



性能测试4与性能测试3最后的
三、性能瓶颈分析和性能调优
(1)基准测试
(2)负载测试
(3)压力测试
(4)浪涌测试
(5)容量测试
有关,需要结合看
性能瓶颈分析和性能调优
(1)基准测试
一般是单接口(单交易):使用一个用持续压测1min以上。
目的:获取单个接口没有压力的情况下各项性能指标,作为他场景的参考依据。
核心性能指标:并发用户数,响应时间(<1.5s),吞吐量(TPS、QPS、RPS),资源利用率(<80%),事务错误率(<0.1%)
(2)负载测试【一般在10分钟左右】
单交易负载测试:单个接口
多交易负载测试:多个接口、流程接口(流程负载测试、混合负载测试)
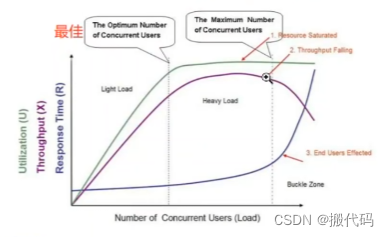
为什么做负载:就是为了得到下面两个指标
最佳并发用户数:资源利用率最高
最大并大用户数:并发用户数的上限,一旦超过上限,那么相应时间用户无法容忍5s,TPS直线下降
(3)压力测试【一般一小时为单位,如8、10、12、24h,有最长的压一个星期】
破坏性压力测试:(极限测试):最大并发用户数,可能会伴随客回复性测试(单机、集群)
稳定性压力测试:最佳并发用户数
(4)浪涌测试
(5)容量测试
第一种:TPS容量
如:测试被测系统是否能够每秒处理1000个事务
第二种:并发用户数容量
如:测试被测系统某一个功能是否能够支持1000个并发
第三种:在线用户数
如:测试被测系统能否支持10000个用户使用。(压力不大)
思考时间:吞吐量控制器
上面3中场景我们应该怎么去做,用例怎么去设计?
二、实战
常规的场景线程组就够了
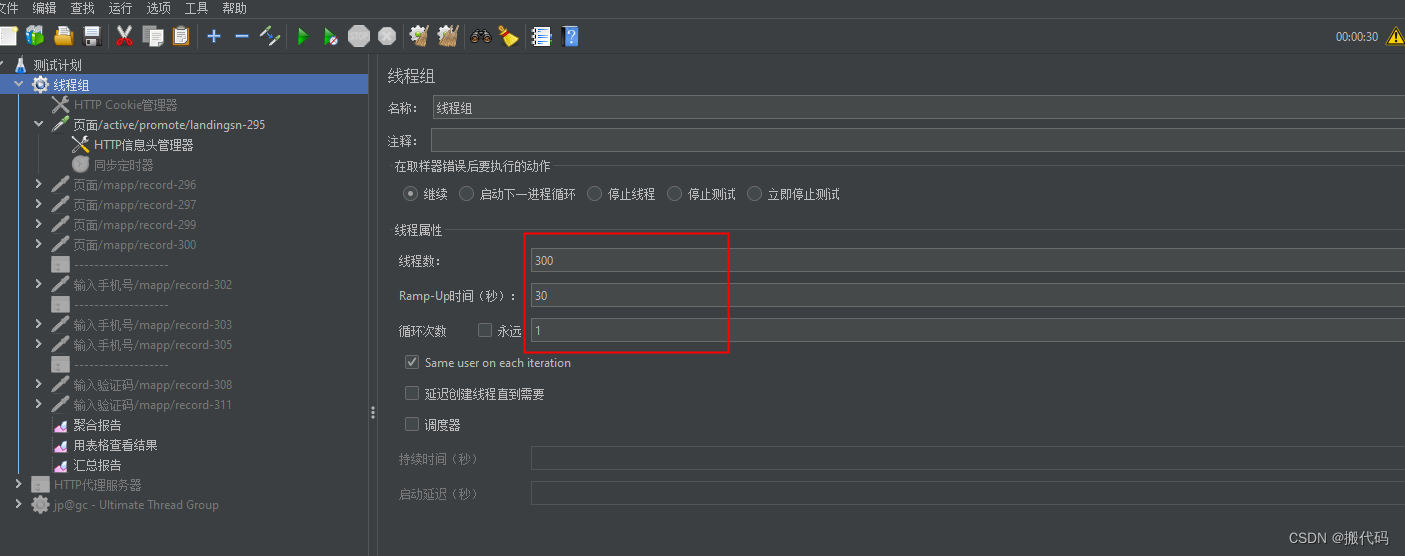
线程组
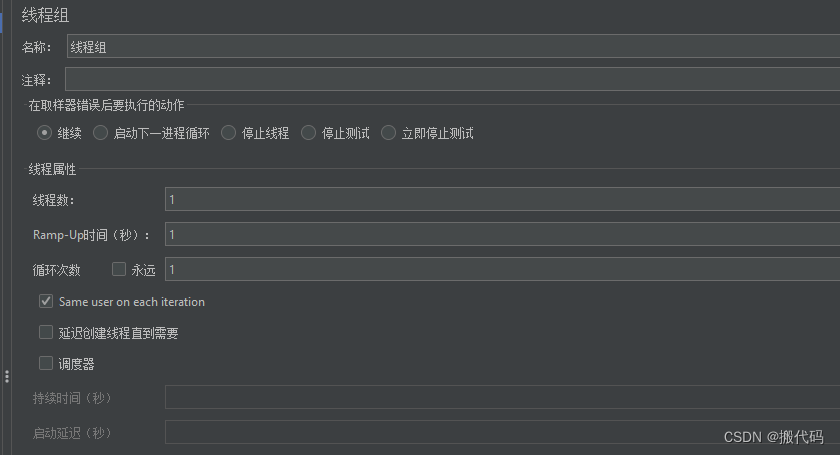
线程数:虚拟用户数:100
Ramp-UP时间:10 10s加载100个用户,平均每秒加载10个
循环次数: 1 永久:一直跑
调度器:
持续时间:10 如果超过这个时间还在一直跑,那么请使用CLI模式,也就是命令行模式
【持续时间优先级大于循环次数】
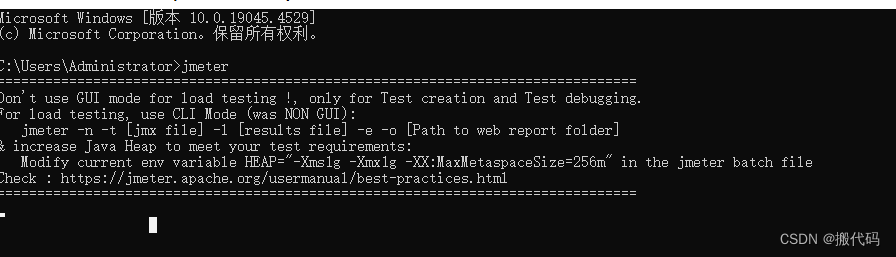

不要使用GUI模式进行负载测试!,仅用于测试创建和测试调试。
对于负载测试,请使用CLI模式(以前是NON GUI):
jmeter-n-t[jmx文件]-l[结果文件]-e-o[web报表文件夹的路径]
&增加Java堆以满足您的测试要求:
修改jmeter批处理文件中的当前环境变量HEAP=“-Xms1g-Xmx1g-XX:MaxMetaspaceSize=256m”
检查https://jmeter.apache.org/usermanual/best-practices.html
命令行:jmeter-n-t[jmx文件]-l[结果文件]-e-o[web报表文件夹的路径]
谁占的资源最多
场景一:
线程数10,Ramp-UP:1,循环次数:2, 每次占用10个资源内存, 1
线程数20,Ramp-UP:1,循环次数:1, 每次占用20个资源内存, 2 占的最多
场景二:
线程数:1,Ramp-UP:1 循环次数:永久。持续时间:10s
问题:请问这里请求了多少次? 这里的请求和设置没有直接关系
以上两个场景对应结论:
1.要吗就是固定循环次数,这个时候你设置持续时间没有意义
2.要吗就是循环次数设置为永久,然后固定持续时间
实战一:(秒杀场景知识没有这么多线程数,只有并发数)
| 场景9 | 总和业务,从投产到入库 | 50~100个用户并发数5的情况,持续运行1个消失 | 持续运行,观察通过的事务和响应时间 |
依据上述场景,要求并发数=5,我们看一下下面做法是否正确:
线程数:50~100,Ramp-UP:1,循环次数:永久,持续时间:30s
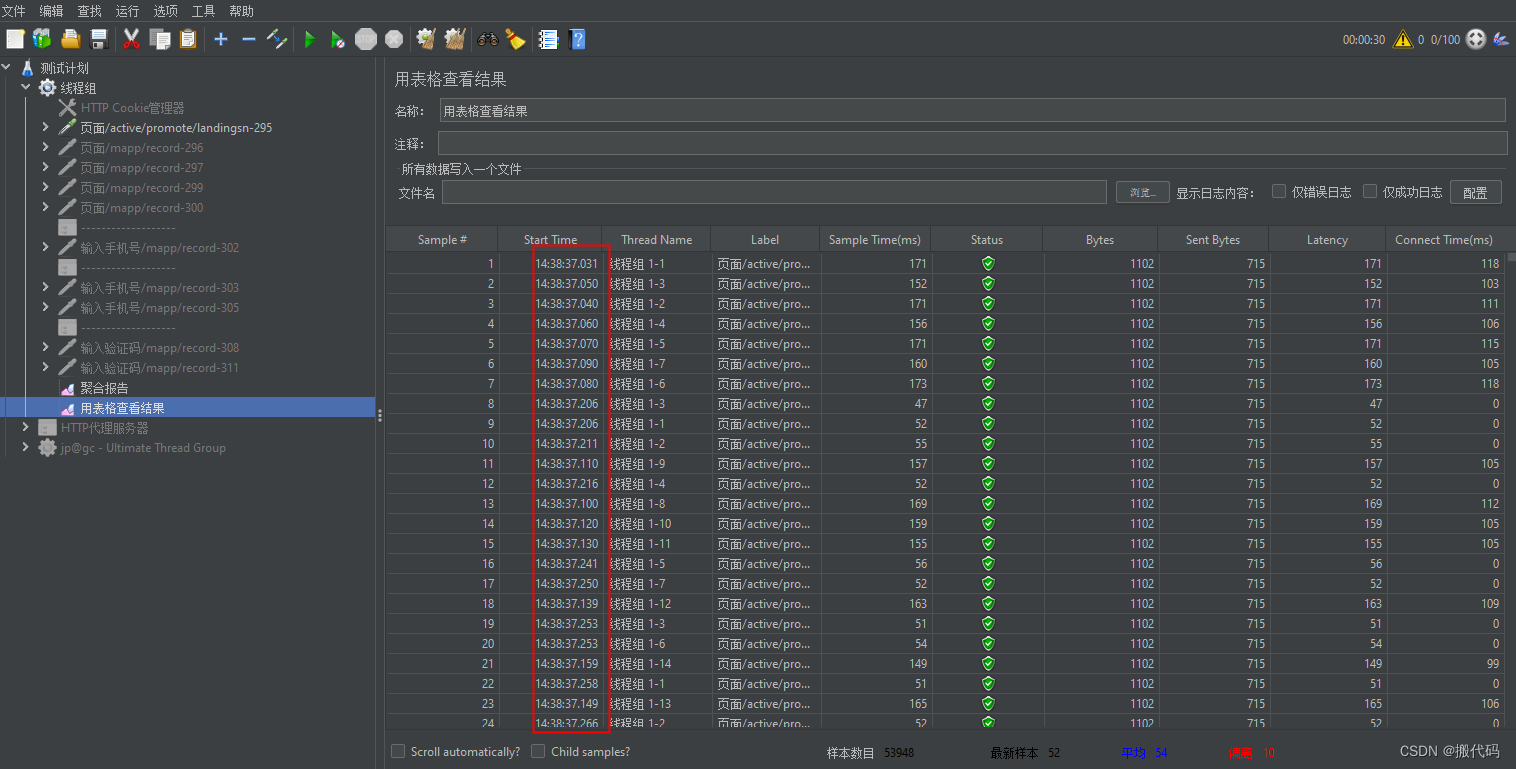
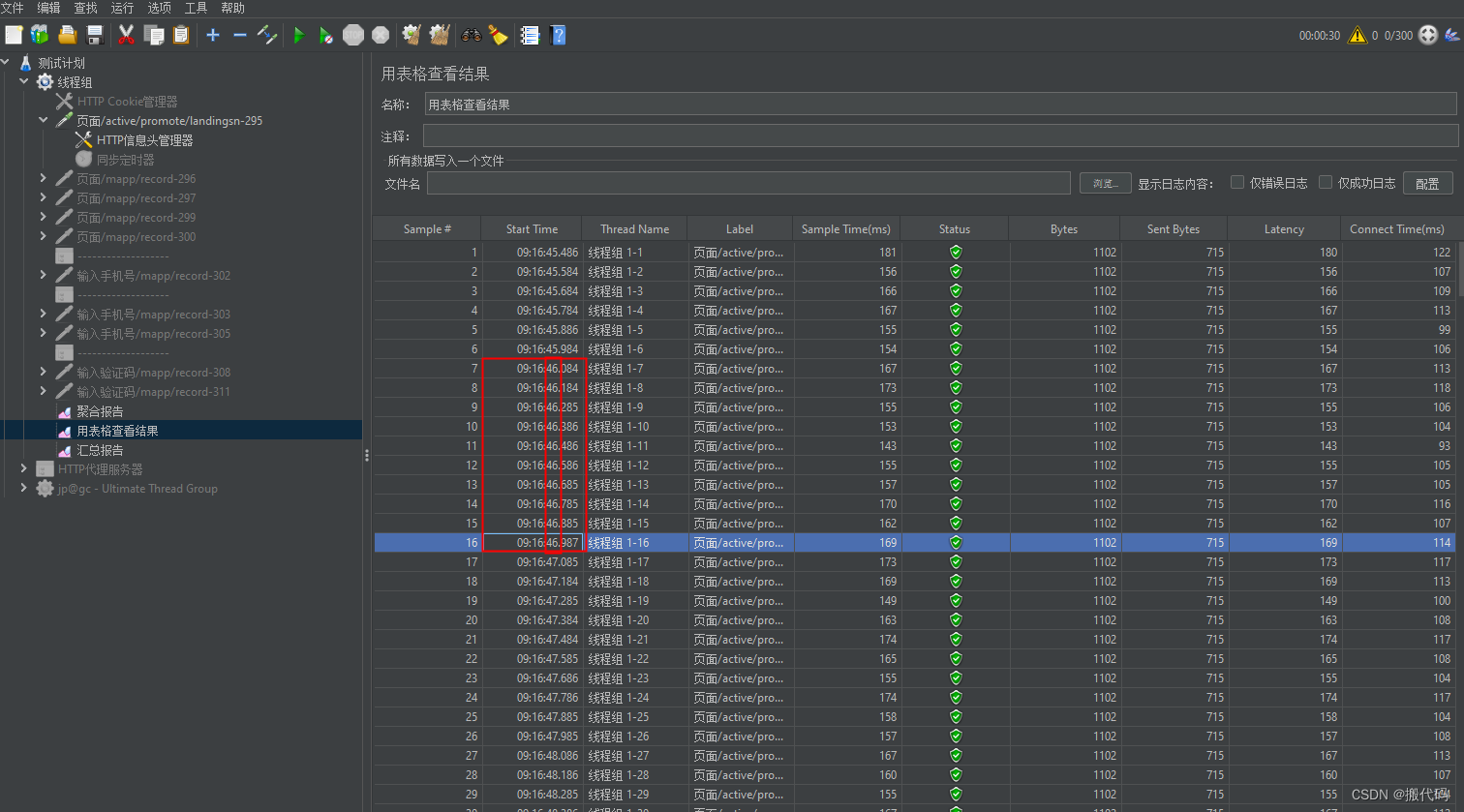
从上图可以看到start Time没有同一时间发送5个请求所以是不对的。
如果想让同时并发,那么就要添加一个同步定时器如图所示:
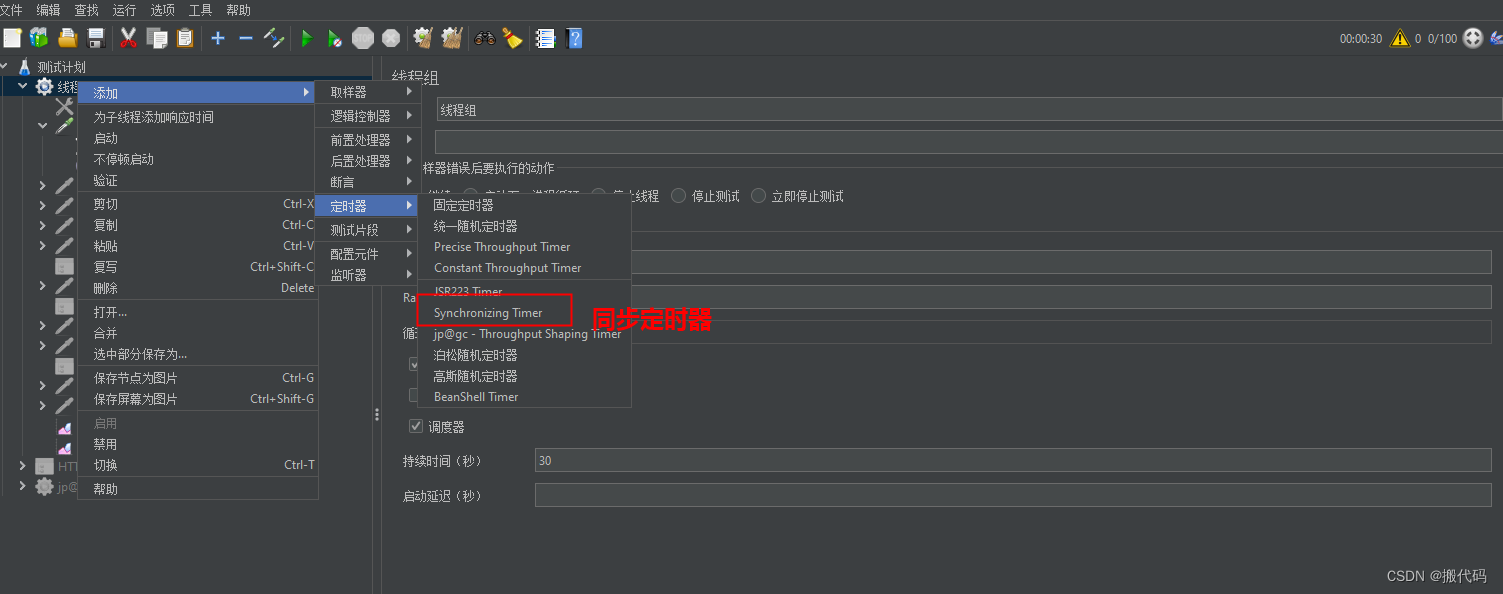
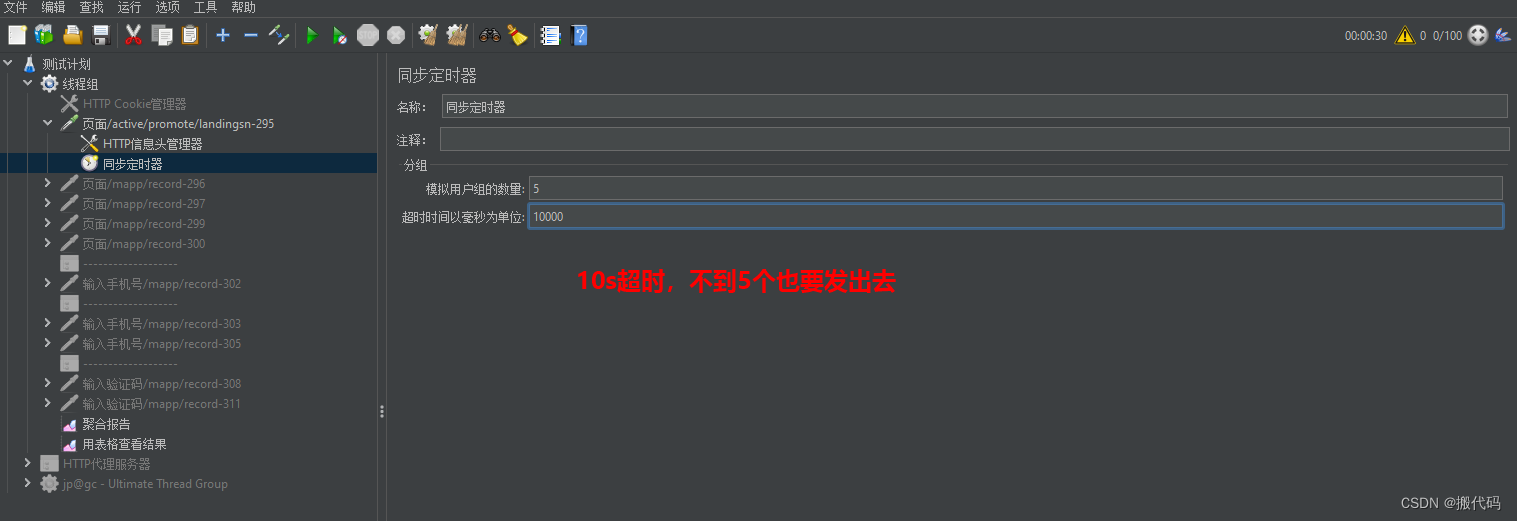
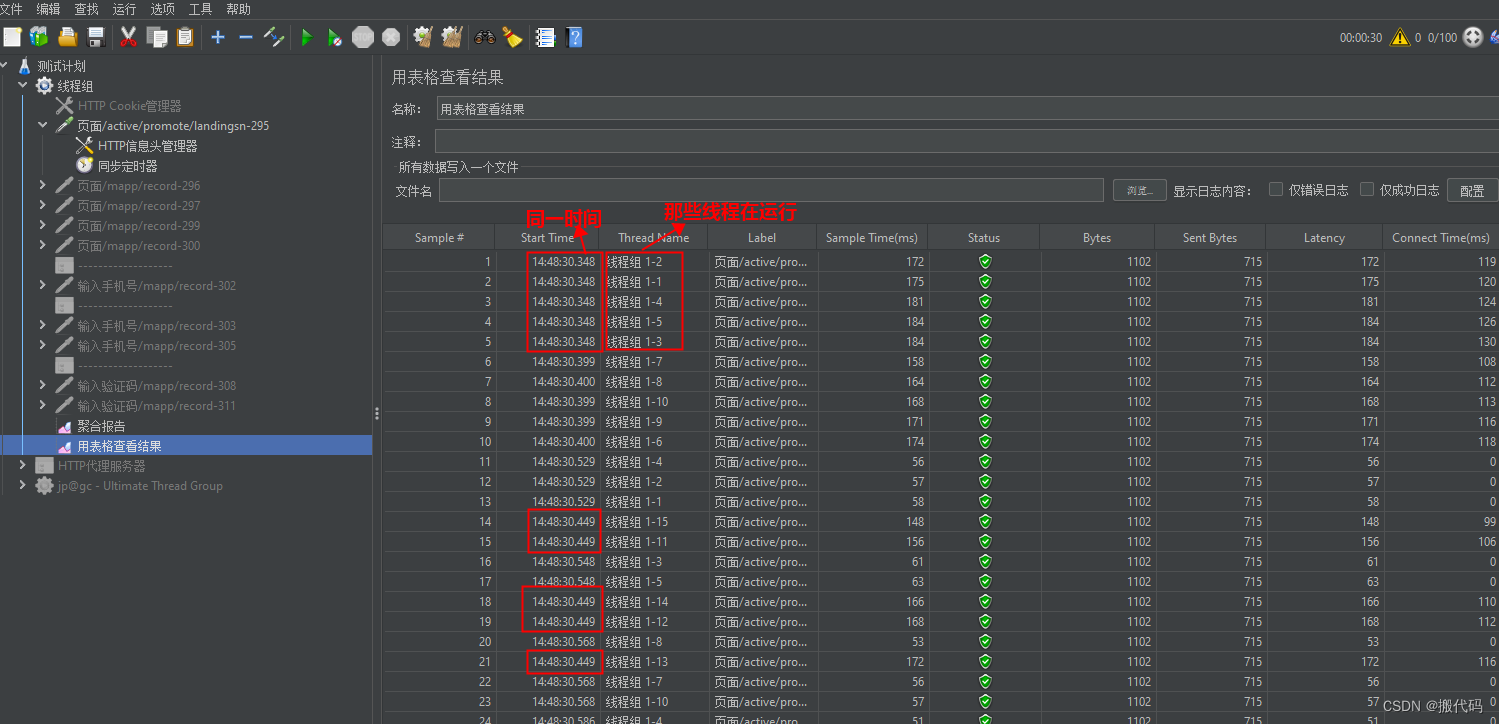
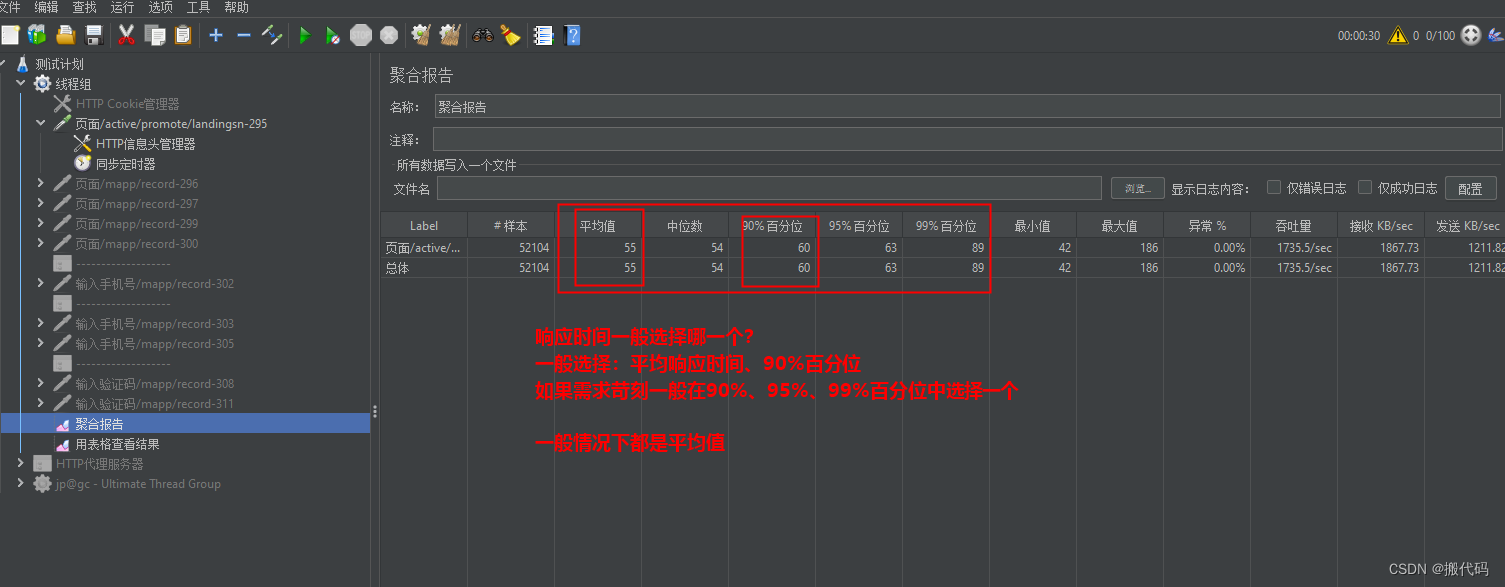
聚合报告:
标准差主要是看:平均值和90%百分位之间的差由上图可以看出标准差还是很大的
吞吐量:就是TPS;算法:总样本数/总时间=吞吐量;52104/30=1,736.8。与吞吐量很相似
接收KB/Sec、发送KB/Sec其实就是吞吐率
如何看响应时间稳不稳定?
看标准差:在汇总报告中的标准误差
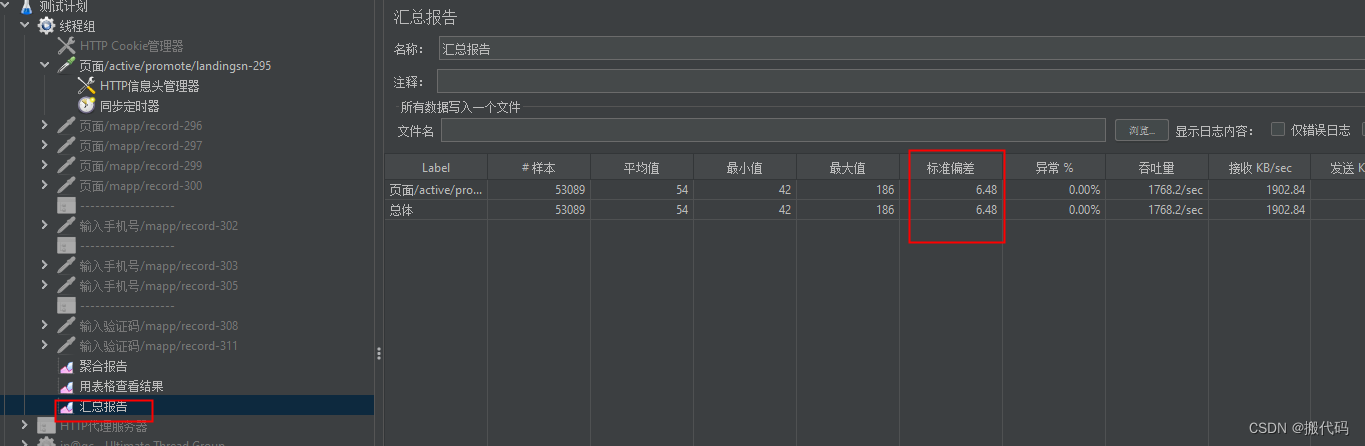
使用同步定时器其实是不对的,因为实际操作中,我们的线程是实时都会来的。并不是等待5个人齐了才发起的。
实战二:
以TPS(每秒完成的事务数)为10的压力持续压测30s?
实战三:
测试被测系统是否能够每秒处理1000个事务,TPS=1000
方案一:负载测试
以1000个线程为基点,以100、200、300、400...1000,1100...个线程往上压,逐步递增,然后看TPS的性能拐点,有没有超过1000
方案二:直接使用到达线程组(面向目标的场景)
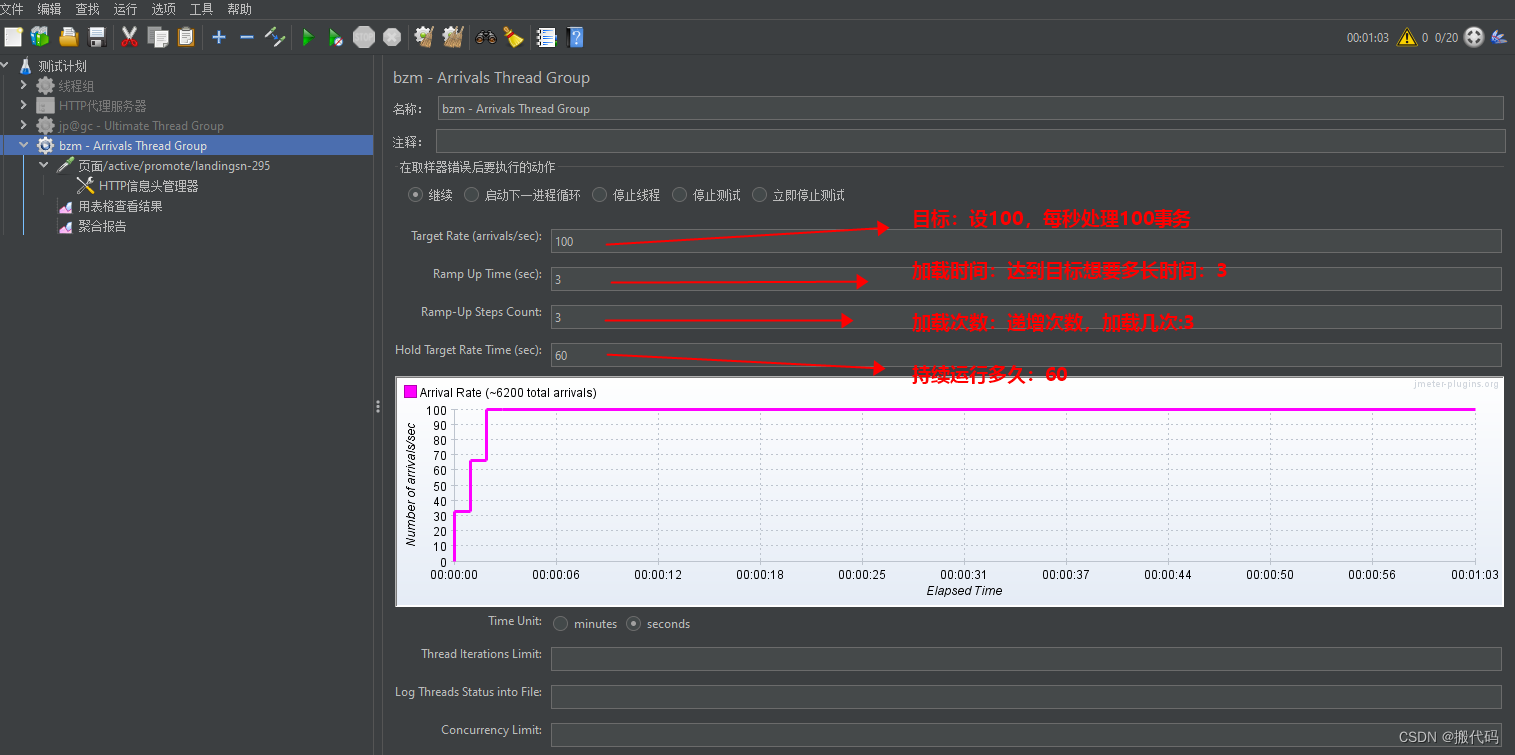
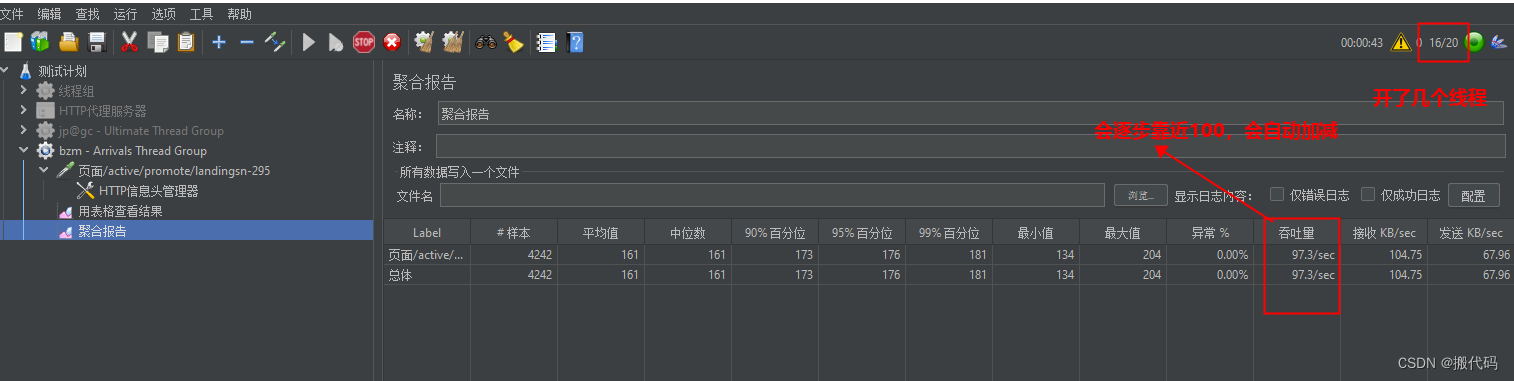
bzm - Arrivals Thread Group到达线程组:是基于TPS为目标的线程组
TPS目标:设100,每秒处理100事务
加载时间:达到目标想要多长时间:3
加载次数:递增次数,加载几次:3
持续运行多久:60
如:测试被测系统某一个功能是否能够支持1000个并发
方案一:1000宪曾+同步定时器 得到核心的五个性能指标((1)基准测试中五个)
方案二:
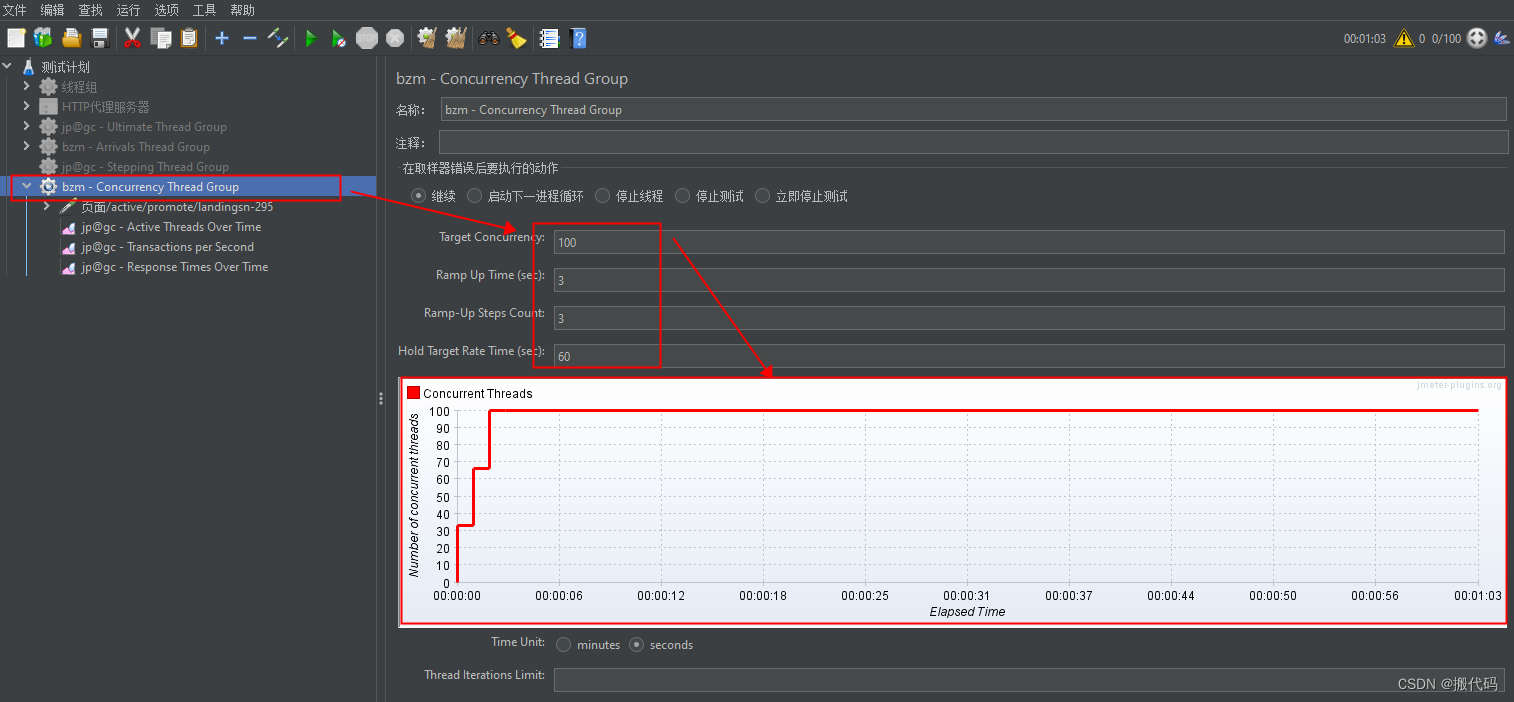
bzm - Arrivals Thread Group到达线程组:的目标是TPS目标
bzm - Concurrency Thread Groupbzm-并发线程组:的目标是并发数目标
两种页面及其相似,但是目标不一样。
具体表现在聚合报告中,右上方的启用的线程多少不一样,TPS吞吐量不一样。
方案二使用的是并发线程组:一般使用一下3个监听器
jp@gc - Active Threads Over Time jp@gc-随时间推移的活动线程
jp@gc - Transactions per Second jp@gc-每秒事务数
jp@gc - Response Times Over Time jp@gc-随时间推移的响应时间
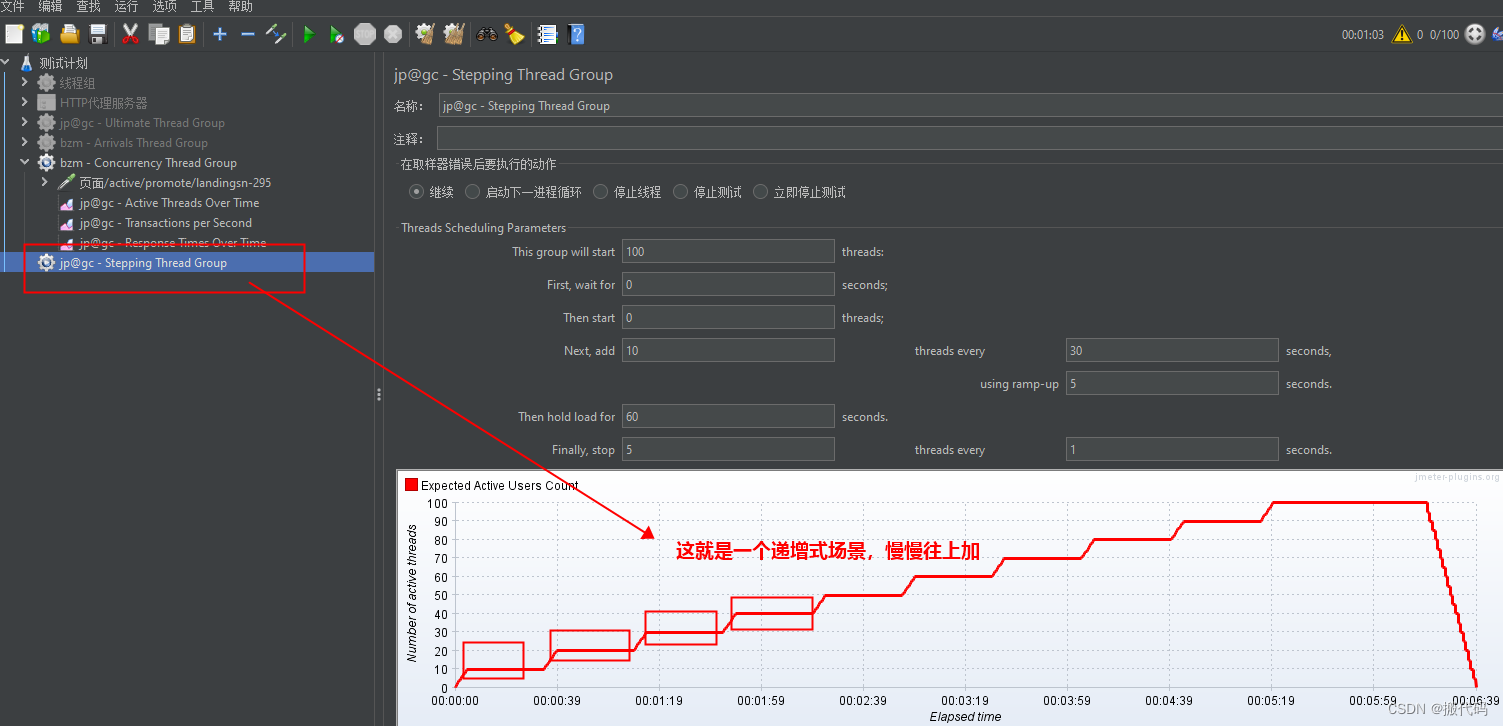
实战四:递增式场景
场景“比如你的线程数多一次性加载不完,实际中也是慢慢加载的,这种情况下就使用递增式。
一般使用的是递增式
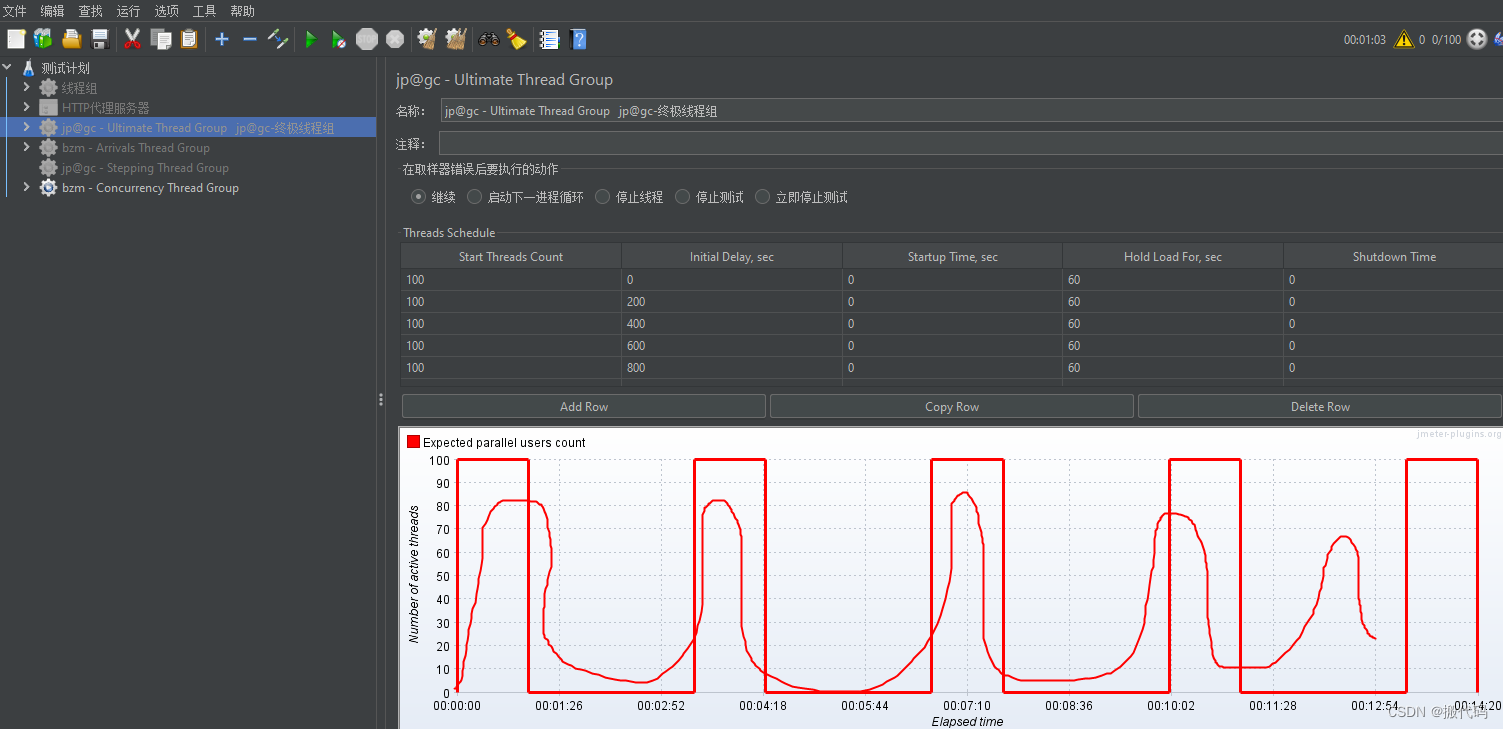
实战五:极限场景【浪涌测试】
如:我们去12306抢票,比较集中,特别是节假日,
早上八点上班前有一波,
中午12点下班有一波,
中午吃完饭有一波,
下午下班后有一波
如图:
jp@gc - Ultimate Thread Group jp@gc-终极线程组
实战六:混合场景【流程压测】
假设100用户
登录100-加入购物车-支付-评论
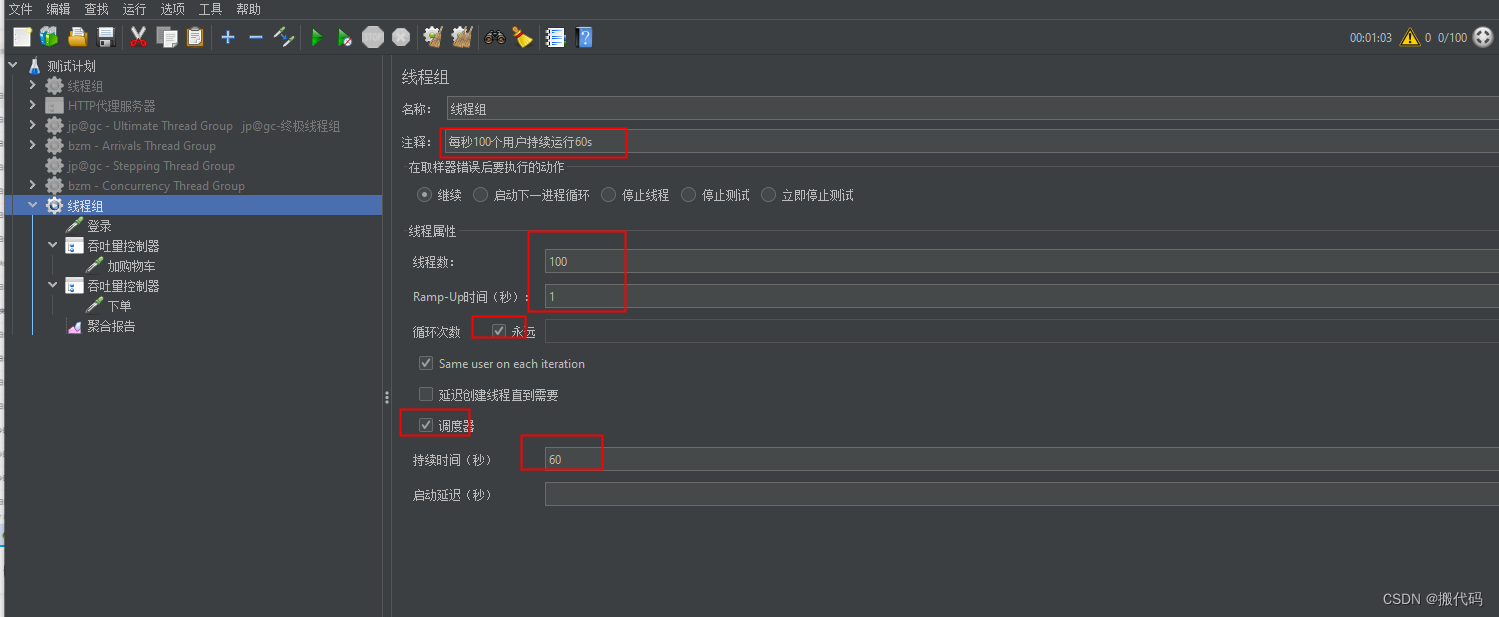
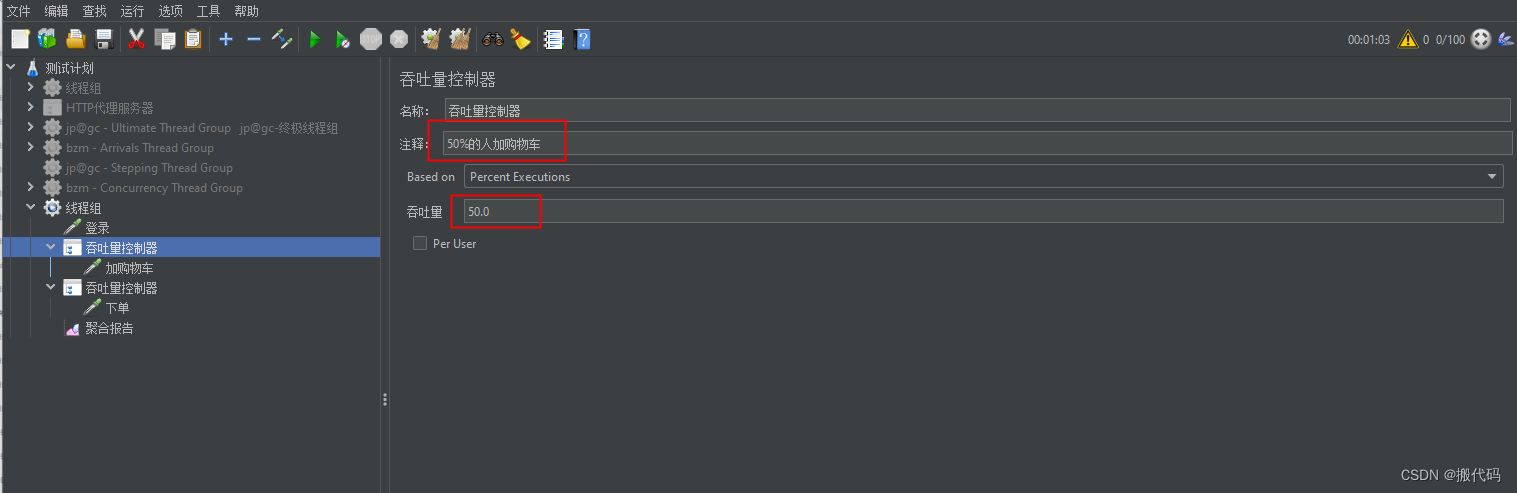
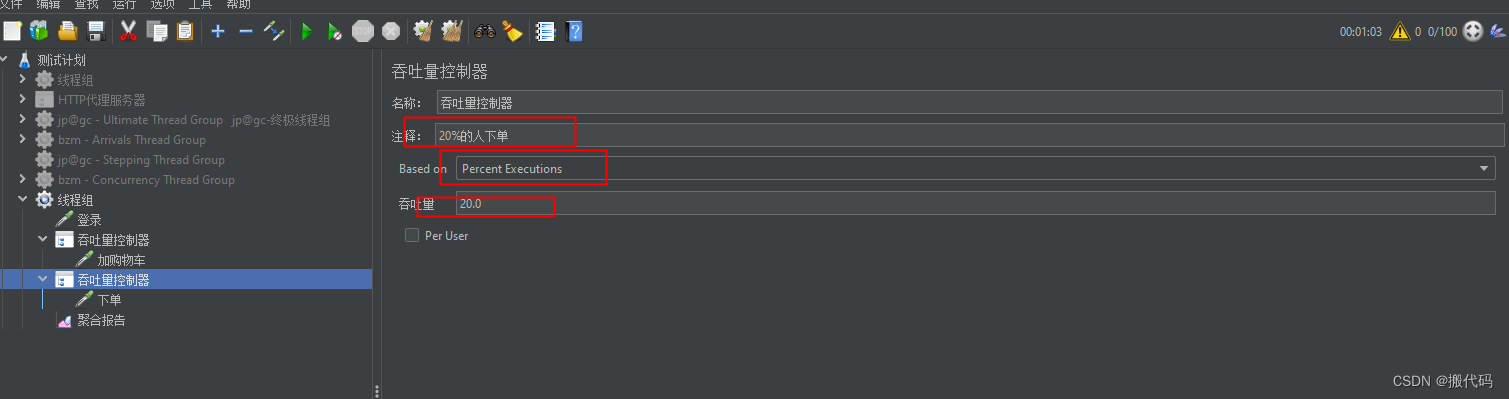
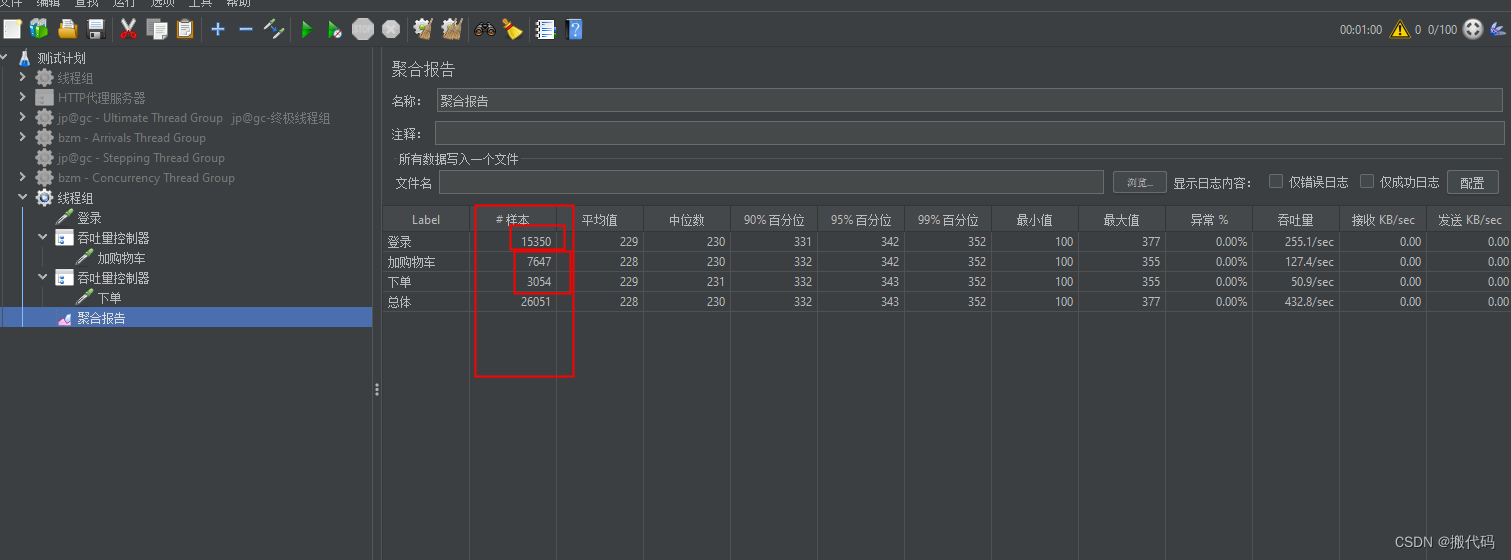
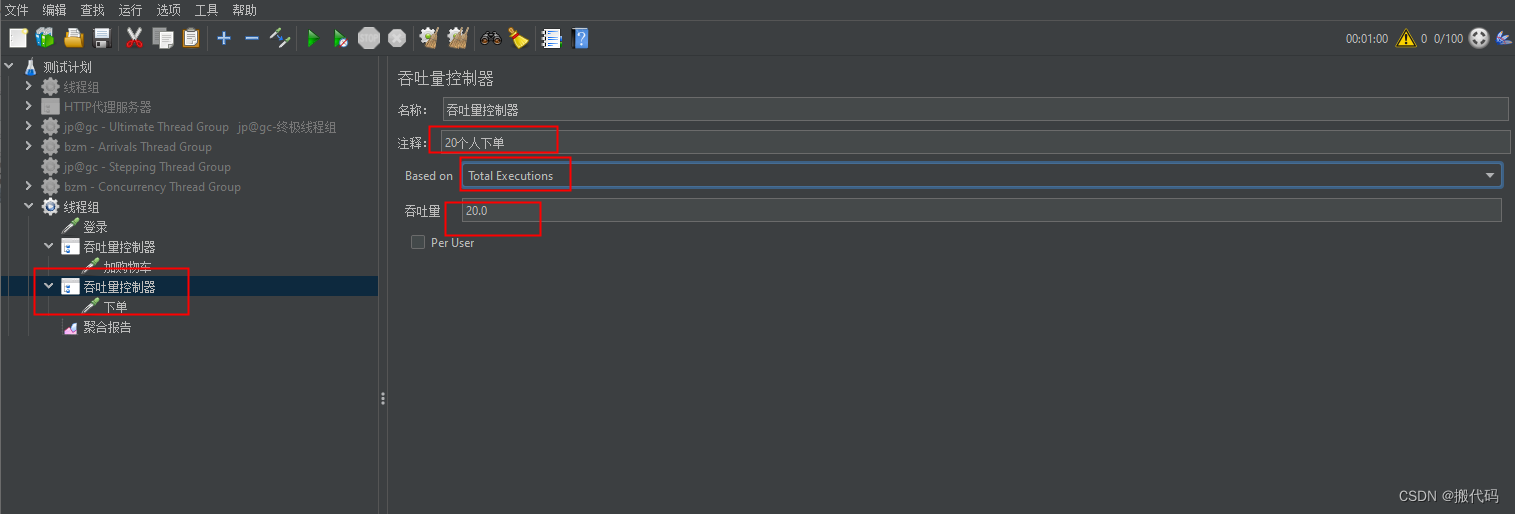
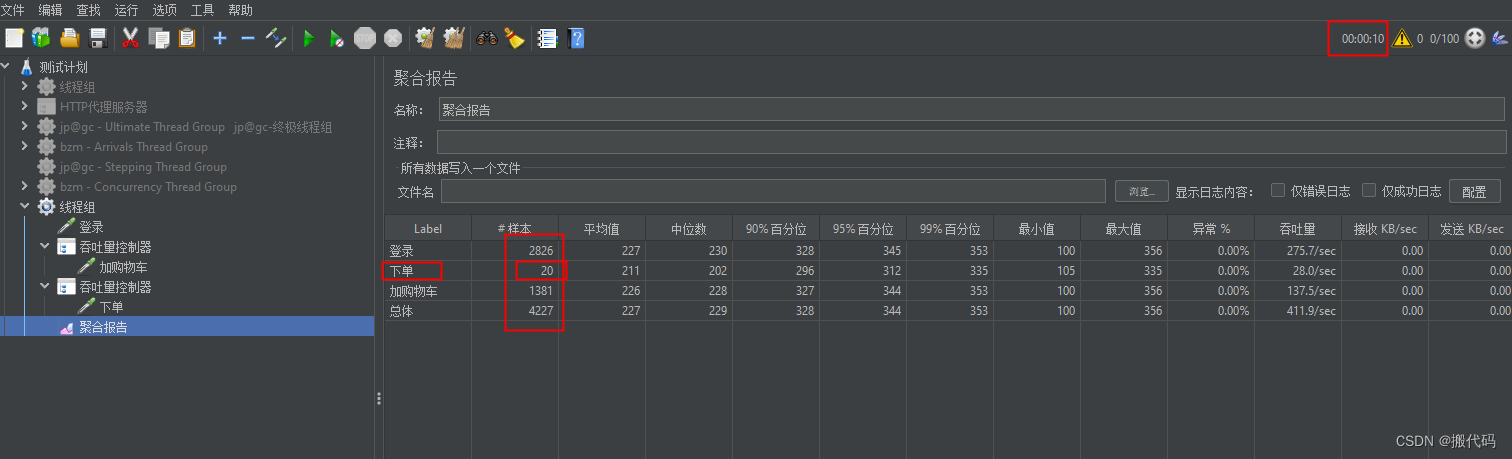
可以看到样本中数量变化,当然吞吐量控制器使用的是百分比。
下面下单的吞吐量控制器使用 线程数,
线程组中只持续时间改成10,时间少一点
看一个结果
以上六个场景在什么时候用,都要了如指掌
最常见的问题:
内存泄漏
资源过高
线程死锁
数据库连接池不够
数据库死锁
SQL需要优化
TPS上不去
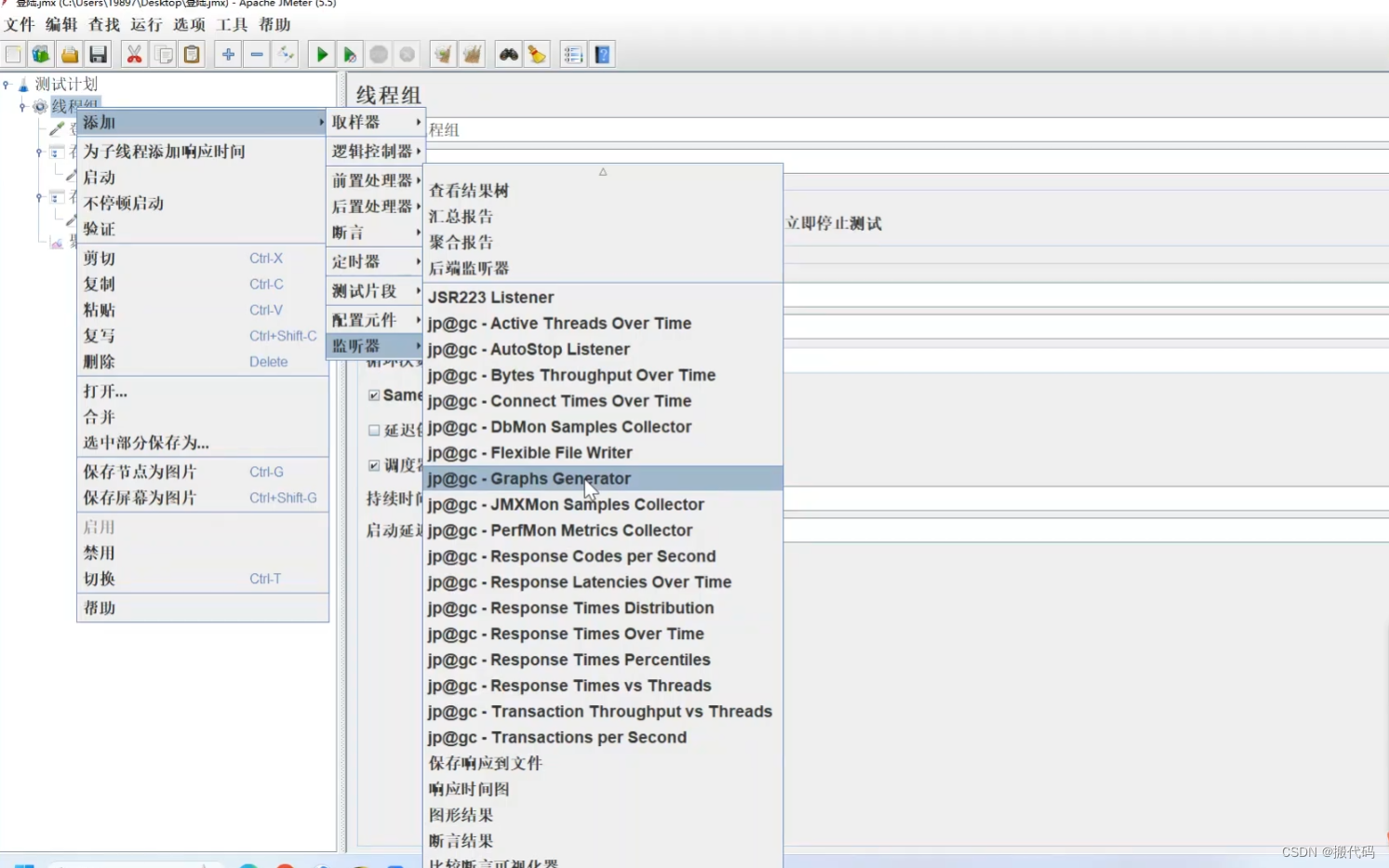
上图这些东西有些事需要在服务安装一些东西,结合性能测试123查看,结合influxdb查看


















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









