






 博客内容讨论了在大量数据插入时,初始化HashMap容量的重要性。阿里巴巴开发手册建议根据预计元素数量来初始化容量,以避免频繁扩容导致的性能下降。通过测试验证,初始化容量确实能提高效率,但测试顺序和多线程环境可能会影响结果。结论强调了正确测试方法和阿里巴巴在性能优化方面的专业性。
博客内容讨论了在大量数据插入时,初始化HashMap容量的重要性。阿里巴巴开发手册建议根据预计元素数量来初始化容量,以避免频繁扩容导致的性能下降。通过测试验证,初始化容量确实能提高效率,但测试顺序和多线程环境可能会影响结果。结论强调了正确测试方法和阿里巴巴在性能优化方面的专业性。
问题来源:
万恶的来源于阿里巴巴开发手册:
【推荐】集合初始化时,指定集合初始值大小。说明:HashMap 使用HashMap(int initialCapacity)初始化,如果暂时无法确定集合大小,那么指定默认值(16)即可。
正例:initialCapacity = (需要存储的元素个数 / 负载因子) + 1。注意负载因子(即loader factor)默认为0.75,如果暂时无法确定初始值大小,请设置为16(即默认值)。
反例:HashMap需要放置1024个元素,由于没有设置容量初始大小,随着元素不断增加,容量7次被迫扩大,resize需要重建hash表。当放置的集合元素个数达千万级别时,不断扩容会严重影响性能。
概括一下:就是阿里巴巴认为,在大数据插入的情况,初始化容量比不初始化容量效率高
测试结果:
兴致勃勃的去写了个代码发现是对的:
public static void main(String[] args) {
int aHundredMillion = 1000000;
Map<Integer, Object> map = new HashMap<>();
long s1 = System.currentTimeMillis();
for (int i = 0; i < aHundredMillion; i++) {
map.put(i, i);
}
long s2 = System.currentTimeMillis();
System.out.println("未初始化容量,耗时 : " + (s2 - s1));
Map<Integer, Integer> map1 = new HashMap<>(aHundredMillion);
long s5 = System.currentTimeMillis();
for (int i = 0; i < aHundredMillion; i++) {
map1.put(i, i);
}
long s6 = System.currentTimeMillis();
System.out.println("初始化容量500000,耗时 : " + (s6 - s5));
Map<Integer, Object> map2 = new HashMap<>(aHundredMillion/3*4+1);
long s3 = System.currentTimeMillis();
for (int i = 0; i < aHundredMillion; i++) {
map2.put(i, i);
}
long s4 = System.currentTimeMillis();
System.out.println("初始化容量为标准容量,耗时 : " + (s4 - s3));
}
打印结果如下:
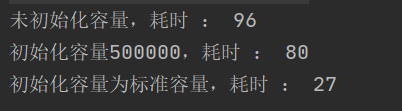
但是,只要更改三者的执行顺序,就会得到不一样的结果(读者可以自行测试),总体来说写在前面的代码执行会慢,具体的原因在于object.hashCode方法是一个native方法,调用该方法所需要的时间取决于操作系统,一般前几次调用该方法会比较慢,多次调用该方法速度会趋于一致,于是修改测试代码并且引入多线程机制进行测试:
public static void main(String[] args) {
new Thread(()->{
test((500000/3*4)+1,500000);
}).start();
new Thread(()->{
test(16,500000);
}).start();
new Thread(()->{
test(0,500000);
}).start();
new Thread(()->{
test(500000,500000);
}).start();
}
private static void test(int range,int size) {
long s1 = System.currentTimeMillis();
for(int j = 0;j<1000;j++) {
Map<Integer, Object> map;
if(size==0)map=new HashMap<>();
else map=new HashMap<>(range);
for (int i = 0; i < size; i++) {
map.put(i, i);
}
}
long s2 = System.currentTimeMillis();
System.out.println("初始化容量为:"+range+" 用时:"+(s2 - s1));
}打印结果如图:
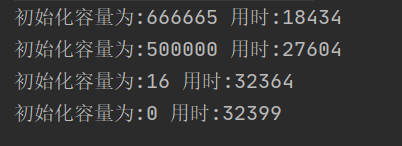
结论:
阿里巴巴牛逼
写个demo的测试方法是不正确的(至少对于Java来说,我用C++好像就没有这样的问题)
推荐测试方法:链接


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









