




 本文探讨了Python中匿名函数(lambda表达式)与有名称函数的区别,包括它们的优势(简洁、性能提升)、闭包的概念及其内存管理。还介绍了装饰器、JSON编码解码、高阶函数(map, reduce, filter, sorted)以及生成器的使用。
本文探讨了Python中匿名函数(lambda表达式)与有名称函数的区别,包括它们的优势(简洁、性能提升)、闭包的概念及其内存管理。还介绍了装饰器、JSON编码解码、高阶函数(map, reduce, filter, sorted)以及生成器的使用。
匿名函数:是指一类无需定义标识符(函数名)的函数或子程序
函数定义中:def关键字,可以定义带有名称的函数(无名称)
lambda关键字,可以定义匿名函数(无名称)
有名称的函数,可以基于名称重复使用
无名称的函数,只可临时使用一次
相比函数,lamba 表达式具有以下 2 个优势:
对于单行函数,使用 lambda 表达式可以省去定义函数的过程,让代码更加简洁;
对于不需要多次复用的函数,使用 lambda 表达式可以在用完之后立即释放,提高程序执行的性能。
通过def 关键字,定义函数,并且传入参数
def test_func(compute):
result=compute(1,2)
print(result)
def compute(x,y):
return x+y
test_func(compute)
输出结果
3
通过lambda关键字,传入一个一次性使用的lambda函数
def test_func(compute):
result=compute(1,2)
print(result)
test_func(lambda x,y:4+6)
输出结果
E:\python\python.exe E:/python_code/douban/__init__.py
10
Process finished with exit code 0
内存回收机制
内存回收机制就是不在用到的内存空间,系统会自动进行清理出空间提供给其他程序使用。那回收的前提是什么呢?
内部函数引用外部的函数的变量,外部函数执行完毕,作用域也不会删除。从而形成了一种不删除的独立作用域。
某一个变量或者对象被引用,因此在回收的时候不会释放它,因为被引用代表着被使用,回收机制不会对正在引用的变量或对象进行回收的。
闭包:如果在一个内部函数里,对在外部作用于(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是闭包
闭包=函数+环境变量(函数定义的时候)
函数定义一点要在定义函数的外部,不能为全局变量
闭包=函数+自由变量的引用(在一个函数中,如果某个变量既不是在函数内部创建的,也不属于函数的形参,还不是全局变量,那就是自由变量)
闭包的现象
:在模板中定义的函数
首先取值,一点是在函数作用域寻找
然后再模板寻找。
重点:不要引用任何循环变量,或是在后续发生变化的变量。或者删除global
如果要引用循环变量,那就重新创建一个函数,用该函数参数绑定循环变量当前的值,无论该循环变量的值后续怎么更改,已经绑定导函数参数的值不变。
Python中的作用域共有3种:
- 局部作用域:这是在一个函数内部定义的变量;
- 闭包作用域:这是在一个函数外部另一个函数内部定义的变量;
- 全局作用域:在所有函数外定义的变量。
闭包包含自由(未绑定到特定对象)变量;这些变量不是在这个代码块内或者任何全局上下文中定义的,而是在定义代码块的环境中定义(局部变量)。"闭包" 一词来源于以下两者的结合:要执行的代码块(由于自由变量被包含在代码块中,这些自由变量以及它们引用的对象没有被释放)和为自由变量提供绑定的计算环境(作用域)。在PHP、Scala、Scheme、Common Lisp、Smalltalk、Groovy、JavaScript、Ruby、 Python、Go、Lua、objective c、swift 以及Java(Java8及以上)等语言中都能找到对闭包不同程度的支持。


如上代码,func1是内部函数,他对于外部函数func中变量a进行引用(使用),延长了外部函数变量a的寿命。所以内部函数func1就是闭包。。。闭包的意义 就是让外部函数的变量活下来,大规模使用,会对内存有消耗。
在这个例子中,内部函数只有在外部函数调用时才会存活,要延续其内部的生命,所以要进行return func1操作,让其在外部函数运行完后继续存活。
装饰器(语法糖@)
就是用于拓展原来函数功能的一种函数,这个函数的特殊之处在于它的返回值也是一个函数,使用python装饰器的好处就是在不用更改原函数的代码前提下给函数增加新的功能
不影响原来函数的功能;
还能添加新的功能
枚举:
一些具有特殊含义的类,其实例化对象的个数往往是固定的,比如用一个类表示月份,则该类的实例对象最多有 12 个;再比如用一个类表示季节,则该类的实例化对象最多有 4 个。
针对这种特殊的类,Python 3.4 中新增加了 Enum 枚举类。也就是说,对于这些实例化对象个数固定的类,可以用枚举类来定义
JSON 函数
使用 JSON 函数需要导入 json 库:import json。
| 函数 | 描述 |
|---|---|
| json.dumps | 将 Python 对象编码成 JSON 字符串 |
| json.loads | 将已编码的 JSON 字符串解码为 Python 对象 |
json.dumps
json.dumps 用于将 Python 对象编码成 JSON 字符串。
语法
json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding="utf-8", default=None, sort_keys=False, **kw)
实例
以下实例将数组编码为 JSON 格式数据:
实例
#!/usr/bin/python
import json
data = [ { 'a' : 1, 'b' : 2, 'c' : 3, 'd' : 4, 'e' : 5 } ]
data2 = json.dumps(data)
print(data2)
以上代码执行结果为:
[{"a": 1, "c": 3, "b": 2, "e": 5, "d": 4}]
使用参数让 JSON 数据格式化输出:
实例
#!/usr/bin/python
import json
data = [ { 'a' : 1, 'b' : 2, 'c' : 3, 'd' : 4, 'e' : 5 } ]
data2 = json.dumps({'a': 'Runoob', 'b': 7}, sort_keys=True, indent=4, separators=(',', ': '))
print(data2)
以上代码执行结果为:
{
"a": "Runoob",
"b": 7
}
python 原始类型向 json 类型的转化对照表:
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str, unicode | string |
| int, long, float | number |
| True | true |
| False | false |
| None | null |
json.loads
json.loads 用于解码 JSON 数据。该函数返回 Python 字段的数据类型。
语法
json.loads(s[, encoding[, cls[, object_hook[, parse_float[, parse_int[, parse_constant[, object_pairs_hook[, **kw]]]]]]]])
实例
以下实例展示了Python 如何解码 JSON 对象:
实例
#!/usr/bin/python
import json
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}';
text = json.loads(jsonData)
print(text)
以上代码执行结果为:
{u'a': 1, u'c': 3, u'b': 2, u'e': 5, u'd': 4}
json 类型转换到 python 的类型对照表:
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | unicode |
| number (int) | int, long |
| number (real) | float |
| true | True |
| false | False |
| null | None |
更多内容参考:18.2. json — JSON encoder and decoder — Python 2.7.18 documentation。
使用第三方库:Demjson
Demjson 是 python 的第三方模块库,可用于编码和解码 JSON 数据,包含了 JSONLint 的格式化及校验功能。
官方地址:http://deron.meranda.us/python/demjson/
JSON 函数
| 函数 | 描述 |
|---|---|
| encode | 将 Python 对象编码成 JSON 字符串 |
| decode | 将已编码的 JSON 字符串解码为 Python 对象 |
encode
Python encode() 函数用于将 Python 对象编码成 JSON 字符串。
语法
demjson.encode(self, obj, nest_level=0)
实例
以下实例将数组编码为 JSON 格式数据:
实例
#!/usr/bin/python
import demjson
data = [ { 'a' : 1, 'b' : 2, 'c' : 3, 'd' : 4, 'e' : 5 } ]
json = demjson.encode(data)
print(json)
以上代码执行结果为:
[{"a":1,"b":2,"c":3,"d":4,"e":5}]
decode
Python 可以使用 demjson.decode() 函数解码 JSON 数据。该函数返回 Python 字段的数据类型。
语法
demjson.decode(self, txt)
实例
以下实例展示了Python 如何解码 JSON 对象:
实例
#!/usr/bin/python
import demjson
json = '{"a":1,"b":2,"c":3,"d":4,"e":5}';
text = demjson.decode(json)
print(text)
以上代码执行结果为:
{u'a': 1, u'c': 3, u'b': 2, u'e': 5, u'd': 4}
高阶函数:map,reduce,filter,sorted
map,reduce,filter,sorted map 一般可以接受二個參數,把第二個參數的元素依次傳入第一個參數中,一般第一個參數是一個函數 reduce 將第二個參數中的元素傳遞給第一個參數,並在第一個參數運算結束後, 將返回值作為第二次運算的其中一個參數 filter 返回值為真,才進行輸出 sorted 正序排列 可以在第二個參數中添加函數 abs,lower,upper,reverse = True 倒敘排列 base64 encode / decode
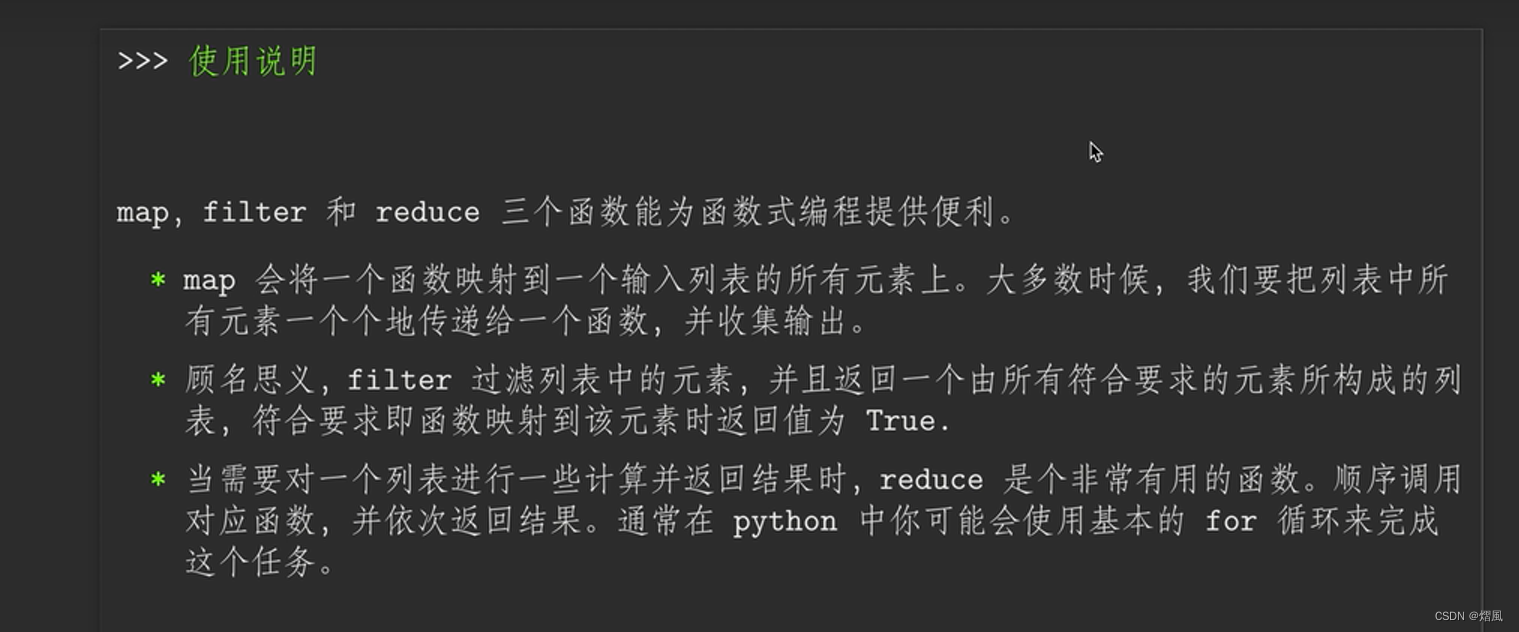
map:(映射)
第一个参数接受一个函数名,后面的参数接受一个或多个可迭代的序列,返回的是一个集合(迭代器)。
把函数依次作用在list中的每一个元素上,得到一个新的list并返回。注意,map不改变原list,而是返回一个新list。
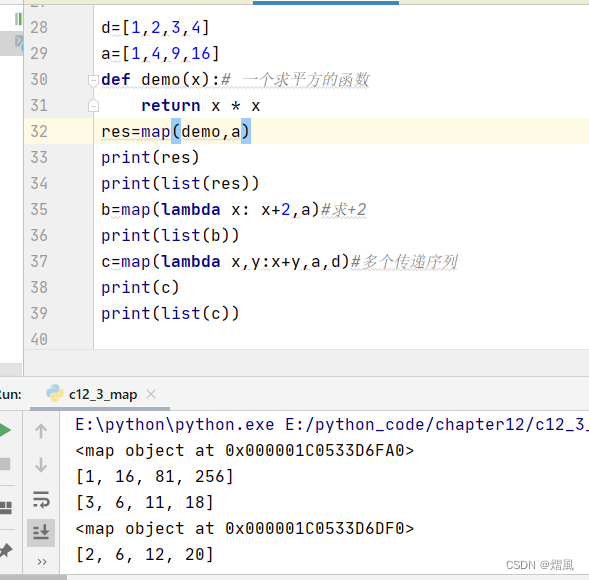
reduce:对列表元素求和
reduce()函数会对参数序列中元素进行累积。
语法:
reduce(function, iterable[, initializer])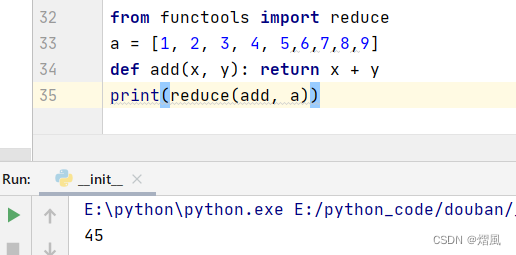
filter函数:过滤
filter()函数的简介和语法:
filter()函数用于过滤序列,过滤掉不符合条件的元素,返回符合条件的元素组成新列表。
filter()语法如下:
filter(function,iterable)
function -- 判断函数。
iterable -- 可迭代对象
迭代器(iterator)(迭代器协议):
可迭代对象有_next_()方法
iter()与可迭代对象等价
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()。
字符串,列表或元组对象都可用于创建迭代器:
Iterable和Iterator的区别
首先从字面意思来解释Iterable和Iterator的区别
Iterable:由英文的命名规则知道,后缀是able的意思就是可怎么样的,因此iterable就是可迭代的意思。
Iterator:由英文的命名规则知道,后缀是or或者er的都是指代名词,所以iterator的意思是迭代器。
这两个概念之间有一个包含与被包含的关系,如果一个对象是迭代器,那么这个对象肯定是可迭代的;但是反过来,如果一个对象是可迭代的,那么这个对象不一定是迭代器。
> from collections import Iterable
>>> isinstance( 'abc', Iterable) # str是否可迭代
True
>>> isinstance([ 1, 2, 3], Iterable) # list是否可迭代
True
>>> isinstance( 123, Iterable) # 整数是否可迭代
False
对于列表这种数据结构,里面的每一个元素我们都要在内存中为之开辟一个空间,不管你以后是否能用到它,如果要创建一个包含100万个元素的列表,但是只会用到其中几个元素,那么这样显然就很浪费内存,所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在python中这种一边循环一边计算的机制,称为生成器:generator。
要创建一个一个generator,有很多种方法,最简单的方法就是直接把一个列表生成器的[]改成()
>>> L = [x * x for x in range( 10)]
>>> L
[ 0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> g = (x * x for x in range( 10))
>>> g
<generator object <genexpr> at 0x1022ef630>
可以看到创建的列表是将所有的元素都输出出来,而
生成器只是生成一个对象,如果使用其中的元素,可以通过生成器的next来调用
>>> next(g)
0
>>> next(g)
1
>>> next(g)
4
>>> next(g)
9
>>> next(g)
16
>>> next(g)
25
凡是可作用于for循环的对象都是Iterable类型;
凡是可用作next()函数的对象都是Iterator类型,它表示一个惰性计算的序列。
集合数据类型如list,dict,str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
生成器:自己写的可以实现迭代器功能的东西
生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。

















 2302
2302




 到【灌水乐园】发言
到【灌水乐园】发言







