




 本文介绍了一种基于CRF的模型,用于处理法律文书中的个人、地点、组织和时间等实体识别任务。通过预处理语料库,构建特征并应用LBFGS算法进行训练,模型能够准确地从文本中抽取关键信息。
本文介绍了一种基于CRF的模型,用于处理法律文书中的个人、地点、组织和时间等实体识别任务。通过预处理语料库,构建特征并应用LBFGS算法进行训练,模型能够准确地从文本中抽取关键信息。

环境要求
numpy==1.15.4
python-crfsuite==0.9.6
scikit-learn==0.20.1
scipy==1.1.0
six==1.11.0
sklearn==0.0
sklearn-crfsuite==0.3.6
tabulate==0.8.2
tqdm==4.28.1
## 文件组织
- **corpus.py**
语料类
- **model.py**
模型类
- **utils.py**
工具函数、映射、配置
- **data**
语料
- **requirements.txt**
依赖
## 运行main
```
pip install -r requireme
nts.txt
python main.py
```
即可
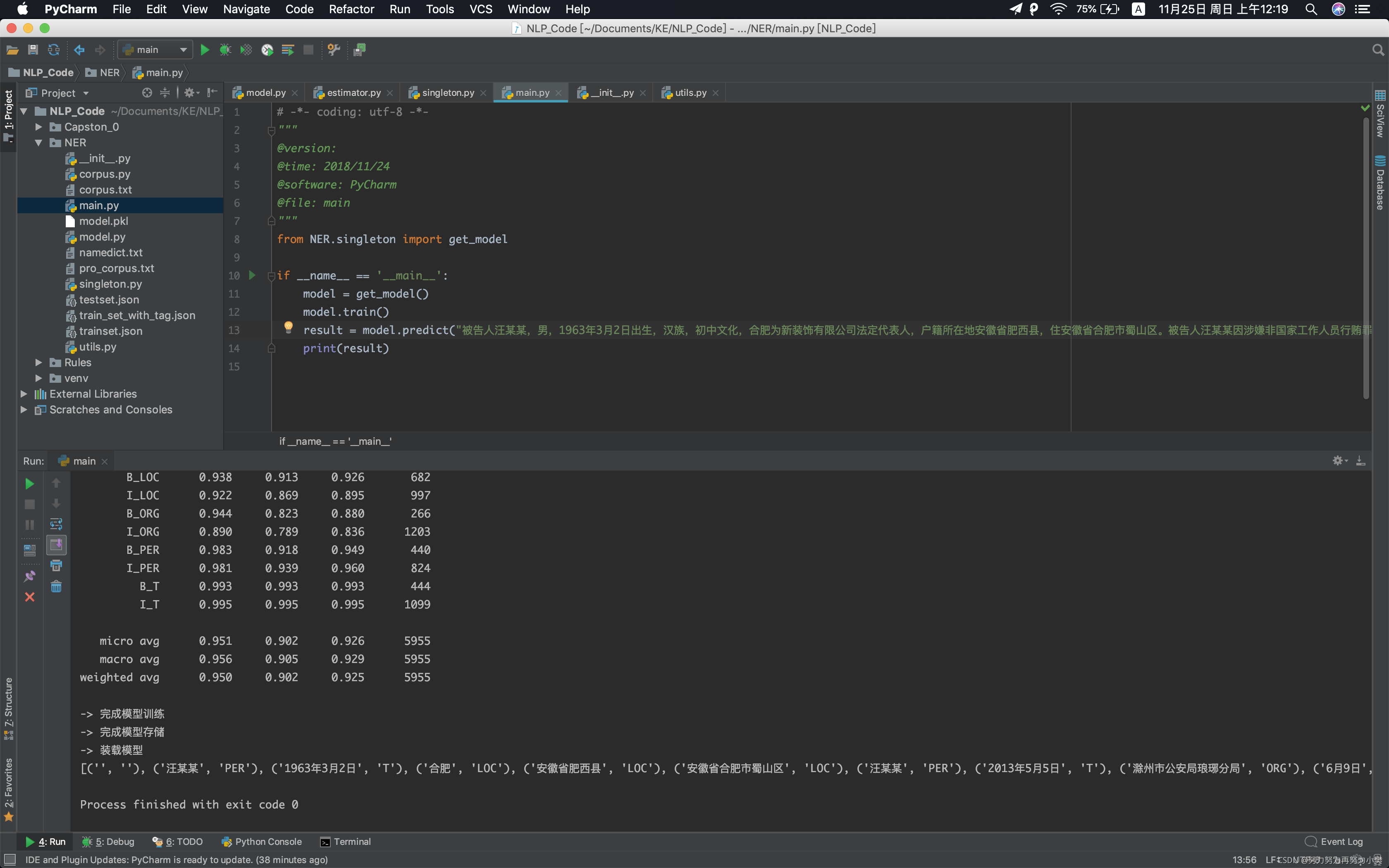
## 效果
中间结果
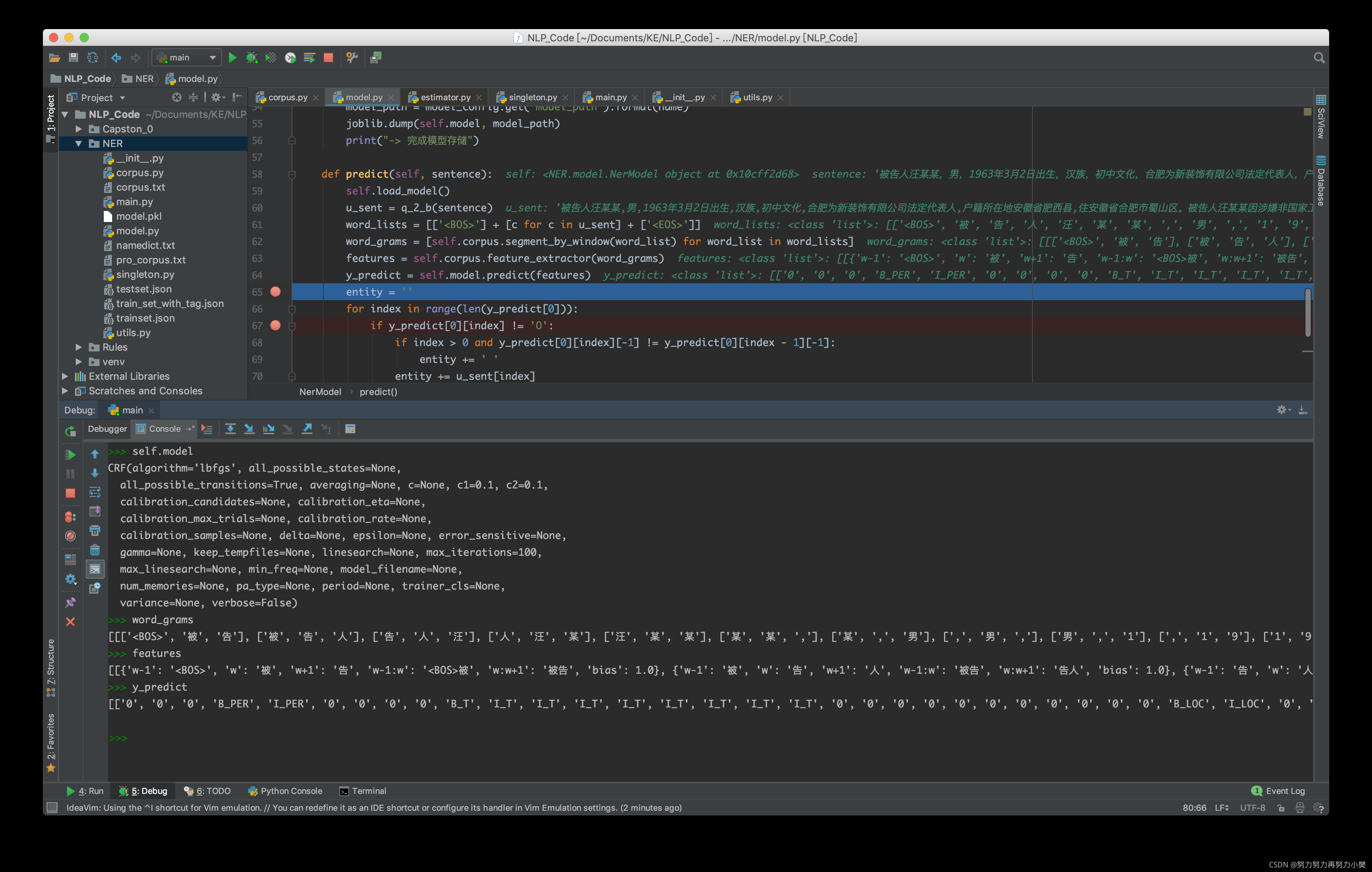
预测结果
**corpus.py** 语料类
# -*- coding: utf-8 -*-
"""
@version:
@time: 2018/11/24
@software: PyCharm
@file: Corpus
"""
import codecs
import re
from utils import q_2_b, tag_mean_map
__corpus = None
class Corpus(object):
def __init__(self):
self.origin_corpus = self.read_corpus("./data/corpus.txt")#读取语料库
self.pro_corpus = self.pre_process(self.origin_corpus)
self.save_pro_corpus(self.pro_corpus)
self.word_seq = []#文本列表
self.pos_seq = []#POS(Part-of-Speech)标注
self.tag_seq = []#标签
def read_corpus(self, path):#读取训练集数据
with open(path, encoding='utf-8') as f:
corpus = f.readlines()
print("-> 完成训练集{0}的读入".format(path))
return corpus
def save_pro_corpus(self, pro_corpus):#保存写入预处理数据
with codecs.open("./data/pro_corpus.txt", 'w', encoding='utf-8') as f:#w:打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
for line in pro_corpus:
f.write(line)#写入文件
f.write("\n")
print("-> 保存预处理数据")
def pre_process(self, origin_corpus):#数据预处理
pro_corpus = []#先创建一个list列表
for line in origin_corpus:
words = q_2_b(line.strip("")).split(' ')#移除字符串头尾得”“,然后split进行分割
pro_words = self.process_big_seq(words)
pro_words = self.process_nr(pro_words)
pro_words = self.process_t(pro_words)
pro_corpus.append(' '.join(pro_words[1:]))#从第二个开始添加,每个成员符号用空格隔开
print("-> 完成数据预处理")
return pro_corpus
def process_nr(self, words):#对nr进行处理
pro_words = []
index = 0
while True:
word = words[index] if index < len(words) else ''
if '/nr' in word:#word列表是现在的单词,words是整个句子列表
next_index = index + 1
#如果说在句子中向下检索单词长度是小于总句子长度而且是'/nr'的时候
if next_index < len(words) and '/nr' in words[next_index]:
#把所有的'/nr'全都替换掉然后把检索的整个句子中的现在的下一个单词压入
pro_words.append(word.replace('/nr', '') + words[next_index])
index = next_index
else:
pro_words.append(word)
elif word:
pro_words.append(word)
else:
break
index += 1
return pro_words
def process_t(self, words):#对_t进行处理
pro_words = []
index = 0
temp = ''
while True:
word = words[index] if index < len(words) else ''
if '/t' in word:
temp = temp.replace('/t', '') + word
elif temp:
pro_words.append(temp)
pro_words.append(word)
temp = ''
elif word:
pro_words.append(word)
else:
break
index += 1
return pro_words
def process_big_seq(self, words):#数据序列发生器
pro_words = []
index = 0
temp = ''
while True:
word = words[index] if index < len(words) else ''
if '[' in word:
temp += re.sub(pattern='/[a-zA-Z]*', repl='', string=word.replace('[', ''))
elif ']' in word:
w = word.split(']')
temp += re.sub(pattern='/[a-zA-Z]*', repl='', string=w[0])
pro_words.append(temp + '/' + w[1])
temp = ''
elif temp:
temp += re.sub(pattern='/[a-zA-Z]*', repl='', string=word)
elif word:
pro_words.append(word)
else:
break
index += 1
return pro_words
def initialize(self):#初始化
pro_corpus = self.read_corpus("./data/pro_corpus.txt")
corpus_list = [line.strip().split(' ') for line in pro_corpus if line.strip()]
del pro_corpus
self.init_sequence(corpus_list)
def init_sequence(self, corpus_list):#字序列、词性序列、标记序列的初始化
words_seq = [[word.split('/')[0] for word in words] for words in corpus_list]
pos_seq = [[word.split('/')[1] for word in words] for words in corpus_list]
tag_seq = [[self.pos_2_tag(p) for p in pos] for pos in pos_seq]
self.pos_seq = [[[pos_seq[index][i] for _ in range(len(words_seq[index][i]))]
for i in range(len(pos_seq[index]))] for index in range(len(pos_seq))]
self.tag_seq = [[[self.perform_tag(tag_seq[index][i], w) for w in range(len(words_seq[index][i]))]
for i in range(len(tag_seq[index]))] for index in range(len(tag_seq))]
self.pos_seq = [['un'] + [self.perform_pos(p) for pos in pos_seq for p in pos] + ['un'] for pos_seq in
self.pos_seq]
self.tag_seq = [[t for tag in tag_seq for t in tag] for tag_seq in self.tag_seq]
self.word_seq = [['<BOS>'] + [w for word in word_seq for w in word] + ['<EOS>'] for word_seq in word 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1118
1118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









