




副本
副本的目的主要是保障数据的高可用性,即使一台ClickHouse节点宕机,那么也可以从其他服务器获得相同的数据。
https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/replication/
副本写入流程
写入流程如图-18所示:
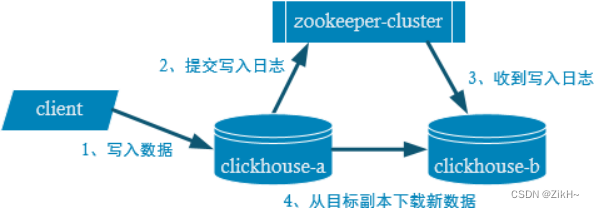
图-18 写入流程
配置步骤
1)启动zookeeper集群。
2)在hadoop101的/etc/clickhouse-server/config.d目录下创建一个名为metrika.xml的配置文件,内容如下:
注:也可以不创建外部文件,直接在config.xml中指定。
<?xml version="1.0"?>
<yandex>
<zookeeper-servers>
<node index="1">
<host>hadoop101</host>
<port>2181</port>
</node>
<node index="2">
<host>hadoop102</host>
<port>2181</port>
</node>
<node index="3">
<host>hadoop103</host>
<port>2181</port>
</node>
</zookeeper-servers>
</yandex>
3)同步到hadoop102和hadoop103上。
xsync /etc/clickhouse-server/config.d/metrika.xml
4)在hadoop101的/etc/clickhouse-server/config.xml中增加。
<zookeeper incl="zookeeper-servers" optional="true" />
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>

图-19 配置文件
5)同步到hadoop102和hadoop103上。
xsync /etc/clickhouse-server/config.xml
6)分别在hadoop102和hadoop103上启动ClickHouse服务。
clickhouse restart
注意:因为修改了配置文件,如果以前启动了服务需要重启。
注意:我们演示副本操作只需要在hadoop101和hadoop102两台服务器即可,上面的操作,我们hadoop103可以你不用同步,我们这里为了保证集群中资源的一致性,做了同步。
7)在hadoop101和hadoop102上分别建表。
副本只能同步数据,不能同步表结构,所以我们需要在每台机器上自己手动建表。
hadoop101:
create table t_order_re ( id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/table/01/t_order','rep_001') partition by toYYYYMMDD(create_time)
primary  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 758
758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











