




#pic_center
R 1 R_1 R1
R 2 R^2 R2
知识框架
No.1 注意力机制
一、注意力机制
1、注意力机制
- 这个还是多看资料吧
2、心理学上的注意力
- 首先,从心理学的角度来看,生物需要在复杂的环境中有效地关注值得注意的事物。这是因为每天我们都会面对大量信息,但大脑会在潜意识中帮我们过滤掉大部分不需要的信息。因此,有效的关注对我们来说至关重要。
- 在心理学中,有一个框架被称为人类注意力机制,它会根据随意和非随意的线索来选择注意的焦点。这里的随意并非指随便,而是指主动、有意识地观察。例如,在一个场景中,有眼睛、报纸、纸张、红色咖啡杯、草稿纸和一本书。首先,可能会注意到红色的咖啡杯,因为它更为显眼。这属于不随意的线索,即下意识地关注亮眼的事物。接着,如果拿起咖啡杯喝了咖啡,可能会想到下一步要做什么。比如,可能会有意识地决定去看一本书,因为在刚刚的情绪激发下,想进行一些学习。这种有意识地追随线索的过程被称为随意线索。
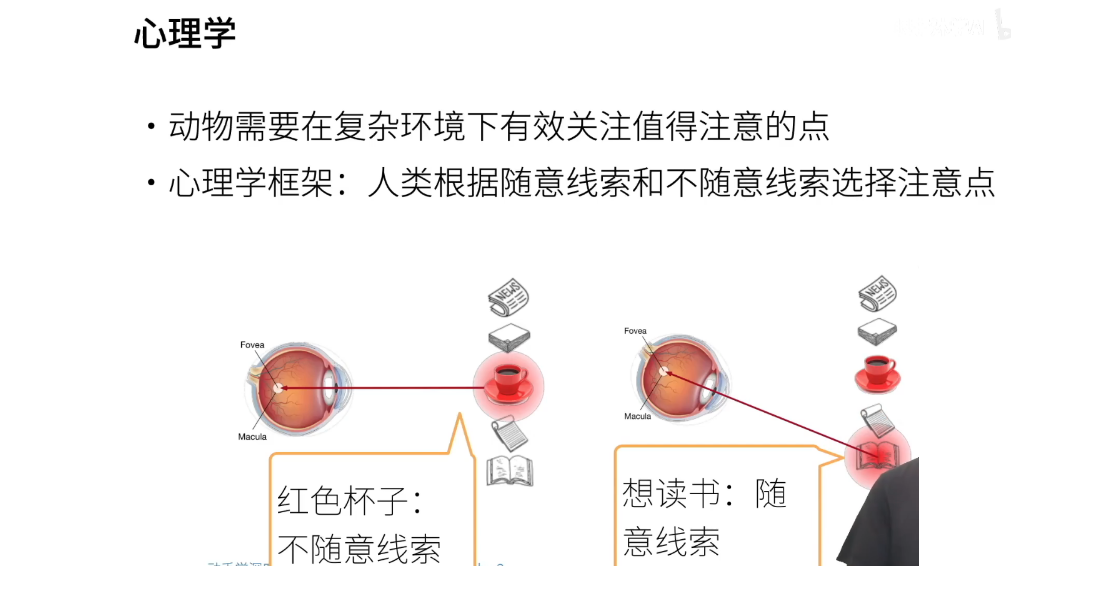
3、注意力机制
-
虽然这个模型并非出自心理学背景,但从心理学的角度来看,我们也可以进行一些解读。首先,卷积神经网络(CNN)和全连接网络是计算机视觉领域中常见的模型。它们主要考虑不随意的线索,即从图像中提取最显著的特征。卷积神经网络通过将图像中最显著的信号进行卷积操作,提取出关键特征。这个过程有点类似于在图像中找到最大的亮点或颜色鲜艳的区域。卷积操作实际上是将图像中的各个部分提取出来,形成一个特征图,更容易捕捉到图像中的大块特征,比如大块的方块或者饱和颜色的像素。
-
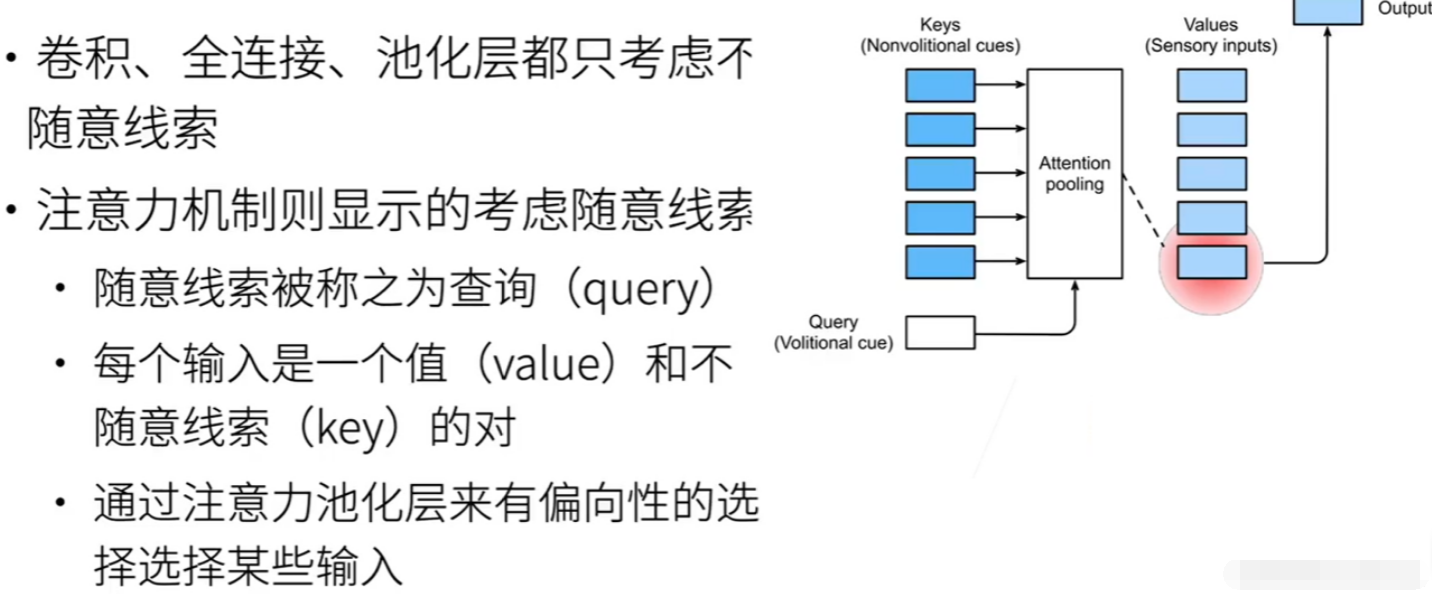
注意力机制是一种很明显地去建模随意线索的方法。在这里,我们可以将心理学中的随意线索直接映射到注意力机制中。首先,随意线索在注意力机制中被称为query,表示想要做什么,比如想要喝咖啡。而环境的元素,例如报纸或咖啡杯,被视为key-value对,其中key是环境元素本身,而value可以是对该元素的某种评价或属性。注意力机制还可以称为注意力,也被形象地称为tension pulling。
-
注意力机制会根据query的输入,有偏向地选择某些key-value对。与之前提到的池化层不同之处在于,注意力机制引入了query的概念,即对环境的主动查询,表示一个意图。这使得注意力机制能够根据query在环境中寻找感兴趣的元素,这是与其他先前介绍的层所不同的特点。
4、非参数注意力池化层
- 了解这个深度学习社区的人们通常喜欢将一些先前已有的东西称为全新的突破,这就像苹果宣称推出一款新手机,将其描述为人类最伟大的创造之一一样。注意力机制作为深度学习领域近年来的一项重要突破,经常被赋予这样的赞誉。然而,值得注意的是,卷积和全连接循环神经网络(GRNN)等技术在80年代和90年代就已经存在,所以它们并不算是最近的突破。
- 如果我们真的追溯注意力机制的发展历程,从统计学的角度看,它其实在五六十年代就已经有了一些雏形。虽然在深度学习中引入了一些新的思想,但在更早的时候,已经有了一些关于注意力的基础。让我们稍微了解一下从古老的技术是如何演进到现代技术的。
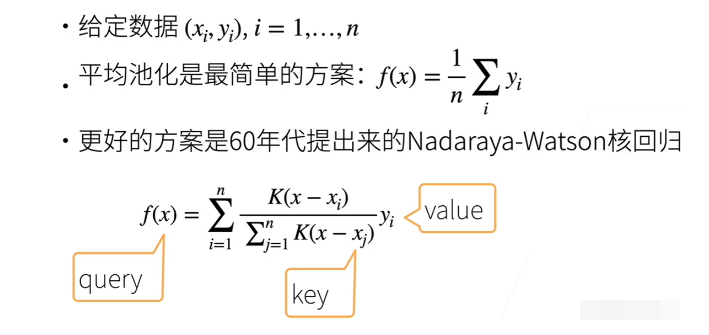
- 首先介绍一下非参数化的注意力机制,即不使用特定的参数进行建模。给定一些数据,包含一些键值对(key-value pair),其中 x 是查询键(key),而 y 是相应的值(value)。最简单的磁化方式是平均磁化,即对所有值 y 进行平均。然而,这种方法可能过于简单,因为它没有考虑到查询键 x 的重要性。
- 较好的方法是这样的:对于给定的查询(query),与所有的候选键(key)进行比较,然后使用科尔索磁化(Connodigrash)函数进行加权。科尔索磁化是一个函数,通常称为核函数,用于衡量查询键 x 与键值对中的键之间的距离。如果你学过支持向量机(SVM),你会对科尔索磁化的概念比较熟悉,因为核函数用于测量向量之间的距离。有许多不同的核函数可供选择,一般来说,距离越小,相似度越大,距离越大,相似度越小。
- 科尔索磁化计算 x 与每个键的相似度,然后将这些相似度转换为概率分布,使用该分布对值 y 进行加权求和。这样,对于给定的查询 x,会选择与 x 相似的键值对,将它们的值 y 组合成最终的输出。
- 值得注意的是,科尔索磁化是一种非参数化的方法,无需学习额外的参数,只需利用已有数据进行计算。这种方法类似于 k-最近邻(KNN)的思想,即对于新的查询,选择与之相近的数据进行处理,无需预先学习模型。
- 最后提到了非参数化的注意力磁化层,可以看作是现代注意力磁化层的前身,两者在概念上非常相似。
5、Nadaraya-Watson核回归
- 接下来来讨论 k 的选择,如果选择高斯核函数,那么它就是一个高斯分布。对于 u(均值)与距离的平方差取负,再除以 2,然后进行指数运算,再除以 1 分之,这就是高斯分布的计算方式。将这个计算带入先前提到的 k(x, x_i),就变成这个形式,因为其中有个 EXP 函数,它的作用是将结果映射到总数大于等于 0的范围。接下来再进行一次除法,相当于进行了 Softmax 操作。Softmax 是一个常用的激活函数,可以将一系列值映射到 0 到 1 之间,而且所有值加起来等于 1。这个映射结果作为权重,应用到 y 上。
- 所以,简而言之,如果选择高斯核函数,它的操作就是对于给定的 x,计算与所有候选 x_i 的距离,然后通过 Softmax 映射到权重,将这个权重应用到 y 上。这与注意力机制的操作非常相似。
- 另外一点是这种方法是非参数化的,也就是说它没有需要学习的参数。在60年代,统计学家可能因为计算机技术不发达,也没有太多可以学习的工具,所以更倾向于不学习参数,直接进行计算。现在我们更倾向于参数化方法,即通过学习一些参数来适应模型。

6、参数化的注意力机制
- 这个 w 是用来做什么的呢?简单来说,它是用来乘以一个向量的,然后通过学习这个 w 的值来调整这个向量。关键在于确定 w 的取值,以及如何使它更为重要。我们可以通过学习这个 w 的过程来优化它,每次进行迭代,使得它能够更好地适应任务。需要注意的是,这里的 w 是一个标量,而不是一个向量,因此 w 是一个只有一个元素的东西。当我们要拓展到多维的情况时,可以将 w 变成一个向量,从而更好地处理多维的情况,这也为接下来要讨论的内容奠定了基础。

7、总结
-
在心理学中,人们通过随意线索和不随意线索来选择注意点。之前介绍的方法主要使用了不随意线索,即不能明确指定要关注什么,而是由数据本身决定。然而,在注意力机制中,引入了一个查询(query)作为随意线索,通过与环境中所有的键(key)和值(value)进行比较,有针对性地进行选择。
-
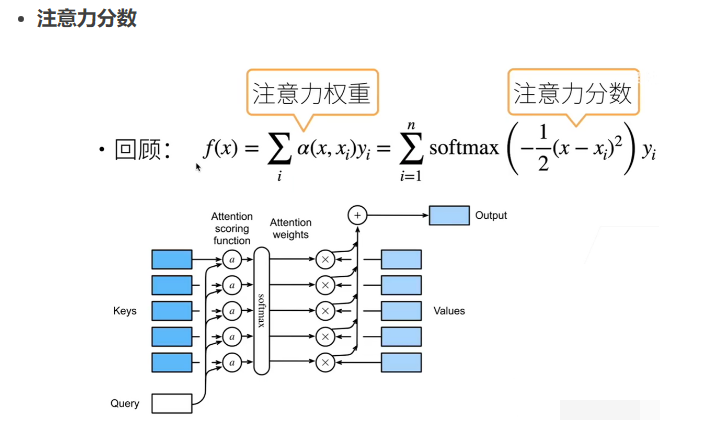
通常可以表示为:$ \text{FX} = \sum_{i} \text{softmax}(\alpha \cdot \text{dist}(x, x_i)) \cdot y_i $
-
其中,(x) 是键, α \alpha α 是注意力权重, dist ( x , x i ) \text{dist}(x, x_i) dist(x,xi) 是计算键之间距离的函数,(y_i) 是对应值, softmax \text{softmax} softmax是用于计算权重的 softmax 函数。
-
这里提到的非参数的注意力机制在60年代就已经有了,通过使用高斯核函数对键进行加权,可以拓展到引入学习参数 (w) 的情况,使其具有学习能力。

二、QA
No.2 注意力分数
一、注意力分数
1、注意力分数
2、注意力分数
3、拓展到高纬度

4、Additive Attention

5、Scaled Dot-Product Attention

6、总结




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









