




Task02:链表
1. 视频题目
1.1 移除链表元素
1.1.1 描述
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1:
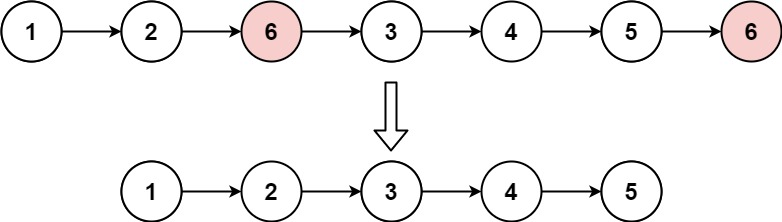
输入:head = [1,2,6,3,4,5,6], val = 6
输出:[1,2,3,4,5]
示例 2:
输入:head = [], val = 1
输出:[]
示例 3:
输入:head = [7,7,7,7], val = 7
输出:[]
提示:
列表中的节点数目在范围 [0, 104] 内
1 <= Node.val <= 50
0 <= val <= 50
1.1.2 代码
给定的链表其实是一个不含头结点的链表,因为其第一个结点的值是有意义的
所以为了方便操作,我们在这里重新定义一个头结点,其数值为空
这个新的头节点主要是为了方便判断原头结点是否需要去除
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def removeElements(self, head: ListNode, val: int) -> ListNode:
new_head = ListNode()
new_head.next = head
prev = new_head
while prev.next :
if prev.next.val == val:
prev.next = prev.next.next
else:
prev = prev.next
return new_head.next
1.1.3 总结
我们新建了一个头结点,除了方便判断原头结点之外
还定下了循环的判别条件,即prev.next,方便找到元素后对其进行去除
所以如果要去除元素,一般都是使用.next.val进行判断
这样找到val之后,直接跳过该元素,即.next = .next.next
1.2 旋转链表
1.2.1 描述
给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置。
示例 1:
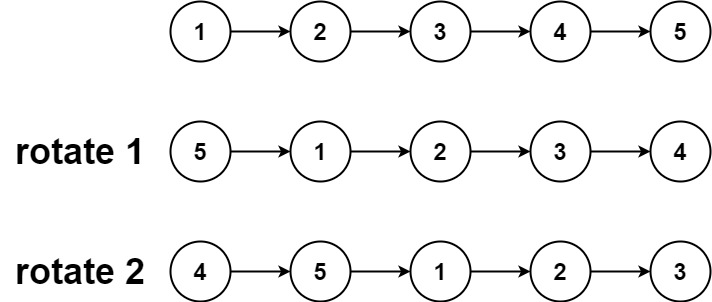
输入:head = [1,2,3,4,5], k = 2
输出:[4,5,1,2,3]
示例 2:
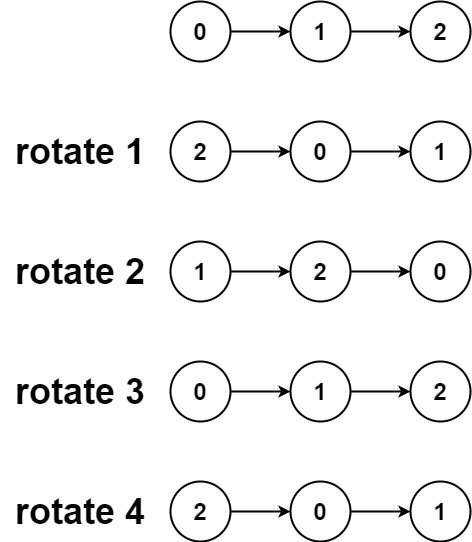
输入:head = [0,1,2], k = 4
输出:[2,0,1]
提示:
链表中节点的数目在范围 [0, 500] 内
-100 <= Node.val <= 100
0 <= k <= 2 * 109
1.2.2 代码
旋转链表,也就是说需要先将链表首尾相连成环,然后在新的尾结点处断开
由于每个结点是向右移k个位置,所以说从末尾往前走k步所到达的元素就是新的尾结点
但是链表是单向的,所以我们要从头结点开始数,也就是从新的头结点走length-k步所到达的结点
这里有一个细节,假设链表长度为length,那么首尾结点之间有length-1个间隔,也就是步长
所以假如从原链表的头结点开始,其需要移动(length-1) - k个步长
其中,length-1是首尾的间隔,k是新的尾结点与旧尾结点的步长,也就是向右移动k个位置
因为我们为了方便操作而新设置了空的头结点,步长+1,所以说需要向右移动length-k个步长
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def rotateRight(self, head, k):
dummy = ListNode(0)
# 新建一个头结点方便操作
dummy.next = head
# 连接原链表的头结点
if head is None:
return None
# 链表为空的话就直接返回了
i = head
# 从原链表的头结点开始
length = 1
# 开始计数
while i.next is not None:
i = i.next
length += 1
# 遍历访问,拿到间隔长度和尾结点
k = k%length
# 链表成环,有可能右移超过一圈
if (k == 0) or length == 1:
return head
# 如果刚好右移length位,那就是不变
# 或者是链表只有一个元素,那也是不变
i.next = head
# 首尾相连,链表成环
i = dummy
for _ in range(length - k):
i = i.next
# 从新建的空的头节点开始
# 向右移动length-k步
# 寻找新的尾结点的位置
j = i.next
# 新的头结点
i.next = None
# 新的尾结点
return j
# 返回头结点
1.2.3 总结
首先是特殊情况的判断,一个是移动的步长恰好等于链表的间隔长度
那就是刚好绕了一圈,又回到原来的位置,也就是没有发生变化
还有一个是只有一个元素,那无论怎么移动都还是在原地没有变化
然后是成环之后,要注意取余,即处理移动超过一圈的情况
最后是要主要间隔的长度与链表的长度是不同的,两者相差1位
2. 作业题目
2.1 合并两个有序链表
2.1.1 描述
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
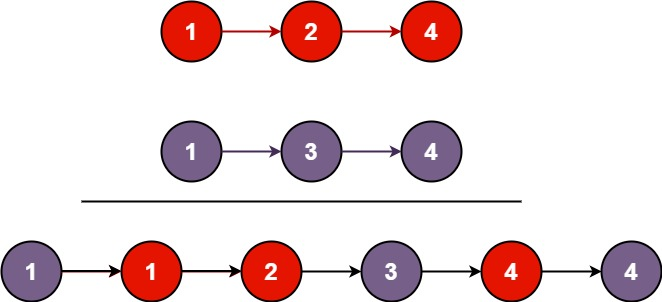
输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
示例 2:
输入:l1 = [], l2 = []
输出:[]
示例 3:
输入:l1 = [], l2 = [0]
输出:[0]
提示:
两个链表的节点数目范围是 [0, 50]
-100 <= Node.val <= 100
l1 和 l2 均按 非递减顺序 排列
2.1.2 代码
最直观的思路就是依次比较两个旧链表的头结点,然后将小的加入新链表
需要注意的是两个旧链表为空,或者两个旧链表头结点是值相等的情况
所以我们在这两种情况都直接使用了else来进行判别
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:
head = ListNode(0)
temp = head
while l1 and l2:
if l1.val < l2.val :
temp.next = l1
l1 = l1.next
temp = temp.next
else:
temp.next = l2
l2 = l2.next
temp = temp.next
if l1:
temp.next = l1
else:
temp.next = l2
return head.next
还有一个递归的解法,运行时间甚至更长,而且思路似乎并不直观
但是如果我们从递归的角度去思考,发现这样看起来或许更直观
好像有那么一点动态规划的意思,叠加最优子解法,达到最优解
其只比较当前值的大小,默认后面的值都是已经排好序的最优子结构
然后递归调用自身来确保后面的值都是已经排好序的
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:
if l1 is None:
return l2
elif l2 is None:
return l1
elif l1.val < l2.val:
l1.next = self.mergeTwoLists(l1.next, l2)
return l1
else:
l2.next = self.mergeTwoLists(l1, l2.next)
return l2
2.1.3 总结
如果对于数值相等的情况,两种操作的处理办法都可以,那适合使用else,直接归入else类别
2.2 相交链表
2.2.1 描述
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交:
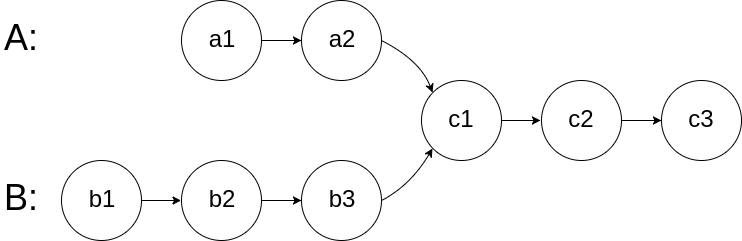
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
自定义评测:
评测系统 的输入如下(你设计的程序 不适用 此输入):
intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0
listA - 第一个链表
listB - 第二个链表
skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数
skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。
示例 1:
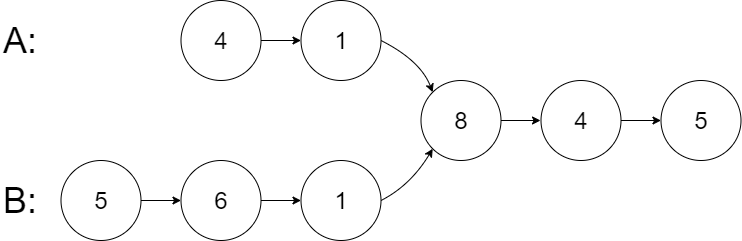
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at ‘8’
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:
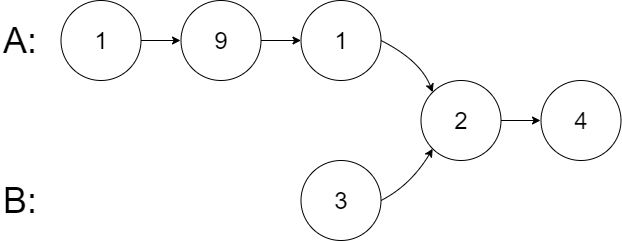
输入:intersectVal = 2, listA = [1,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Intersected at ‘2’
解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [1,9,1,2,4],链表 B 为 [3,2,4]。
在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
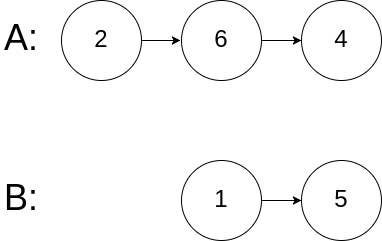
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。
由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
这两个链表不相交,因此返回 null 。
提示:
listA 中节点数目为 m
listB 中节点数目为 n
1 <= m, n <= 3 * 104
1 <= Node.val <= 105
0 <= skipA <= m
0 <= skipB <= n
如果 listA 和 listB 没有交点,intersectVal 为 0
如果 listA 和 listB 有交点,intersectVal==listA[skipA]==listB[skipB]
进阶:你能否设计一个时间复杂度 O(m + n) 、仅用 O(1) 内存的解决方案?
2.2.2 代码
最简单直观的方法就是打表,先对其中一个链表建一个哈希表
然后遍历另一个链表,遇到相同的就跳出返回该相交的结点
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution(object):
def getIntersectionNode(self, headA, headB):
d = dict()
while headA:
d[headA] = 1
headA = headA.next
while headB:
if headB in d:
return headB
headB = headB.next
return None
还有一个双指针的解法,思路也比较神奇和巧妙
我感觉就是对于指针a,就是让他跑在链表B自成的环里面,指针b则相反
入环后,两个指针的移动速度一样,但是两个链表的长度不一样,所以相遇
如果两个链表长度一样,那就不用入环,直接在相交结点相遇
但是如果指针a和b各自跑在A和B各自的环里面,那就会出问题
要么是两个链表不相交的死循环,要么是跑的太久超时
或许这么说不够直观,我们可以将两个链表拉平,固定指针,移动链表
那我们就可以发现,当a,b跑完各自的链表进入对方的环,只需再跑相交前的长度即可
假设A在相交前的长度为
α
\alpha
α,B在相交前的长度为
β
\beta
β,相交后的长度为
θ
\theta
θ
将链表铺平后,指针a跑了
α
+
θ
+
β
\alpha+\theta+\beta
α+θ+β,b跑了
β
+
θ
+
α
\beta+\theta+\alpha
β+θ+α,两者相遇
如果两者不相交,设A的长度为
α
\alpha
α,B的长度为
β
\beta
β,则相遇时为None
其中a跑了
α
+
β
\alpha+\beta
α+β,而b跑了
β
+
α
\beta+\alpha
β+α,长度一致在末尾处相遇
以上思路来自博客1,详见其中的解释和配图
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution(object):
def getIntersectionNode(self, headA, headB):
pA = headA
pB = headB
while pA != pB :
pA = pA.next if pA else headB
pB = pB.next if pB else headA
return pA
2.2.3 总结
如果只要求通过题目的话,那当然是打表万岁
以固定链表移动指针的视角,要使用双指针,那两者要有差值,否则无法相遇
本题巧妙的地方就在两个链表长度一致时,指针会在入环前相遇
而且如果题目本身没有环的话,我们可以构造环来使用双指针
而且成环时我们可以换一个视角,即拉平链表后相连,固定指针移动链表
2.3 删除排序链表中的重复元素 II
2.3.1 描述
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:
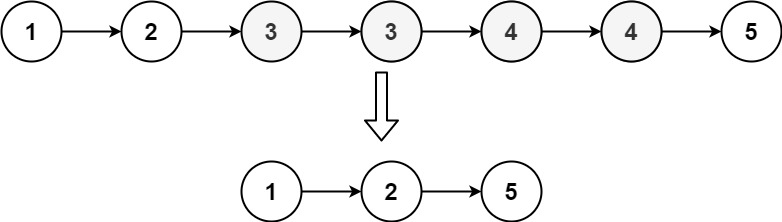
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
示例 2:
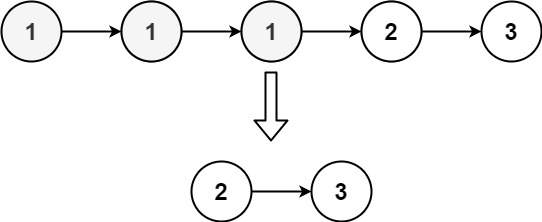
输入:head = [1,1,1,2,3]
输出:[2,3]
提示:
链表中节点数目在范围 [0, 300] 内
-100 <= Node.val <= 100
题目数据保证链表已经按升序 排列
2.3.2 代码
完全抹除重复的元素,所以需要记录重复序列的前一个元素
并将其连接到重复序列后的第一个元素,所以是双指针
一个指针负责记录重复序列的前一个元素
另一个负责找到重复序列后的第一个元素
这里使用next将其简化成为了一个指针
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def deleteDuplicates(self, head: ListNode) -> ListNode:
if not head:
return head
dummy = ListNode(0, head)
# 新建头结点,确保从头结点开始去重
cur = dummy
while cur.next and cur.next.next:
# 循环到列表的末尾
if cur.next.val == cur.next.next.val:
# 一旦发现有存在重复的数值
x = cur.next.val
# 拿到这个重复的数值
while cur.next and cur.next.val == x:
# 凡是等于这个数值的都抹除
cur.next = cur.next.next
else:
cur = cur.next
# 移动到下一个结点
return dummy.next
2.3.3 总结
我最开始的想法是设置fast和slow两个指针,后来发现可以合并成为一个
然后就是对于重复的数字,这是一个序列,所以要用循环去消除

















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









