash))
然后拿hash 到shadon进行查询即可
fuckcdn
通过工具进行查询
fuckcdn
网站有具体教程

















 2482
2482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









