




摘要: 本文介绍了LongBench v2,这是一个旨在评估法学硕士处理需要深入理解和推理的长上下文问题的能力的基准。LongBench v2包含503个具有挑战性的多项选择题,上下文从8k到2M不等,跨越6个主要任务类别:单文档QA、多文档QA、长上下文学习、长对话历史理解、代码存储库理解和长结构化数据理解。为了保证数据的广度和实用性,我们收集了近100位高学历、不同专业背景的个人数据。我们采用自动化和人工审查过程来保持高质量和难度,导致人类专家在15分钟的时间限制下仅达到53.7%的准确率。我们的评估显示,当直接回答问题时,表现最好的模型只有50.1%的准确率。相比之下,包含更长的推理的o1preview模型达到了57.7%,比人类基线高出4%。这些结果突出了在LongBench v2中增强推理能力和扩展推理时间计算以解决长上下文挑战的重要性。
单位: 智谱AI (1.3号); 只是说如何测试
1 Introduction 介绍
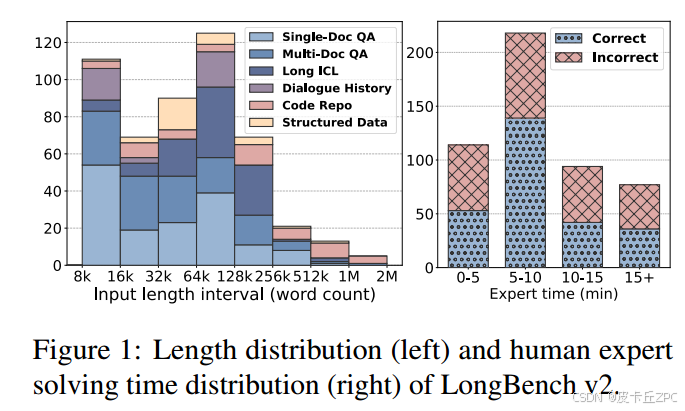
在过去的一年里,关于长上下文大型语言模型(llm)的研究和产品取得了显著的进展:在上下文窗口长度方面,从最初的8k推进到目前的128k甚至1M token (OpenAI, 2024c;人为,2024;Reid等,2024;GLM等,2024);并在长期基准上取得有希望的表现。然而,在这些进步的背后,存在着一个紧迫而现实的问题:这些模型是否真正理解长文本他们处理,也就是说,他们是否能够深刻理解、学习和推理这些长文本中包含的信息?关键是,现有的长上下文理解基准(Bai等人,2024b;张等,2024d;Hsieh等人,2024)未能反映出长语境法学硕士对不同任务的深度理解能力。他们通常专注于提取问题,其中答案直接在材料中找到,这是现代长上下文模型和RAG系统很容易处理的挑战,正如他们在大海捞针测试中的完美召回(Kamradt, 2023)所证明的那样。此外,许多这些基准测试依赖于合成任务,这限制了它们对现实场景的适用性,并且它们采用的指标(如F1和ROUGE)是不可靠的。为了解决这些问题,我们的目标是建立一个具有以下特征的基准:(1)长度:上下文长度范围从8k到2M,大多数在128k以下。(2)难度:具有足够的挑战性,即使是人类专家,使用文档中的搜索工具,也无法在短时间内正确回答。(3)覆盖范围:覆盖各种现实场景。(4)可靠性:全部以选择题形式进行可靠性评估。考虑到上述目标,我们提出了LongBench v2。LongBench v2包含503个选择题,由6个主要任务类别和20个子任务组成,以涵盖尽可能多的现实情况尽可能深入的理解场景,包括单文档QA、多文档QA、长上下文学习、长对话历史理解、代码存储库理解和长结构化数据理解(详见表1)。LongBench v2中的所有测试数据都是英文的,每个任务类别的长度分布如图1左侧所示。为了确保测试数据的质量和难度,我们在数据收集过程中结合了自动化和人工审查。我们首先从顶尖大学中招募97名不同学术背景和成绩的数据注释者,然后从中选择24名数据审稿人。注释者提供的数据包括长文档、问题、选项、答案和证据。然后,我们利用三个长上下文llm进行自动审查,如果三个llm都正确回答了一个问题,那么这个问题就被认为太简单了。通过自动审查的数据被分配给审查者,他们回答问题并确定问题是否合适(满足我们的需求)以及答案是否正确。在我们的标准中,一个合格的数据点应该有(1)一个适当的问题和一个客观、正确的答案;(2)足够的难度,使得三个llm不能同时正确回答,即使使用文档中的搜索工具,人工审稿人也不能在3分钟内正确回答。如果数据不符合这些标准,我们要求注释者进行修改。我们还设置了长度和难度激励,以鼓励更长和更难的测试数据。图1(右)可视化了专家解决时间的分布以及人类的准确性。总体而言,我们的数据显示中位数字数为54k,平均字数为104k。人类专家能够在15分钟内达到53.7%的准确率,而随机猜测的准确率为25%,这凸显了测试的挑战性。在评价中,表现最好的模型在直接输出答案时准确率仅为50.1%。相比之下,在推理过程中包含更长的推理的01 -预览模型达到了57.7%,超过了人类专家。这意味着LongBench v2对当前模型的推理能力提出了更高的要求,并且结合更多的推理时间思考和推理似乎是解决这种长上下文推理挑战的自然和关键步骤。我们希望LongBench v2将加速探索扩展推理时间计算如何影响长上下文场景中的深度理解和推理。
2 Related Work 相关工作
我们将llm现有的长上下文基准分为两种类型。第一个包含综合的基准测试,它结合了多任务,如QA、检索和总结。根据发布日期排序,这些基准包括ZeroSCROLLS (Shaham等人,2023)、L-Eval (An等人,2024)、LongBench (Bai等人,2024b)、BAMBOO (Dong等人,2024)、LooGLE (Li等人
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









