




离散数学论文草稿
主题:用离散数学方法研究McCulloh-Pitts模型
McCulloh-Pitts模型
构建简单的思维模型函数,研究与有序n元组的关系。
在神经学家McCulloh和数学家Pitts在他们的合作论文中,提到了一种神经元模型即McCulloh-Pitts模型
麦卡洛克-皮特斯模型 [1] 简称MP模型一种神经元网络模型.它是在1943年,由美国心理学家麦卡洛克(McCulloch, W. S. )和数学家皮特斯((Puts , W.)等提出的利用神经元网络对信息进行处理的数学模型,从此人们开始了对神经元网络的研究.该模型的主要目的是完成对神经元状态的描述.通过对大脑的分析,人们发现,从信息处理的功能看,神经元由以下特点:1.多输入单输出.2.突触(传递神经冲动的地方)兼有兴奋和抑制两种性能.3.能时间加权和空间加权.4.可产生脉冲.5.脉冲进行传递6.非线性(有I}值).
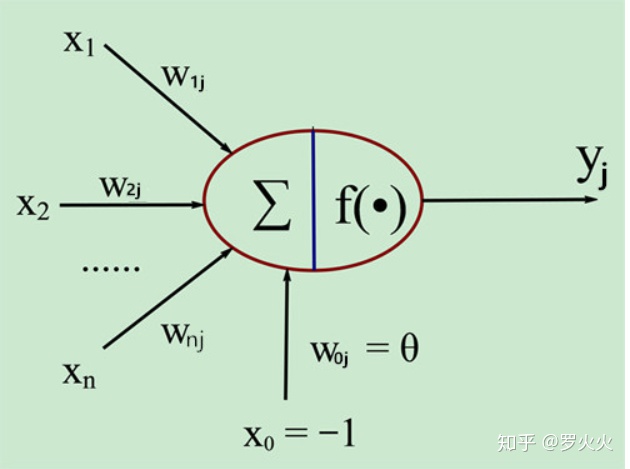
我们将外界刺激X0到Xn写作<X0X1X2X3…Xn-2>与将输出的神经脉冲Yj作为一个有序n元组,Ai=<<X0,X1,X2,X3…Xn-2>,Yj>,简记为<X0,X1,X2,X3…Xn-2,Yj>
该模型是对神经元一种相当简化的模仿,将<X0X1X2X3…Xn-2>通过树突进入神经元,再通过轴突输出结果Yj,它们分别对应着函数中的自变量和因变量。
而每一个因变量都对应一个参数Wi,因此Wi也可以写做一个有序组<W0W1W2W3…Wn-2>,控制着不同输入对输出的影响,于此同时还有一个神经元的激活阈值θ,因此参数也可以写作一个有序对,A0=<<W0W1W2W3…Wn-2>,θ>。
此时我们将参数列表<<W0W1W2W3…Wn-2>,θ>储存在A0中,Ai(i > 0,i ∈ Z)符合以下公式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YQsgafZ6-1639273241051)(https://www.zhihu.com/equation?tex=y%3Df%EF%BC%88%5Csum_%7B1%7D%5E%7Bn%7D%7Bw_%7Bi%7Dx_%7Bi%7D-%5Ctheta%7D%EF%BC%89)]
为了方便研究,我们将外界的刺激简化到一个,将神经元简化为一个一元函数 Yn = f ( WnXn - θ ) ,再进行一个简单的变化,就会变成即McCulloh-Pitts模型选用的公式——**y=f(wx+b)**其中b为偏置项,w为感知机输入层到输出层连接的权重。
此时我们可以将一个神经元对外界的刺激做出的不同反应记录成为一个序偶集合。
y=f(wx+b),我们先不处理阶跃函数f( )和偏置项b,将公式简化为y = wx 。
假设有一种只有两个个神经元的生物,该生物需要根据外界的温度x来判断自己的存活率y(两者符合一元一次函数y = wx),并且根据存活率y判断自己是否需要迁徙z(两者也符合一元一次函数z = wy)。
我们要模拟该生物,就需要知道两个函数的参数w的数值。我们先研究第一个函数y = wx,我们假设w为2,于是在温度为20℃时计算得存活率为40%,可是实际上该生物的存活率低于20%,由于误判我们模拟的生物死亡了,因此我们需要调节w使得我们模拟的生物接近真实生物。
Rosenblatt感知器
人类作为一种智能生物,我们知道需要将w降低,但是机器如何知道呢?
于是在1958年,Rosenblatt提出了一种感知器模型,使得神经元有调整自己权重参数w的能力。
例如当偏置项为0时,存在一个正确的序偶<x,y0>,而我们初步猜测的结果是<x,y1>(y0>y1),即我们预测的参数w0过低。
所以我们令下一次的参数为va为系数,用于调整w改变的幅度,例如0.05,这就意味着我们每次修正的幅度降低20倍。
根据奥卡姆的剃刀原理,如果不加上此参数,会导致模型纠错震荡幅度过大,无法得出正确序偶对<w,b>,当a缩小时,震荡幅度会逐渐趋于合理,但是如果过小,又会导致参数调整过慢,降低机器学习效率。
目前这种古老的模型已经很少使用,目前使用较多的是梯度下降和反向传播。
方差代价函数
Rosenblatt感知器的参数修正函数是wn+1=wn+ax(y0-yn),但是为什么要使用这个函数修正呢?要解决这个问题,我们就要先理解如何评估误差。
说到评估误差,我么第一反应就是差值——预测值和标准答案的差值。
但是这样是不对的假设我么进行两次预估,第一次的误差是0.3第二次是-0.3,综合两者误差就成为了0,这意味着我们把误差看作差值会导致但当误差恰好可以抵消的时候,会被计算机误判为预估正确
所以我们需要引进新的误差估计法,对于这种情况我们会首先想到加绝对值,利用绝对值处理误差在数学上叫做绝对差,但是绝对差在数学处理和计算机编码上并不是很方便,于是人们选用了一种更好的误差处理办法——平方误差,将插值取一个平方,正负号就消失了。不难发现y=wx+b的平方误差和每次选用的w成二次函数关系,是一个开口向上的一元二次函数——e=x2w2-2xyw+y2
对一组平方误差取平均值,我们称之为e均方误差,机器要做的就是找出这个二次函数的最低点,即找出e最小的时候的w。
梯度下降和反向传播
根据上面的公式可以判断出此时的最低点的w是和正规方程矩阵退化为单个函数时的结论是一样的。这种方法在处理少量数据的时候是合适的,但数据量变大时,就不再合适了,因为这种一次结合所有数据计算出结论的方式,计算量太过庞大。并且在一般情况下,x不会是单个的数值,而是拥有多个维度的向量,这就导致计算量更加庞大。
因此我们要采用梯度下降法

















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









