




一句话总结 beam search
从同一个 prompt 开始,把输入序列复制成多条 beam,第一步只允许一个 beam 扩展出全部候选 token 并选出 top-k 个作为初始分支;之后每一轮都对所有存活的 beam 进行前向计算,得到每个 beam 的下一个 token 分布,叠加历史分数后在所有候选中选出 top-k 保留,遇到 EOS 的序列交给 beam_scorer 收集,直到所有 beam 完成或达到最大长度,最后输出分数最高的若干完整序列。
记录LLM decoding的beam search 策略在transformers库中的实现
beam search 伪代码
为了搞清楚beam search在transformers库中的过程,把其中设计工程的部分删除了,留下了重要的部分写成伪代码的形式。
transformers\generation\utils.py
function BEAM_SEARCH_CORE(model, input_ids, num_beams, max_len,
logits_processor, stopping_criteria,
pad_id, eos_id, do_sample=False):
# 形状约定:
# input_ids: [B * nb, L],初始常由 [B, L] 扩展/重复到 [B*nb, L]
B = batch_size_from(input_ids, num_beams)
V = model.vocab_size
nb = num_beams
# 1) 初始化 beam 分数:首列 0,其他列 -INF
beam_scores = zeros([B, nb]); beam_scores[:, 1:] = -INF
beam_scores = beam_scores.view(B * nb) # [B*nb]
-------------------------
假设
batch_size (B) = 1
beam_size (nb) = 3
prompt 长度 (L) = 2
词表大小 (V) = 5
pad = 0, eos = 4
input_ids 是 [1, 10]
input_ids =
[
[1, 10], # beam 0
[1, 10], # beam 1
[1, 10], # beam 2
] # shape = [3, 2]
--------------------------
past = None
while not finished:
# 2) 前向,取最后一步 logits(仅自回归一步输出)
logits, past = model.forward(input_ids, past=past) # logits: [B*nb, L, V]
step_logits = logits[:, -1, :] # [B*nb, V]
--------------------------
模型给出每个 beam 的下一步 logits(这里举个假设概率):
next_token_probs (log_softmax 后):
beam 0: [0.05, 0.10, 0.70, 0.10, 0.05]
beam 1: ...
beam 2: ...
--------------------------
# 3) 转 log 概率 + 规则化(温度/禁词/重复惩罚等)
step_scores = log_softmax(step_logits) # [B*nb, V]
step_scores = logits_processor(input_ids, step_scores)# [B*nb, V]
# 4) 加上累计的 beam 分数(序列级)
step_scores = step_scores + beam_scores[:, None] # [B*nb, V]
# 5) reshape 成每个 batch 独立选择 (nb*V) 的全局前 K
step_scores = step_scores.view(B, nb * V) # [B, nb*V]
# 6) 选择候选(采样或确定性 top-k)
k = max(2, 1 + count_eos(eos_id)) * nb
if do_sample:
probs = softmax(step_scores) # [B, nb*V]
next_tokens = multinomial(probs, num_samples=k) # [B, k](索引范围 0..nb*V-1)
# 将抽到的候选按分数重排(降序)
cand_scores = gather(step_scores, next_tokens)
next_tokens = sort_by_desc(cand_scores, next_tokens)
next_scores = sort_desc(cand_scores)
else:
next_scores, next_tokens = topk(step_scores, k) # 都是 [B, k]
# 7) 还原:来源 beam 索引 + 词表索引
next_indices = floor_div(next_tokens, V) # [B, k] in [0..nb-1]
next_tokens = next_tokens % V # [B, k] in [0..V-1]
# 8) 交给 beam_scorer 进行“存活/完成/排序”裁决(核心)
# 返回:保留的 nb 个 beam 的新分数/新 token/来自哪个旧 beam
out = beam_scorer.process(
input_ids, next_scores, next_tokens, next_indices,
pad_token_id=pad_id, eos_token_id=eos_id)
beam_scores = out.next_beam_scores # [B*nb]
beam_next_tokens = out.next_beam_tokens # [B*nb]
beam_src_indices = out.next_beam_indices # [B*nb](全局索引 0..B*nb-1)
# 9) 重排并拼接 token;缓存也按相同索引重排
input_ids = concat( input_ids[beam_src_indices], beam_next_tokens[:, None] )
past = reorder_cache(past, beam_src_indices)
# 10) 停止判定(达到 max_len / beam_scorer 判定完成 / 其他条件)
if beam_scorer.is_done() or stopping_criteria(input_ids) or length(input_ids) >= max_len:
break
# 11) 收尾:整合已完成与在生的 beam,输出最终序列与分数
result = beam_scorer.finalize(
input_ids, beam_scores,
pad_token_id=pad_id, eos_token_id=eos_id, max_length=max_len)
return result.sequences, result.sequence_scores
注意
初始化 beam 分数
在 Hugging Face 的 _beam_search 里,第一次迭代时确实只有第一个 beam 会被真正展开,其他 beam 的分数一开始设为 −1e9(负无穷),保证它们不会被选中。这样做的目的就是避免一开始多个 beam 完全重复 prompt,导致前几个 token 都一样,浪费算力。
流程可以这么理解:
- 初始化
beam_scores = [0, -1e9, -1e9, ...]- 只有 beam 0 是合法候选,其余 beam 被“屏蔽”。
- 第一次扩展
- 从 beam 0 展开出
vocab_size个 token。 - 取 top-k(k ≥ num_beams),交给
beam_scorer。 - 这时候 beam_scorer 会选出
num_beams条路径,分配给 beam 0、beam 1、beam 2。 - 这样每个 beam 就都拿到了不同的前缀。
- 从 beam 0 展开出
- 后续步骤
- 从第二次迭代开始,所有 beam 的分数都是真实值了(不再是 −1e9),所以后续都会被同时展开。
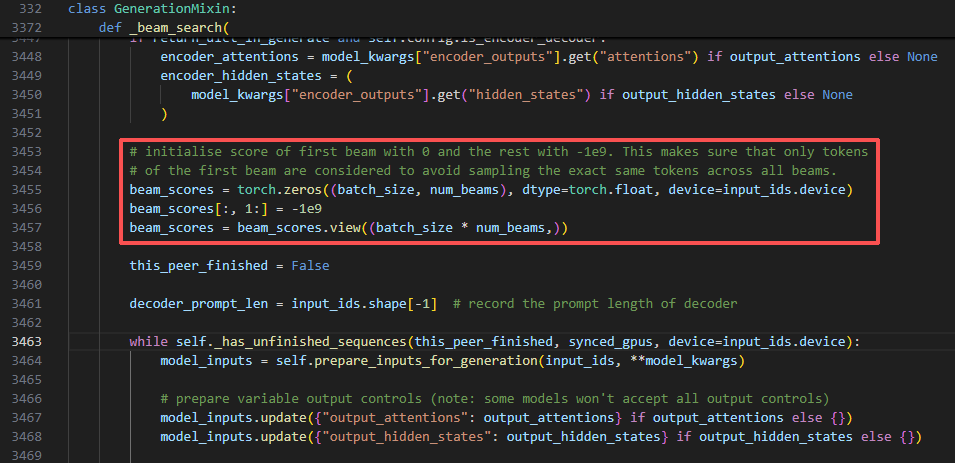
- 从第二次迭代开始,所有 beam 的分数都是真实值了(不再是 −1e9),所以后续都会被同时展开。
规则化(温度/禁词/重复惩罚等)
transformers\generation\utils.py
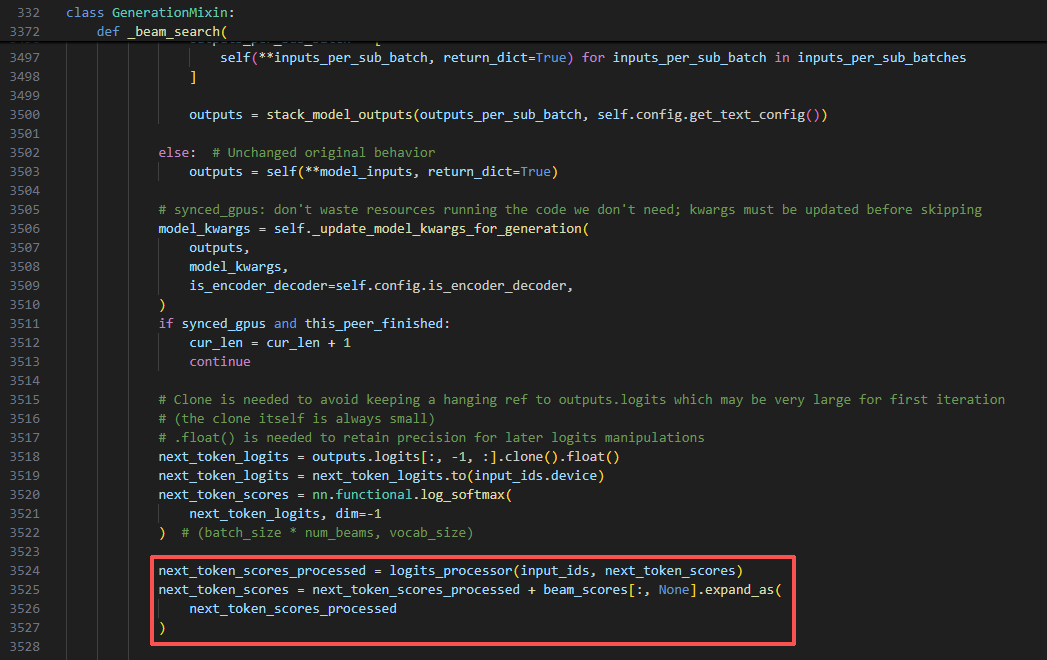
transformers\generation\logits_process.py
伪代码中3) 转 log 概率 + 规则化(温度/禁词/重复惩罚等)
在 transformers 库的 generate 方法中,LogitsProcessorList 被用来实现各种复杂的文本生成策略。例如:
- 控制重复:
RepetitionPenaltyLogitsProcessor会被加入列表,以降低已生成词元的分数。 - 采样策略:
TopKLogitsWarper、TopPLogitsWarper和TemperatureLogitsWarper会被加入列表,以实现 Top-K、Top-P (Nucleus) 和温度采样。 - 强制约束:
MinLengthLogitsProcessor会被加入,以禁止在生成文本达到最小长度前产生 EOS (end-of-sequence) 标记。
通过将这些不同的处理器组合在一个 LogitsProcessorList 中,transformers 库能够以一种模块化、可扩展的方式,灵活地控制文本生成过程。
采样 vs 确定性:
transformers\generation\utils.py
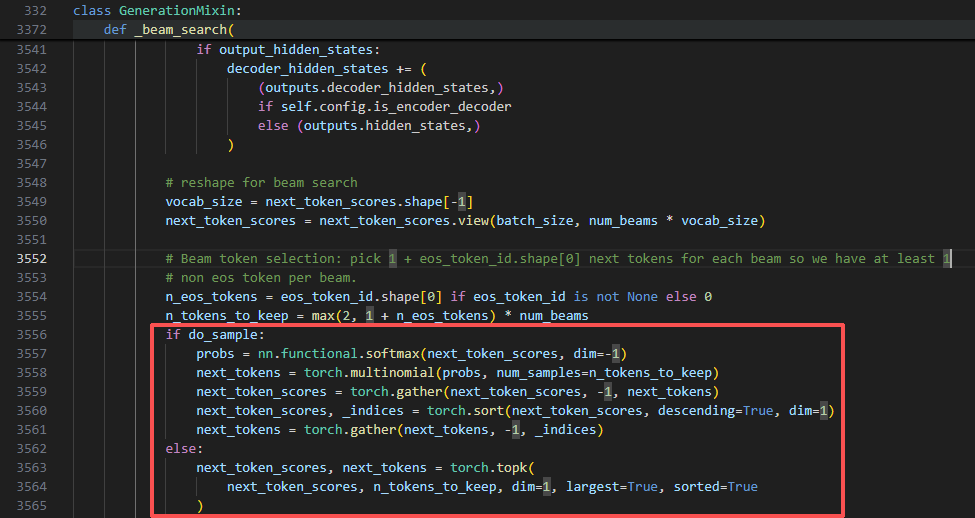
伪代码中 6) 选择候选(采样或确定性 top-k)
do_sample=True 时【采样解码】,它对 (batch, num_beams*vocab) 的分数做 softmax 后抽样 n_tokens_to_keep 个,再排序取前 B 个;【贪心解码】否则直接 topk。
Beam Search (束搜索) 算法的核心决策与状态更新阶段
可视化可参考 b站up”五道口纳什“:
【github】https://github.com/chunhuizhang/llm_rl/blob/main/tutorials/search-learn/llm_beam_search.ipynb
【[LLM+RL] model.generate 之 beam search decoding strategy】 https://www.bilibili.com/video/BV1SbrKYkETg/?share_source=copy_web&vd_source=ac07d48defe559c6322dff2c05c6eb10
伪代码中 8) 交给 beam_scorer 进行“存活/完成/排序”裁决(核心) 部分
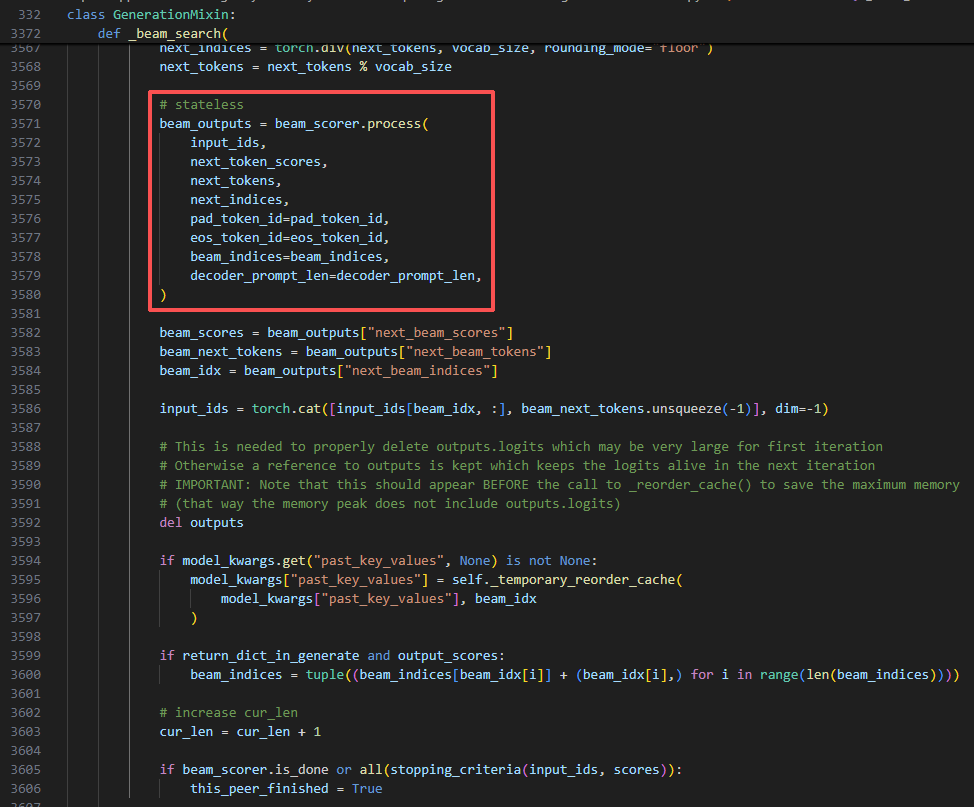
BeamScorer
transformers\generation\beam_search.py
- BeamSearchScorer
- ConstrainedBeamSearchScorer


















 230
230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









